NVIDIA Triton auf Vertex AI
Vertex AI unterstützt die Bereitstellung von Modellen auf dem Triton-Inferenzserver, der in einem von NVIDIA GPU Cloud (NGC) veröffentlichten benutzerdefinierten Container ausgeführt wird – NVIDIA Triton Inference Server Image. Triton-Images von NVIDIA haben alle erforderlichen Pakete und Konfigurationen, die die Vertex AI-Anforderungen für benutzerdefinierte Bereitstellungs-Container-Images erfüllen. Das Image enthält den Triton-Inferenz-Server mit Unterstützung für TensorFlow-, PyTorch-, TensorRT-, ONNX- und OpenVINO-Modelle. Das Image enthält auch das FIL-Backend (Forest Inference Library), das die Ausführung von ML-Frameworks wie XGBoost, LightGBM und Scikit-Learn unterstützt.
Triton lädt die Modelle und macht Inferenz-, System- und Modellverwaltungs-REST-Endpunkte verfügbar, die Standard-Inferenzprotokolle verwenden. Bei der Bereitstellung eines Modells für Vertex AI erkennt Triton die Vertex AI-Umgebungen und übernimmt das Vertex AI Inference-Protokoll für Systemdiagnosen und Inferenzanfragen.
In der folgenden Liste sind die wichtigsten Features und Anwendungsfälle des NVIDIA Triton-Inferenzservers aufgeführt:
- Unterstützung für mehrere Deep Learning- und ML-Frameworks: Triton unterstützt den Einsatz mehrerer Modelle und eine Mischung aus Frameworks und Modellformaten – TensorFlow (SavedModel und GraphDef), PyTorch (TorchScript), TensorRT, ONNX, OpenVINO und FIL-Back-Ends zur Unterstützung von Frameworks wie XGBoost, LightGBM, Scikit-Learn und beliebigen benutzerdefinierten Python- oder C++-Modellformaten.
- Gleichzeitige Ausführung mehrerer Modelle: Triton ermöglicht die gleichzeitige Ausführung mehrerer Modelle, mehrerer Instanzen desselben Modells oder beider Modelle auf derselben Rechenressource mit null oder mehr GPUs.
- Modellsequenzierung (Verkettung oder Pipelineerstellung): Triton Ensemble unterstützt Anwendungsfälle, bei denen mehrere Modelle als Pipeline zusammengesetzt sind (oder ein DAG, gerichteter azyklischer Graph). mit Eingabe- und Ausgabetensoren, die zwischen ihnen verbunden sind. Darüber hinaus können Sie mit einem Triton Python-Backend beliebige Vor- und Nachverarbeitungs- oder Kontrollflusslogik einbinden, die durch Business Logic Scripting (BLS) definiert ist.
- Auf CPU- und GPU-Back-Ends ausführen: Triton unterstützt Inferenz für Modelle, die auf Knoten mit CPUs und GPUs bereitgestellt werden.
- Dynamische Batchverarbeitung von Inferenzanfragen:Bei Modellen, die Batching unterstützen, verfügt Triton über integrierte Planungs- und Batching-Algorithmen. Mit diesen Algorithmen werden einzelne Inferenzanfragen dynamisch in Batches auf der Serverseite kombiniert, um den Inferenzdurchsatz zu verbessern und die GPU-Auslastung zu erhöhen.
Weitere Informationen zum NVIDIA Triton-Inferenzserver finden Sie in der Dokumentation zu Triton.
