In Vector Search können Sie mithilfe von booleschen Regeln die Suche nach Vektorähnlichkeiten auf eine Teilmenge des Index beschränken. Boolesche Prädikate teilen der Vektorsuche mit, welche Vektoren im Index ignoriert werden sollen. Auf dieser Seite erfahren Sie mehr über die Funktionsweise des Filterns und können sich Beispiele und Möglichkeiten zur effizienten Abfrage von Daten basierend auf Vektorähnlichkeiten ansehen.
Mit der Vektorsuche können Sie Ergebnisse nach kategorialen und numerischen Einschränkungen einschränken. Das Hinzufügen von Einschränkungen oder das „Filtern“ Ihrer Indexergebnisse ist aus verschiedenen Gründen hilfreich, wie in den folgenden Beispielen:
Verbesserte Ergebnisrelevanz: Die Vektorsuche ist ein leistungsstarkes Tool zum Auffinden semantisch ähnlicher Elemente. Mithilfe von Filtern können irrelevante Ergebnisse aus den Suchergebnissen entfernt werden, z. B. Elemente, die nicht in der richtigen Sprache, Kategorie, Preis oder demselben Zeitraum liegen.
Geringere Anzahl an Ergebnissen: Die Vektorsuche kann eine große Anzahl von Ergebnissen zurückgeben, insbesondere bei großen Datasets. Mit Filtern lässt sich die Anzahl der Ergebnisse auf eine überschaubare Menge reduzieren, während die relevantesten Ergebnisse weiterhin zurückgegeben werden.
Segmentierte Ergebnisse: Mithilfe von Filtern können die Suchergebnisse an die individuellen Anforderungen und Einstellungen des Nutzers angepasst werden. Ein Nutzer möchte die Ergebnisse beispielsweise so filtern, dass nur Elemente angezeigt werden, die er in der Vergangenheit gut bewertet hat oder die in eine bestimmte Preisklasse fallen.
Vektorattribute
Bei einer Vektorähnlichkeitssuche in einer Datenbank mit Vektoren wird jeder Vektor durch null oder mehr Attribute beschrieben. Diese Attribute werden als Tokens für Token-Einschränkungen und als Werte für numerische Einschränkungen bezeichnet. Diese Einschränkungen können aus verschiedenen Attributkategorien, auch Namespaces genannt, stammen.
In der folgenden Beispielanwendung sind Vektoren mit color, price und shape getaggt:
color,price, undshapesind Namespaces.redundbluesind Tokens aus demcolor-Namespace.squareundcirclesind Tokens aus demshape-Namespace.100und50sind Werte aus demprice-Namespace.
Vektorattribute angeben
- So geben Sie einen „roten Kreis “ an:
{color: red}, {shape: circle}. - So geben Sie ein „ rotes und blaues Quadrat“ an:
{color: red, blue}, {shape: square}. - Wenn Sie ein Objekt ohne Farbe angeben möchten, lassen Sie den Namespace „Farbe“ im Feld
restrictsweg. - Wenn Sie numerische Einschränkungen für ein Objekt angeben möchten, notieren Sie sich den Namespace und den Wert im entsprechenden Feld für den Typ. Der Ganzzahlwert muss in
value_int, der Gleitkommawert invalue_floatund der doppelte Wert invalue_doubleangegeben werden. Für einen bestimmten Namespace sollte nur ein Zahlentyp verwendet werden.
Informationen zu dem Schema, das zum Angeben dieser Daten verwendet wird, finden Sie unter Namespaces und Tokens in den Eingabedaten angeben.
Abfragen
- Abfragen drücken einen logischen UND-Operator über Namespaces hinweg und einen logischen OR-Operator innerhalb jedes Namespace aus. Eine Abfrage, die
{color: red, blue}, {shape: square, circle}angibt, stimmt mit allen Datenbankpunkten überein, die(red || blue) && (square || circle)erfüllen. - Eine Abfrage, die
{color: red}angibt, Übereinstimmungen werden mit allenred-Objekten ohne Einschränkung beishapeabgeglichen. - Für numerische Einschränkungen in Abfragen sind
namespace, einer der numerischen Werte ausvalue_int,value_floatundvalue_doublesowie der Operatoroperforderlich. - Der Operator
opist einer der folgenden:LESS,LESS_EQUAL,EQUAL,GREATER_EQUALundGREATER. Wenn beispielsweise der OperatorLESS_EQUALverwendet wird, kommen Datenpunkte infrage, deren Wert kleiner oder gleich dem in der Abfrage verwendeten Wert ist.
