Questa guida mostra come eseguire un job di ricerca di architetture neurali di Vertex AI utilizzando gli spazi di ricerca predefiniti di Google e il codice di addestramento predefinito basato su TF-vision per MnasNet e SpineNet. Per esempi end-to-end, consulta il notebook di classificazione MnasNet e il notebook di rilevamento di oggetti SpineNet.
Preparazione dei dati per l'addestratore precompilato
L'addestratore predefinito di Neural Architecture Search richiede che i dati siano in formato TFRecord e contengano tf.train.Example. I tf.train.Example devono includere i seguenti campi:
'image/encoded': tf.FixedLenFeature(tf.string)
'image/height': tf.FixedLenFeature(tf.int64)
'image/width': tf.FixedLenFeature(tf.int64)
# For image classification only.
'image/class/label': tf.FixedLenFeature(tf.int64)
# For object detection only.
'image/object/bbox/xmin': tf.VarLenFeature(tf.float32)
'image/object/bbox/xmax': tf.VarLenFeature(tf.float32)
'image/object/bbox/ymin': tf.VarLenFeature(tf.float32)
'image/object/bbox/ymax': tf.VarLenFeature(tf.float32)
'image/object/class/label': tf.VarLenFeature(tf.int64)
Puoi seguire le istruzioni per la preparazione dei dati di ImageNet qui.
Per convertire i dati personalizzati, utilizza lo script di analisi incluso nel codice di esempio e nelle utilità che hai scaricato. Per personalizzare l'analisi dei dati, modifica i file tf_vision/dataloaders/*_input.py.
Scopri di più su
TFRecord e tf.train.Example.
Definisci le variabili di ambiente dell'esperimento
Prima di eseguire gli esperimenti, devi definire diverse variabili di ambiente, tra cui:
- TRAINER_DOCKER_ID:
${USER}_nas_experiment(formato consigliato) Posizioni di Cloud Storage dei set di dati di addestramento e convalida che verranno utilizzati dall'esperimento. Ad esempio (CoCo per il rilevamento):
gs://cloud-samples-data/ai-platform/built-in/image/coco/train*gs://cloud-samples-data/ai-platform/built-in/image/coco/val*
Percorso di Cloud Storage per l'output dell'esperimento. Formato consigliato:
gs://${USER}_nas_experiment
REGION: una regione che deve corrispondere alla regione del bucket di output dell'esperimento. Ad esempio:
us-central1.PARAM_OVERRIDE: un file .yaml che sostituisce i parametri dell'addestratore precompilato. Neural Architecture Search fornisce alcune configurazioni predefinite che puoi utilizzare:
PROJECT_ID=PROJECT_ID
TRAINER_DOCKER_ID=TRAINER_DOCKER_ID
LATENCY_CALCULATOR_DOCKER_ID=LATENCY_CALCULATOR_DOCKER_ID
GCS_ROOT_DIR=OUTPUT_DIR
REGION=REGION
PARAM_OVERRIDE=tf_vision/configs/experiments/spinenet_search_gpu.yaml
TRAINING_DATA_PATH=gs://PATH_TO_TRAINING_DATA
VALIDATION_DATA_PATH=gs://PATH_TO_VALIDATION_DATA
Ti consigliamo di selezionare e/o modificare il file di override che corrisponde ai tuoi requisiti di addestramento. Considera quanto segue:
- Puoi impostare
--accelerator_typeper scegliere tra GPU o CPU. Per eseguire solo alcune epoche per test rapidi utilizzando la CPU, puoi impostare il flag--accelerator_type=""e utilizzare il file di configurazionetf_vision/test_files/fast_nas_detection_spinenet_search_for_testing.yaml. - Numero di epoche
- Tempo di esecuzione dell'addestramento
- Iperparametri come il tasso di apprendimento
Per un elenco di tutti i parametri per controllare i job di addestramento, consulta
tf_vision/configs/. Di seguito sono riportati i parametri chiave:
task:
train_data:
global_batch_size: 80
validation_data:
global_batch_size: 16
init_checkpoint: null
trainer:
train_steps: 16634
steps_per_loop: 1386
optimizer_config:
learning_rate:
cosine:
initial_learning_rate: 0.16
decay_steps: 16634
type: 'cosine'
warmup:
type: 'linear'
linear:
warmup_learning_rate: 0.0067
warmup_steps: 1386
Crea un bucket Cloud Storage per la ricerca di architetture neurali in cui archiviare gli output dei job (ad es. i checkpoint):
gcloud storage buckets create $GCS_ROOT_DIR
Crea un container per l'addestramento e un container per il calcolo della latenza
Il seguente comando creerà un'immagine di trainer in Google Cloud con il seguente URI:
gcr.io/PROJECT_ID/TRAINER_DOCKER_ID che verrà utilizzato nel job di ricerca nell'architettura neurale nel
passaggio successivo.
