Questa guida per principianti è un'introduzione all'addestramento personalizzato su Vertex AI. L'addestramento personalizzato si riferisce all'addestramento di un modello utilizzando un framework ML come TensorFlow, PyTorch o XGBoost.
Obiettivi di apprendimento
Livello di esperienza con Vertex AI: principiante
Tempo di lettura stimato: 15 minuti
Argomenti trattati:
- Vantaggi dell'utilizzo di un servizio gestito per l'addestramento personalizzato.
- Best practice per il packaging del codice di addestramento.
- Come inviare e monitorare un job di addestramento.
Perché utilizzare un servizio di addestramento gestito?
Immagina di lavorare a un nuovo problema di ML. Apri un notebook, importa i tuoi dati ed esegui l'esperimento. In questo scenario, crei un modello con il framework ML che preferisci ed esegui le celle del notebook per eseguire un ciclo di addestramento. Al termine dell'addestramento, valuti i risultati del modello, apporti modifiche e poi esegui nuovamente l'addestramento. Questo flusso di lavoro è utile per la sperimentazione, ma quando inizi a pensare di creare applicazioni di produzione con il machine learning, potresti scoprire che l'esecuzione manuale delle celle del notebook non è l'opzione più conveniente.
Ad esempio, se il set di dati e il modello sono di grandi dimensioni, potresti provare l'addestramento distribuito. Inoltre, in un ambiente di produzione è improbabile che dovrai addestrare il modello una sola volta. Nel tempo, addestrerai nuovamente il modello per assicurarti che rimanga aggiornato e continui a produrre risultati utili. Quando vuoi automatizzare gli esperimenti su larga scala o eseguire il retraining dei modelli per un'applicazione di produzione, l'utilizzo di un servizio di addestramento ML gestito semplificherà i tuoi flussi di lavoro.
Questa guida fornisce un'introduzione all'addestramento di modelli personalizzati su Vertex AI. Poiché il servizio di addestramento è completamente gestito, Vertex AI esegue automaticamente il provisioning delle risorse di calcolo, esegue l'attività di addestramento e garantisce l'eliminazione delle risorse di calcolo al termine del job di addestramento. Tieni presente che esistono ulteriori personalizzazioni, funzionalità e modi di interagire con il servizio che non sono trattati qui. Questa guida ha lo scopo di fornire una panoramica. Per maggiori dettagli, consulta la documentazione di Vertex AI Training.
Panoramica dell'addestramento personalizzato
L'addestramento di modelli personalizzati su Vertex AI segue questo flusso di lavoro standard:
Pacchettizza il codice dell'applicazione di addestramento.
Configura e invia il job di addestramento personalizzato.
Monitora il job di addestramento personalizzato.
Pacchettizzazione del codice dell'applicazione di addestramento
L'esecuzione di un job di addestramento personalizzato su Vertex AI viene eseguita con i container. I container sono pacchetti del codice dell'applicazione, in questo caso il codice di addestramento, insieme a dipendenze come versioni specifiche di librerie necessarie per eseguire il codice. Oltre a semplificare la gestione delle dipendenze, i container possono essere eseguiti virtualmente ovunque, consentendo una maggiore portabilità. Il packaging del codice di addestramento con i relativi parametri e dipendenze in un container per creare un componente portatile è un passaggio importante quando sposti le applicazioni ML dal prototipo alla produzione.
Prima di poter avviare un job di addestramento personalizzato, devi creare un pacchetto della tua applicazione di addestramento. In questo caso, l'applicazione di addestramento si riferisce a un file o a più file che eseguono attività come il caricamento dei dati, il pretrattamento dei dati, la definizione di un modello e l'esecuzione di un ciclo di addestramento. Il servizio di addestramento Vertex AI esegue qualsiasi codice tu fornisca, quindi spetta interamente a te decidere quali passaggi includere nell'applicazione di addestramento.
Vertex AI fornisce container predefiniti per TensorFlow, PyTorch, XGBoost e Scikit-learn. Questi container vengono aggiornati regolarmente e includono librerie comuni che potresti utilizzare nel codice di addestramento. Puoi scegliere di eseguire il codice di addestramento con uno di questi container oppure creare un container personalizzato con il codice di addestramento e le dipendenze preinstallate.
Esistono tre opzioni per il packaging del codice su Vertex AI:
- Invia un singolo file Python.
- Crea una distribuzione di origine Python.
- Utilizza container personalizzati.
File python
Questa opzione è adatta per esperimenti rapidi. Puoi utilizzare questa opzione se tutto il codice necessario per eseguire l'applicazione di addestramento si trova in un file Python e uno dei container di addestramento predefiniti di Vertex AI contiene tutte le librerie necessarie per eseguire l'applicazione. Per un esempio di pacchettizzazione dell'applicazione di addestramento come singolo file Python, consulta il tutorial del blocco note Addestramento personalizzato e inferenza batch.