Die folgenden Codebeispiele identifizieren Vektorattribute in der Beispielanwendung:
[
{
"namespace": "price",
"value_int": 20,
"op": "LESS"
},
{
"namespace": "length",
"value_float": 0.3,
"op": "GREATER_EQUAL"
},
{
"namespace": "width",
"value_double": 0.5,
"op": "EQUAL"
}
]
Sperrliste
Für komplexere Szenarien unterstützt Google eine Form der Negation, die als Sperrlisten-Tokens bezeichnet wird. Wenn eine Abfrage ein Token in die Sperrliste aufnimmt, werden Übereinstimmungen für jeden Datenpunkt ausgeschlossen, der das Sperrlisten-Token enthält. Wenn ein Abfrage-Namespace nur Sperrlisten-Tokens enthält, stimmen alle Punkte, die nicht explizit auf die Sperrliste gesetzt wurden, genau auf dieselbe Weise überein wie ein leerer Namespace mit allen Punkten übereinstimmt.
Datenpunkte können auch ein Token auf die Sperrliste setzen und Übereinstimmungen mit jeder Abfrage, die dieses Token enthält, ausschließen.
Definieren Sie beispielsweise die folgenden Datenpunkte mit den angegebenen Tokens:
A: {} // empty set matches everything
B: {red} // only a 'red' token
C: {blue} // only a 'blue' token
D: {orange} // only an 'orange' token
E: {red, blue} // multiple tokens
F: {red, !blue} // deny the 'blue' token
G: {red, blue, !blue} // An unlikely edge-case
H: {!blue} // deny-only (similar to empty-set)
Das System verhält sich so:
- Leere Abfrage-Namespaces sind universell übereinstimmende Platzhalter. Beispielsweise stimmt Q:
{}mit DB:{color:red}überein. Leere Datenpunkt-Namespaces sind keine universell übereinstimmende Platzhalter. Q:
{color:red}stimmt beispielsweise nicht mit DB:{}überein.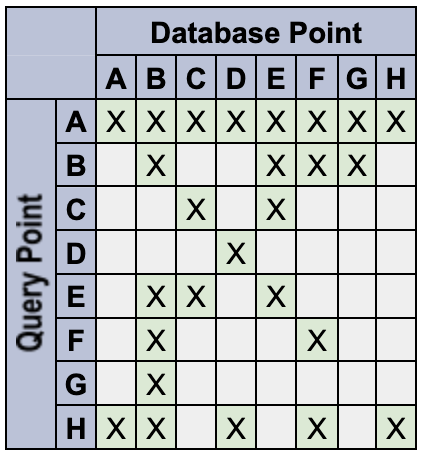
Namespaces und Tokens oder Werte in den Eingabedaten angeben
Informationen zur Strukturierung Ihrer Eingabedaten finden Sie unter Format und Struktur der Eingabedaten.
Auf den folgenden Tabs wird gezeigt, wie Sie die Namespaces und Tokens angeben, die mit jedem Eingabevektor verknüpft sind.
JSON
Fügen Sie für den Datensatz jedes Vektors ein Feld namens
restrictshinzu, das ein Array von Objekten enthält, die jeweils ein Namespace sind.- Jedes Objekt muss ein Feld mit dem Namen
namespacehaben. Dieses Feld ist der NamespaceTokenNamespace.namespace. - Der Wert des Felds
allow, falls vorhanden, ist ein Array von Strings. Dieses Array von Strings ist die ListeTokenNamespace.string_tokens. - Der Wert des Felds
deny, falls vorhanden, ist ein Array von Strings. Dieses Array von Strings ist die ListeTokenNamespace.string_denylist_tokens.
- Jedes Objekt muss ein Feld mit dem Namen
Im Folgenden finden Sie zwei Beispieleinträge im JSON-Format:
[
{
"id": "42",
"embedding": [
0.5,
1
],
"restricts": [
{
"namespace": "class",
"allow": [
"cat",
"pet"
]
},
{
"namespace": "category",
"allow": [
"feline"
]
}
]
},
{
"id": "43",
"embedding": [
0.6,
1
],
"sparse_embedding": {
"values": [
0.1,
0.2
],
"dimensions": [
1,
4
]
},
"restricts": [
{
"namespace": "class",
"allow": [
"dog",
"pet"
]
},
{
"namespace": "category",
"allow": [
"canine"
]
}
]
}
]
Fügen Sie für den Datensatz jedes Vektors ein Feld namens
numeric_restrictshinzu, das ein Array von Objekten enthält, die jeweils eine numerische Beschränkung sind.- Jedes Objekt muss ein Feld mit dem Namen
namespacehaben. Dieses Feld ist der NamespaceNumericRestrictNamespace.namespace. - Jedes Objekt muss eines der folgenden Elemente enthalten:
value_int,value_floatundvalue_double. - Jedes Objekt darf kein Feld mit dem Namen
ophaben. Dieses Feld ist nur für Abfragen vorgesehen.
