Os fluxos de trabalho tabulares são um conjunto de pipelines integrados, totalmente gerenciados e escalonáveis para ML de ponta a ponta com dados tabulares. Esse conjunto usa a tecnologia do Google para o desenvolvimento de modelos e fornece opções de personalização para atender às suas necessidades.
Benefícios
- Totalmente gerenciado: você não precisa se preocupar com atualizações, dependências e conflitos.
- Fácil escalonamento: não é necessário reestruturar a infraestrutura à medida que as cargas de trabalho ou os conjuntos de dados aumentam.
- Otimizado para melhor desempenho: o hardware certo é configurado automaticamente para os requisitos do fluxo de trabalho.
- Totalmente integrado: oferece suporte aos produtos do pacote MLOps da Vertex AI, como os Pipelines da Vertex AI e os Experimentos da Vertex AI, e permite executar muitos experimentos em um curto período.
Visão geral técnica
Cada fluxo de trabalho é uma instância gerenciada do Vertex AI Pipelines.
O Vertex AI Pipelines é um serviço sem servidor que executa pipelines do Kubeflow. É possível usar pipelines para automatizar e monitorar suas tarefas de machine learning e de preparação de dados. Cada etapa em um pipeline executa parte do fluxo de trabalho do pipeline. Por exemplo, um pipeline pode incluir etapas para dividir dados, transformar tipos de dados e treinar um modelo. Como as etapas são instâncias de componentes do pipeline, as etapas têm entradas, saídas e uma imagem de contêiner. As entradas de etapa podem ser definidas nas entradas do pipeline ou elas podem depender da saída de outras etapas dentro do pipeline. Essas dependências definem o fluxo de trabalho do pipeline como um gráfico acíclico dirigido.
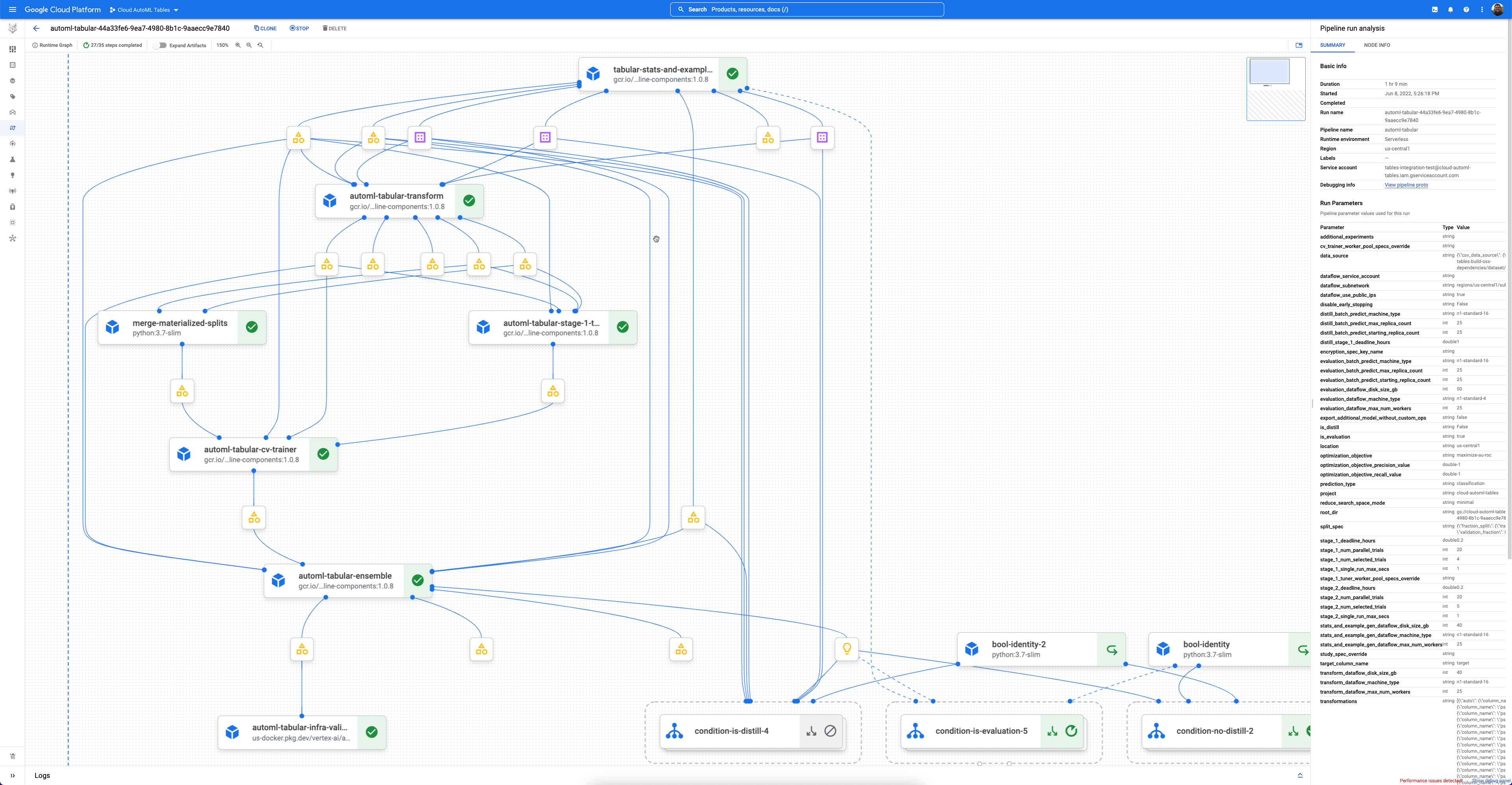
Primeiros passos
Na maioria dos casos, defina e execute o pipeline usando o SDK de componentes de pipeline doGoogle Cloud . O exemplo de código a seguir ilustra esse processo. A implementação real do código pode ser diferente.
