Vector Search 是一款功能强大的向量搜索引擎,基于 Google 研究团队开发的开创性技术构建。借助 ScaNN 算法,Vector Search 可让您构建新一代搜索和推荐系统,以及生成式 AI 应用。
您可以受益于为 Google 搜索、YouTube 和 Google Play 等核心 Google 产品提供支持的相同研究和技术。 这意味着,您可以获得值得信赖的可伸缩性、可用性和性能,从而处理海量数据集,并在全球范围内以极快的速度提供结果。借助 Vector Search,您可以获得企业级解决方案,在自己的应用中实现先进的语义搜索功能。
|
|
|

|
开始使用
Vector Search 互动演示: 查看实时演示,了解向量搜索技术可以实现的真实示例,抢先体验 Vector Search。
Vector Search 快速入门:使用示例数据集构建、部署和查询 Vector Search 索引,在 30 分钟内试用 Vector Search。本教程介绍了设置、数据准备、索引创建、部署、查询和清理。
准备工作:通过选择和训练模型以及准备数据来准备嵌入。然后,选择要将查询索引部署到的公共或私密端点。
Vector Search 价格和价格计算器:Vector Search 价格包括用于托管已部署索引的虚拟机的费用,以及构建和更新索引的费用。即使是最低配置(每月低于 100 美元),对于中等规模的用例,也能应对高吞吐量。如需估算每月费用,请执行以下操作:
- 前往 Google Cloud 的价格计算器。
- 点击添加到估算。
- 搜索 Vertex AI。
- 点击 Vertex AI 按钮。
- 从服务类型下拉菜单中选择 Vertex AI Vector Search。
- 保留默认设置或配置您自己的设置。每月估算费用会显示在费用详情面板中。
文档
用例和博客
向量搜索技术正成为使用 AI 的企业的中心枢纽。与关系型数据库在 IT 系统中的运作方式类似,Vector Search 会根据相关性将各种业务元素(例如文档、内容、产品、用户、事件和其他实体)关联起来。除了搜索文档和图片等传统媒体外,Vector Search 还可以支持智能建议,将业务问题与解决方案进行匹配,甚至可以将 IoT 信号与监控提醒相关联。这是一个多功能工具,对于应对不断扩大的依托 AI 技术的企业数据领域至关重要。