Distribuzione di origine Python
Puoi creare una distribuzione di origine Python che contenga l'applicazione di addestramento. Memorizzerai la distribuzione dell'origine con il codice di addestramento e le dipendenze in un bucket Cloud Storage. Per un esempio di pacchettizzazione dell'applicazione di addestramento come distribuzione di origine Python, consulta il tutorial del blocco note Training, tuning and deploying a PyTorch classification model.
Container personalizzato
Questa opzione è utile quando vuoi avere un maggiore controllo sulla tua applicazione o magari vuoi eseguire codice non scritto in Python. In questo caso, devi scrivere un Dockerfile, creare l'immagine personalizzata ed eseguirne il push su Artifact Registry. Per un esempio di containerizzazione dell'applicazione di addestramento, consulta il tutorial del blocco note Profilare le prestazioni dell'addestramento del modello utilizzando Profiler.
Struttura consigliata per l'applicazione di addestramento
Se scegli di creare un pacchetto del codice come distribuzione di origine Python o come container personalizzato, ti consigliamo di strutturare l'applicazione nel seguente modo:
training-application-dir/
....setup.py
....Dockerfile
trainer/
....task.py
....model.py
....utils.py
Crea una directory per archiviare tutto il codice dell'applicazione di addestramento, in questo
caso, training-application-dir. Questa directory conterrà un file setup.py se utilizzi una distribuzione di codice sorgente Python o un file Dockerfile se utilizzi un container personalizzato.
In entrambi gli scenari, questa directory di livello superiore conterrà anche una sottodirectory trainer, che contiene tutto il codice per eseguire l'addestramento. All'interno di trainer,
task.py è l'entry point principale della tua applicazione. Questo file esegue l'addestramento
del modello. Puoi scegliere di inserire tutto il codice in questo file, ma per
le applicazioni di produzione è probabile che tu abbia file aggiuntivi, ad esempio
model.py, data.py, utils.py, per citarne alcuni.
Eseguire un allenamento personalizzato
I job di addestramento su Vertex AI eseguono automaticamente il provisioning delle risorse di calcolo, eseguono il codice dell'applicazione di addestramento e garantiscono l'eliminazione delle risorse di calcolo al termine del job di addestramento.
Man mano che crei flussi di lavoro più complessi, è probabile che utilizzerai l'SDK Vertex AI per Python per configurare, inviare e monitorare i job di addestramento. Tuttavia, la prima volta che esegui un job di addestramento personalizzato, può essere più facile utilizzare la console Google Cloud .
- Vai ad Addestramento nella sezione Vertex AI di Cloud Console. Puoi creare un nuovo job di addestramento facendo clic sul pulsante CREA.
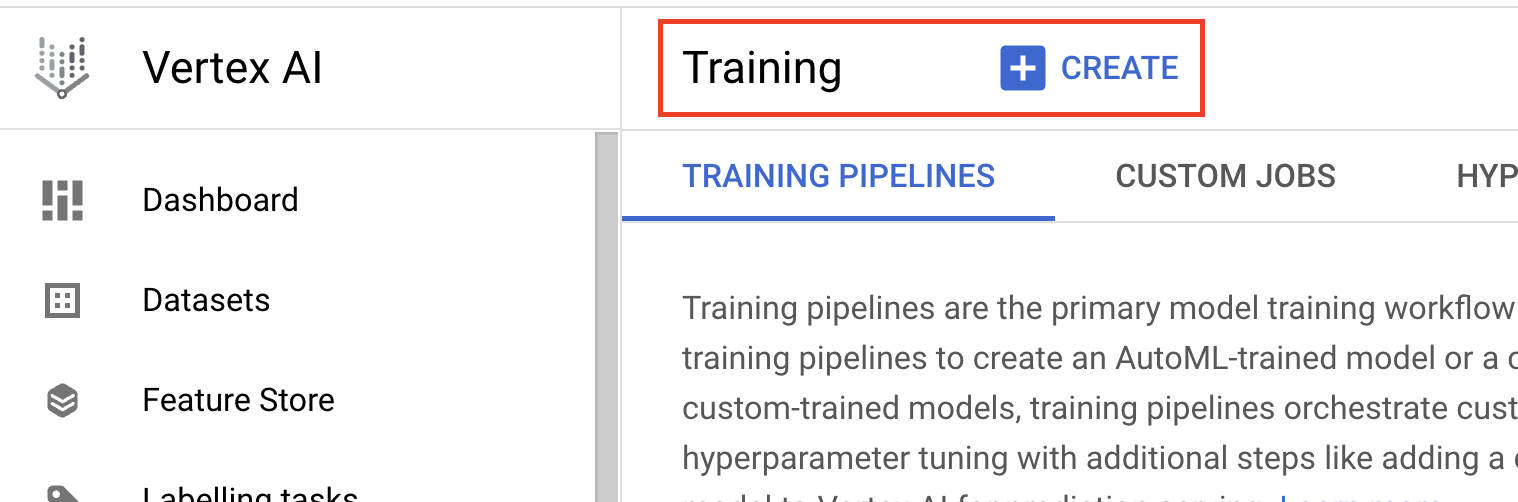
- In Metodo di addestramento del modello, seleziona Addestramento personalizzato (avanzato).
