Vertex AI fornisce un servizio di addestramento gestito che ti consente di mettere in operazione l'addestramento di modelli su larga scala. Puoi utilizzare Vertex AI per eseguire applicazioni di addestramento basate su qualsiasi framework di machine learning (ML) sull'Google Cloud infrastruttura. Per i seguenti framework ML di uso comune, Vertex AI offre anche il supporto integrato che semplifica la procedura di preparazione per l'addestramento e la pubblicazione dei modelli:
Questa pagina illustra i vantaggi dell'addestramento personalizzato su Vertex AI, il flusso di lavoro coinvolto e le varie opzioni di addestramento disponibili.
Vertex AI rende operativo l'addestramento su larga scala
Esistono diverse sfide per l'implementazione dell'addestramento dei modelli. Queste sfide includono il tempo e il costo necessari per addestrare i modelli, la profondità delle competenze richieste per gestire l'infrastruttura di calcolo e la necessità di fornire sicurezza a livello di azienda. Vertex AI risolve questi problemi, offrendo al contempo una serie di altri vantaggi.
Infrastruttura di calcolo completamente gestita
|
|
L'addestramento dei modelli su Vertex AI è un servizio completamente gestito che non richiede l'amministrazione dell'infrastruttura fisica. Puoi addestrare i modelli di ML senza dover eseguire il provisioning o gestire i server. Paghi solo per le risorse di calcolo che utilizzi. Vertex AI gestisce inoltre il logging, l'inserimento in coda e il monitoraggio dei job. |
Prestazioni elevate
|
|
I job di addestramento di Vertex AI sono ottimizzati per l'addestramento dei modelli ML, il che può offrire prestazioni più rapide rispetto all'esecuzione diretta dell'applicazione di addestramento su un cluster GKE. Puoi anche identificare e eseguire il debug dei colli di bottiglia delle prestazioni nel tuo job di addestramento utilizzando Cloud Profiler. |
Addestramento distribuito
|
|
Reduction Server è un algoritmo all-reduce in Vertex AI che può aumentare il throughput e ridurre la latenza dell'addestramento distribuito su più nodi su unità di elaborazione grafica (GPU) NVIDIA. Questa ottimizzazione consente di ridurre il tempo e i costi per il completamento di job di addestramento di grandi dimensioni. |
Ottimizzazione degli iperparametri
|
|
I job di ottimizzazione degli iperparametri eseguono più prove dell'applicazione di addestramento utilizzando diversi valori dell'iperparametro. Specifichi un intervallo di valori da testare e Vertex AI scopre i valori ottimali per il tuo modello all'interno di quell'intervallo. |
Sicurezza aziendale
|
|
Vertex AI offre le seguenti funzionalità di sicurezza aziendale:
|
Integrazioni di ML Operations (MLOps)
|
|
Vertex AI fornisce una suite di strumenti MLOps integrati e funzionalità che puoi utilizzare per le seguenti finalità:
|
Flusso di lavoro per l'addestramento personalizzato
Il seguente diagramma mostra una panoramica generale del flusso di lavoro dell'addestramento personalizzato su Vertex AI. Le sezioni seguenti descrivono ogni passaggio in dettaglio.