Verfügbare NVIDIA Triton-Container-Images
Die folgende Tabelle zeigt die Triton Docker-Images, die im NVIDIA NGC-Katalog verfügbar sind. Wählen Sie ein Image anhand des Modell-Frameworks, des Back-Ends und der verwendeten Container-Image-Größe aus.
xx und yy beziehen sich auf Haupt- bzw. Nebenversionen von Triton.
| NVIDIA Triton-Image | Unterstützt |
|---|---|
xx.yy-py3 |
Vollständiger Container mit Unterstützung für TensorFlow-, PyTorch-, TensorRT-, ONNX- und OpenVINO-Modelle |
xx.yy-pyt-python-py3 |
Nur PyTorch- und Python-Back-Ends |
xx.yy-tf2-python-py3 |
Nur Back-Ends von TensorFlow 2.x und Python |
xx.yy-py3-min |
Triton-Container nach Bedarf anpassen |
Erste Schritte: Inferenz mit NVIDIA Triton bereitstellen
Die folgende Abbildung zeigt die Gesamtarchitektur von Triton auf Vertex AI Inference:
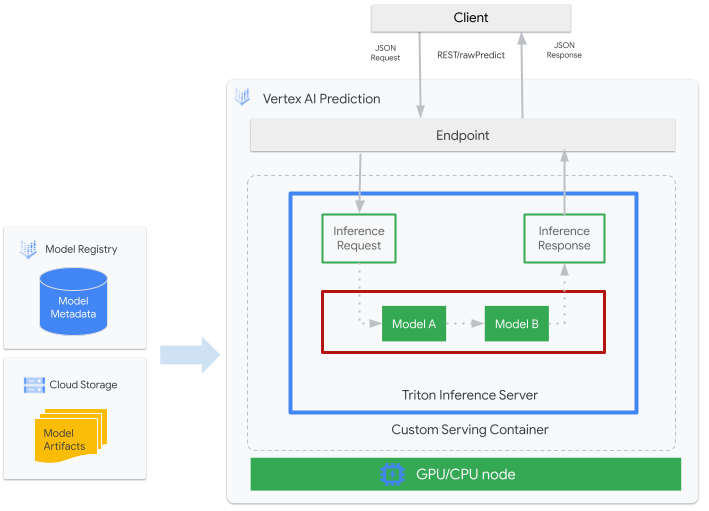
- Ein von Triton bereitgestelltes ML-Modell wird bei Vertex AI Model Registry registriert. Die Metadaten des Modells verweisen auf einen Speicherort der Modellartefakte in Cloud Storage, des benutzerdefinierten Bereitstellungscontainers und seiner Konfiguration.
- Das Modell aus Vertex AI Model Registry wird auf einem Vertex AI Inference-Endpunkt bereitgestellt, auf dem der Triton-Inferenzserver als benutzerdefinierter Container auf Compute-Knoten mit CPU und GPU ausgeführt wird.
- Inferenzanfragen erreichen den Triton-Inferenzserver über einen Vertex AI-Inferenzendpunkt und werden an den entsprechenden Planer weitergeleitet.
- Das Backend führt eine Inferenz mithilfe der in den Batch-Anfragen angegebenen Eingaben durch und gibt eine Antwort zurück.
- Triton bietet Bereitschafts- und Aktivitätsstatus-Endpunkte, die die Einbindung von Triton in Bereitstellungsumgebungen wie Vertex AI ermöglichen.
In dieser Anleitung erfahren Sie, wie Sie einen benutzerdefinierten Container mit NVIDIA Triton-Inferenzserver verwenden, um ein Modell für maschinelles Lernen (ML) auf Vertex AI bereitzustellen, das Onlineinferenzen liefert. Sie stellen einen Container bereit, in dem Triton ausgeführt wird, um Inferenzanfragen für ein Objekterkennungsmodell von TensorFlow Hub zu verarbeiten, das auf dem COCO 2017-Dataset vortrainiert wurde. Anschließend können Sie Vertex AI verwenden, um Objekte in einem Bild zu erkennen.
So führen Sie diese Anleitung in Form eines Notebooks aus:
In Colab öffnen | In Colab Enterprise öffnen | Auf GitHub ansehen | In Vertex AI Workbench öffnen |Hinweise
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API and Artifact Registry API APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API and Artifact Registry API APIs.
-
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init - Installieren Sie Docker gemäß der Dokumentation zu Artifact Registry.
- LOCATION_ID ist die Region Ihres Artifact Registry-Repositorys, wie in einem vorherigen Abschnitt festgelegt.