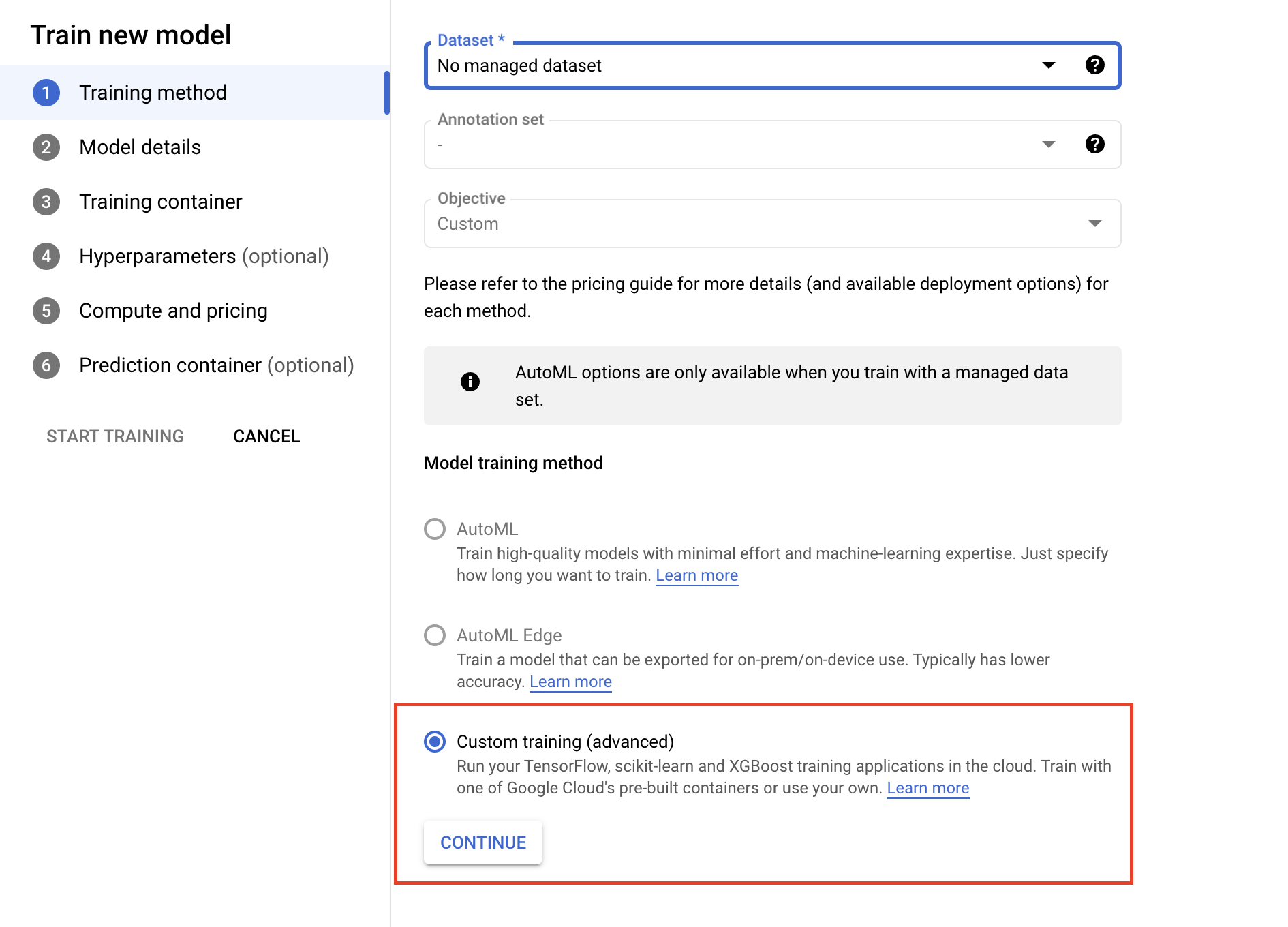
- Nella sezione Container di addestramento, seleziona il container predefinito o personalizzato, a seconda di come hai pacchettizzato l'applicazione.