python3 vertex_nas_cli.py build \
--project_id=PROJECT_ID \
--trainer_docker_id=TRAINER_DOCKER_ID \
--latency_calculator_docker_id=LATENCY_CALCULATOR_DOCKER_ID \
--trainer_docker_file=tf_vision/nas_multi_trial.Dockerfile \
--latency_calculator_docker_file=tf_vision/latency_computation_using_saved_model.Dockerfile
Per modificare lo spazio di ricerca e la ricompensa, aggiornali nel file Python e poi ricostruisci l'immagine Docker.
Prova il trainer localmente
Poiché il lancio di un job in Google Cloud service richiede diversi minuti, potrebbe essere più
conveniente testare il docker del trainer in locale, ad esempio con la convalida del formato
TFRecord. Utilizza lo spazio di ricerca spinenet come esempio. Puoi eseguire il job di ricerca localmente (il modello verrà campionato in modo casuale):
# Define the local job output dir.
JOB_DIR="/tmp/iod_${search_space}"
python3 vertex_nas_cli.py search_in_local \
--project_id=PROJECT_ID \
--trainer_docker_id=TRAINER_DOCKER_ID \
--prebuilt_search_space=spinenet \
--use_prebuilt_trainer=True \
--local_output_dir=${JOB_DIR} \
--search_docker_flags \
params_override="tf_vision/test_files/fast_nas_detection_spinenet_search_for_testing.yaml" \
training_data_path=TEST_COCO_TF_RECORD \
validation_data_path=TEST_COCO_TF_RECORD \
model=retinanet
training_data_path e validation_data_path sono i percorsi dei tuoi TFRecord.
Avvia una ricerca di fase 1 seguita da un job di addestramento di fase 2 su Google Cloud
Per esempi end-to-end, consulta il notebook di classificazione MnasNet e il notebook di rilevamento di oggetti SpineNet.
Puoi impostare i flag
--max_parallel_nas_triale--max_nas_trialper personalizzare. Neural Architecture Search inizieràmax_parallel_nas_trialprove in parallelo e terminerà dopomax_parallel_nas_trialprove.max_nas_trialSe il flag
--target_device_latency_msè impostato, verrà avviato un joblatency calculatorseparato con l'acceleratore specificato dal flag--target_device_type.Il controller Neural Architecture Search fornirà a ogni prova un suggerimento per una nuova architettura candidata tramite il FLAG
--nas_params_str.Ogni prova creerà un grafico in base al valore del FLAG
nas_params_stre avvierà un job di addestramento. Ogni prova salva il proprio valore anche in un file JSON (inos.path.join(nas_job_dir, str(trial_id), "nas_params_str.json")).
Premio con un vincolo di latenza
Il notebook di classificazione MnasNet mostra un esempio di ricerca con vincoli di latenza basata su dispositivi cloud-CPU.
Per cercare modelli con vincolo di latenza, l'addestratore può segnalare la ricompensa come funzione sia dell'accuratezza sia della latenza.