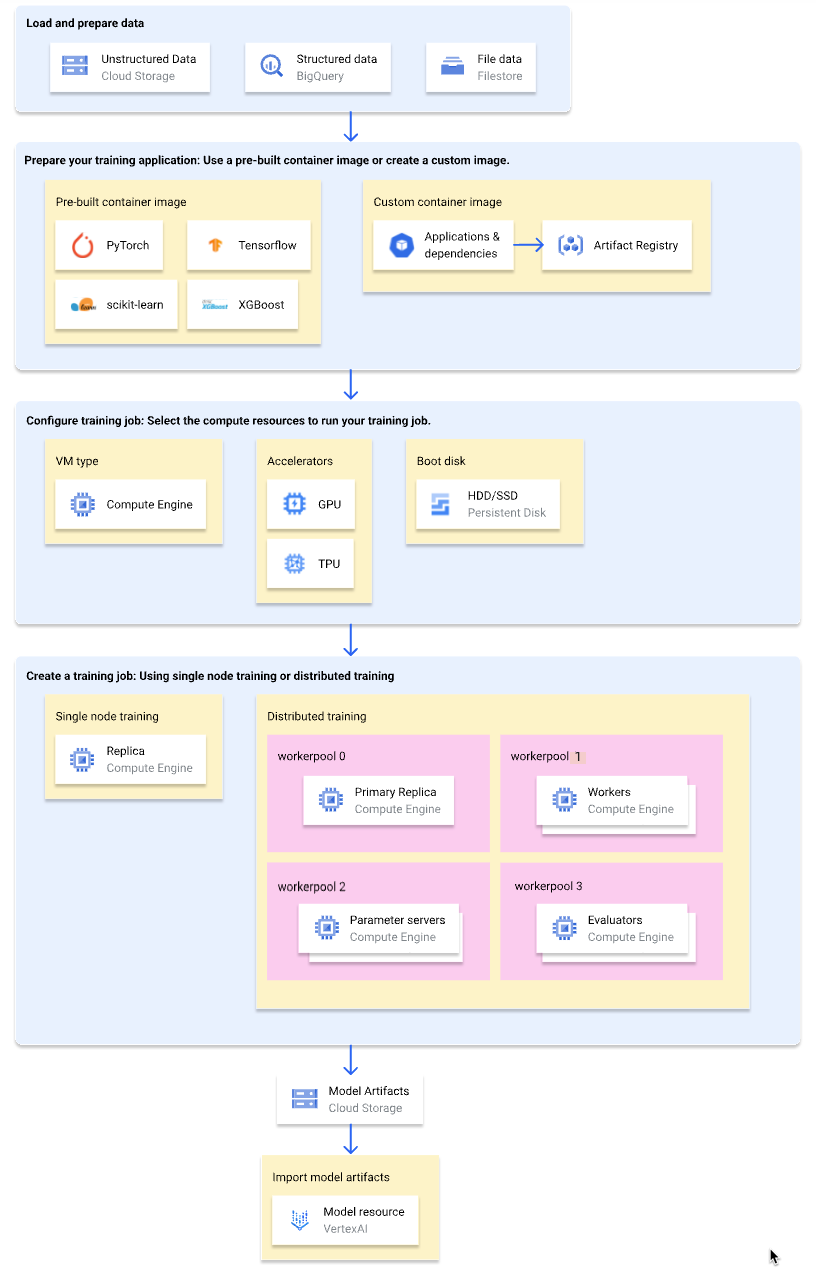
Carica e prepara i dati di addestramento
Per le migliori prestazioni e l'assistenza, utilizza uno dei seguenti Google Cloud servizi come origine dati:
Puoi anche specificare un set di dati gestito da Vertex AI come origine dati quando utilizzi una pipeline di addestramento per addestrare il modello. L'addestramento di un modello personalizzato e di un modello AutoML utilizzando lo stesso set di dati consente di confrontare il rendimento dei due modelli.
Preparare l'applicazione di addestramento
Per preparare l'applicazione di addestramento per l'utilizzo su Vertex AI, segui questi passaggi:
- Implementa le best practice per il codice di addestramento per Vertex AI.
- Determina un tipo di immagine del contenitore da utilizzare.
- Pacchettizza l'applicazione di addestramento in un formato supportato in base al tipo di immagine container selezionato.
Implementare le best practice per il codice di addestramento
L'applicazione di addestramento deve implementare le best practice per il codice di addestramento per Vertex AI. Queste best practice riguardano la capacità della tua applicazione di addestramento di svolgere quanto segue:
- Accedi ai servizi Google Cloud .
- Carica i dati di input.
- Attivare il logging automatico per il monitoraggio degli esperimenti.
- Esporta gli artefatti del modello.
- Utilizza le variabili di ambiente di Vertex AI.
- Garantire la resilienza ai riavvii della VM.
Seleziona un tipo di contenitore
Vertex AI esegue l'applicazione di addestramento in un'immagine del container Docker. Un'immagine del contenitore Docker è un pacchetto software autonomo che include il codice e tutte le dipendenze e può essere eseguito in quasi qualsiasi ambiente di calcolo. Puoi specificare l'URI di un'immagine container predefinita da utilizzare oppure creare e caricare un'immagine container personalizzata con l'applicazione di addestramento e le dipendenze preinstallate.
