Questa pagina introduce ripristino di emergenza in Cloud SQL.
Panoramica
In Google Cloud, il ripristino di emergenza (RE) del database è un processo che garantisce la continuità dell'elaborazione, in particolare quando una regione non funziona o non è più disponibile. Cloud SQL è un servizio regionale (quando Cloud SQL è configurato per l'alta disponibilità (HA)). Pertanto, se la regione Google Cloud che ospita un database Cloud SQL non è più disponibile, anche il database Cloud SQL non sarà più disponibile.
Per continuare l'elaborazione, devi rendere disponibile il database in una regione secondaria il prima possibile. Il piano di DR richiede la configurazione di una replica di lettura tra regioni in Cloud SQL. È possibile anche un failover basato su esportazione/importazione o backup/ripristino, ma questo approccio richiede più tempo, soprattutto per i database di grandi dimensioni.
I seguenti scenari aziendali sono esempi che giustificano una configurazione di failover tra regioni:
- L'accordo sul livello del servizio dell'applicazione aziendale è superiore all'accordo sul livello del servizio di Cloud SQL regionale (disponibilità del 99,99% a seconda della versione di Cloud SQL). Eseguendo il failover in un'altra regione, puoi mitigare un'interruzione.
- Tutti i livelli dell'applicazione aziendale sono già multiregionali e possono continuare l'elaborazione quando si verifica un'interruzione della regione. La configurazione del failover tra regioni consente di supportare la disponibilità continua di un database.
- Il Recovery Time Objective (RTO) e il Recovery Point Objective (RPO) richiesti sono in minuti anziché in ore. Il failover a un'altra regione è più rapido della ricreazione di un database.
In generale, esistono due varianti per la procedura di RE:
- Un database esegue il failover in una regione secondaria. Una volta che il database è pronto e utilizzato da un'applicazione, diventa il nuovo database principale e rimane tale.
- Un database esegue il failover in una regione secondaria, ma torna alla regione principale dopo che quest'ultima è stata ripristinata dall'errore.
Questa Google Cloud panoramica del ripristino di emergenza del database SQL descrive la seconda variante, ovvero quando un database non funzionante viene recuperato e torna alla regione primaria. Questa variante del processo di DR è particolarmente pertinente per i database che devono essere eseguiti nella regione principale a causa della latenza di rete o perché alcune risorse sono disponibili solo nella regione principale. Con questa variante, il database viene eseguito nella regione secondaria solo per la durata dell'interruzione nella regione primaria.
A questo documento di RE sono associati due tutorial:- Ripristino di emergenza di Cloud SQL per MySQL: una procedura completa di failover e fallback
- Ripristino di emergenza Cloud SQL per PostgreSQL: una procedura completa di failover e fallback
Architettura del disaster recovery
Il seguente diagramma mostra l'architettura minima che supporta il RE del database per un'istanza Cloud SQL ad alta affidabilità:
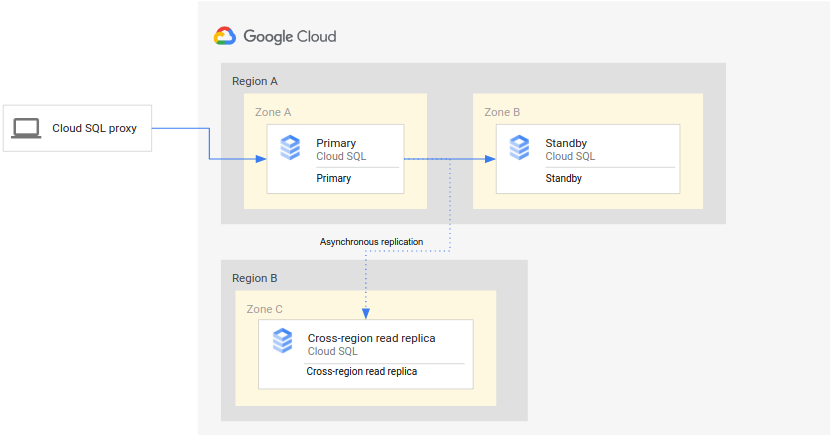
L'architettura funziona nel seguente modo:
- Due istanze di Cloud SQL (una primaria e una in standby) si trovano in due zone separate all'interno di una singola regione (la regione primaria). Le istanze vengono sincronizzate utilizzando dischi permanenti a livello di regione.
