In Vector Search, puoi limitare le ricerche di corrispondenza vettoriale a un sottoinsieme dell'indice utilizzando regole booleane. I predicati booleani indicano a Vector Search quali vettori nell'indice ignorare. In questa pagina scoprirai come funziona il filtraggio, vedrai esempi e modi per eseguire query in modo efficiente sui tuoi dati in base alla somiglianza vettoriale.
Con la ricerca vettoriale puoi limitare i risultati in base a restrizioni numeriche e categoriche. L'aggiunta di limitazioni o il "filtraggio" dei risultati dell'indice è utile per diversi motivi, come i seguenti esempi:
Maggiore pertinenza dei risultati: Vector Search è uno strumento potente per trovare elementi semanticamente simili. Il filtro può essere utilizzato per rimuovere risultati non pertinenti dai risultati di ricerca, ad esempio elementi che non rientrano nella lingua, nella categoria, nel prezzo o nell'intervallo di date corretti.
Numero ridotto di risultati: la ricerca vettoriale può restituire un gran numero di risultati, soprattutto per set di dati di grandi dimensioni. Il filtro può essere utilizzato per ridurre il numero di risultati a un numero più gestibile, restituendo comunque i risultati più pertinenti.
Risultati segmentati: il filtro può essere utilizzato per personalizzare i risultati di ricerca in base alle esigenze e alle preferenze individuali dell'utente. Ad esempio, un utente potrebbe voler filtrare i risultati in modo da includere solo gli articoli che ha valutato positivamente in passato o che rientrano in una fascia di prezzo specifica.
Attributi vettoriali
In una ricerca di similarità vettoriale in un database di vettori, ogni vettore è descritto da zero o più attributi. Questi attributi sono noti come token per le limitazioni dei token e valori per le limitazioni numeriche. Queste limitazioni possono essere applicate a ciascuna delle diverse categorie di attributi, note anche come spazi dei nomi.
Nella seguente applicazione di esempio, i vettori sono taggati con un color, un
price e un shape:
color,priceeshapesono spazi dei nomi.redebluesono token dello spazio dei nomicolor.squareecirclesono token dello spazio dei nomishape.100e50sono valori dello spazio dei nomiprice.
Specifica gli attributi del vettore
- Per specificare un "cerchio rosso":
{color: red}, {shape: circle}. - Per specificare un "quadrato rosso o blu":
{color: red, blue}, {shape: square}. - Per specificare un oggetto senza colore, ometti lo spazio dei nomi "color"
nel campo
restricts. - Per specificare le limitazioni numeriche per un oggetto, annota lo spazio dei nomi e il valore nel campo appropriato per il tipo. Il valore int deve essere specificato in
value_int, il valore float deve essere specificato invalue_floate il valore double deve essere specificato invalue_double. Per un determinato spazio dei nomi deve essere utilizzato un solo tipo di numero.
Per informazioni sullo schema utilizzato per specificare questi dati, consulta Specificare spazi dei nomi e token nei dati di input.
Query
- Le query esprimono un operatore logico AND tra gli spazi dei nomi e un operatore logico OR all'interno di ogni spazio dei nomi. Una query che specifica
{color: red, blue}, {shape: square, circle}corrisponde a tutti i punti del database che soddisfano(red || blue) && (square || circle). - Una query che specifica
{color: red}corrisponde a tutti gli oggettireddi qualsiasi tipo, senza alcuna restrizione sushape. - Le limitazioni numeriche nelle query richiedono
namespace, uno dei valori numerici divalue_int,value_floatevalue_doublee l'operatoreop. - L'operatore
opè uno traLESS,LESS_EQUAL,EQUAL,GREATER_EQUALeGREATER. Ad esempio, se viene utilizzato l'operatoreLESS_EQUAL, i punti dati sono idonei se il loro valore è inferiore o uguale al valore utilizzato nella query.
