In qualità di data scientist, questo è un flusso di lavoro comune: addestra un modello localmente (nel mio notebook), registra i parametri, registra le metriche delle serie temporali di addestramento in Vertex AI TensorBoard e registra le metriche di valutazione.
In qualità di data scientist, voglio essere in grado di riutilizzare il codice di pre-elaborazione dei dati scritto da altri membri della mia azienda per semplificare e standardizzare tutte le complesse operazioni di manipolazione dei dati che eseguiamo. Voglio essere in grado di:
- Utilizza una libreria di pre-elaborazione dei dati Python per pulire un set di dati in memoria (un DataFrame Pandas) in un notebook.
- Addestra un modello utilizzando Keras (di nuovo in un notebook).
Blocco note: sperimentazione del modello con dati pre-elaborati
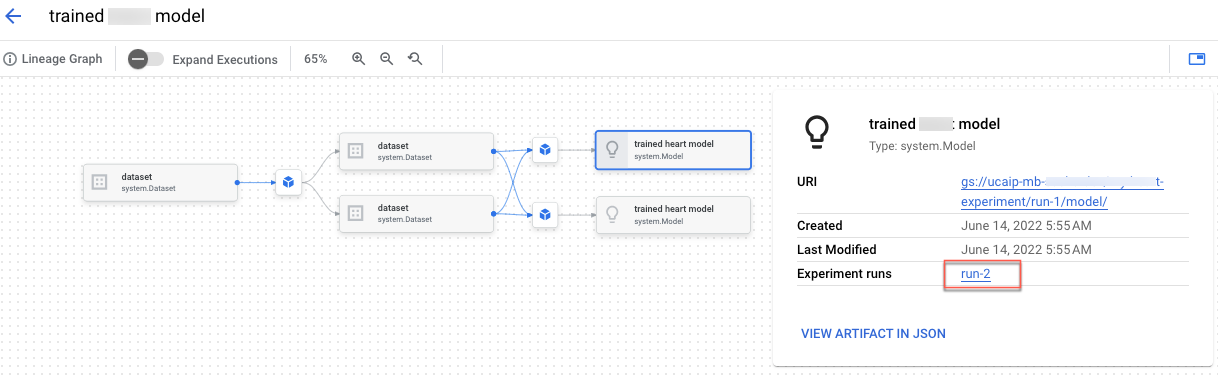
Nel blocco note "Build Vertex AI Experiments lineage for custom training" (Crea la genealogia di Vertex AI Experiments per l'addestramento personalizzato), imparerai a integrare il codice di preelaborazione in Vertex AI Experiments. Inoltre, creerai la derivazione dell'esperimento che ti consente di registrare, analizzare, eseguire il debug e controllare i metadati e gli artefatti prodotti durante il percorso di ML.
Puoi visualizzare la genealogia degli artefatti nella console Google Cloud .