- PROJECT_ID: Die ID Ihres Google Cloud-Projekts
Geben Sie den folgenden Befehl in der Shell ein, um das Container-Image lokal auszuführen:
docker run -t -d -p 8000:8000 --rm \ --name=local_object_detector \ -e AIP_MODE=True \ LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference \ --model-repository MODEL_ARTIFACTS_REPOSITORY \ --strict-model-config=falseErsetzen Sie Folgendes wie im vorherigen Abschnitt:
- LOCATION_ID ist die Region Ihres Artifact Registry-Repositorys, wie in einem vorherigen Abschnitt festgelegt.
- PROJECT_ID: Die ID Ihres Google Cloud. Projekt
- MODEL_ARTIFACTS_REPOSITORY ist der Cloud Storage-Pfad, in dem sich Modellartefakte befinden.
Mit diesem Befehl wird ein Container im getrennten Modus ausgeführt, wobei Port
8000des Containers dem Port8000der lokalen Umgebung zugeordnet wird. Das Triton-Image von NGC konfiguriert Triton für die Verwendung von Port8000.Führen Sie den folgenden Befehl in der Shell aus, um dem Server des Containers eine Systemdiagnose zu senden:
curl -s -o /dev/null -w "%{http_code}" http://localhost:8000/v2/health/readyBei Erfolg gibt der Server den Statuscode als
200zurück.Führen Sie den folgenden Befehl aus, um dem Server des Containers eine Inferenzanfrage zu senden. Verwenden Sie dazu die zuvor generierte Nutzlast und rufen Sie Inferenzantworten ab:
curl -X POST \ -H "Content-Type: application/json" \ -d @instances.json \ localhost:8000/v2/models/object_detector/infer | jq -c '.outputs[] | select(.name == "detection_classes")'Bei dieser Anfrage wird ein Test-Image verwendet, das im Beispiel für die TensorFlow-Objekterkennung enthalten ist.
Bei erfolgreicher Ausführung gibt der Server die folgende Inferenz zurück:
{"name":"detection_classes","datatype":"FP32","shape":[1,300],"data":[38,1,...,44]}Führen Sie den folgenden Befehl in der Shell aus, um den Container zu beenden:
docker stop local_object_detectorFühren Sie den folgenden Befehl in der Shell aus, um Ihrer lokalen Docker-Installation die Berechtigung zum Übertragen an Artifact Registry per Push in der gewählten Region zu erteilen:
gcloud auth configure-docker LOCATION_ID-docker.pkg.dev- Ersetzen Sie dabei LOCATION_ID durch die Region, in der Sie Ihr Repository in einem vorherigen Abschnitt erstellt haben.
Führen Sie den folgenden Befehl in der Shell aus, um das Container-Image per Push zu übertragen, das Sie gerade in Artifact Registry erstellt haben:
docker push LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inferenceErsetzen Sie Folgendes wie im vorherigen Abschnitt:
- LOCATION_ID ist die Region Ihres Artifact Registry-Repositorys, wie in einem vorherigen Abschnitt festgelegt.
- PROJECT_ID: Die ID Ihres Google Cloud-Projekts.
- LOCATION_ID: Die Region, in der Sie Vertex AI verwenden.
- PROJECT_ID: die ID Ihres Google Cloud-Projekts
-
DEPLOYED_MODEL_NAME: Ein Name für
DeployedModel. Sie können auch den Anzeigenamen vonModelfürDeployedModelverwenden. - LOCATION_ID: Die Region, in der Sie Vertex AI verwenden.
- ENDPOINT_NAME: Der Anzeigename für den Endpunkt.
- LOCATION_ID: Die Region, in der Sie Vertex AI verwenden.
- ENDPOINT_NAME: Der Anzeigename für den Endpunkt.