Nel codice sorgente condiviso, il premio viene calcolato come segue:
def compute_reward(target_latency, accuracy, inference_latency, weight=0.07):
"""Compute reward from accuracy and latency."""
speed_ratio = target_latency / inference_latency
return accuracy * (speed_ratio**weight)
Puoi utilizzare altre varianti del calcolo di reward nella pagina 3
del documento mnasnet.
target_device_typespecifica il tipo di dispositivo di destinazione supportato in Google Cloud, comeNVIDIA_TESLA_P100.use_prebuilt_latency_calculatorutilizza il nostro calcolatore della latenza predefinitotf_vision/latency_computation_using_saved_model.py.target_device_latency_msspecifica la latenza del dispositivo di destinazione.
Per informazioni su come personalizzare la funzione di calcolo della latenza, consulta tf_vision/latency_computation_using_saved_model.py.
Monitorare l'avanzamento del job Neural Architecture Search
Nella Google Cloud console, nella pagina del job, il grafico mostra il reward vs. trial number mentre la tabella mostra i premi per ogni prova. Puoi trovare le migliori prove con il premio più alto.
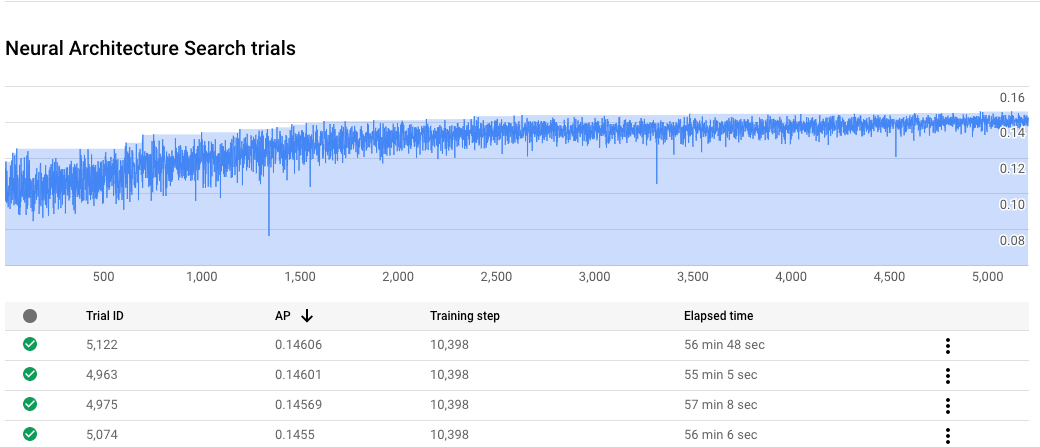
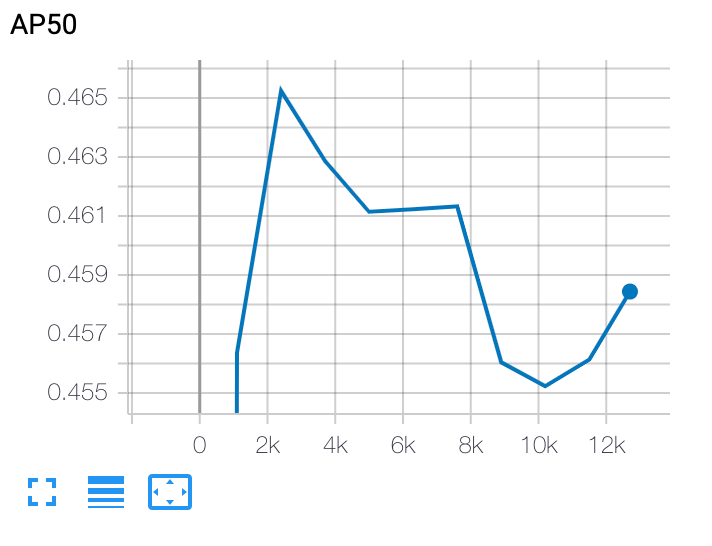
Grafica una curva di addestramento di fase 2
Dopo l'addestramento di secondo livello, utilizza Cloud Shell o Google Cloud
TensorBoard per tracciare la curva di addestramento indicando la directory del job:
Esegui il deployment di un modello selezionato
Per creare un SavedModel, puoi utilizzare lo script
export_saved_model.py
con
params_override=${GCS_ROOT_DIR}/${TRIAL_ID}/params.yaml.