La seguente tabella mostra le differenze tra le immagini dei container predefinite e personalizzate:
| Specifiche | Immagini container preimpostate | Immagini container personalizzate |
|---|---|---|
| Framework ML | Ogni immagine container è specifica per un framework ML. | Utilizza qualsiasi framework di ML o non utilizzarne nessuno. |
| Versione del framework ML | Ogni immagine container è specifica per una versione del framework ML. | Utilizza qualsiasi versione del framework ML, incluse le versioni secondarie e le compilazioni notturne. |
| Dipendenze dell'applicazione | Le dipendenze comuni per il framework ML sono preinstallate. Puoi specificare dipendenze aggiuntive da installare nell'applicazione di formazione. | Preinstalla le dipendenze necessarie per l'applicazione di addestramento. |
| Formato di pubblicazione dell'applicazione |
|
Preinstalla l'applicazione di addestramento nell'immagine del container personalizzato. |
| Impegno richiesto per la configurazione | Bassa | Alta |
| Consigliati per | Applicazioni di addestramento Python basate su un framework ML e su una versione del framework per la quale è disponibile un'immagine container predefinita. |
|
Pacchettizza l'applicazione di addestramento
Dopo aver determinato il tipo di immagine container da utilizzare, pacchettizza la tua applicazione di addestramento in uno dei seguenti formati in base al tipo di immagine container:
File Python singolo da utilizzare in un container predefinito
Scrivi l'applicazione di addestramento come singolo file Python e utilizza l'SDK Vertex AI per Python per creare una classe
CustomJoboCustomTrainingJob. Il file Python viene pacchettizzato in una distribuzione di origine Python e installato in un'immagine container predefinita. L'implementazione dell'applicazione di addestramento come singolo file Python è adatta per la prototipazione. Per le applicazioni di addestramento di produzione, è probabile che l'applicazione di addestramento sia organizzata in più di un file.Distribuzione di codice sorgente Python da utilizzare in un container predefinito
Pacchettizza la tua applicazione di addestramento in una o più distribuzioni di origine Python e caricale in un bucket Cloud Storage. Vertex AI installa le distribuzioni di origine in un'immagine container predefinita quando crei un job di addestramento.
Immagine del container personalizzato
Crea la tua immagine container Docker con l'applicazione di addestramento e le dipendenze preinstallate e caricala su Artifact Registry. Se l'applicazione di addestramento è scritta in Python, puoi eseguire questi passaggi utilizzando un comando Google Cloud CLI.
Configura il job di addestramento
Un job di addestramento Vertex AI esegue le seguenti attività:
- Esegui il provisioning di una (addestramento con un solo nodo) o più (addestramento distribuito) macchine virtuali (VM).
- Esegue l'applicazione di addestramento containerizzata sulle VM di cui è stato eseguito il provisioning.
- Elimina le VM al termine del job di addestramento.
Vertex AI offre tre tipi di job di addestramento per eseguire l'applicazione di addestramento:
-
Un job personalizzato (
CustomJob) esegue l'applicazione di addestramento. Se utilizzi un'immagine container predefinita, gli elementi del modello vengono visualizzati nel bucket Cloud Storage specificato. Per le immagini container personalizzate, l'applicazione di addestramento può anche generare elementi del modello in altre posizioni. Job di ottimizzazione degli iperparametri
Un job di ottimizzazione degli iperparametri (
HyperparameterTuningJob) esegue più prove dell'applicazione di addestramento utilizzando diversi valori degli iperparametri finché non produce elementi del modello con i valori degli iperparametri con prestazioni ottimali. Specifica l'intervallo di valori degli iperparametri da testare e le metriche in base alle quali eseguire l'ottimizzazione.-
Una pipeline di addestramento (
CustomTrainingJob) esegue un job personalizzato o di ottimizzazione degli iperparametri ed eventualmente esporta gli artefatti del modello in Vertex AI per creare una risorsa modello. Puoi specificare un set di dati gestito da Vertex AI come origine dati.