- Un'istanza di Cloud SQL (la replica di lettura tra regioni) si trova in una seconda regione (la regione secondaria). Per il DR, la replica di lettura tra regioni è configurata per la sincronizzazione (utilizzando la replica asincrona) con l'istanza primaria utilizzando una configurazione di replica di lettura.
Le istanze primaria e in standby condividono lo stesso disco a livello di regione, quindi i loro stati sono identici.
Poiché questa configurazione utilizza la replica asincrona, è possibile che la replica di lettura cross-region sia in ritardo rispetto all'istanza principale. Di conseguenza, quando si verifica un failover, l'RPO della replica di lettura tra regioni è probabilmente diverso da zero.
Procedura di disaster recovery
Il processo di ripristino di emergenza (RE) inizia quando la regione principale non è più disponibile. Per riprendere l'elaborazione in una regione secondaria, attivi un failover dell'istanza primaria promuovendo una replica di lettura tra regioni. Il processo di DR definisce i passaggi operativi da eseguire, manualmente o automaticamente, per mitigare l'errore della regione e stabilire un'istanza primaria in esecuzione in una regione secondaria.
Il seguente diagramma mostra la procedura di RE:
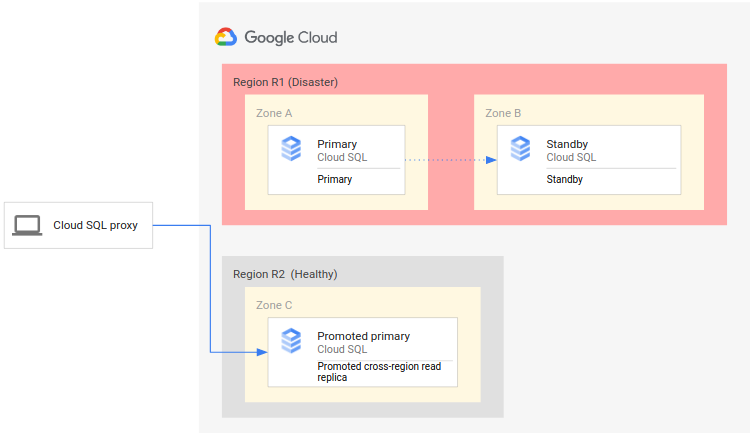
Il processo di DR prevede i seguenti passaggi:
- La regione primaria (R1), in cui è in esecuzione l'istanza primaria, diventa non disponibile.
- Il team operativo riconosce e conferma formalmente l'emergenza e decide se è necessario eseguire un failover.
- Se è necessario un failover, puoi promuovere la replica di lettura tra regioni nella regione secondaria (R2) in modo che diventi la nuova istanza primaria.
- Le connessioni client vengono riconfigurate per riprendere l'elaborazione nella nuova istanza primaria e accedere all'istanza primaria in R2.
Questo processo iniziale ristabilisce un database primario funzionante. Tuttavia, non consente di creare un'architettura di RE completa in cui la nuova istanza primaria disponga di un'istanza in standby e di una replica di lettura tra regioni.
Un processo di RE completo garantisce che la singola istanza, la nuova istanza primaria, sia abilitata per l'alta affidabilità e disponga di una replica di lettura tra regioni. Un processo di RE completo fornisce anche un failback al deployment originale nella regione principale originale.