I seguenti esempi di codice identificano gli attributi vettoriali nell'applicazione di esempio:
[
{
"namespace": "price",
"value_int": 20,
"op": "LESS"
},
{
"namespace": "length",
"value_float": 0.3,
"op": "GREATER_EQUAL"
},
{
"namespace": "width",
"value_double": 0.5,
"op": "EQUAL"
}
]
Lista bloccata
Per attivare scenari più avanzati, Google supporta una forma di negazione nota come token denylist. Quando una query inserisce un token in una lista bloccata, le corrispondenze vengono escluse per qualsiasi punto dati che contiene il token inserito nella lista bloccata. Se uno spazio dei nomi di query contiene solo token inseriti nella lista nera, tutti i punti non esplicitamente inseriti nella lista nera corrispondono esattamente allo stesso modo in cui uno spazio dei nomi vuoto corrisponde a tutti i punti.
I punti dati possono anche inserire un token in una lista nera, escludendo le corrispondenze con qualsiasi query che specifica quel token.
Ad esempio, definisci i seguenti punti dati con i token specificati:
A: {} // empty set matches everything
B: {red} // only a 'red' token
C: {blue} // only a 'blue' token
D: {orange} // only an 'orange' token
E: {red, blue} // multiple tokens
F: {red, !blue} // deny the 'blue' token
G: {red, blue, !blue} // An unlikely edge-case
H: {!blue} // deny-only (similar to empty-set)
Il sistema si comporta nel seguente modo:
- Gli spazi dei nomi delle query vuote sono caratteri jolly di corrispondenza totale. Ad esempio,
Q:
{}corrisponde a DB:{color:red}. Gli spazi dei nomi dei punti dati vuoti non sono caratteri jolly di corrispondenza totale. Ad esempio, D:
{color:red}non corrisponde a DB:{}.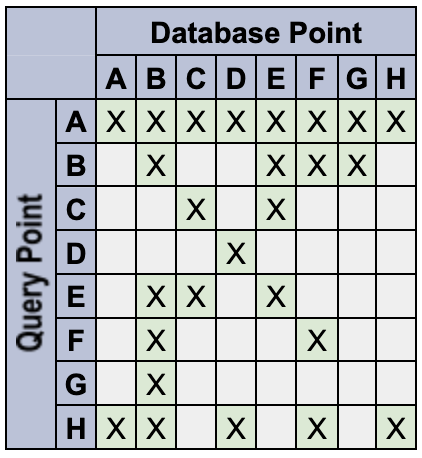
Specifica spazi dei nomi e token o valori nei dati di input
Per informazioni su come strutturare i dati di input in generale, consulta Formato e struttura dei dati di input.
Le seguenti schede mostrano come specificare gli spazi dei nomi e i token associati a ogni vettore di input.
JSON
Per ogni record del vettore, aggiungi un campo denominato
restricts, in modo che contenga un array di oggetti, ognuno dei quali è uno spazio dei nomi.- Ogni oggetto deve avere un campo denominato
namespace. Questo campo è lo spazio dei nomiTokenNamespace.namespace. - Il valore del campo
allow, se presente, è un array di stringhe. Questo array di stringhe è l'elencoTokenNamespace.string_tokens. - Il valore del campo
deny, se presente, è un array di stringhe. Questo array di stringhe è l'elencoTokenNamespace.string_denylist_tokens.
- Ogni oggetto deve avere un campo denominato
Di seguito sono riportati due record di esempio in formato JSON:
[
{
"id": "42",
"embedding": [
0.5,
1
],
"restricts": [
{
"namespace": "class",
"allow": [
"cat",
"pet"
]
},
{
"namespace": "category",
"allow": [
"feline"
]
}
]
},
{
"id": "43",
"embedding": [
0.6,
1
],
"sparse_embedding": {
"values": [
0.1,
0.2
],
"dimensions": [
1,
4
]
},
"restricts": [
{
"namespace": "class",
"allow": [
"dog",
"pet"
]
},
{
"namespace": "category",
"allow": [
"canine"
]
}
]
}
]
Per ogni record del vettore, aggiungi un campo denominato
numeric_restricts, in modo che contenga un array di oggetti, ognuno dei quali è una restrizione numerica.- Ogni oggetto deve avere un campo denominato
namespace. Questo campo è lo spazio dei nomiNumericRestrictNamespace.namespace. - Ogni oggetto deve avere uno tra
value_int,value_floatevalue_double. - Ogni oggetto non deve avere un campo denominato
op. Questo campo è solo per le query.