-
DEPLOYED_MODEL_NAME: Ein Name für
DeployedModel. Sie können auch den Anzeigenamen vonModelfürDeployedModelverwenden. -
MACHINE_TYPE: Optional. Die für jeden Knoten dieser Bereitstellung verwendeten Maschinenressourcen. Die Standardeinstellung ist
n1-standard-2. Weitere Informationen zu Maschinentypen. - MIN_REPLICA_COUNT: Die minimale Anzahl von Knoten für diese Bereitstellung. Die Knotenzahl kann je nach der Inferenzlast erhöht oder verringert werden, bis zur maximalen Anzahl von Knoten und niemals auf weniger als diese Anzahl von Knoten.
- MAX_REPLICA_COUNT: Die maximale Anzahl von Knoten für diese Bereitstellung. Die Knotenzahl kann je nach der Inferenzlast erhöht oder verringert werden, bis zu dieser Anzahl von Knoten und niemals auf weniger als die minimale Anzahl von Knoten.
ACCELERATOR_COUNT: Die Anzahl der Beschleuniger, die an jede Maschine angeschlossen werden, auf der der Job ausgeführt wird. Dies ist normalerweise 1. Wenn keine Angabe erfolgt, beträgt der Standardwert 1.
ACCELERATOR_TYPE: Beschleunigerkonfiguration für GPU-Bereitstellung verwalten Bei der Bereitstellung eines Modells mit Compute-Engine-Maschinentypen kann auch ein GPU-Beschleuniger ausgewählt werden, und der Typ muss angegeben werden. Die Optionen sind
nvidia-tesla-a100,nvidia-tesla-p100,nvidia-tesla-p4,nvidia-tesla-t4undnvidia-tesla-v100.- LOCATION_ID: Die Region, in der Sie Vertex AI verwenden.
- ENDPOINT_NAME: Der Anzeigename für den Endpunkt.
Führen Sie den folgenden Befehl in der Shell aus, um die Bereitstellung des Modells beim Endpunkt aufzuheben und den Endpunkt zu löschen:
ENDPOINT_ID=$(gcloud ai endpoints list \ --region=LOCATION_ID \ --filter=display_name=ENDPOINT_NAME \ --format="value(name)") DEPLOYED_MODEL_ID=$(gcloud ai endpoints describe $ENDPOINT_ID \ --region=LOCATION_ID \ --format="value(deployedModels.id)") gcloud ai endpoints undeploy-model $ENDPOINT_ID \ --region=LOCATION_ID \ --deployed-model-id=$DEPLOYED_MODEL_ID gcloud ai endpoints delete $ENDPOINT_ID \ --region=LOCATION_ID \ --quietErsetzen Sie dabei LOCATION_ID durch die Region, in der Sie das Modell in einem vorherigen Abschnitt erstellt haben.
Führen Sie den folgenden Befehl in der Shell aus, um das Modell zu löschen:
MODEL_ID=$(gcloud ai models list \ --region=LOCATION_ID \ --filter=display_name=DEPLOYED_MODEL_NAME \ --format="value(name)") gcloud ai models delete $MODEL_ID \ --region=LOCATION_ID \ --quietErsetzen Sie dabei LOCATION_ID durch die Region, in der Sie das Modell in einem vorherigen Abschnitt erstellt haben.
Führen Sie den folgenden Befehl in der Shell aus, um Ihr Artifact Registry-Repository und das darin enthaltene Container-Image zu löschen:
gcloud artifacts repositories delete getting-started-nvidia-triton \ --location=LOCATION_ID \ --quietErsetzen Sie dabei LOCATION_ID durch die Region, in der Sie das Artifact Registry-Repository in einem vorherigen Abschnitt erstellt haben.
- Der benutzerdefinierte Triton-Container ist nicht mit Vertex Explainable AI oder Vertex AI Model Monitoring kompatibel.
- Weitere Informationen zu Bereitstellungsmustern mit dem NVIDIA Triton-Inferenzserver auf Vertex AI finden Sie in den NVIDIA Triton-Notebook-Anleitungen.
