Auf dieser Seite wird beschrieben, wie Sie die Ergebnisse von Model Monitoring-Jobs für Modelle erstellen, verwalten und interpretieren, die auf Onlinevorhersage-Endpunkten bereitgestellt werden. Vertex AI Model Monitoring unterstützt die Erkennung von Merkmalsabweichungen und Driften für kategoriale und numerische Eingabefeatures.
Wenn ein Modell mit aktiviertem Model Monitoring in Produktion ist, werden die eingehenden Vorhersageanfragen in einer BigQuery-Tabelle in Ihrem Google Cloud -Projekt protokolliert. Die in den protokollierten Anfragen enthaltenen Eingabemerkmalswerte werden dann auf Abweichungen oder Drift analysiert.
Sie können die Abweichungserkennung aktivieren, wenn Sie das ursprüngliche Trainings-Dataset für Ihr Modell angeben. Andernfalls sollten Sie die Drift-Erkennung aktivieren. Weitere Informationen finden Sie unter Einführung in Vertex AI Model Monitoring.
Vorbereitung
So verwenden Sie die Modellüberwachung:
Sie haben in Vertex AI ein verfügbares Modell, das entweder ein tabellarisches AutoML-Modell oder ein importiertes benutzerdefiniertes Trainingsmodell ist.
- Achten Sie bei Verwendung eines vorhandenen Endpunkts darauf, dass alle unter dem Endpunkt bereitgestellte Modelle tabellarische AutoML- oder importierte benutzerdefinierte Trainingstypen sind.
Wenn Sie die Abweichungserkennung aktivieren, laden Sie Ihre Trainingsdaten in Cloud Storage oder BigQuery hoch und rufen Sie den URI-Link zu den Daten ab. Für die Drifterkennung sind Trainingsdaten nicht erforderlich.
Optional: Für benutzerdefiniert trainierte Modelle laden Sie das Analyseinstanzschema für Ihr Modell in Cloud Storage hoch. Für das Modell-Monitoring muss das Schema den Monitoring-Prozess starten und die Basisverteilung zur Verzerrungserkennung berechnen. Wenn Sie das Schema während der Joberstellung nicht angeben, verbleibt der Job im Status "Ausstehend", bis das Modellmonitoring das Schema aus den ersten 1.000 Vorhersageanfragen, die das Modell empfängt, automatisch parsen kann.
Model Monitoring-Job erstellen
Erstellen Sie einen Monitoring-Job für die Modellbereitstellung, um die Erkennung von Abweichungen oder die Drifterkennung einzurichten:
Console
Erstellen Sie einen vorhandenen Endpunkt, um mithilfe der Google Cloud Console einen Monitoring-Job zur Modellbereitstellung zu erstellen:
Rufen Sie in der Google Cloud Console die Seite Vertex AI Endpoints auf.
Klicken Sie auf Endpunkt erstellen.
Geben Sie im Bereich Neuer Endpunkt einen Namen für den Endpunkt ein und legen Sie eine Region fest.
Klicken Sie auf Weiter.
Wählen Sie im Feld Modellname ein importiertes benutzerdefiniertes Trainingsmodell oder ein tabellarisches AutoML-Modell aus.
Wählen Sie im Feld Version eine Version für Ihr Modell aus.
Klicken Sie auf Weiter.
Achten Sie darauf, dass im Bereich Modellmonitoring die Option Modell-Monitoring für diesen Endpunkt aktivieren aktiviert ist. Alle von Ihnen konfigurierten Monitoring-Einstellungen gelten für alle Modelle, die auf dem Endpunkt bereitgestellt werden.
Geben Sie einen Anzeigenamen des Monitoring-Jobs ein.
Geben Sie eine Länge des Monitoringfensters ein.
Geben Sie unter Benachrichtigungs-E-Mails eine oder mehrere durch Kommas getrennte E-Mail-Adressen ein, um Benachrichtigungen zu erhalten, wenn ein Modell einen Benachrichtigungsgrenzwert überschreitet.