- Ogni oggetto deve avere un campo denominato
Di seguito sono riportati due record di esempio in formato JSON:
[
{
"id": "42",
"embedding": [
0.5,
1
],
"numeric_restricts": [
{
"namespace": "size",
"value_int": 3
},
{
"namespace": "ratio",
"value_float": 0.1
}
]
},
{
"id": "43",
"embedding": [
0.6,
1
],
"sparse_embedding": {
"values": [
0.1,
0.2
],
"numeric_restricts": [
{
"namespace": "weight",
"value_double": 0.3
}
]
}
}
]
Avro
I record Avro utilizzano lo schema seguente:
{
"type": "record",
"name": "FeatureVector",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "embedding",
"type": {
"type": "array",
"items": "float"
}
},
{
"name": "sparse_embedding",
"type": [
"null",
{
"type": "record",
"name": "sparse_embedding",
"fields": [
{
"name": "values",
"type": {
"type": "array",
"items": "float"
}
},
{
"name": "dimensions",
"type": {
"type": "array",
"items": "long"
}
}
]
}
]
},
{
"name": "restricts",
"type": [
"null",
{
"type": "array",
"items": {
"type": "record",
"name": "Restrict",
"fields": [
{
"name": "namespace",
"type": "string"
},
{
"name": "allow",
"type": [
"null",
{
"type": "array",
"items": "string"
}
]
},
{
"name": "deny",
"type": [
"null",
{
"type": "array",
"items": "string"
}
]
}
]
}
}
]
},
{
"name": "numeric_restricts",
"type": [
"null",
{
"type": "array",
"items": {
"name": "NumericRestrict",
"type": "record",
"fields": [
{
"name": "namespace",
"type": "string"
},
{
"name": "value_int",
"type": [ "null", "int" ],
"default": null
},
{
"name": "value_float",
"type": [ "null", "float" ],
"default": null
},
{
"name": "value_double",
"type": [ "null", "double" ],
"default": null
}
]
}
}
],
"default": null
},
{
"name": "crowding_tag",
"type": [
"null",
"string"
]
}
]
}
CSV
Limitazioni token
Per ogni record del vettore, aggiungi coppie separate da virgole nel formato
name=valueper specificare le limitazioni dello spazio dei nomi dei token. Lo stesso nome può essere ripetuto se sono presenti più valori in uno spazio dei nomi.Ad esempio,
color=red,color=bluerappresenta questoTokenNamespace:{ "namespace": "color" "string_tokens": ["red", "blue"] }Per ogni record del vettore, aggiungi coppie separate da virgole nel formato
name=!valueper specificare il valore escluso per le limitazioni dello spazio dei nomi dei token.Ad esempio,
color=!redrappresenta questoTokenNamespace:{ "namespace": "color" "string_blacklist_tokens": ["red"] }
Limitazioni numeriche
Per ogni record del vettore, aggiungi coppie separate da virgole nel formato
#name=numericValuecon il suffisso del tipo di numero per specificare le restrizioni dello spazio dei nomi numerico.Il suffisso del tipo di numero è
iper int,fper float edper double. Lo stesso nome non deve essere ripetuto, in quanto deve essere associato un solo valore per spazio dei nomi.Ad esempio,
#size=3irappresenta questoNumericRestrictNamespace:{ "namespace": "size" "value_int": 3 }#ratio=0.1frappresenta questoNumericRestrictNamespace:{ "namespace": "ratio" "value_float": 0.1 }#weight=0.3drappresenta questoNumericRestriction:{ "namespace": "weight" "value_double": 0.3 }Ecco un esempio di punto dati con
id: "6",embedding: [7, -8.1],sparse_embedding: {values: [0.1, -0.2, 0.5],dimensions: [40, 901, 1111]}}, tag di affollamentotest, lista consentita di tokencolor: red, blue, lista bloccata di tokencolor: purplee limite numericoratiocon numero in virgola mobile0.1:6,7,-8.1,40:0.1,901:-0.2,1111:0.5,crowding_tag=test,color=red,color=blue,color=!purple, ratio=0.1f