- In Compute e prezzi, specifica l'hardware per il job di addestramento. Per l'addestramento con un nodo singolo, devi configurare solo il pool di worker 0. Se ti interessa eseguire l'addestramento distribuito, devi comprendere gli altri pool di worker. Per saperne di più, consulta la sezione Addestramento distribuito.
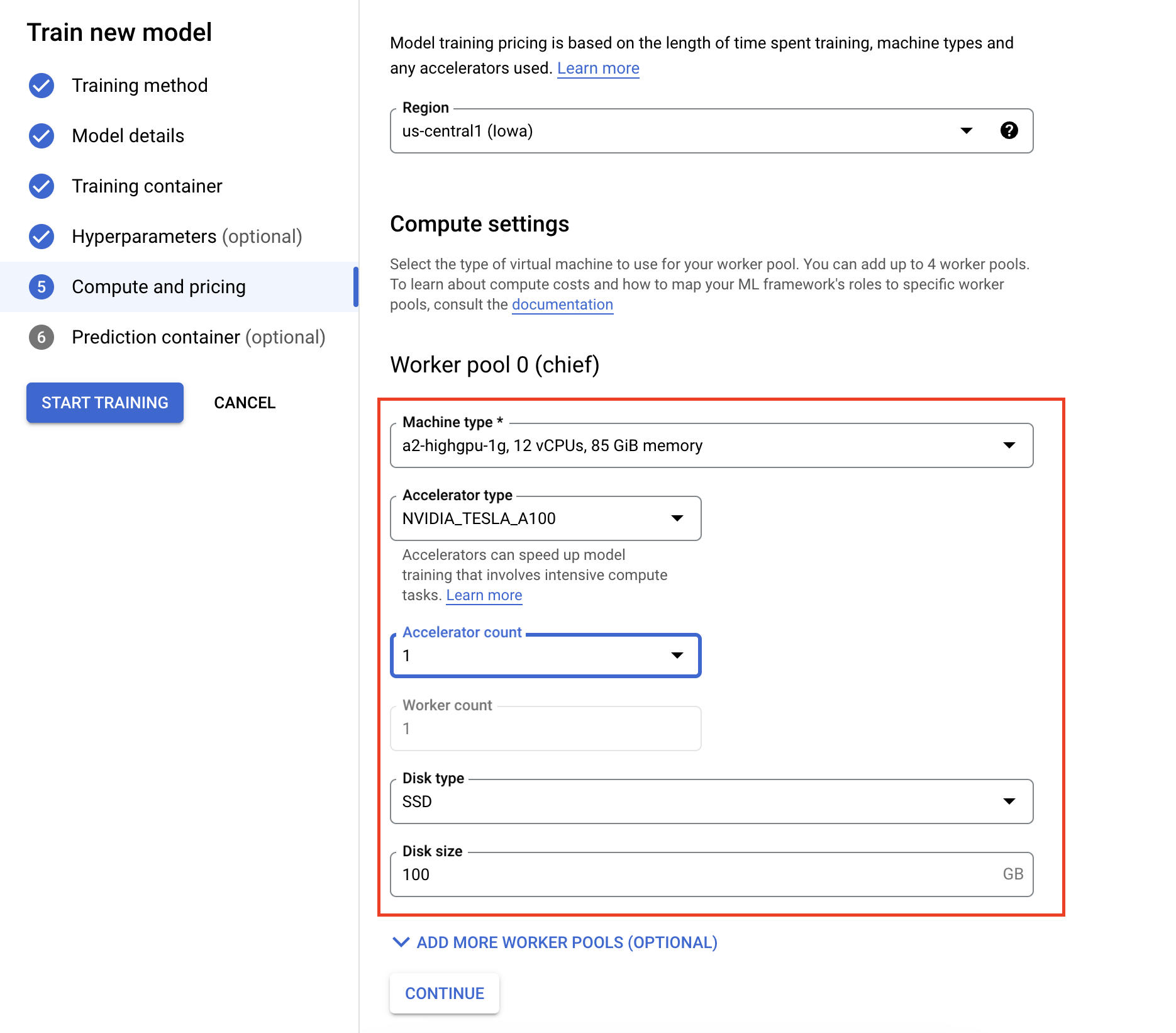
La configurazione del contenitore di inferenza è facoltativa. Se vuoi solo addestrare un modello su Vertex AI e accedere agli artefatti del modello salvato risultanti, puoi saltare questo passaggio. Se vuoi ospitare ed eseguire il deployment del modello risultante sul servizio di inferenza gestito Vertex AI, devi configurare un container di inferenza. Per saperne di più, vedi Ottenere inferenze da un modello con addestramento personalizzato.
Monitoraggio dei job di addestramento
Puoi monitorare il job di addestramento nella console Google Cloud . Vedrai un elenco di tutti i job eseguiti. Puoi fare clic su un job specifico ed esaminare i log in caso di problemi.