Optional: Fügen Sie unter Benachrichtigungskanäle Cloud Monitoring-Kanäle hinzu, um Benachrichtigungen zu erhalten, wenn ein Modell einen Benachrichtigungsgrenzwert überschreitet. Sie können vorhandene Cloud Monitoring-Kanäle auswählen oder neue erstellen. Klicken Sie dazu auf Benachrichtigungskanäle verwalten. Die Console unterstützt PagerDuty-, Slack- und Pub/Sub-Benachrichtigungskanäle.
Geben Sie eine Abtastrate ein.
Optional: Geben Sie das Eingabeschema für die Vorhersage und das Eingabeschema für die Analyse ein.
Klicken Sie auf Weiter. Der Bereich Monitoring-Ziel wird mit Optionen zur Erkennung von Abweichungen oder Drifts geöffnet:
Abweichungserkennung
- Wählen Sie Erkennung von Abweichungen zwischen Training und Bereitstellung aus.
- Geben Sie unter Trainingsdatenquelle eine Trainingsdatenquelle an.
- Geben Sie unter Zielspalte den Spaltennamen aus den Trainingsdaten ein, für die das Modell trainiert werden soll. Dieses Feld ist aus der Monitoringanalyse ausgeschlossen.
- Optional: Geben Sie unter Benachrichtigungsgrenzwerte Grenzwerte an, ab denen Benachrichtigungen ausgelöst werden sollen. Informationen zum Formatieren der Grenzwerte erhalten Sie, wenn Sie den Mauszeiger auf das Hilfesymbol bewegen.
- Klicken Sie auf Erstellen.
Drifterkennung
- Wählen Sie die Erkennung des Vorhersage-Drifts aus.
- Optional: Geben Sie unter Benachrichtigungsgrenzwerte Grenzwerte an, ab denen Benachrichtigungen ausgelöst werden sollen. Informationen zum Formatieren der Grenzwerte erhalten Sie, wenn Sie den Mauszeiger auf das Hilfesymbol bewegen.
- Klicken Sie auf Erstellen.
gcloud
Wenn Sie einen Monitoring-Job für die Modellbereitstellung mit der gcloud CLI erstellen möchten, stellen Sie Ihr Modell zuerst auf einem Endpunkt bereit.
Die Konfiguration eines Monitoring-Jobs gilt für alle bereitgestellten Modelle unter einem Endpunkt.
Führen Sie den Befehl gcloud ai model-monitoring-jobs create aus.
gcloud ai model-monitoring-jobs create \ --project=PROJECT_ID \ --region=REGION \ --display-name=MONITORING_JOB_NAME \ --emails=EMAIL_ADDRESS_1,EMAIL_ADDRESS_2 \ --endpoint=ENDPOINT_ID \ [--feature-thresholds=FEATURE_1=THRESHOLD_1, FEATURE_2=THRESHOLD_2] \ [--prediction-sampling-rate=SAMPLING_RATE] \ [--monitoring-frequency=MONITORING_FREQUENCY] \ [--analysis-instance-schema=ANALYSIS_INSTANCE_SCHEMA] \ --target-field=TARGET_FIELD \ --bigquery-uri=BIGQUERY_URI
Dabei gilt:
PROJECT_ID ist die ID Ihres Google Cloud Projekts. Beispiel:
my-project.REGION ist der Speicherort für Ihren Monitoring-Job. Beispiel:
us-central1MONITORING_JOB_NAME ist der Name Ihres Monitoring-Jobs. Beispiel:
my-jobEMAIL_ADDRESS ist die E-Mail-Adresse, an die Sie Benachrichtigungen von Modell-Monitoring erhalten möchten. Beispiel:
example@example.comENDPOINT_ID ist der Name des Endpunkts, unter dem Ihr Modell bereitgestellt wird. Beispiel:
1234567890987654321.Optional: FEATURE_1=THRESHOLD_1 ist der Schwellenwert für Benachrichtigungen für jedes Feature, das Sie überwachen möchten. Wenn Sie beispielsweise