Für diese Anleitung empfehlen wir die Verwendung von Cloud Shell zur Interaktion mit Google Cloud. Wenn Sie anstelle von Cloud Shell eine andere Bash-Shell nutzen möchten, führen Sie die folgende zusätzliche Konfiguration aus:
Container-Image erstellen und per Push übertragen
Wenn Sie einen benutzerdefinierten Container verwenden möchten, müssen Sie ein Docker-Container-Image angeben, das die Anforderungen für benutzerdefinierte Container erfüllt. In diesem Abschnitt wird gezeigt, wie Sie das Container-Image erstellen und per Push nach Artifact Registry übertragen.
Modellartefakte herunterladen
Modellartefakte sind Dateien, die vom ML-Training erstellt werden und zum Bereitstellen von Inferenzvorhersagen verwendet werden können. Sie enthalten mindestens die Struktur und Gewichtungen Ihres trainierten ML-Modells. Das Format der Modellartefakte hängt vom ML-Framework ab, das Sie für das Training nutzen.
In dieser Anleitung erstellen Sie kein neues Modell zur Modellerkennung, sondern laden das Objekterkennungsmodell von TensorFlow Hub herunter, das auf dem COCO 2017-Datensatz trainiert wurde.
Triton erwartet, dass das Modell-Repository in der folgenden Struktur organisiert ist, um das TensorFlow SavedModel-Format bereitzustellen:
└── model-repository-path
└── model_name
├── config.pbtxt
└── 1
└── model.savedmodel
└── <saved-model-files>
Die Datei config.pbtxt beschreibt die Modellkonfiguration für das Modell. Standardmäßig muss die Modellkonfigurationsdatei bereitgestellt werden, die die erforderlichen Einstellungen enthält. Wenn Triton jedoch mit der Option --strict-model-config=false gestartet wird, dann kann die Modellkonfiguration in einigen Fällen automatisch von Triton generiert werden und muss nicht explizit angegeben werden.
Insbesondere TensorRT-, TensorFlow SavedModel- und ONNX-Modelle benötigen keine Modellkonfigurationsdatei, da Triton alle erforderlichen Einstellungen automatisch ableiten kann. Alle anderen Modelltypen müssen eine Modellkonfigurationsdatei bereitstellen.
# Download and organize model artifacts according to the Triton model repository spec
mkdir -p models/object_detector/1/model.savedmodel/
curl -L "https://tfhub.dev/tensorflow/faster_rcnn/resnet101_v1_640x640/1?tf-hub-format=compressed" | \
tar -zxvC ./models/object_detector/1/model.savedmodel/
ls -ltr ./models/object_detector/1/model.savedmodel/
Nach dem lokalen Herunterladen des Modells wird das Modell-Repository so organisiert:
./models
└── object_detector
└── 1
└── model.savedmodel
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
Modellartefakte in einen Cloud Storage-Bucket kopieren
Die heruntergeladenen Modellartefakte einschließlich Modellkonfigurationsdatei werden in einen Cloud Storage-Bucket verschoben, der durch MODEL_ARTIFACTS_REPOSITORY angegeben wird. Dieser kann beim Erstellen der Vertex AI-Modellressource verwendet werden.
gcloud storage cp ./models/object_detector MODEL_ARTIFACTS_REPOSITORY/ --recursive
Artifact Registry-Repository erstellen
Erstellen Sie ein Artifact Registry-Repository, um darin das Container-Image zu speichern, das Sie im nächsten Abschnitt erstellen.
Aktivieren Sie den Artifact Registry API-Dienst für Ihr Projekt.
gcloud services enable artifactregistry.googleapis.com
Führen Sie den folgenden Befehl in Ihrer Shell aus, um Artifact Registry-Repository zu erstellen:
gcloud artifacts repositories create getting-started-nvidia-triton \
--repository-format=docker \
--location=LOCATION_ID \
--description="NVIDIA Triton Docker repository"
Ersetzen Sie dabei LOCATION_ID durch die Region, in der Artifact Registry Ihr Container-Image speichert. Später müssen Sie eine Vertex AI-Modellressource an einem Standortendpunkt erstellen, der zu dieser Region passt. Wählen Sie also eine Region, in der Vertex AI einen Standortendpunkt hat, z. B. us-central1.