// Define the pipeline and the parameters
template_path, parameter_values = tabular_utils.get_default_pipeline_and_parameters(
…
optimization_objective=optimization_objective,
data_source=data_source,
target_column_name=target_column_name
…)
// Run the pipeline
job = pipeline_jobs.PipelineJob(..., template_path=template_path, parameter_values=parameter_values)
job.run(...)
Para amostras de colabs e notebooks, entre em contato com seu representante de vendas ou preencha um formulário de solicitação.
Controle de versões e manutenção
Os fluxos de trabalho tabulares têm um sistema de controle de versões eficaz que permite atualizações e melhorias contínuas sem alterações interruptivas nos aplicativos.
Cada fluxo de trabalho é lançado e atualizado como parte do SDK de componentes do pipeline doGoogle Cloud . As atualizações e modificações de qualquer fluxo de trabalho são lançadas como novas versões desse fluxo de trabalho. As versões anteriores de cada fluxo de trabalho estão sempre disponíveis pelas versões mais antigas do SDK. Se a versão do SDK estiver fixada, a versão do fluxo de trabalho também será fixada.
Fluxos de trabalho disponíveis
A Vertex AI fornece os fluxos de trabalho tabulares a seguir:
| Nome | Tipo | Disponibilidade |
|---|---|---|
| Feature Transform Engine | Engenharia de atributos | Prévia pública |
| End to End AutoML | Classificação e regressão | Disponibilidade geral |
| TabNet | Classificação e regressão | Prévia pública |
| Amplitude e profundidade | Classificação e regressão | Prévia pública |
| Previsão | Previsão | Prévia pública |
Para mais informações e amostras de notebooks, entre em contato com seu representante de vendas ou preencha um formulário de solicitação.
Feature Transform Engine
O Feature Transform Engine realiza a seleção de atributos e as transformações de atributos. Se a seleção de atributos estiver ativada, o Feature Transform Engine vai criar um conjunto classificado de recursos importantes. Se as transformações de atributos estiverem ativadas, o Feature Transform Engine processará os atributos para garantir que a entrada do treinamento e da disponibilização do modelo seja consistente. O Feature Transform Engine pode ser usado sozinho ou com qualquer um dos fluxos de trabalho de treinamento tabulares. Ele é compatível com o TensorFlow e frameworks que não são do TensorFlow.
Para mais informações, consulte Engenharia de atributos.
Fluxos de trabalho tabulares para classificação e regressão
Fluxo de trabalho tabular para o AutoML de ponta a ponta
O fluxo de trabalho tabular para o AutoML de ponta a ponta é um pipeline completo do AutoML para tarefas de classificação e regressão. Ele é semelhante à API AutoML, mas permite que você escolha o que controlar e o que automatizar. Em vez de ter controles para o pipeline inteiro, você tem controles para cada etapa no pipeline. Esses controles de pipeline incluem o seguinte:
- Divisão de dados
- Engenharia de atributos
- Pesquisa de arquitetura
- Treinamento de modelo
- Conjunto de modelos
- Destilação de modelo
Benefícios
- Suporta grandes conjuntos de dados com vários TB de tamanho e até 1.000 colunas.
- Permite melhorar a estabilidade e reduzir o tempo de treinamento limitando o espaço de pesquisa de tipos de arquitetura ou pulando a pesquisa de arquitetura.
- Permite melhorar a velocidade do treinamento selecionando manualmente o hardware usado para pesquisa de treinamento e arquitetura.
- Permite reduzir o tamanho do modelo e melhorar a latência com destilação ou mudando o tamanho do ensemble.
- Cada componente do AutoML pode ser inspecionado em uma ótima interface de gráfico de pipelines que permite ver as tabelas de dados transformadas, as arquiteturas de modelos avaliadas e muitos outros detalhes.
