Questa pagina descrive come configurare le richieste di job di inferenza batch in modo da includere l'analisi una tantum di Model Monitoring. Per le inferenze batch, il monitoraggio del modello supporta il rilevamento di disallineamento delle caratteristiche per le caratteristiche di input categoriche e numeriche.
Per creare un job di inferenza batch con l'analisi del disallineamento di Model Monitoring, devi includere nella richiesta sia i dati di input dell'inferenza batch sia i dati di addestramento originali per il modello. Puoi aggiungere l'analisi Model Monitoring solo quando crei nuovi job di inferenza batch.
Per saperne di più sul disallineamento, consulta Introduzione a Model Monitoring.
Per istruzioni su come configurare Model Monitoring per le inferenze online (in tempo reale), vedi Utilizzo di Model Monitoring.
Prerequisiti
Per utilizzare Model Monitoring con le inferenze batch, completa i seguenti passaggi:
Avere un modello disponibile in Vertex AI Model Registry di tipo AutoML tabulare o addestramento personalizzato tabulare.
Carica i dati di addestramento su Cloud Storage o BigQuery e ottieni il link URI ai dati.
- Per i modelli addestrati con AutoML, puoi utilizzare l'ID set di dati per il set di dati di addestramento.
Model Monitoring confronta i dati di addestramento con l'output dell'inferenza batch. Assicurati di utilizzare i formati file supportati per i dati di addestramento e l'output dell'inferenza batch:
Tipo di modello Dati di addestramento Output dell'inferenza batch Addestrato dal cliente CSV, JSONL, BigQuery, TFRecord(tf.train.Example) JSONL AutoML Tabular CSV, JSONL, BigQuery, TFRecord(tf.train.Example) CSV, JSONL, BigQuery, TfRecord(Protobuf.Value) (Facoltativo) Per i modelli con addestramento personalizzato, carica lo schema del modello su Cloud Storage. Model Monitoring richiede lo schema per calcolare la distribuzione di base per il rilevamento del disallineamento.
Richiedere un'inferenza batch
Puoi utilizzare i seguenti metodi per aggiungere le configurazioni di Model Monitoring ai job di inferenza batch:
Console
Segui le istruzioni per effettuare una richiesta di inferenza batch con Model Monitoring abilitato:
API REST
Segui le istruzioni per effettuare una richiesta di inferenza batch utilizzando l'API REST:
Quando crei la richiesta di inferenza batch, aggiungi la seguente configurazione di Model Monitoring al corpo JSON della richiesta:
"modelMonitoringConfig": {
"alertConfig": {
"emailAlertConfig": {
"userEmails": "EMAIL_ADDRESS"
},
"notificationChannels": [NOTIFICATION_CHANNELS]
},
"objectiveConfigs": [
{
"trainingDataset": {
"dataFormat": "csv",
"gcsSource": {
"uris": [
"TRAINING_DATASET"
]
}
},
"trainingPredictionSkewDetectionConfig": {
"skewThresholds": {
"FEATURE_1": {
"value": VALUE_1
},
"FEATURE_2": {
"value": VALUE_2
}
}
}
}
]
}
dove:
EMAIL_ADDRESS è l'indirizzo email a cui vuoi ricevere gli avvisi di Model Monitoring. Ad esempio,
example@example.com.NOTIFICATION_CHANNELS: un elenco di canali di notifica di Cloud Monitoring in cui vuoi ricevere avvisi da Model Monitoring. Utilizza i nomi delle risorse per i canali di notifica, che puoi recuperare elencando i canali di notifica nel tuo progetto. Ad esempio:
"projects/my-project/notificationChannels/1355376463305411567", "projects/my-project/notificationChannels/1355376463305411568".TRAINING_DATASET è il link al set di dati di addestramento archiviato in Cloud Storage.
- Per utilizzare un link a un set di dati di addestramento BigQuery, sostituisci
il campo
gcsSourcecon quanto segue:
"bigquerySource": { { "inputUri": "TRAINING_DATASET" } }- Per utilizzare un link a un modello AutoML, sostituisci il campo
gcsSourcecon quanto segue:
"dataset": "TRAINING_DATASET"
- Per utilizzare un link a un set di dati di addestramento BigQuery, sostituisci
il campo
FEATURE_1:VALUE_1 e FEATURE_2:VALUE_2 è la soglia di avviso per ogni funzionalità che vuoi monitorare. Ad esempio, se specifichi
Age=0.4, Model Monitoring registra un avviso quando la distanza statistica tra le distribuzioni di input e di base per la caratteristicaAgesupera 0,4. Per impostazione predefinita, ogni funzionalità categorica e numerica viene monitorata con valori di soglia pari a 0,3.
Per ulteriori informazioni sulle configurazioni di Model Monitoring, consulta il riferimento al job di monitoraggio.
Python
Consulta il notebook di esempio per eseguire un job di inferenza batch con Model Monitoring per un modello tabulare personalizzato.
Model Monitoring ti invia automaticamente notifiche via email relative ad aggiornamenti e avvisi dei job.
Accedere alle metriche di asimmetria
Puoi utilizzare i seguenti metodi per accedere alle metriche di distorsione per i job di inferenza batch:
Console (istogramma)
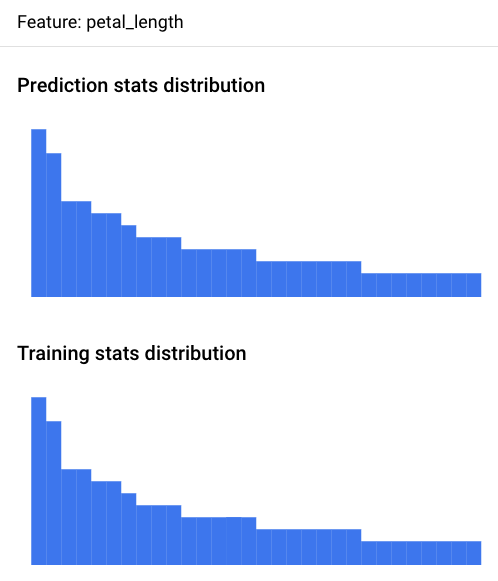
Utilizza la console Google Cloud per visualizzare gli istogrammi della distribuzione delle funzionalità per ogni funzionalità monitorata e scoprire quali modifiche hanno portato a uno sbilanciamento nel tempo:
Vai alla pagina Previsioni batch:
Nella pagina Previsioni batch, fai clic sul job di inferenza batch che vuoi analizzare.
Fai clic sulla scheda Avvisi di monitoraggio del modello per visualizzare un elenco delle funzionalità di input del modello, insieme a informazioni pertinenti, come la soglia di avviso per ciascuna funzionalità.
Per analizzare una funzionalità, fai clic sul relativo nome. Una pagina mostra gli istogrammi della distribuzione delle funzionalità per quella funzionalità.
La visualizzazione della distribuzione dei dati sotto forma di istogrammi consente di comprendere rapidamente ciò che è accaduto nei dati. In seguito, potresti decidere di modificare la pipeline di generazione delle caratteristiche o di conservare il modello.
Console (file JSON)
Utilizza la console Google Cloud per accedere alle metriche in formato JSON:
Vai alla pagina Previsioni batch:
Fai clic sul nome del job di monitoraggio dell'inferenza batch.
Fai clic sulla scheda Proprietà di monitoraggio.
Fai clic sul link Directory di output del monitoraggio, che ti indirizza a un bucket Cloud Storage.
Fai clic sulla cartella
metrics/.Fai clic sulla cartella
skew/.Fai clic sul file
feature_skew.json, che ti indirizza alla pagina Dettagli oggetto.Apri il file JSON utilizzando una delle seguenti opzioni:
Fai clic su Scarica e apri il file nell'editor di testo locale.
Utilizza il percorso URI gsutil per eseguire
gcloud storage cat gsutil_URIin Cloud Shell o nel terminale locale.
Il file feature_skew.json include un dizionario in cui la chiave è il nome della funzionalità e il valore è il disallineamento della funzionalità. Ad esempio:
{
"cnt_ad_reward": 0.670936,
"cnt_challenge_a_friend": 0.737924,
"cnt_completed_5_levels": 0.549467,
"month": 0.293332,
"operating_system": 0.05758,
"user_pseudo_id": 0.1
}
Python
Consulta il blocco note di esempio per accedere alle metriche di disallineamento per un modello tabellare personalizzato dopo aver eseguito un job di inferenza batch con Model Monitoring.
Eseguire il debug degli errori di monitoraggio dell'inferenza batch
Se il job di monitoraggio dell'inferenza batch non va a buon fine, puoi trovare i log di debug nella console Google Cloud :
Vai alla pagina Previsioni batch.
Fai clic sul nome del job di monitoraggio dell'inferenza batch non riuscito.
Fai clic sulla scheda Proprietà di monitoraggio.
Fai clic sul link Directory di output del monitoraggio, che ti indirizza a un bucket Cloud Storage.
Fai clic sulla cartella
logs/.Fai clic su uno dei file
.INFO, che ti indirizza alla pagina Dettagli oggetto.Apri il file dei log utilizzando una delle seguenti opzioni:
Fai clic su Scarica e apri il file nell'editor di testo locale.
Utilizza il percorso URI gsutil per eseguire
gcloud storage cat gsutil_URIin Cloud Shell o nel terminale locale.
Tutorial su Notebook
Scopri di più su come utilizzare Vertex AI Model Monitoring per ottenere visualizzazioni e statistiche per i modelli con questi tutorial end-to-end.
AutoML
- Vertex AI Model Monitoring per i modelli tabulari AutoML
- Vertex AI Model Monitoring per la previsione batch nei modelli di immagini AutoML
- Vertex AI Model Monitoring per la previsione online nei modelli di immagini AutoML
Personalizzato
- Vertex AI Model Monitoring per modelli tabellari personalizzati
- Vertex AI Model Monitoring per modelli tabulari personalizzati con container TensorFlow Serving
Modelli XGBoost
Attribuzioni delle caratteristiche di Vertex Explainable AI
Inferenza batch
Configurazione per i modelli tabulari
Passaggi successivi
- Scopri come utilizzare il monitoraggio del modello.
- Scopri come Model Monitoring calcola il disallineamento tra addestramento e distribuzione e la deviazione dell'inferenza.