JupyterLab 내에서 BigQuery의 데이터 쿼리
이 페이지에서는 Vertex AI Workbench 인스턴스의 JupyterLab 인터페이스에서 BigQuery에 저장된 데이터를 쿼리하는 방법을 보여줍니다.
노트북(IPYNB) 파일에서 BigQuery 데이터를 쿼리하는 방법
JupyterLab 노트북 파일 내에서 BigQuery 데이터를 쿼리하려면 %%bigquery 매직 명령어와 Python용 BigQuery 클라이언트 라이브러리를 사용하면 됩니다.
Vertex AI Workbench 인스턴스에는 JupyterLab 인터페이스 내에서 데이터를 탐색하고 쿼리할 수 있게 해주는 BigQuery 통합도 포함되어 있습니다.
이 페이지에서는 이러한 각 메서드를 사용하는 방법을 설명합니다.
시작하기 전에
아직 Vertex AI Workbench 인스턴스를 만들지 않았으면 인스턴스를 만듭니다.
필요한 역할
인스턴스의 서비스 계정에 BigQuery에서 데이터를 쿼리하는 데 필요한 권한이 있게 하려면 관리자에게 인스턴스의 서비스 계정에 프로젝트에 대한 서비스 사용량 소비자(roles/serviceusage.serviceUsageConsumer) IAM 역할을 부여해 달라고 요청하세요.
관리자는 커스텀 역할이나 다른 사전 정의된 역할을 통해 인스턴스의 서비스 계정에 필요한 권한을 부여할 수도 있습니다.
JupyterLab 열기
Google Cloud 콘솔에서 인스턴스 페이지로 이동합니다.
Vertex AI Workbench 인스턴스 이름 옆에 있는 JupyterLab 열기를 클릭합니다.
Vertex AI Workbench 인스턴스가 JupyterLab을 엽니다.
BigQuery 리소스 둘러보기
BigQuery 통합은 액세스 권한이 있는 BigQuery 리소스를 찾아볼 수 있는 창을 제공합니다.
JupyterLab 탐색 메뉴에서
 BigQuery in Notebooks(Notebooks의 BigQuery)를 클릭합니다.
BigQuery in Notebooks(Notebooks의 BigQuery)를 클릭합니다.BigQuery 창에 다음과 같이 태스크를 수행할 수 있는 사용 가능한 프로젝트 및 데이터 세트가 나열됩니다.
- 데이터 세트 설명을 보려면 데이터 세트 이름을 더블클릭합니다.
- 데이터 세트의 테이블, 뷰, 모델을 표시하려면 데이터 세트를 펼칩니다.
- JupyterLab에서 요약 설명을 탭으로 열려면 테이블, 뷰 또는 모델을 더블클릭합니다.
참고: 테이블의 요약 설명에서 미리보기 탭을 클릭하여 테이블의 데이터를 미리 보세요. 다음 이미지에서는
bigquery-public-data프로젝트의google_trends데이터 세트에 있는international_top_terms테이블의 미리보기를 보여줍니다.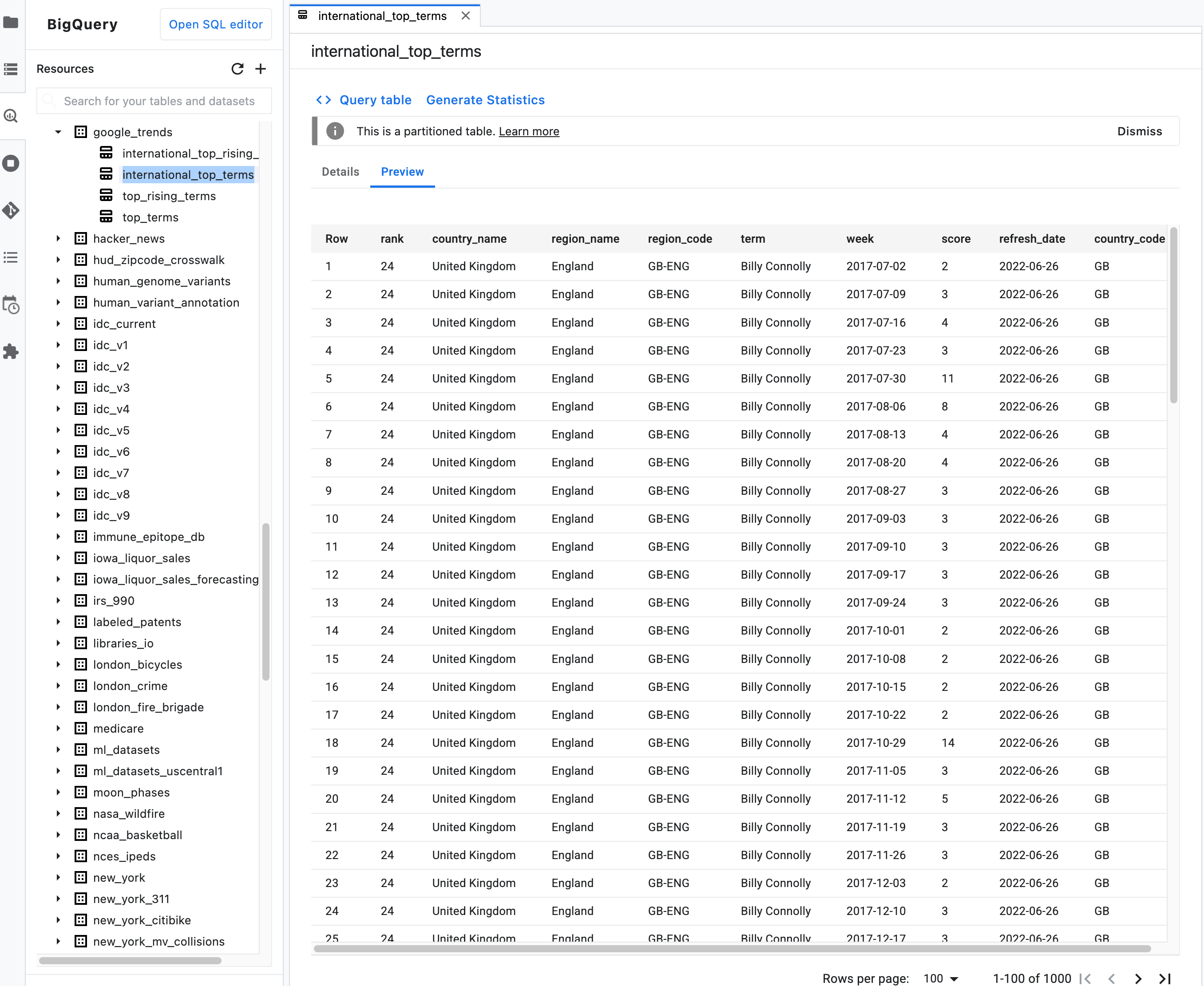
%%bigquery 매직 명령어를 사용하여 데이터 쿼리