- Os componentes do AutoML têm mais flexibilidade e transparência, como personalização de parâmetros, hardware, status do processo de visualização, registros e muito mais.
Entrada/Saída
- Usa uma tabela do BigQuery ou um arquivo CSV do Cloud Storage como entrada.
- Produz um modelo Vertex AI como saída.
- As saídas intermediárias incluem estatísticas e divisões de conjuntos de dados.
Para mais informações, consulte Fluxo de trabalho tabular para AutoML de ponta a ponta.
Fluxo de trabalho tabular para TabNet
O fluxo de trabalho tabular para treinamento do TabNet é um pipeline que pode ser usado para treinar modelos de classificação ou regressão. A TabNet usa a atenção sequencial para escolher quais recursos usar em cada etapa de decisão. Isso promove interpretabilidade e aprendizado mais eficiente, porque a capacidade de aprendizado é usada para os atributos mais significativos.
Vantagens
- Seleciona automaticamente o espaço de pesquisa de hiperparâmetros adequado com base no tamanho do conjunto de dados, no tipo de inferência e no orçamento de treinamento.
- Integrado com a Vertex AI. O modelo treinado é um modelo da Vertex AI. Você pode executar inferências em lote ou implantar o modelo para inferências on-line imediatamente.
- Fornece a interpretabilidade inerente do modelo. É possível receber insights sobre quais atributos a TabNet usou para tomar a decisão.
- Oferece suporte ao treinamento de GPUs.
Entrada/Saída
Usa uma tabela do BigQuery ou um arquivo CSV do Cloud Storage como entrada e fornece um modelo da Vertex AI como saída.
Para mais informações, consulte Fluxo de trabalho tabular para TabNet.
Fluxo de trabalho tabular para amplo e profundo
O fluxo de trabalho tabular para treinamento amplo e profundo é um pipeline que pode ser usado para treinar modelos de classificação ou regressão. O modelo profundo e amplo treina em conjunto modelos lineares amplos e redes neurais profundas. Ele combina os benefícios de memorização e generalização. Em alguns experimentos on-line, os resultados mostraram que o modelo profundo e amplo aumentou significativamente aquisições de aplicativos da Google Store em comparação com os modelos somente amplos e somente profundos.
Benefícios
- Integrado com a Vertex AI. O modelo treinado é um modelo da Vertex AI. Você pode executar inferências em lote ou implantar o modelo para inferências on-line imediatamente.
Entrada/Saída
Usa uma tabela do BigQuery ou um arquivo CSV do Cloud Storage como entrada e fornece um modelo da Vertex AI como saída.
Saiba mais em Fluxo de trabalho tabular para treinamento amplo e profundo.
Fluxos de trabalho tabulares para previsão
Fluxo de trabalho tabular para previsão
O fluxo de trabalho tabular para previsão é o pipeline completo para tarefas de previsão. Ele é semelhante à API AutoML, mas permite que você escolha o que controlar e o que automatizar. Em vez de ter controles para o pipeline inteiro, você tem controles para cada etapa no pipeline. Esses controles de pipeline incluem o seguinte:
- Divisão de dados
- Engenharia de atributos
- Pesquisa de arquitetura
- Treinamento de modelo
- Conjunto de modelos
Benefícios
- Suporta conjuntos de dados grandes com tamanho de até 1 TB e até 200 colunas.
- Permite melhorar a estabilidade e reduzir o tempo de treinamento limitando o espaço de pesquisa de tipos de arquitetura ou pulando a pesquisa de arquitetura.
- Permite melhorar a velocidade do treinamento selecionando manualmente o hardware usado para pesquisa de treinamento e arquitetura.
- Permite reduzir o tamanho do modelo e melhorar a latência mudando o tamanho do conjunto.
- Cada componente pode ser inspecionado em uma ótima interface de gráfico de pipelines que permite ver as tabelas de dados transformadas, as arquiteturas de modelos avaliadas e muitos outros detalhes.
- Os componentes têm mais flexibilidade e transparência, como personalização de parâmetros, hardware, status do processo de visualização, registros e muito mais.
Entrada/Saída
- Usa uma tabela do BigQuery ou um arquivo CSV do Cloud Storage como entrada.
- Produz um modelo Vertex AI como saída.
- As saídas intermediárias incluem estatísticas e divisões de conjuntos de dados.
Para mais informações, consulte Fluxo de trabalho tabular para previsão.
A seguir
- Saiba mais sobre o fluxo de trabalho tabular para o AutoML End-to-End.
- Saiba mais sobre o Fluxo de trabalho tabular para o TabNet.
- Saiba mais sobre o fluxo de trabalho tabular para largura e profundidade.
- Saiba mais sobre o Fluxo de trabalho tabular para previsão.
- Saiba mais sobre engenharia de atributos.
- Saiba mais sobre Preços de fluxos de trabalho tabulares.