Age=0.4angeben, protokolliert Modell-Monitoring eine Benachrichtigung, wenn die statistische Entfernung zwischen den Eingabe- und Referenzverteilungen für das FeatureAge0,4 überschreitet. Standardmäßig wird jedes kategoriale und numerische Feature mit Grenzwerten von 0,3 überwacht.Optional: SAMPLING_RATE ist der Anteil der eingehenden Vorhersageanfragen, die Sie protokollieren möchten. Beispiel:
0.5. Wenn nicht angegeben, protokolliert Model Monitoring alle Vorhersageanfragen.Optional: MONITORING_FREQUENCY ist die Häufigkeit, mit der der Monitoringjob mit kürzlich protokollierten Eingaben ausgeführt werden soll. Die Mindestgranularität beträgt 1 Stunde. Der Standardwert ist 24 Stunden. Beispiel:
2.Optional: ANALYSIS_INSTANCE_SCHEMA ist der Cloud Storage-URI für die Schemadatei, die das Format Ihrer Eingabedaten beschreibt. Beispiel:
gs://test-bucket/schema.yaml(Nur für die Abweichungserkennung erforderlich) TARGET_FIELD ist das Feld, das vom Modell vorhergesagt wird. Dieses Feld ist aus der Monitoringanalyse ausgeschlossen. Beispiel:
housing-price.(Nur für die Abweichungserkennung erforderlich) BIGQUERY_URI ist der Link zum in BigQuery gespeicherten Trainings-Dataset im folgenden Format:
bq://\PROJECT.\DATASET.\TABLE
z. B.
bq://\my-project.\housing-data.\san-francisco.Sie können das Flag
bigquery-uridurch alternative Links zu Ihrem Trainings-Dataset ersetzen:Verwenden Sie
--data-format=csv --gcs-uris=gs://BUCKET_NAME/OBJECT_NAMEfür eine in einem Cloud Storage-Bucket gespeicherte CSV-Datei.Verwenden Sie
--data-format=tf-record --gcs-uris=gs://BUCKET_NAME/OBJECT_NAMEfür eine TFRecord-Datei, die in einem Cloud Storage-Bucket gespeichert ist.Verwenden Sie für ein verwaltetes AutoML-Dataset
--dataset=DATASET_ID.
Python SDK
Informationen zum vollständigen End-to-End-Model Monitoring API-Workflow finden Sie im Beispielnotebook.
REST API
Stellen Sie das Modell auf einem Endpunkt bereit, falls noch nicht geschehen. Notieren Sie sich während des Schritts Endpunkt-ID abrufen in der Anleitung zur Modellbereitstellung den Wert
deployedModels.idin der JSON-Antwort für die spätere Verwendung:Erstellen Sie eine Anfrage für einen Model Monitoring-Job. In der folgenden Anleitung wird gezeigt, wie Sie einen einfachen Monitoring-Job zur Drifterkennung erstellen. Informationen zum Anpassen der JSON-Anfrage finden Sie in der Referenz zu Monitoring-Jobs.
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- PROJECT_ID ist die ID Ihres Google Cloud -Projekts. Beispiel:
my-project. - LOCATION ist der Speicherort für Ihren Monitoring-Job. Beispiel:
us-central1. - MONITORING_JOB_NAME ist der Name Ihres Monitoring-Jobs. Beispiel:
my-job. - PROJECT_NUMBER: die Nummer für Ihr Google Cloud -Projekt. Beispiel:
1234567890. - ENDPOINT_ID ist die ID des Endpunkts, auf dem Ihr Modell bereitgestellt wird. Beispiel:
1234567890. - DEPLOYED_MODEL_ID ist Die ID für das bereitgestellte Modell.