|
搜索/信息检索
推荐 |
Vertex AI Vector Search 如何帮助打造高性能生成式 AI 应用: Vector Search 可为各种应用提供支持,包括电子商务、RAG 系统和推荐引擎,以及聊天机器人、多模态搜索等。混合搜索可进一步提升小众字词的搜索结果。 Bloomreach、eBay 和 Mercado Libre 等客户之所以使用 Vertex AI,是因为它具有出色的性能、可伸缩性和成本效益,可带来更快的搜索速度和更高的转化次数等优势。 eBay 使用 Vector Search 进行推荐:重点介绍 eBay 如何在其推荐系统中使用 Vector Search。借助这项技术,eBay 可以在其庞大的目录中查找类似产品,从而提升用户体验。 Mercari 利用 Google 的向量搜索技术打造全新的购物平台:介绍 Mercari 如何使用 Vector Search 改进其全新的购物平台。Vector Search 为该平台的推荐功能提供支持,帮助用户更有效地找到相关产品。 Vertex AI Embeddings for Text:轻松实现 LLM 接地:侧重于如何使用 Vertex AI Embeddings for Text 数据实现 LLM 接地。Vector Search 在查找相关文本段方面发挥着重要作用,可确保模型的回答以事实信息为依据。 什么是多模式搜索:“具有视觉功能的 LLM”改变企业:介绍将 LLM 与视觉理解相结合的多模式搜索。该博客介绍了 Vector Search 如何处理和比较文本和图片数据,从而提供更全面的搜索体验。 大规模实现多模态搜索:将文本和图片功能与 Vertex AI 相结合: 介绍如何使用 Vertex AI 构建多模态搜索引擎,该引擎使用加权 Rank-Biased Reciprocal Rank 集成学习方法将文本搜索和图片搜索相结合。这有助于改善用户体验并提供更相关的结果。 使用 TensorFlow Recommender 和 Vector Search 扩缩深度检索:介绍如何使用 TensorFlow Recommender 和 Vector Search 构建播放列表推荐系统,涵盖深度检索模型、训练、部署和扩缩。 |
|
Gen AI:RAG 和智能体的检索 |
Vertex AI 和 Denodo 利用生成式 AI 发掘企业数据:展示了 Vertex AI 与 Denodo 的集成如何让企业能够使用生成式 AI 从数据中获取分析洞见。Vector Search是高效访问和分析企业环境中的相关数据的关键。 Infinite Nature 和行业的本质:此“野生”演示展示了 AI 的多种可能性:展示了一个演示,说明 AI 在不同行业的潜力。它利用 Vector Search 来支持生成式推荐和多模态语义搜索。 Infinite Fleurs:探索 AI 辅助的创意之花:Google 的 Infinite Fleurs 是一项使用 Vector Search、Gemini 和 Imagen 模型的 AI 实验,可根据用户提示生成独特的花束。这项技术展示了 AI 在各个行业激发创造力的潜力。 适用于 Google Cloud 上的 RAG 的 LlamaIndex:介绍如何使用 LlamaIndex 通过大型语言模型促进检索增强生成 (RAG)。LlamaIndex 利用 Vector Search 从知识库中检索相关信息,从而生成更准确且更适合上下文的回答。 Vertex AI 上的 RAG 和接地:检查 Vertex AI 上的 RAG 和接地技术。 Vector Search 有助于在检索期间识别相关的接地信息,从而使生成的内容更准确、更可靠。 Vector Search on LangChain:提供有关如何将 Vector Search 与 LangChain 搭配使用以构建和部署文本数据的向量数据库索引(包括问答和 PDF 处理)的指南。 |
|
商业智能、数据分析、监控等 |
使用 Vertex AI 中的流式注入功能实现实时 AI:探索 Vector Search 中的流式更新以及它如何提供实时 AI 功能。此技术可实时处理和分析传入的数据流。 |
相关资源
您可以使用以下资源开始使用 Vector Search:
笔记本和解决方案

|
|
|
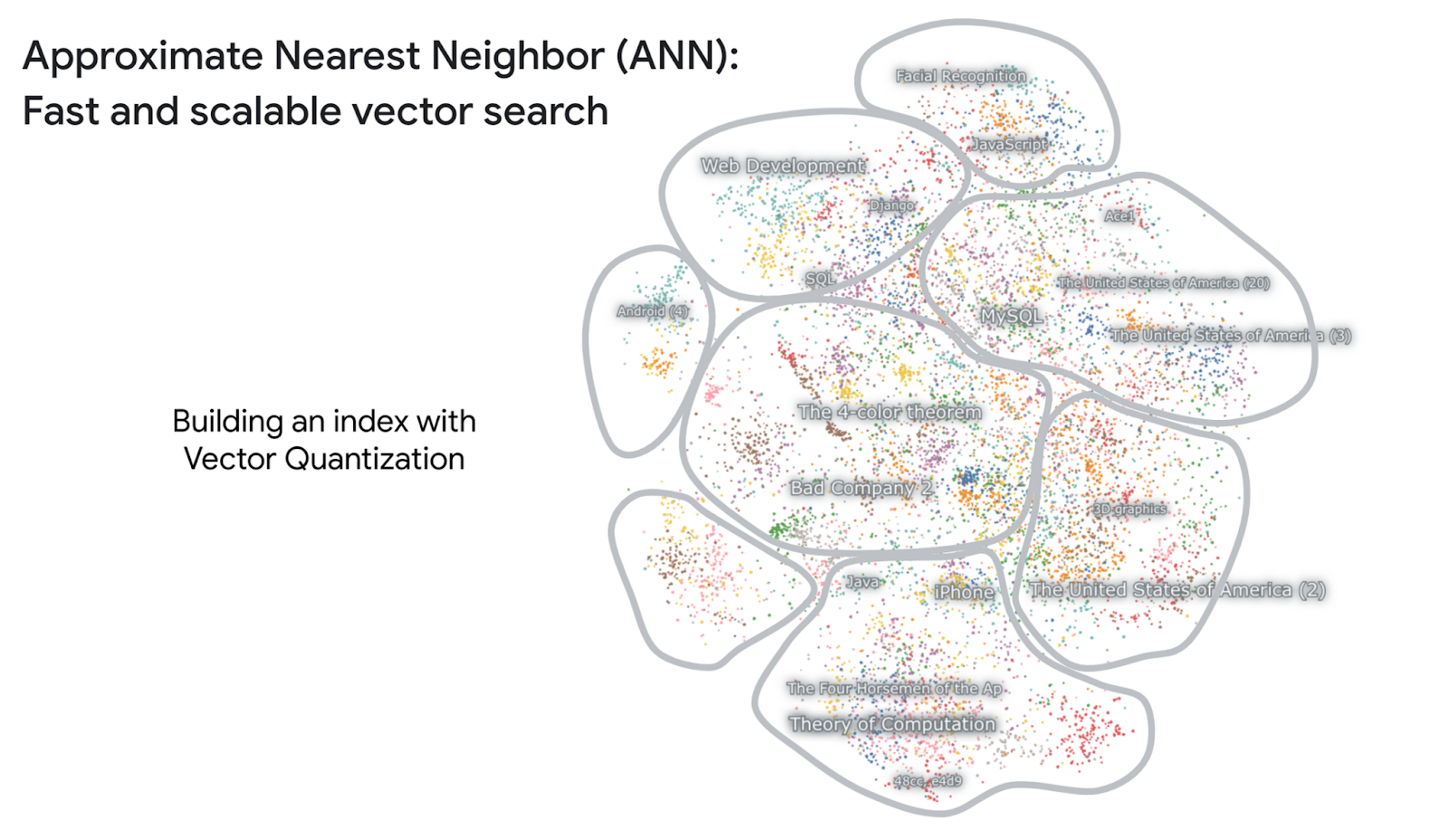
Vertex AI Vector Search 快速入门:简要介绍了 Vector Search。此快速入门面向刚开始接触该平台且希望快速上手的用户。 |
文本嵌入和 Vector Search 使用入门:介绍了文本嵌入和 Vector Search。此使用入门介绍了这些技术的工作原理,以及如何利用这些技术来改进搜索结果。 |

|
|
|
结合使用语义搜索和关键字搜索:使用 Vertex AI Vector Search 实现混合搜索的教程:提供有关如何使用 Vector Search 实现混合搜索的说明。 此教程介绍了设置和配置混合搜索系统所涉及的步骤。 |
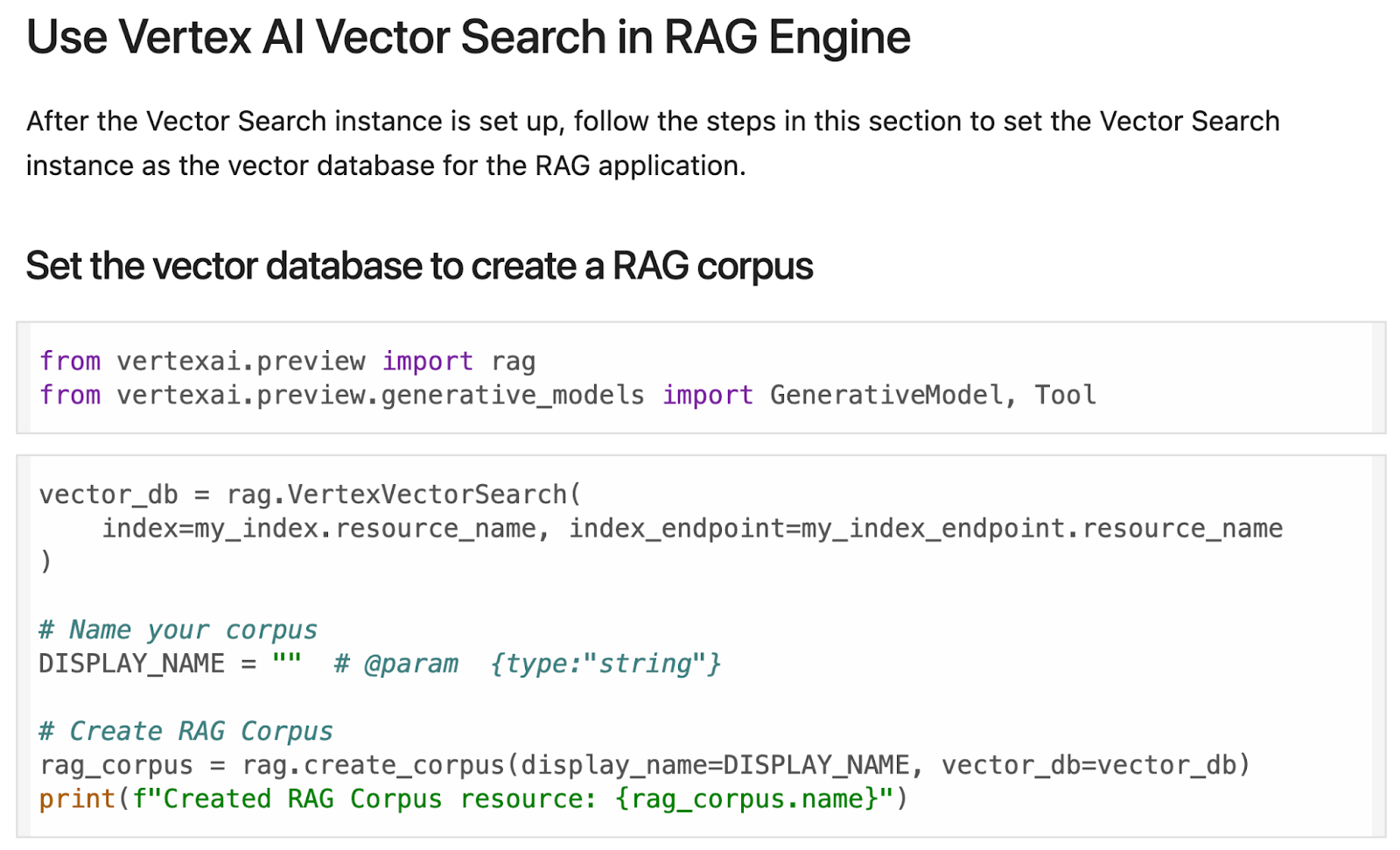
将 Vertex AI RAG Engine 与 Vector Search 结合使用:探索如何将 Vertex AI RAG Engine 与 Vector Search 结合使用。 本文介绍了将这两种技术结合使用的好处,并提供了示例,说明如何在实际应用中使用这两种技术。 |
|
|
|
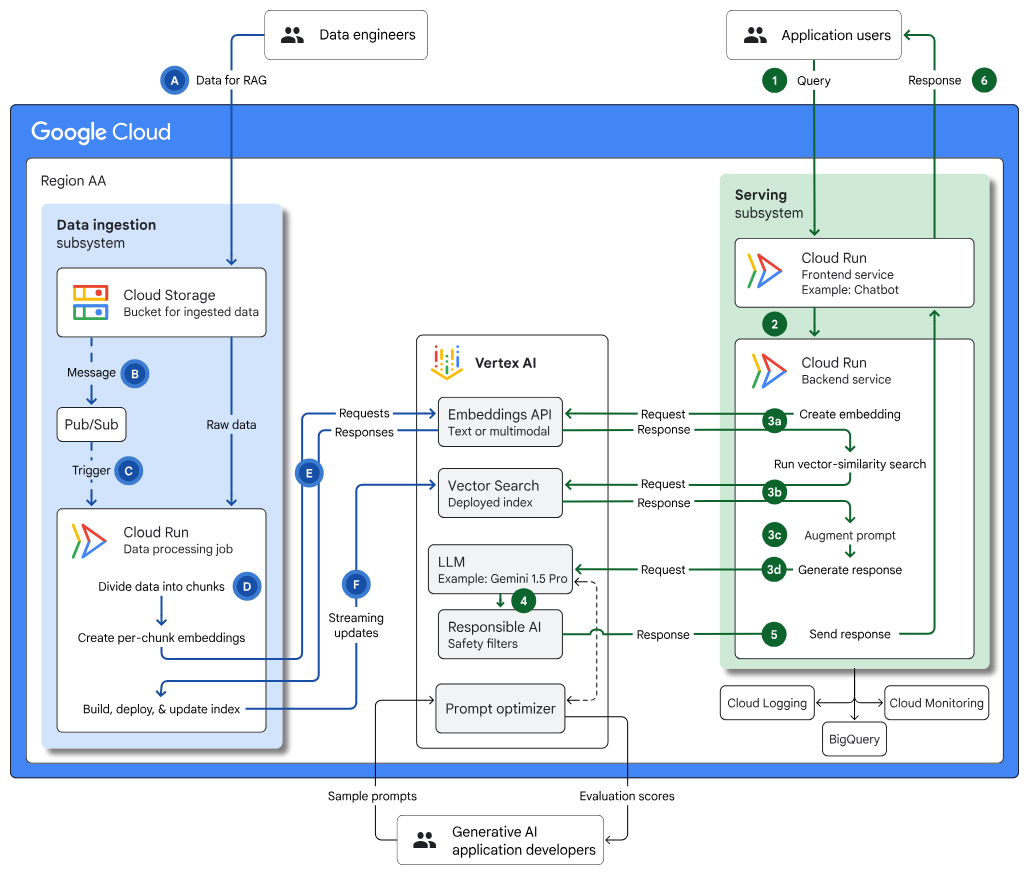
使用 Vertex AI 和 Vector Search 且支持 RAG 的生成式 AI 应用的基础设施:详细介绍了使用 Vector Search、Cloud Run 和 Cloud Storage 构建生成式 AI 应用和 RAG 的架构,涵盖了用例、设计选项和主要注意事项。 |
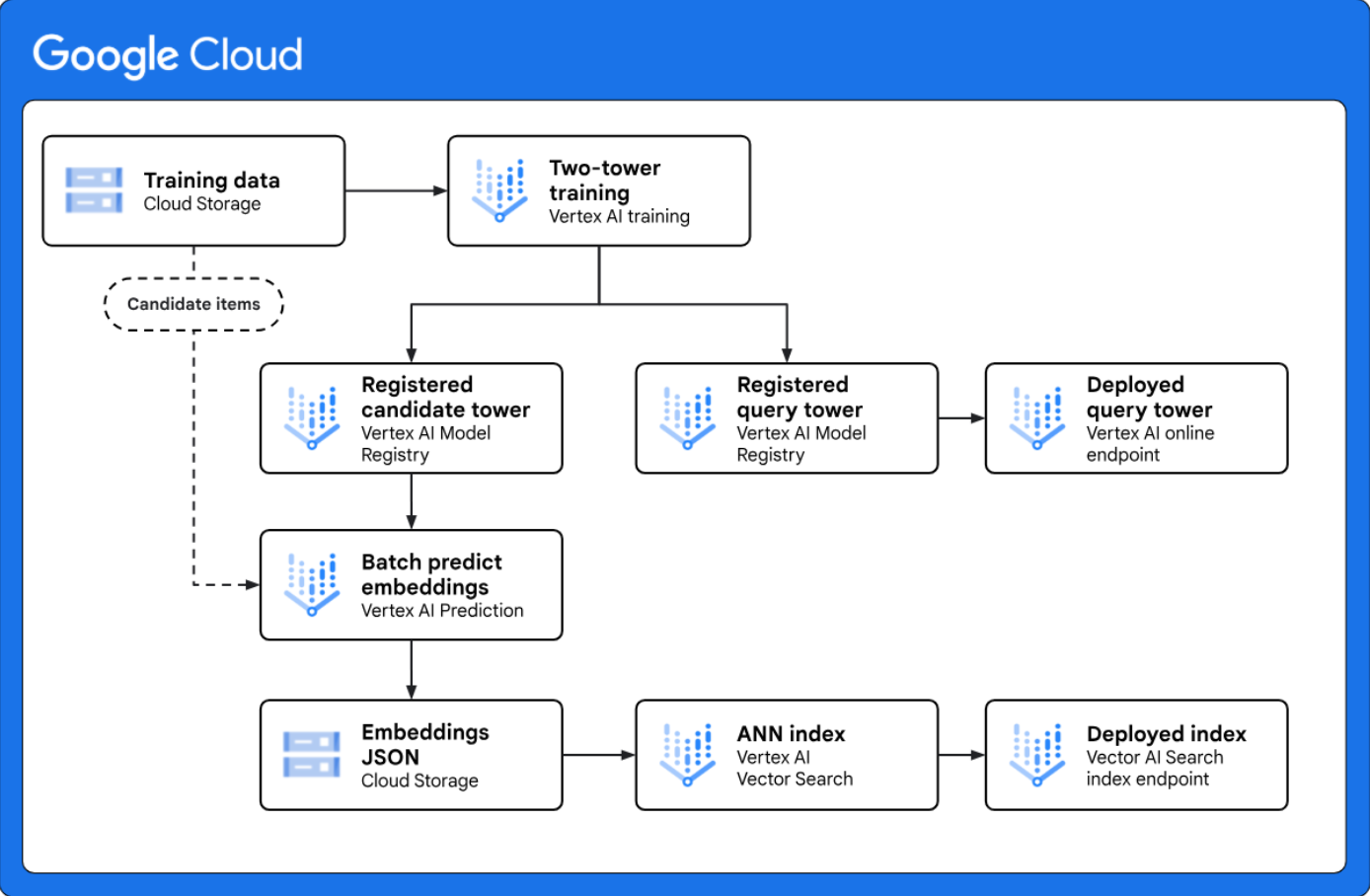
通过双塔检索实现大规模候选集生成: 提供了一个参考架构,展示了如何使用 Vertex AI 实现端到端双塔候选集生成工作流。双塔建模框架是一种强大的检索技术,适用于个性化应用场景,因为它可学习两个不同实体(例如 Web 查询和候选项)之间的语义相似度。 |
培训
Vector Search 和嵌入使用入门 Vector Search 用于查找类似或相关的项。它可以用于推荐、搜索、聊天机器人和文本分类。该过程涉及创建嵌入、将其上传到 Google Cloud,并为其编制索引以进行查询。此实验侧重于如何使用 Vertex AI 生成文本嵌入,但也可以为其他数据类型生成嵌入。
Vector Search 和嵌入 此课程介绍了 Vector Search,并说明了如何使用 Vertex AI Vector Search 通过用于嵌入的大语言模型 (LLM) API 来构建搜索应用。此课程包括以下内容:有关 Vector Search 和文本嵌入的概念性课程、有关如何在 Vertex AI 上构建 Vector Search 的实用演示以及实操实验。
了解和应用文本嵌入
Vertex AI Embeddings API 会生成文本嵌入,
即文本的数值表示法,用于执行相似项识别等任务。
在此课程中,您将使用文本嵌入来执行分类和语义搜索等任务,并将语义搜索与 LLM 相结合,以使用 Vertex AI 构建问答系统。
机器学习速成课程:嵌入 此课程介绍了字词嵌入,并将其与稀疏表示进行对比。此课程探索了获取嵌入的方法,并区分了静态嵌入和上下文嵌入。
相关产品
Vertex AI 嵌入:简要介绍了 Embeddings API。文本和多模态嵌入用例,以及指向其他资源和相关 Google Cloud 服务的链接。
Vertex AI Search Ranking API 该 Ranking API 会使用预训练语言模型根据与查询的相关性对文档进行重新排名,并提供精确的得分。它非常适合用于改进来自各种来源(包括 Vector Search)的搜索结果。
Vertex AI Feature Store 让您可以使用 BigQuery 作为数据源来管理和传送特征数据。它会为在线传送预配资源,并充当元数据层,以便直接从 BigQuery 传送最新的特征值。使用 Feature Store 可即时检索 Vector Store 针对查询返回的项的特征值。
Vertex AI Pipelines 借助 Vertex AI Pipelines,您可以使用机器学习流水线编排机器学习工作流,从而以无服务器方式实现机器学习系统的自动化、监控和治理。您可以批量运行使用 Kubeflow Pipelines 或 TensorFlow Extended (TFX) 框架定义的机器学习流水线。借助流水线,您可以构建自动化流水线,以便生成嵌入、创建和更新 Vector Search 索引,以及为生产搜索和推荐系统构成 MLOps 设置。
深入探究资源
使用 Vertex AI 嵌入和任务类型增强您的生成式 AI 用例 侧重于如何使用 Vertex AI 嵌入和任务类型改进生成式 AI 应用。Vector Search 可与任务类型嵌入结合使用,通过查找更多相关信息来增强生成内容的上下文和准确性。
TensorFlow Recommender 用于构建推荐系统的开源库。它简化了从数据准备到部署的过程,并支持灵活的模型构建。TFRS 提供教程和资源,并支持创建复杂的推荐模型。
TensorFlow Ranking TensorFlow Ranking 是一个开源库,用于构建可伸缩的神经 learning-to-rank (LTR) 模型。它支持各种损失函数和排名指标,可应用于搜索、推荐和其他领域。该库由 Google AI 积极开发。
正式推出 ScaNN:高效的向量相似性搜索 Google 的 ScaNN 是一种高效的向量相似性搜索算法,它利用一种新技术来提高查找最近邻的准确性和速度。它优于现有方法,并且在需要语义搜索的机器学习任务中具有广泛的应用。Google 的研究工作涵盖了各个领域,包括基础机器学习和 AI 的社会影响。
SOAR:用于通过 ScaNN 实现更快的 Vector Search 的新算法 Google 的 SOAR 算法通过引入受控冗余来提高 Vector Search 效率,从而能够使用较小的索引实现更快的搜索。SOAR 会将向量分配给多个聚类,从而创建“备份”搜索路径以提高性能。
相关视频
使用 Vertex AI 的 Vector Search 的使用入门
Vector Search 是一款功能强大的工具,可用于构建依托 AI 技术的应用。此视频介绍了该技术,并提供了入门分步指南。
Vector Search 可用于混合搜索,让您能够将 Vector Search 的强大功能与传统搜索引擎的灵活性和速度相结合。此视频介绍了混合搜索,并向您展示了如何使用 Vector Search 进行混合搜索。
您已在使用 Vector Search!下面介绍了如何成为专家
您知道吗?您可能每天都在使用 Vector Search,只是没有意识到?从在社交媒体上查找难以捉摸的商品,到追踪脑海中挥之不去的歌曲,Vector Search 是这些日常体验背后的 AI 魔法。
DeepMind 团队推出了新的“任务类型”嵌入功能,可提高 RAG 搜索质量
借助 Google DeepMind 团队开发的新任务类型嵌入,提高 RAG 系统的准确性和相关性。观看视频,了解 RAG 搜索质量中存在的常见难题,以及任务类型嵌入如何有效地弥合问题和答案之间的语义差距,从而实现更有效的检索和增强的 RAG 性能。
Vector Search 术语
以下列表包含一些重要的术语,您需要了解这些术语才能使用 Vector Search:
向量:向量是带有幅度和方向的浮点值列表。它可用于表示任何类型的数据,例如数字、空间中的点和方向。
嵌入:嵌入是一种向量类型,用于通过捕获数据的语义含义来表示数据。嵌入通常是使用机器学习技术创建的,通常用于自然语言处理 (NLP) 和其他机器学习应用。
密集嵌入:密集嵌入使用主要包含非零值的数组来表示文本的语义含义。借助密集嵌入,可以根据语义相似性返回类似的搜索结果。
稀疏嵌入:稀疏嵌入使用高维数组来表示文本语法,与密集嵌入相比,其中包含的非零值非常少。稀疏嵌入通常用于关键字搜索。
混合搜索:混合搜索同时使用密集嵌入和稀疏嵌入,可让您基于关键字搜索和语义搜索的组合进行搜索。Vector Search 支持基于密集嵌入、稀疏嵌入和混合搜索进行搜索。
索引:为相似度搜索而部署的一组向量。可以在索引中添加或移除向量。相似度搜索查询会被发送到特定索引,并搜索该索引中的向量。
标准答案:该术语是指根据真实世界(例如标准答案数据集)验证机器学习的准确率。
召回率:索引返回的最近邻的百分比,这些最近邻实际上是真正的最近邻。例如,如果一个对 20 个最近邻的最近邻查询返回 19 个标准答案最近邻项,则召回率为 19/20x100 = 95%。
限制:使用布尔值规则将搜索限制为索引的子集的功能。限制也称为“过滤”。借助 Vector Search,您可以使用数字过滤和文本属性过滤。