Eseguire il failover in una regione secondaria
Un processo di RE completo implica l'aggiunta di passaggi al processo di RE di base per stabilire un'architettura di RE completa dopo il failover. Il seguente diagramma mostra un'architettura di RE del database completo dopo il failover:
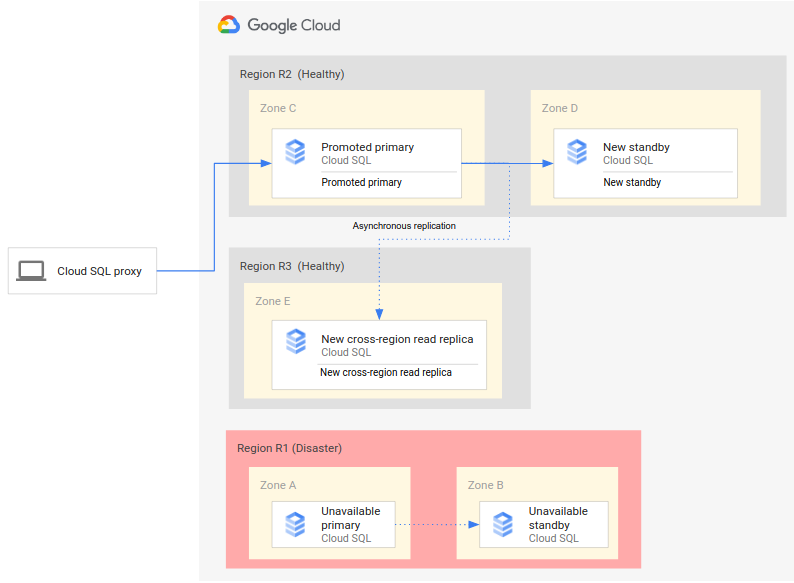
Il processo di RE del database completo prevede i seguenti passaggi:
- La regione primaria (R1), in cui è in esecuzione il database primario, diventa non disponibile.
- Il team operativo riconosce e conferma formalmente l'emergenza e decide se è necessario eseguire un failover.
- Se è necessario un failover, puoi promuovere la replica di lettura tra regioni nella regione secondaria (R2) in modo che diventi la nuova istanza primaria.
- Le connessioni client vengono riconfigurate per accedere ed elaborare i dati nella nuova istanza primaria (R2).
- Una nuova istanza in standby viene creata, avviata in R2 e aggiunta all'istanza primaria. L'istanza in standby si trova in una zona diversa rispetto all'istanza primaria. L'istanza principale è ora ad alta disponibilità perché è stata creata un'istanza di standby.
- In una terza regione (R3), viene creata una nuova replica di lettura tra regioni e collegata all'istanza primaria. A questo punto, un'architettura di disaster recovery completa viene ricreata e resa operativa.
Se la regione primaria originale (R1) diventa disponibile prima dell'implementazione del passaggio 6, la replica di lettura tra regioni può essere posizionata immediatamente nella regione R1 anziché nella regione R3. In questo caso, il failover alla regione primaria originale (R1) è meno complesso e richiede meno passaggi.
Evitare uno stato di split-brain
Un errore della regione primaria (R1) non significa che l'istanza primaria originale e la relativa istanza in standby vengano arrestate, rimosse o rese inaccessibili automaticamente quando R1 torna disponibile. Se R1 torna disponibile, i client potrebbero leggere e scrivere dati (anche per errore) nell'istanza primaria originale. In questo caso, può svilupparsi una situazione di split-brain in cui alcuni client accedono a dati obsoleti nel vecchio database principale e altri client accedono a dati aggiornati nel nuovo database principale, causando problemi nella tua attività.
Per evitare una situazione di split-brain, devi assicurarti che i client non possano più accedere all'istanza primaria originale dopo che R1 diventa disponibile. Idealmente, dovresti rendere inaccessibile il database principale originale prima che i client inizino a utilizzare il nuovo database principale, quindi eliminare il database principale originale subito dopo averlo reso inaccessibile.