- FEATURE:VALUE ist der Schwellenwert für Benachrichtigungen für jedes Feature, das Sie überwachen möchten. Wenn Sie beispielsweise
"Age": {"value": 0.4}angeben, protokolliert das Modell-Monitoring eine Benachrichtigung, wenn die statistische Entfernung zwischen den Eingabe- und Referenzverteilungen für dasAge-Feature 0,4 überschreitet. Standardmäßig wird jedes kategoriale und numerische Feature mit Grenzwerten von 0,3 überwacht. - EMAIL_ADDRESS ist die E-Mail-Adresse, an die Sie Benachrichtigungen von Model Monitoring erhalten möchten. Beispiel:
example@example.com. - NOTIFICATION_CHANNELS: Eine Liste der Cloud Monitoring-Benachrichtigungskanäle, in denen Sie Benachrichtigungen von Model Monitoring erhalten möchten. Verwenden Sie die Ressourcennamen für die Benachrichtigungskanäle, die Sie durch Auflisten der Benachrichtigungskanäle in Ihrem Projekt abrufen können. Beispiel:
"projects/my-project/notificationChannels/1355376463305411567", "projects/my-project/notificationChannels/1355376463305411568" - Optional: ANALYSIS_INSTANCE_SCHEMA ist der Cloud Storage-URI für die Schemadatei, die das Format Ihrer Eingabedaten beschreibt. Beispiel:
gs://test-bucket/schema.yaml.
JSON-Text der Anfrage:
{ "displayName":"MONITORING_JOB_NAME", "endpoint":"projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID", "modelDeploymentMonitoringObjectiveConfigs": { "deployedModelId": "DEPLOYED_MODEL_ID", "objectiveConfig": { "predictionDriftDetectionConfig": { "driftThresholds": { "FEATURE_1": { "value": VALUE_1 }, "FEATURE_2": { "value": VALUE_2 } } }, }, }, "loggingSamplingStrategy": { "randomSampleConfig": { "sampleRate": 0.5, }, }, "modelDeploymentMonitoringScheduleConfig": { "monitorInterval": { "seconds": 3600, }, }, "modelMonitoringAlertConfig": { "emailAlertConfig": { "userEmails": ["EMAIL_ADDRESS"], }, "notificationChannels": [NOTIFICATION_CHANNELS] }, "analysisInstanceSchemaUri": ANALYSIS_INSTANCE_SCHEMA }Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{ "name": "projects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_NUMBER", ... "state": "JOB_STATE_PENDING", "scheduleState": "OFFLINE", ... "bigqueryTables": [ { "logSource": "SERVING", "logType": "PREDICT", "bigqueryTablePath": "bq://PROJECT_ID.model_deployment_monitoring_8451189418714202112.serving_predict" } ], ... }- PROJECT_ID ist die ID Ihres Google Cloud -Projekts. Beispiel:
Nachdem der Monitoring-Job erstellt wurde, erfasst die Modellüberwachung eingehende Vorhersageanfragen in einer generierten BigQuery-Tabelle mit dem Namen PROJECT_ID.model_deployment_monitoring_ENDPOINT_ID.serving_predict.
Wenn das Anfrage-/Antwort-Logging aktiviert ist, protokolliert die Modellüberwachung eingehende Anfragen in derselben BigQuery-Tabelle, die für das Anfrage-/Antwort-Logging verwendet wird.
(Optional) Benachrichtigungen für den Model Monitoring-Job konfigurieren
Sie können Ihren Modellmonitoringjob durch Benachrichtigungen beobachten und Fehler beheben. Sie werden von Model Monitoring automatisch per E-Mail über Jobaktualisierungen benachrichtigt. Sie können jedoch auch Benachrichtigungen über Cloud Logging- und Cloud Monitoring-Benachrichtigungskanäle einrichten.