Nach Abschluss des Vorgangs gibt der Befehl die folgende Ausgabe aus:
Created repository [getting-started-nvidia-triton].
Container-Image erstellen
NVIDIA bietet Docker-Images zum Erstellen eines Container-Images, das Triton ausführt und den benutzerdefinierten Containeranforderungen von Vertex AI für die Bereitstellung entspricht. Sie können das Image mit docker abrufen und den Artifact Registry-Pfad taggen, in den das Image übertragen wird.
NGC_TRITON_IMAGE_URI="nvcr.io/nvidia/tritonserver:22.01-py3"
docker pull $NGC_TRITON_IMAGE_URI
docker tag $NGC_TRITON_IMAGE_URI LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference
Dabei gilt:
Die Ausführung des Befehls kann mehrere Minuten dauern.
Nutzlastdatei zum Testen von Inferenzanfragen vorbereiten
Bereiten Sie die Nutzlast mit einer Beispiel-Image-Datei vor, die Python verwendet, um dem Server des Containers eine Inferenzanfrage zu senden. Führen Sie das folgende Python-Script aus, um die Nutzlastdatei zu generieren:
import json
import requests
# install required packages before running
# pip install pillow numpy --upgrade
from PIL import Image
import numpy as np
# method to generate payload from image url
def generate_payload(image_url):
# download image from url and resize
image_inputs = Image.open(requests.get(image_url, stream=True).raw)
image_inputs = image_inputs.resize((200, 200))
# convert image to numpy array
image_tensor = np.asarray(image_inputs)
# derive image shape
image_shape = [1] + list(image_tensor.shape)
# create payload request
payload = {
"id": "0",
"inputs": [
{
"name": "input_tensor",
"shape": image_shape,
"datatype": "UINT8",
"parameters": {},
"data": image_tensor.tolist(),
}
],
}
# save payload as json file
payload_file = "instances.json"
with open(payload_file, "w") as f:
json.dump(payload, f)
print(f"Payload generated at {payload_file}")
return payload_file
if __name__ == '__main__':
image_url = "https://github.com/tensorflow/models/raw/master/research/object_detection/test_images/image2.jpg"
payload_file = generate_payload(image_url)
Das Python-Script generiert eine Nutzlast und gibt die folgende Antwort aus:
Payload generated at instances.json
Container lokal ausführen (optional)
Bevor Sie Ihr Container-Image per Push in Artifact Registry hochladen, um es mit Vertex AI zu verwenden, können Sie es als Container in Ihrer lokalen Umgebung ausführen und so prüfen, ob der Server wie erwartet funktioniert:
{kind=link}
Container-Image per Push nach Artifact Registry übertragen
Konfigurieren Sie Docker für den Zugriff auf Artifact Registry. Übertragen Sie dann das Container-Image per Push in das Artifact Registry-Repository.
Modell bereitstellen
In diesem Abschnitt erstellen Sie ein Modell und einen Endpunkt und stellen das Modell dann auf dem Endpunkt bereit.
Modell erstellen
Verwenden Sie den gcloud ai models upload-Befehl, um eine Model-Ressource zu erstellen, die einen benutzerdefinierten Container verwendet, der Triton ausführt.
Bevor Sie Ihr Modell erstellen, lesen Sie den Abschnitt Einstellungen für benutzerdefinierte Container, um herauszufinden, ob Sie die optionalen Felder sharedMemorySizeMb, startupProbe und healthProbe für Ihren Container angeben müssen.
gcloud ai models upload \
--region=LOCATION_ID \
--display-name=DEPLOYED_MODEL_NAME \
--container-image-uri=LOCATION_ID-docker.pkg.dev/PROJECT_ID/getting-started-nvidia-triton/vertex-triton-inference \
--artifact-uri=MODEL_ARTIFACTS_REPOSITORY \
--container-args='--strict-model-config=false'
Mit dem Argument --container-args='--strict-model-config=false' kann Triton die Modellkonfiguration automatisch generieren.