Creazione di un backup iniziale dopo il failover
Quando promuovi la replica di lettura tra regioni in modo che diventi la nuova istanza primaria in un failover, le transazioni nella nuova istanza primaria potrebbero non essere completamente sincronizzate con le transazioni dell'istanza primaria originale. Pertanto, queste transazioni non sono disponibili nella nuova istanza.
Come best practice, ti consigliamo di eseguire immediatamente il backup della nuova istanza primaria all'inizio del failover e prima che i client accedano al database. Questo backup rappresenta uno stato coerente e noto al momento del failover. Questi backup possono essere importanti a fini normativi o per il ripristino di uno stato noto se i client riscontrano problemi durante l'accesso al nuovo server primario.
Ripristino della regione primaria originale
Come descritto in precedenza, questo documento fornisce i passaggi per eseguire il failback alla regione originale (R1). Esistono due versioni diverse del processo di fallback.
- Se hai creato la nuova replica di lettura tra regioni in una regione terziaria (R3), devi creare un'altra (seconda) replica di lettura tra regioni nella regione primaria (R1).
- Se hai creato la nuova replica di lettura tra regioni nella regione primaria (R1), non devi creare un'altra replica di lettura tra regioni aggiuntiva in R1.
Una volta creata la replica di lettura cross-region in R1, l'istanza Cloud SQL può eseguire il failback a R1. Poiché questo fallback viene attivato manualmente e non si basa su un'interruzione, puoi scegliere un giorno e un'ora appropriati per questa attività di manutenzione.
Pertanto, per ottenere un RE completo con una replica di lettura primaria, in standby e cross-region, sono necessari due failover. Il primo failover viene attivato dall'interruzione (un vero failover), mentre il secondo ristabilisce la distribuzione iniziale (un fallback).
Il fallback alla regione principale originale (R1) prevede i seguenti passaggi:
- Promuovi la replica tra regioni appena creata nella regione primaria originale (R1).
- Se l'istanza promossa non è stata creata originariamente come replica HA, abilita l'alta affidabilità sull'istanza per proteggerla da errori zonali.
- Riconfigura le applicazioni per connetterti alla nuova istanza primaria.
- Crea una replica tra regioni per la nuova istanza primaria nella regione di RE (R2).
- (Facoltativo) Per evitare di eseguire più istanze primarie indipendenti, pulisci l'istanza primaria nella regione di RE (R2).
Ripristino di emergenza (RE) avanzato
Se utilizzi la versione Cloud SQL Enterprise Plus, puoi sfruttare ilREa avanzato. Il ripristino di emergenza avanzato semplifica il recupero e il fallback dopo un failover tra regioni. Come descritto nella sezione Procedura di disaster recovery, quando esegui RE, rimuovi la connessione tra la regione non riuscita della vecchia istanza primaria e la regione operativa della nuova istanza primaria. Con RE, per ripristinare le connessioni alla regione di deployment originale e recuperare la vecchia istanza primaria, devi eseguire una serie di passaggi di failback manuali.
Con RE avanzato, quando si verifica un errore a livello di regione, puoi richiamare un failover della replica. Con il failover della replica, promuovi una replica di lettura tra regioni in modo simile all'esecuzione del normale RE, tranne per il fatto che promuovi la replica di ripristino di emergenza (RE) designata. La promozione della replica di RE è immediata.
Anziché rimuovere la vecchia istanza principale, l'istanza rimane parte della topologia di replica asincrona di Cloud SQL. La vecchia istanza primaria (istanza A) alla fine diventa una replica della sua replica di RE (istanza B) dopo che la replica di RE è stata promossa alla nuova istanza primaria.