Bei den folgenden Ereignissen sendet Model Monitoring eine E-Mail-Benachrichtigung an jede E-Mail-Adresse, die beim Erstellen des Model Monitoring-Jobs angegeben wurde:
- Jedes Mal, wenn Abweichungs- oder Drifterkennung eingerichtet wird
- Jedes Mal, wenn eine vorhandene Konfiguration eines Model Monitoring-Jobs aktualisiert wird
- Jedes Mal, wenn die geplante Ausführung einer Monitoring-Pipeline fehlschlägt.
Cloud Logging
Setzen Sie das Feld enableMonitoringPipelineLogs in der Konfiguration von modelDeploymentMonitoringJobs auf true, um Logs für geplante Ausführungen von Monitoring-Pipelines zu aktivieren. Debugging-Logs werden in Cloud Logging geschrieben, wenn der Monitoringjob eingerichtet wird und in jedem Monitoring-Intervall.
Die Debugging-Logs werden mit dem Lognamen in Cloud Logging geschrieben: model_monitoring. Beispiel:
logName="projects/model-monitoring-demo/logs/aiplatform.googleapis.com%2Fmodel_monitoring" resource.labels.model_deployment_monitoring_job=6680511704087920640
Hier ein Beispiel für einen Logeintrag zum Jobfortschritt:
{ "insertId": "e2032791-acb9-4d0f-ac73-89a38788ccf3@a1", "jsonPayload": { "@type": "type.googleapis.com/google.cloud.aiplatform.logging.ModelMonitoringPipelineLogEntry", "statusCode": { "message": "Scheduled model monitoring pipeline finished successfully for job projects/677687165274/locations/us-central1/modelDeploymentMonitoringJobs/6680511704087920640" }, "modelDeploymentMonitoringJob": "projects/677687165274/locations/us-central1/modelDeploymentMonitoringJobs/6680511704087920640" }, "resource": { "type": "aiplatform.googleapis.com/ModelDeploymentMonitoringJob", "labels": { "model_deployment_monitoring_job": "6680511704087920640", "location": "us-central1", "resource_container": "projects/677687165274" } }, "timestamp": "2022-02-04T15:33:54.778883Z", "severity": "INFO", "logName": "projects/model-monitoring-demo/logs/staging-aiplatform.sandbox.googleapis.com%2Fmodel_monitoring", "receiveTimestamp": "2022-02-04T15:33:56.343298321Z" }
Benachrichtigungskanäle
Jedes Mal, wenn die geplante Ausführung einer Monitoring-Pipeline fehlschlägt, sendet Model Monitoring eine Benachrichtigung an die Cloud Monitoring-Benachrichtigungskanäle, die Sie beim Erstellen des Model Monitoring-Jobs angegeben haben.
Benachrichtigungen für Featureanomalien konfigurieren
Die Modellüberwachung erkennt eine Anomalie, wenn der für ein Feature festgelegte Schwellenwert überschritten wird. Sie werden von Model Monitoring automatisch per E-Mail über erkannte Anomalien benachrichtigt. Sie können jedoch auch Benachrichtigungen über Cloud Logging- und Cloud Monitoring-Benachrichtigungskanäle einrichten.
Wenn der Grenzwert von mindestens einem Feature den Grenzwert in jedem Monitoring-Intervall überschreitet, sendet Model Monitoring eine E-Mail-Benachrichtigung an jede E-Mail-Adresse, die beim Erstellen des Model Monitoring-Jobs angegeben wurde. Die E-Mail enthält Folgendes:
- Der Zeitpunkt, zu dem der Monitoring-Job ausgeführt wurde
- Der Name des Merkmals, das verzerrt oder verschoben ist
- Der Schwellenwert für die Benachrichtigung sowie die erfasste statistische Entfernungsmessung
Cloud Logging
Zum Aktivieren von Cloud Logging-Benachrichtigungen setzen Sie das Feld enableLogging Ihrer ModelMonitoringAlertConfig-Konfiguration auf true.