Quando crei un job di addestramento, specifica le risorse di calcolo da utilizzare per eseguire l'applicazione di addestramento e configura le impostazioni del contenitore.
Configurazioni di calcolo
Specifica le risorse di calcolo da utilizzare per un job di addestramento. Vertex AI supporta l'addestramento con un nodo singolo, in cui il job di addestramento viene eseguito su una VM, e l'addestramento distribuito, in cui il job di addestramento viene eseguito su più VM.
Le risorse di calcolo che puoi specificare per il job di addestramento sono le seguenti:
Tipo di macchina VM
I diversi tipi di macchine offrono CPU, dimensioni della memoria e larghezza di banda diverse.
Unità di elaborazione grafica (GPU)
Puoi aggiungere una o più GPU alle VM di tipo A2 o N1. Se la tua applicazione di addestramento è progettata per utilizzare le GPU, l'aggiunta di GPU può migliorare notevolmente le prestazioni.
Tensor Processing Unit (TPU)
Le TPU sono progettate specificamente per accelerare i carichi di lavoro di machine learning. Quando utilizzi una VM TPU per l'addestramento, puoi specificare un solo pool di worker. Questo pool di worker può avere una sola replica.
Dischi di avvio
Puoi utilizzare SSD (valore predefinito) o HDD per il disco di avvio. Se l'applicazione di addestramento legge e scrive sul disco, l'utilizzo di unità SSD può migliorare le prestazioni. Puoi anche specificare le dimensioni del disco di avvio in base alla quantità di dati temporanei che l'applicazione di addestramento scrive sul disco. I dischi di avvio possono avere una dimensione compresa tra 100 GiB (valore predefinito) e 64.000 GiB. Tutte le VM in un pool di worker devono utilizzare lo stesso tipo e le stesse dimensioni del disco di avvio.
Configurazioni dei contenitori
Le configurazioni del contenitore che devi apportare dipendono dal fatto che tu stia utilizzando un'immagine container predefinita o personalizzata.
Configurazioni dei container predefiniti:
- Specifica l'URI dell'immagine del container predefinita che vuoi utilizzare.
- Se l'applicazione di addestramento è pacchettizzata come distribuzione di origine Python, specifica l'URI Cloud Storage in cui si trova il pacchetto.
- Specifica il modulo del punto di ingresso dell'applicazione di addestramento.
- (Facoltativo) Specifica un elenco di argomenti della riga di comando da passare al modulo del punto di ingresso della tua applicazione di addestramento.
Configurazioni dei container personalizzati:
- Specifica l'URI dell'immagine del container personalizzato, che può essere un URI di Artifact Registry o Docker Hub.
- (Facoltativo) Sostituisci le istruzioni
ENTRYPOINToCMDnell'immagine container.
Creare un job di addestramento
Dopo aver preparato i dati e l'applicazione di addestramento, esegui l'applicazione di addestramento creando uno dei seguenti job di addestramento:
- Crea un job personalizzato.
- Crea un job di ottimizzazione degli iperparametri.
- Crea una pipeline di addestramento.
Per creare il job di addestramento, puoi utilizzare la console Google Cloud, Google Cloud CLI, l'SDK Vertex AI per Python o l'API Vertex AI.
(Facoltativo) Importa gli elementi del modello in Vertex AI
L'applicazione di addestramento probabilmente genera uno o più artefatti del modello in una posizione specificata, in genere un bucket Cloud Storage. Prima di poter ottenere le previsioni in Vertex AI dai tuoi elementi del modello, devi prima importare gli elementi del modello in Vertex AI Model Registry.
Come per le immagini container per l'addestramento, Vertex AI ti offre la possibilità di utilizzare immagini container predefinite o personalizzate per le previsioni. Se per il tuo framework di ML e la relativa versione è disponibile un'immagine del container predefinita per le previsioni, ti consigliamo di utilizzarla.
Passaggi successivi
- Ottieni le previsioni dal modello.
- Valuta il modello.
- Prova il tutorial Hello custom training per istruzioni dettagliate sull'addestramento di un modello di classificazione delle immagini TensorFlow Keras su Vertex AI.