Dopo che la vecchia istanza principale (A) è stata trasformata in una replica, puoi eseguire il passaggio finale del RE avanzato. Puoi riportare il deployment Cloud SQL allo stato originale e ripristinare il ruolo precedente dell'istanza principale (A) come istanza principale senza alcuna perdita di dati. Per eseguire questo ripristino senza perdita di dati della vecchia istanza primaria (A), puoi utilizzare l'operazione switchover. Quando esegui un cambio, non si verifica alcuna perdita di dati perché l'istanza principale (B) rimane in modalità di sola lettura finché la replica dREDR designata (A) non raggiunge l'istanza principale (B). Dopo che la replica di RE (A) ha ricevuto tutti gli aggiornamenti di replica, la replica diRER (A) assume il ruolo di istanza primaria, mentre l'istanza primaria precedente (B) viene riconfigurata automaticamente come replica dREDR dell'istanza primaria attuale (A). Le istanze tornano ai ruoli originali, ripristinando la topologia allo stato originale prima del failover di RE e della replica.
Durante RE avanzato, tutte le istanze coinvolte nelle operazioni di failover e switchover delle repliche mantengono i propri indirizzi IP.
Puoi anche utilizzare l'operazione di switchover di RE avanzato per eseguire test di routine di RE per testare e preparare la topologia Cloud SQL per il failover cross-regionale prima che si verifichi un disastro. Se si verifica un'emergenza effettiva, puoi eseguire il failover della replica tra regioni che hai già testato.
Replica per il disaster recovery
In quanto componente obbligatorio del ripristino di emergenza avanzato, la replica RE presenta le seguenti caratteristiche:
- Una replica di RE è una replica di lettura tra regioni connessa direttamente.
- Puoi modificare più volte la designazione della replica di RE.
- Puoi modificare la designazione della replica di RE in qualsiasi momento, tranne durante un'operazione di switchover o failover della replica.
Inoltre, per ridurre l'RTO dopo aver utilizzato RE avanzato, ti consigliamo di procedere come segue:
- Configura la replica RE con le stesse dimensioni dell'istanza principale.
- Se l'istanza principale ha HA abilitata, ti consigliamo di abilitare HA anche sulla replicaRER. Per farlo, verifica innanzitutto che il primario abbia abilitato l'HA. Quindi, esegui il failover alla replica di RE. Una volta completata l'operazione di switchover, attiva l'alta disponibilità sulla nuova istanza principale. Poi puoi tornare all'istanza principale precedente. La replica di ripristino di emergenza mantiene la configurazione HA anche dopo essere tornata a essere una replica.
Failover della replica
In sintesi, il failover di una replica è costituito dai seguenti eventi:
- Crei e assegni una replica RE.
- La regione primaria non è più disponibile.
- Esegui il failover della replica sulla replica RE.
- L'endpoint di scrittura viene aggiornato e inizia a puntare alla nuova istanza principale.
- Quando l'istanza principale originale torna online, diventa una replica di lettura della nuova istanza principale.
- Puoi utilizzare l'operazione di switchover per ripristinare il deployment alla topologia originale.
Per visualizzare i dettagli e i diagrammi di un'operazione di failover della replica, fai clic sulle seguenti schede.
Assegna replica RE
Prima di eseguire un failover della replica, hai assegnato una replica di RE di emergenza all'istanza principale e, se possibile, hai testato la procedura eseguendo un cambio.

Si verifica un'interruzione
La regione principale, in cui è in esecuzione il database principale, diventa non disponibile.

Failover della replica
Dopo aver stabilito che è necessario il ripristino di emergenza, esegui un failover della replica alla replica di RE designata tra regioni.
La replica di RE designata tra regioni diventa immediatamente l'istanza primaria e inizia ad accettare letture e scritture in entrata. L'endpoint di scrittura viene aggiornato e inizia a puntare alla nuova istanza principale.

L'istanza principale originale diventa la replica
Dopo la promozione della replica, Cloud SQL controlla periodicamente se l'istanza principale originale è di nuovo online. Se l'istanza principale originale è online, Cloud SQL ricrea la vecchia istanza principale come replica dell'istanza promossa. La vecchia istanza principale conserva il suo indirizzo IP.