Endpunkt erstellen
Sie müssen das Modell auf einem Endpunkt bereitstellen, bevor es zum Bereitstellen von Onlineinferenzen verwendet werden kann. Wenn Sie ein Modell auf einem vorhandenen Endpunkt bereitstellen, können Sie diesen Schritt überspringen. Im folgenden Beispiel wir der Befehl gcloud ai endpoints create verwendet:
gcloud ai endpoints create \
--region=LOCATION_ID \
--display-name=ENDPOINT_NAME
Dabei gilt:
Es kann einige Sekunden dauern, bis das Google Cloud CLI den Endpunkt erstellt.
Modell auf dem Endpunkt bereitstellen
Wenn der Endpunkt bereit ist, stellen Sie das Modell für den Endpunkt bereit. Wenn Sie ein Modell auf einem Endpunkt bereitstellen, verknüpft der Dienst physische Ressourcen mit dem Modell, auf dem Triton für Onlineinferenzen ausgeführt wird.
Im folgenden Beispiel wird der Befehl gcloud ai endpoints deploy-model verwendet, um das Model auf einem endpoint bereitzustellen, auf dem Triton auf GPUs ausgeführt wird, um die Inferenzbereitstellung zu beschleunigen und ohne den Traffic zwischen mehreren DeployedModel-Ressourcen aufzuteilen:
ENDPOINT_ID=$(gcloud ai endpoints list \ --region=LOCATION_ID\ --filter=display_name=ENDPOINT_NAME\ --format="value(name)") MODEL_ID=$(gcloud ai models list \ --region=LOCATION_ID\ --filter=display_name=DEPLOYED_MODEL_NAME\ --format="value(name)") gcloud ai endpoints deploy-model $ENDPOINT_ID \ --region=LOCATION_ID\ --model=$MODEL_ID \ --display-name=DEPLOYED_MODEL_NAME\ --machine-type=MACHINE_TYPE\ --min-replica-count=MIN_REPLICA_COUNT\ --max-replica-count=MAX_REPLICA_COUNT\ --accelerator=count=ACCELERATOR_COUNT,type=ACCELERATOR_TYPE\ --traffic-split=0=100
Ersetzen Sie Folgendes:
Es kann einige Sekunden dauern, bis das Google Cloud CLI das Modell am Endpunkt bereitstellt. Wenn das Modell erfolgreich bereitgestellt wurde, gibt dieser Befehl die folgende Ausgabe aus:
Deployed a model to the endpoint xxxxx. Id of the deployed model: xxxxx.
Onlineinferenzen aus dem bereitgestellten Modell abrufen
Wenn Sie das Modell über den Vertex AI Inference-Endpunkt aufrufen möchten, formatieren Sie die Inferenzanfrage mithilfe eines Standard-JSON-Objekts für die Inferenzanfrage
oder eines JSON-Objekts für die Inferenzanfrage mit einer binären Erweiterung
und senden eine Anfrage an den Vertex AI REST rawPredict-Endpunkt.
Im folgenden Beispiel wir der Befehl gcloud ai endpoints raw-predict verwendet:
ENDPOINT_ID=$(gcloud ai endpoints list \
--region=LOCATION_ID \
--filter=display_name=ENDPOINT_NAME \
--format="value(name)")
gcloud ai endpoints raw-predict $ENDPOINT_ID \
--region=LOCATION_ID \
--http-headers=Content-Type=application/json \
--request=@instances.json
Ersetzen Sie dabei Folgendes:
Der Endpunkt gibt für eine gültige Anfrage die folgende Antwort zurück:
{
"id": "0",
"model_name": "object_detector",
"model_version": "1",
"outputs": [{
"name": "detection_anchor_indices",
"datatype": "FP32",
"shape": [1, 300],
"data": [2.0, 1.0, 0.0, 3.0, 26.0, 11.0, 6.0, 92.0, 76.0, 17.0, 58.0, ...]
}]
}
Bereinigen
Löschen Sie die in dieser Anleitung erstellten Google Cloud -Ressourcen, damit keine weiteren Kosten für Vertex AI-Gebühren und Artifact Registry-Gebühren anfallen: