Questa pagina fornisce una panoramica di Vertex AI Model Monitoring.
Panoramica del monitoraggio
Vertex AI Model Monitoring consente di eseguire job di monitoraggio in base alle necessità o in base a una pianificazione regolare per monitorare la qualità dei modelli tabellari. Se hai impostato avvisi, Vertex AI Model Monitoring ti informa quando le metriche superano una soglia specificata.
Ad esempio, supponiamo di avere un modello che prevede il lifetime value cliente. Man mano che le abitudini dei clienti cambiano, cambiano anche i fattori che prevedono la spesa dei clienti. Di conseguenza, le funzionalità e i valori delle funzionalità che hai utilizzato per addestrare il modello in precedenza potrebbero non essere pertinenti per fare inferenze oggi. Questa deviazione nei dati è nota come deriva.
Vertex AI Model Monitoring può monitorare e avvisarti quando le deviazioni superano una soglia specificata. Puoi quindi rivalutare o riaddestrare il modello per assicurarti che si comporti come previsto.
Ad esempio, Vertex AI Model Monitoring può fornire visualizzazioni come quella nella figura seguente, che sovrappone due grafici di due set di dati. Questa visualizzazione ti consente di confrontare rapidamente e vedere le deviazioni tra i due set di dati.
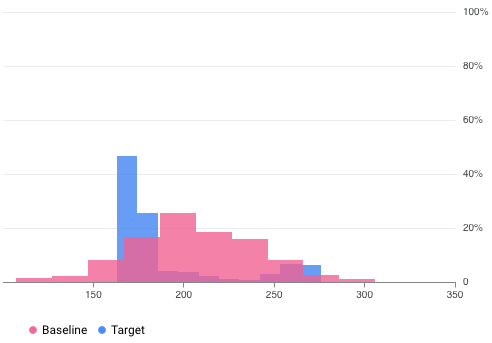
Versioni di Vertex AI Model Monitoring
Vertex AI Model Monitoring offre due opzioni: v2 e v1.
Il monitoraggio dei modelli v2 è in anteprima ed è l'ultima offerta che associa tutte le attività di monitoraggio a una versione del modello. Al contrario, il monitoraggio dei modelli v1 è in disponibilità generale e viene configurato sugli endpoint Vertex AI.
Se hai bisogno di assistenza a livello di produzione e vuoi monitorare un modello di cui è stato eseguito il deployment su un endpoint Vertex AI, utilizza Model Monitoring v1. Per tutti gli altri casi d'uso, utilizza Model Monitoring v2, che offre tutte le funzionalità di Model Monitoring v1 e altro ancora. Per ulteriori informazioni, consulta la panoramica di ogni versione:
Per gli utenti esistenti di Model Monitoring v1, Model Monitoring v1 viene mantenuto così com'è. Non è necessario eseguire la migrazione a Model Monitoring v2. Se vuoi eseguire la migrazione, puoi utilizzare entrambe le versioni contemporaneamente fino a quando non avrai eseguito completamente la migrazione a Model Monitoring v2 per evitare lacune nel monitoraggio durante la transizione.
Panoramica di Model Monitoring v2
Model Monitoring v2 ti consente di monitorare le metriche nel tempo dopo aver configurato un monitoraggio del modello ed eseguito i job di monitoraggio. Puoi eseguire job di monitoraggio on demand o configurare esecuzioni pianificate. Utilizzando le esecuzioni pianificate, Model Monitoring esegue automaticamente i job di monitoraggio in base a una pianificazione definita dall'utente.
Obiettivi di monitoraggio
Le metriche e le soglie che monitori sono mappate agli obiettivi di monitoraggio. Per ogni versione del modello, puoi specificare uno o più obiettivi di monitoraggio. La tabella seguente descrive in dettaglio ogni scopo:
| Obiettivo | Descrizione | Tipo di dati della funzionalità | Metriche supportate |
|---|---|---|---|
| Deviazione dei dati delle caratteristiche di input |
Misura la distribuzione dei valori delle caratteristiche di input rispetto a una distribuzione dei dati di base. |
Categorico: booleano, stringa, categorico |
|
| Numerico: float, integer | Divergenza di Jensen-Shannon | ||
| Deviazione dei dati di inferenza di output |
Misura la distribuzione dei dati delle inferenze del modello rispetto a una distribuzione dei dati di base. |
Categorico: booleano, stringa, categorico |
|
| Numerico: float, integer | Divergenza di Jensen-Shannon | ||
| Attribuzione delle caratteristiche |
Misura la variazione del contributo delle caratteristiche all'inferenza di un modello rispetto a una base di riferimento. Ad esempio, puoi monitorare se una funzionalità molto importante perde improvvisamente importanza. |
Tutti i tipi di dati | Valore SHAP (SHapley Additive exPlanations) |
Deviazione della caratteristica di input e dell'inferenza di output
Dopo il deployment di un modello in produzione, i dati di input possono discostarsi da quelli utilizzati per addestrare il modello o la distribuzione dei dati delle funzionalità in produzione potrebbe variare in modo significativo nel tempo. Model Monitoring v2 può monitorare le modifiche alla distribuzione dei dati di produzione rispetto ai dati di addestramento o monitorare l'evoluzione della distribuzione dei dati di produzione nel tempo.
Allo stesso modo, per i dati di inferenza, Model Monitoring v2 può monitorare le variazioni nella distribuzione dei risultati previsti rispetto alla distribuzione dei dati di addestramento o di produzione nel tempo.
Attribuzione delle caratteristiche
L'attribuzione delle caratteristiche indica in che misura ciascuna caratteristica del modello ha contribuito alle inferenze per ogni istanza specificata. I punteggi di attribuzione sono proporzionali al contributo della caratteristica all'inferenza di un modello. In genere sono firmati, per indicare se una funzionalità contribuisce ad aumentare o diminuire l'inferenza. Le attribuzioni in tutte le funzionalità devono essere pari al punteggio di inferenza del modello.
Monitorando le attribuzioni delle caratteristiche, Model Monitoring v2 tiene traccia delle variazioni dei contributi di una caratteristica alle inferenze di un modello nel tempo. Una variazione del punteggio di attribuzione di una caratteristica chiave spesso indica che la caratteristica è cambiata in un modo che può influire sull'accuratezza delle inferenze del modello.
Per ulteriori informazioni sugli attributi e sulle metriche delle funzionalità, consulta Spiegazioni basate sulle funzionalità e Metodo Shapley campionato.
Come configurare Model Monitoring v2
Devi prima registrare i tuoi modelli in Vertex AI Model Registry. Se pubblichi modelli al di fuori di Vertex AI, non devi caricare l'artefatto del modello. Poi crei un monitor del modello, che associ a una versione del modello e definisci lo schema del modello. Per alcuni modelli, come i modelli AutoML, lo schema viene fornito.
Nel monitoraggio del modello, puoi specificare facoltativamente configurazioni predefinite come obiettivi di monitoraggio, un set di dati di addestramento, la posizione dell'output di monitoraggio e le impostazioni di notifica. Per maggiori informazioni, vedi Configurare il monitoraggio del modello.
Dopo aver creato un monitoraggio del modello, puoi eseguire un job di monitoraggio on demand o pianificare job regolari per il monitoraggio continuo. Quando esegui un job, Model Monitoring utilizza la configurazione predefinita impostata nel monitoraggio del modello, a meno che tu non fornisca una configurazione di monitoraggio diversa. Ad esempio, se fornisci obiettivi di monitoraggio diversi o un set di dati di confronto diverso, Model Monitoring utilizza le configurazioni del job anziché la configurazione predefinita del monitoraggio del modello. Per maggiori informazioni, consulta Esegui un job di monitoraggio.
Prezzi
Il monitoraggio dei modelli v2 non viene addebitato durante l'anteprima. Ti viene comunque addebitato l'utilizzo di altri servizi, come Cloud Storage, BigQuery, inferenze batch di Vertex AI, Vertex Explainable AI e Cloud Logging.
Tutorial su Notebook
I seguenti tutorial mostrano come utilizzare l'SDK Vertex AI per Python per configurare Model Monitoring v2 per il tuo modello.
Model Monitoring v2: job di inferenza batch del modello personalizzato
Monitoraggio del modello v2: inferenza online del modello personalizzato
Model Monitoring v2: modelli esterni a Vertex AI
Panoramica di Model Monitoring v1
Per aiutarti a mantenere le prestazioni di un modello, Model Monitoring v1 monitora i dati di input dell'inferenza del modello per il disallineamento e la deviazione delle caratteristiche:
Il disallineamento addestramento/produzione si verifica quando la distribuzione dei dati delle funzionalità in produzione si discosta dalla distribuzione dei dati delle funzionalità utilizzata per addestrare il modello. Se i dati di addestramento originali sono disponibili, puoi attivare il rilevamento del disallineamento per monitorare i modelli per il disallineamento addestramento/produzione.
La deviazione dell'inferenza si verifica quando la distribuzione dei dati delle funzionalità in produzione cambia in modo significativo nel tempo. Se i dati di addestramento originali non sono disponibili, puoi attivare il rilevamento della deviazione per monitorare le modifiche ai dati di input nel tempo.
Puoi attivare il rilevamento di disallineamenti e deviazioni.
Model Monitoring v1 supporta il rilevamento di disallineamenti e deviazioni delle caratteristiche per le caratteristiche categoriche e numeriche:
Le caratteristiche categoriche sono dati limitati dal numero di valori possibili, in genere raggruppati in base a proprietà qualitative. Ad esempio, categorie come tipo di prodotto, paese o tipo di cliente.
Le caratteristiche numeriche sono dati che possono essere qualsiasi valore numerico. Ad esempio, peso e altezza.
Quando il disallineamento o la deviazione di una caratteristica di un modello supera una soglia di avviso che hai impostato, Model Monitoring v1 ti invia un avviso via email. Puoi anche visualizzare le distribuzioni per ogni funzionalità nel tempo per valutare se è necessario eseguire di nuovo il training del modello.
Calcola la deriva
Per rilevare la deviazione per la versione 1, Vertex AI Model Monitoring utilizza TensorFlow Data Validation (TFDV) per calcolare le distribuzioni e i punteggi di distanza.
Calcola la distribuzione statistica del riferimento:
Per il rilevamento del disallineamento, la base è la distribuzione statistica dei valori della caratteristica nei dati di addestramento.
Per il rilevamento della deviazione, la base è la distribuzione statistica dei valori della caratteristica rilevati in produzione in passato.
Le distribuzioni per le caratteristiche categoriche e numeriche vengono calcolate come segue:
Per le caratteristiche categoriche, la distribuzione calcolata è il numero o la percentuale di istanze di ogni possibile valore della caratteristica.
Per le caratteristiche numeriche, Vertex AI Model Monitoring divide l'intervallo dei possibili valori delle caratteristiche in intervalli uguali e calcola il numero o la percentuale di valori delle caratteristiche che rientrano in ciascun intervallo.
La baseline viene calcolata quando crei un job Vertex AI Model Monitoring e viene ricalcolata solo se aggiorni il set di dati di addestramento per il job.
Calcola la distribuzione statistica degli ultimi valori delle caratteristiche rilevati in produzione.
Confronta la distribuzione degli ultimi valori delle caratteristiche in produzione con la distribuzione di base calcolando un punteggio di distanza:
Per le caratteristiche categoriche, il punteggio di distanza viene calcolato utilizzando la distanza L-infinita.
Per le caratteristiche numeriche, il punteggio di distanza viene calcolato utilizzando la divergenza di Jensen-Shannon.
Se il punteggio di distanza tra due distribuzioni statistiche supera la soglia specificata, Vertex AI Model Monitoring identifica l'anomalia come disallineamento o deviazione.
L'esempio seguente mostra l'asimmetria o la deriva tra la distribuzione di base e quella più recente di una funzionalità categorica:
Distribuzione di base
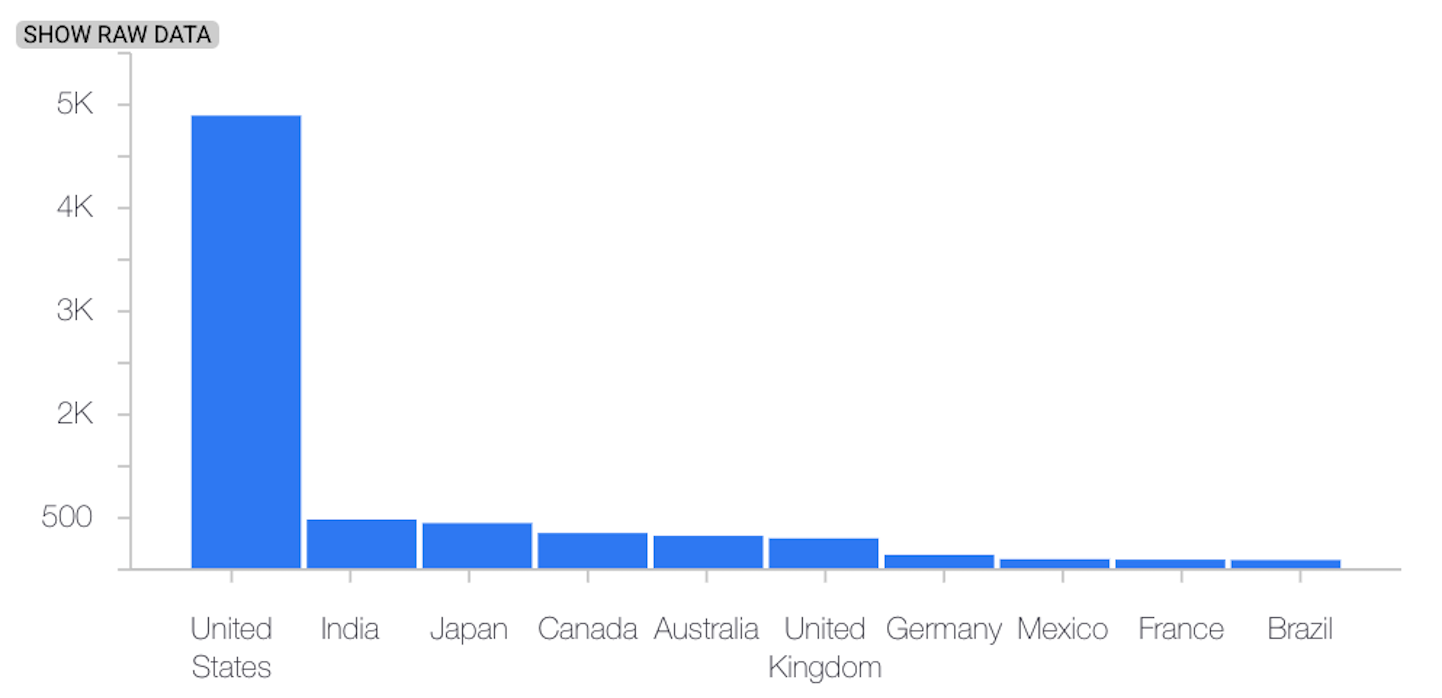
Ultima distribuzione
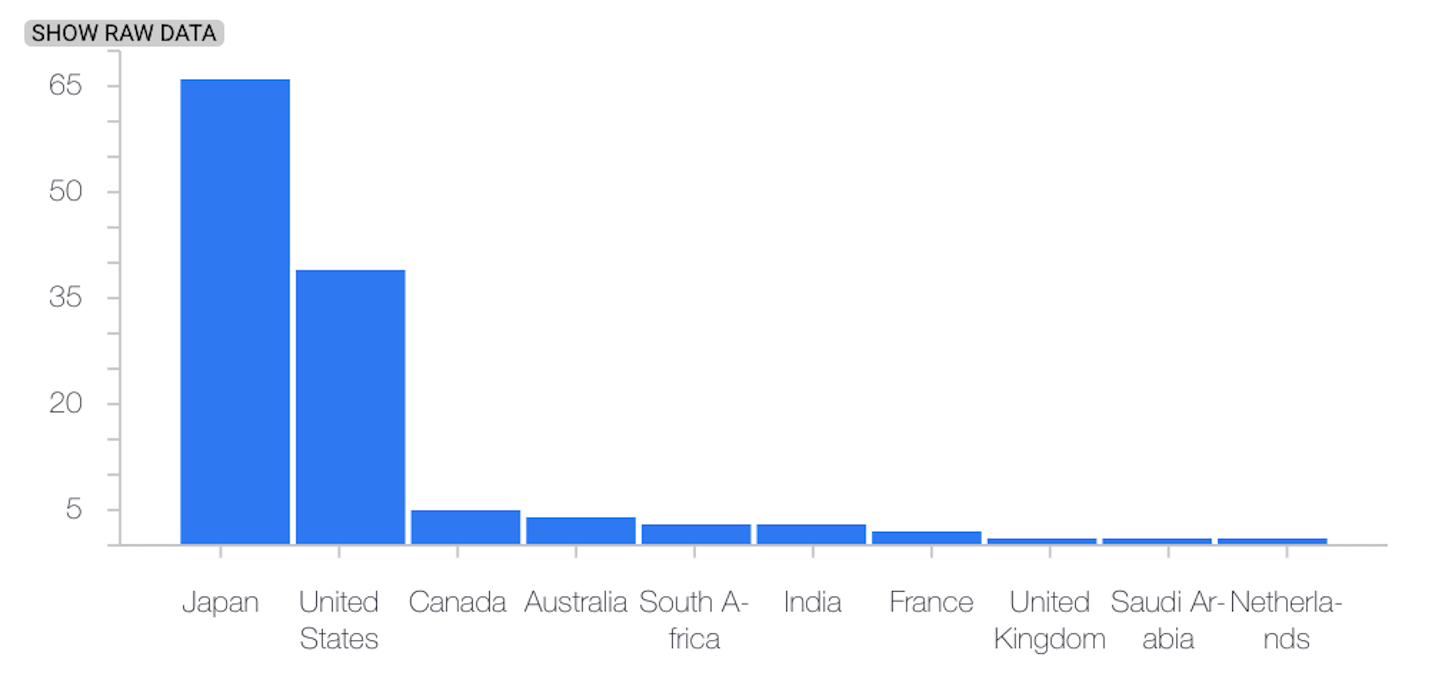
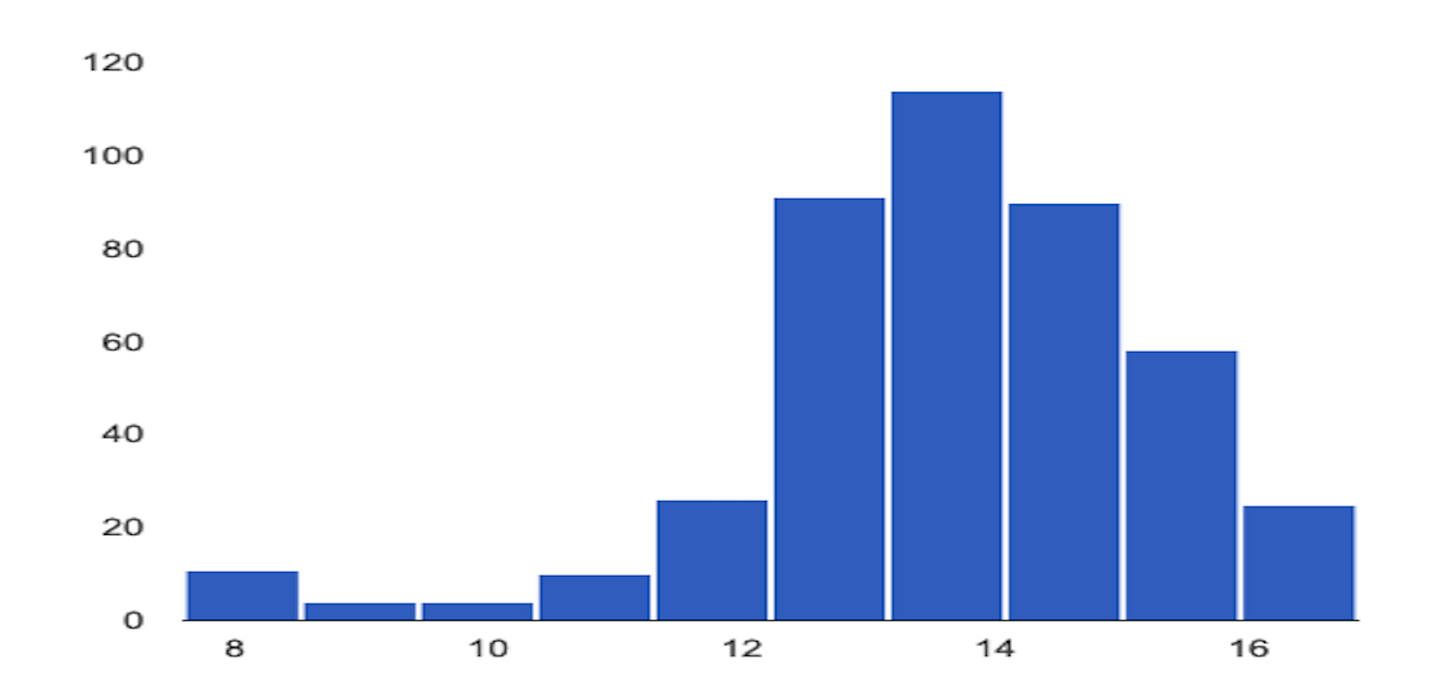
L'esempio seguente mostra l'asimmetria o la deriva tra la distribuzione di base e quella più recente di una caratteristica numerica:
Distribuzione di base
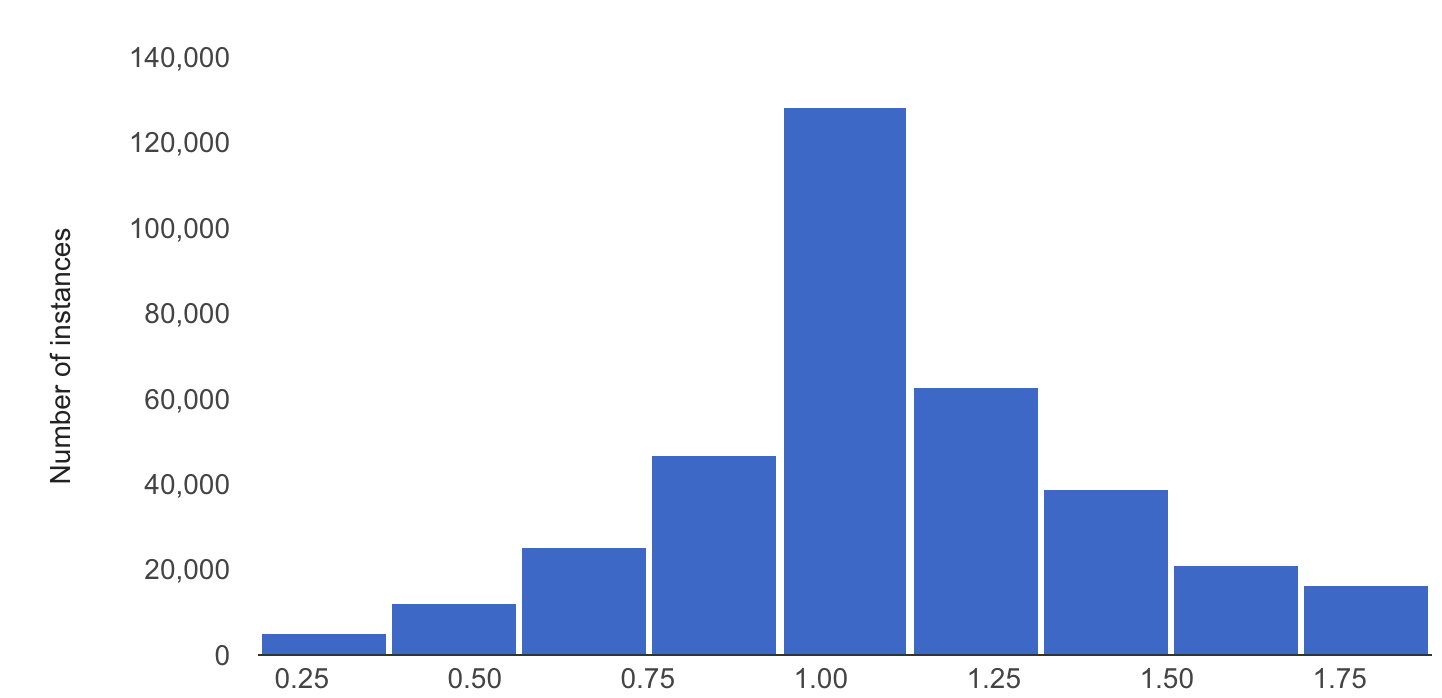
Ultima distribuzione
Considerazioni sull'utilizzo di Model Monitoring
Per contenere i costi, puoi impostare una frequenza di campionamento delle richieste di inferenza per monitorare un sottoinsieme degli input di produzione inviati a un modello.
Puoi impostare una frequenza con cui gli input registrati di recente di un modello distribuito vengono monitorati per verificare la presenza di disallineamenti o deviazioni. La frequenza di monitoraggio determina il periodo di tempo, o durata della finestra di monitoraggio, dei dati registrati che vengono analizzati in ogni esecuzione del monitoraggio.
Puoi specificare le soglie di avviso per ogni funzionalità che vuoi monitorare. Un avviso viene registrato quando la distanza statistica tra la distribuzione delle caratteristiche di input e la relativa base di riferimento supera la soglia specificata. Per impostazione predefinita, ogni funzionalità categorica e numerica viene monitorata, con valori <x0A>di soglia pari a 0,3.
Un endpoint di inferenza online può ospitare più modelli. Quando abiliti il rilevamento di distorsione o deriva su un endpoint, i seguenti parametri di configurazione vengono condivisi tra tutti i modelli ospitati in quell'endpoint:
- Tipo di rilevamento
- Frequenza di monitoraggio
- Frazione di richieste di input monitorate
Per gli altri parametri di configurazione, puoi impostare valori diversi per ogni modello.