In jedem Monitoring-Intervall wird ein Anomalielog in Cloud Logging geschrieben, wenn die Verteilung von mindestens einem Feature den Schwellenwert für dieses Feature überschreitet. Sie können Logs an jeden Dienst weiterleiten, der von Cloud Logging unterstützt wird, z. B. Pub/Sub.
Anomalien werden in Cloud Logging mit dem Lognamen geschrieben: model_monitoring_anomaly. Beispiel:
logName="projects/model-monitoring-demo/logs/aiplatform.googleapis.com%2Fmodel_monitoring_anomaly" resource.labels.model_deployment_monitoring_job=6680511704087920640
Hier ein Beispiel für einen Anomalie-Logeintrag:
{ "insertId": "b0e9c0e9-0979-4aff-a5d3-4c0912469f9a@a1", "jsonPayload": { "anomalyObjective": "RAW_FEATURE_SKEW", "endTime": "2022-02-03T19:00:00Z", "featureAnomalies": [ { "featureDisplayName": "age", "deviation": 0.9, "threshold": 0.7 }, { "featureDisplayName": "education", "deviation": 0.6, "threshold": 0.3 } ], "totalAnomaliesCount": 2, "@type": "type.googleapis.com/google.cloud.aiplatform.logging.ModelMonitoringAnomaliesLogEntry", "startTime": "2022-02-03T18:00:00Z", "modelDeploymentMonitoringJob": "projects/677687165274/locations/us-central1/modelDeploymentMonitoringJobs/6680511704087920640", "deployedModelId": "1645828169292316672" }, "resource": { "type": "aiplatform.googleapis.com/ModelDeploymentMonitoringJob", "labels": { "model_deployment_monitoring_job": "6680511704087920640", "location": "us-central1", "resource_container": "projects/677687165274" } }, "timestamp": "2022-02-03T19:00:00Z", "severity": "WARNING", "logName": "projects/model-monitoring-demo/logs/staging-aiplatform.sandbox.googleapis.com%2Fmodel_monitoring_anomaly", "receiveTimestamp": "2022-02-03T19:59:52.121398388Z" }
Benachrichtigungskanäle
Wenn der Grenzwert von mindestens einem Feature den Grenzwert in jedem Monitoring-Intervall überschreitet, sendet Model Monitoring eine Benachrichtigung an die Cloud Monitoring-Benachrichtigungskanäle, die Sie beim Erstellen des Model Monitoring-Jobs angegeben haben. Die Benachrichtigung enthält Informationen zum Modellmonitoringjob, der die Benachrichtigung ausgelöst hat.
Modell-Monitoring-Job aktualisieren
Sie können einen Modellmonitoringjob anzeigen, aktualisieren, pausieren und löschen. Sie müssen einen Job pausieren, bevor Sie ihn löschen können.
Console
Das Pausieren und Löschen wird in der Google Cloud Console nicht unterstützt. Verwenden Sie stattdessen die gcloud CLI.
So aktualisieren Sie Parameter für einen Model Monitoring-Job:
Rufen Sie in der Google Cloud Console die Seite Vertex AI Endpoints auf.
Klicken Sie auf den Namen des Endpunkts, den Sie bearbeiten möchten.
Klicken Sie auf Einstellungen bearbeiten.
Wählen Sie im Bereich Endpunkt bearbeiten die Option Modellmonitoring oder Monitoringziele aus.
Aktualisieren Sie die Felder, die Sie ändern möchten.
Klicken Sie auf Aktualisieren.
So rufen Sie Messwerte, Benachrichtigungen und Monitoring-Attribute für ein Modell auf:
Rufen Sie in der Google Cloud Console die Seite Vertex AI Endpoints auf.
Klicken Sie auf den Namen des Endpunkts.