- Jedes Objekt muss ein Feld mit dem Namen
Im Folgenden finden Sie zwei Beispieleinträge im JSON-Format:
[
{
"id": "42",
"embedding": [
0.5,
1
],
"numeric_restricts": [
{
"namespace": "size",
"value_int": 3
},
{
"namespace": "ratio",
"value_float": 0.1
}
]
},
{
"id": "43",
"embedding": [
0.6,
1
],
"sparse_embedding": {
"values": [
0.1,
0.2
],
"numeric_restricts": [
{
"namespace": "weight",
"value_double": 0.3
}
]
}
}
]
Avro
Avro-Datensätze verwenden das folgende Schema:
{
"type": "record",
"name": "FeatureVector",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "embedding",
"type": {
"type": "array",
"items": "float"
}
},
{
"name": "sparse_embedding",
"type": [
"null",
{
"type": "record",
"name": "sparse_embedding",
"fields": [
{
"name": "values",
"type": {
"type": "array",
"items": "float"
}
},
{
"name": "dimensions",
"type": {
"type": "array",
"items": "long"
}
}
]
}
]
},
{
"name": "restricts",
"type": [
"null",
{
"type": "array",
"items": {
"type": "record",
"name": "Restrict",
"fields": [
{
"name": "namespace",
"type": "string"
},
{
"name": "allow",
"type": [
"null",
{
"type": "array",
"items": "string"
}
]
},
{
"name": "deny",
"type": [
"null",
{
"type": "array",
"items": "string"
}
]
}
]
}
}
]
},
{
"name": "numeric_restricts",
"type": [
"null",
{
"type": "array",
"items": {
"name": "NumericRestrict",
"type": "record",
"fields": [
{
"name": "namespace",
"type": "string"
},
{
"name": "value_int",
"type": [ "null", "int" ],
"default": null
},
{
"name": "value_float",
"type": [ "null", "float" ],
"default": null
},
{
"name": "value_double",
"type": [ "null", "double" ],
"default": null
}
]
}
}
],
"default": null
},
{
"name": "crowding_tag",
"type": [
"null",
"string"
]
}
]
}
CSV
Tokeneinschränkungen
Fügen Sie für den Eintrag jedes Vektors kommagetrennte Paare des Formats
name=valuehinzu, um Token-Namespace-Einschränkungen anzugeben. Derselbe Name kann wiederholt werden, wenn ein Namespace mehrere Werte enthält.Beispielsweise steht
color=red,color=bluefür diesenTokenNamespace:{ "namespace": "color" "string_tokens": ["red", "blue"] }Fügen Sie für den Eintrag jedes Vektors kommagetrennte Paare des Formats
name=!valuehinzu, um den Ausschlusswert für Token-Namespace-Einschränkungen anzugeben.Beispielsweise steht
color=!redfür diesenTokenNamespace:{ "namespace": "color" "string_blacklist_tokens": ["red"] }
Numerische Einschränkungen
Fügen Sie für den Datensatz jedes Vektors kommagetrennte Paare des Formats
#name=numericValuemit dem Zahlentypsuffix hinzu, um numerische Namespace-Einschränkungen anzugeben.Das Zahlentypsuffix ist
ifür Ganzzahl,ffür Gleitkommazahl unddfür Double. Derselbe Name sollte nicht wiederholt werden, da jedem Namespace ein einzelner Wert zugeordnet sein sollte.Beispielsweise steht
#size=3ifür diesenNumericRestrictNamespace:{ "namespace": "size" "value_int": 3 }#ratio=0.1fsteht für dieseNumericRestrictNamespace:{ "namespace": "ratio" "value_float": 0.1 }#weight=0.3dsteht für dieseNumericRestriction:{ "namespace": "weight" "value_double": 0.3 }Hier ist ein Beispiel für einen Datenpunkt mit
id: "6",embedding: [7, -8.1],sparse_embedding: {values: [0.1, -0.2, 0.5],dimensions: [40, 901, 1111]}}, dem crowding-Tagtest, der Token-Zulassungslistecolor: red, blue, der Token-Sperrlistecolor: purpleund der numerischen Einschränkungratiomit dem Gleitkommawert0.1:6,7,-8.1,40:0.1,901:-0.2,1111:0.5,crowding_tag=test,color=red,color=blue,color=!purple, ratio=0.1f