Failback all'originale
Dopo aver eseguito un failover della replica, puoi ripristinare l'istanza principale nella regione originale eseguendo l'operazione di switchover, invertendo la stessa coppia di replica di RE e istanza principale.

Cambia
In sintesi, un'operazione di switchover è costituita dai seguenti eventi:
- Crei e assegni una replica RE.
- Avvii un cambio di ruolo.
- Quando il ritardo di replica scende a zero, le nuove istanze principali iniziano ad accettare le connessioni in entrata.
- La vecchia istanza principale diventa una replica di lettura.
- Se viene utilizzato un endpoint di scrittura DNS, questo viene aggiornato in modo da puntare alla nuova istanza primaria.
Per visualizzare i dettagli e i diagrammi di un'operazione di switchover, fai clic sulle seguenti schede.
Assegna replica RE
Prima di avviare l'operazione di *switchover*, devi assegnare una replica RE all'istanza primaria.
Verifica che l'istanza primaria sia integra. Puoi eseguire un cambio solo quando sia l'istanza primaria sia la replicaRER sono online.
Avvia cambio
Avvii il cambio. Quando avvii un cambio, l'istanza principale smette di accettare scritture e diventa di sola lettura. Cloud SQL attende che i log delle transazioni vengano copiati in Cloud Storage. La replica di RE designata raggiunge l'istanza principale.
Quando il ritardo della replica scende a zero, la replica di RE viene promossa come nuova istanza principale. La nuova istanza primaria inizia ad accettare le connessioni in entrata, incluse le letture e le scritture delle applicazioni.
Endpoint aggiornato
Dopo che la replica di ripristino di emergenza viene promossa alla nuova istanza primaria, l'endpoint di scrittura DNS viene aggiornato e inizia a puntare alla nuova istanza primaria. Se non utilizzi un endpoint di scrittura DNS, devi configurare le tue applicazioni in modo che puntino all'indirizzo IP della nuova istanza primaria.
La vecchia istanza principale viene riconfigurata come replica di lettura.
Il PITR viene attivato automaticamente per la nuova istanza principale. Il recupero point-in-time è possibile solo dopo il primo backup automatico.
Endpoint di scrittura
Un endpoint di scrittura è un nome DNS (Domain Name Service) globale che si risolve automaticamente nell'indirizzo IP dell'istanza primaria corrente. Questo endpoint reindirizza automaticamente le connessioni in entrata alla nuova istanza principale in caso di operazione di failover o switchover della replica. Puoi utilizzare l'endpoint di scrittura in una stringa di connessione SQL anziché un indirizzo IP. Utilizzando un endpoint di scrittura, puoi evitare di dover apportare modifiche alla connessione dell'applicazione quando si verifica un'interruzione della regione.
Un endpoint di scrittura richiede che l'API Cloud DNS sia abilitata nel progetto in cui crei o hai l'istanza primaria Cloud SQL Enterprise Plus esistente. Quando crei un'istanza Cloud SQL Enterprise Plus con un indirizzo IP privato e reti autorizzate, Cloud SQL genera automaticamente un endpoint di scrittura per l'istanza. Se hai già un'istanza principale di Cloud SQL Enterprise Plus, Cloud SQL genera l'endpoint di scrittura quando crei la replica REDR (una replica cross-region che designi per l'istanza principale). Se l'istanza principale cambia a causa di un'operazione di switchover o di failover della replica, Cloud SQL assegna l'endpoint di scrittura alla replicaRER quando la replica REDR diventa la nuova istanza principale.
Per saperne di più sull'utilizzo di un endpoint di scrittura per connettersi a un'istanza, vedi Connettersi a un'istanza utilizzando un endpoint di scrittura.
Passaggi successivi
- Utilizza il ripristino di emergenza (RE) avanzato.
- Prova il tutorial Ripristino di emergenza Cloud SQL per MySQL.
- Esplora architetture di riferimento, diagrammi, tutorial e best practice su Google Cloud. Consulta il nostro Cloud Architecture Center.