Klicken Sie in der Spalte Monitoring für das Modell, das Sie aufrufen möchten, auf Aktiviert.
gcloud
Führen Sie dazu diesen Befehl aus:
gcloud ai model-monitoring-jobs COMMAND MONITORING_JOB_ID \ --PARAMETER=VALUE --project=PROJECT_ID --region=LOCATION
Dabei gilt:
COMMAND ist der Befehl, den Sie für den Monitoring-Job ausführen möchten. Beispiel:
update,pause,resumeoderdelete. Weitere Informationen finden Sie in der Referenz zur gcloud-Befehlszeile.MONITORING_JOB_ID ist die ID Ihres Monitoring-Jobs. Beispiel:
123456789Sie finden die ID, indem Sie die Endpunktinformationen abrufen [retrieve-id] abrufen oder Monitoring-Attribute für ein Modell in der Google Cloud -Konsole aufrufen. Die ID ist im Namen der Monitoringjob-Ressource im Formatprojects/PROJECT_NUMBER/locations/LOCATION/modelDeploymentMonitoringJobs/MONITORING_JOB_IDenthalten.(Optional) PARAMETER=VALUE ist der Parameter, den Sie aktualisieren möchten. Dieses Flag ist nur erforderlich, wenn Sie den Befehl
updateverwenden. Beispiel:monitoring-frequency=2. Eine Liste der Parameter, die Sie aktualisieren können, finden Sie in der Referenz zur gcloud CLI.PROJECT_ID ist die ID für Ihr Google Cloud Projekt. Beispiel:
my-project.LOCATION ist der Speicherort für Ihren Monitoring-Job. Beispiel:
us-central1
REST API
Job anhalten
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- PROJECT_NUMBER: Die Nummer Ihres Google Cloud -Projekts. Beispiel:
1234567890. - LOCATION: Speicherort für Ihren Monitoringjob. Beispiel:
us-central1. - MONITORING_JOB_ID: ID Ihres Monitoringjobs. Beispiel:
0987654321.
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{}
Job löschen
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- PROJECT_NUMBER: Die Nummer Ihres Google Cloud -Projekts. Beispiel:
my-project. - LOCATION: Speicherort für Ihren Monitoringjob. Beispiel:
us-central1. - MONITORING_JOB_ID: ID Ihres Monitoringjobs. Beispiel:
0987654321.
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/operations/MONITORING_JOB_ID",
...
"done": true,
...
}
Abweichungs- und Driftdaten analysieren
Sie können die Google Cloud Console verwenden, um die Verteilungen der einzelnen überwachten Features zu visualisieren und zu ermitteln, welche Änderungen zu einer Abweichung oder einem Drift geführt haben. Sie können die Verteilung der Featurewerte als Histogramm anzeigen.
Console
Rufen Sie in derGoogle Cloud -Konsole die Histogramme der Featureverteilung auf der Seite Endpunkte auf.
Klicken Sie auf der Seite Endpunkte auf den Endpunkt, den Sie analysieren möchten.
Auf der Detailseite für den ausgewählten Endpunkt finden Sie eine Liste aller Modelle, die auf diesem Endpunkt bereitgestellt sind. Klicken Sie auf den Namen eines zu analysierenden Modells.
Auf der Detailseite des Modells werden die Eingabefeatures des Modells aufgelistet. Außerdem finden Sie dort relevante Informationen wie den Grenzwert für die Benachrichtigung für die einzelnen Features und die Anzahl der vorherigen Benachrichtigungen für das Feature.
Klicken Sie auf den Namen eines Elements, um es zu analysieren. Auf einer Seite werden die Histogramme für die Featureverteilung für dieses Feature angezeigt.
Für jedes überwachte Feature können Sie sich die Verteilung der 50 neuesten Monitoringjobs in der Google Cloud -Konsole ansehen. Zur Erkennung von Abweichungen wird die Trainingsdatenverteilung direkt neben der Eingabedatenverteilung angezeigt:
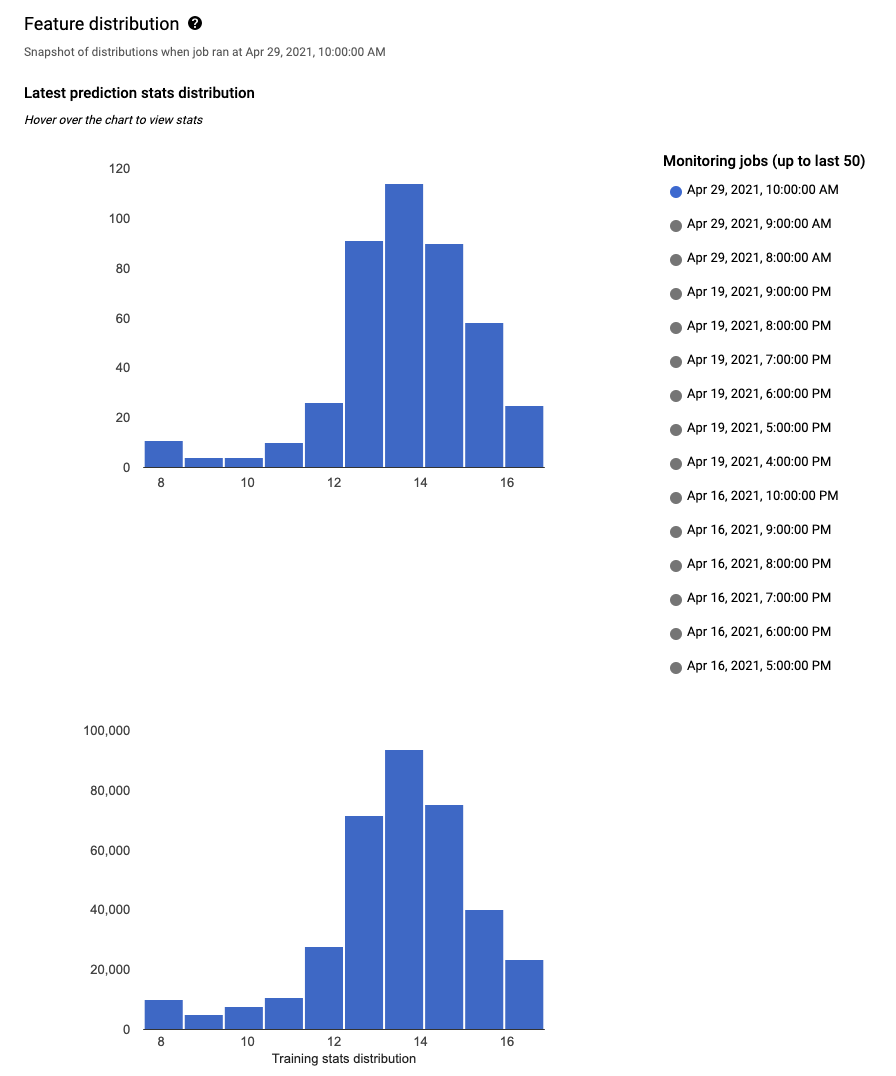
Durch die Visualisierung der Datenverteilung als Histogramme können Sie sich schnell auf die Änderungen an den Daten konzentrieren. Anschließend können Sie die Pipeline zur Featuregenerierung anpassen oder das Modell neu trainieren.
Nächste Schritte
- Arbeiten Sie mit Model Monitoring gemäß der API-Dokumentation.
- Arbeiten Sie mit dem Modellmonitoring gemäß der Dokumentation zur gcloud CLI.
- Sie können das Beispielnotebook in Colab ausführen oder es sich auf GitHub ansehen.
- Berechnen von Abweichungen zwischen Training und Bereitstellung und Vorhersageabweichung