이 섹션에서는 SQL을 노트북 셀에 직접 쓰고 BigQuery에서 Python 노트북으로 데이터를 읽습니다.
단일 또는 이중 백분율 문자(% 또는 %%)를 사용하는 매직 명령어를 사용하면 최소한의 구문을 사용하여 노트북 내에서 BigQuery와 상호작용할 수 있습니다. Python용 BigQuery 클라이언트 라이브러리는 Vertex AI Workbench 인스턴스에 자동으로 설치됩니다. 백그라운드에서 %%bigquery 매직 명령어가 Python용 BigQuery 클라이언트 라이브러리를 사용하여 지정된 쿼리를 실행하고, 결과를 Pandas DataFrame으로 변환하고, 선택한 경우 결과를 변수에 저장한 후 결과를 표시합니다.
참고: google-cloud-bigquery Python 패키지 버전 1.26.0부터 기본적으로 BigQuery Storage API가 %%bigquery 매직에서 결과를 다운로드하는 데 사용됩니다.
노트북 파일을 열려면 파일 > 새로 만들기 > 노트북을 선택합니다.
커널 선택 대화상자에서 Python 3를 선택한 다음 선택을 클릭합니다.
새 IPYNB 파일이 열립니다.
international_top_terms데이터 세트에서 국가별 리전 수를 확인하려면 다음 문을 입력합니다.%%bigquery SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
셀 실행을 클릭합니다.
출력은 다음과 비슷합니다.
Query complete after 0.07s: 100%|██████████| 4/4 [00:00<00:00, 1440.60query/s] Downloading: 100%|██████████| 41/41 [00:02<00:00, 20.21rows/s] country_code country_name num_regions 0 TR Turkey 81 1 TH Thailand 77 2 VN Vietnam 63 3 JP Japan 47 4 RO Romania 42 5 NG Nigeria 37 6 IN India 36 7 ID Indonesia 34 8 CO Colombia 33 9 MX Mexico 32 10 BR Brazil 27 11 EG Egypt 27 12 UA Ukraine 27 13 CH Switzerland 26 14 AR Argentina 24 15 FR France 22 16 SE Sweden 21 17 HU Hungary 20 18 IT Italy 20 19 PT Portugal 20 20 NO Norway 19 21 FI Finland 18 22 NZ New Zealand 17 23 PH Philippines 17 ...
다음 셀(이전 셀의 출력 아래)에 다음 명령어를 입력하여 동일한 쿼리를 실행합니다. 단, 이번에는 결과를 이름이
regions_by_country인 새 Pandas DataFrame에 저장합니다.%%bigquery매직 명령어와 함께 인수를 사용하여 해당 이름을 제공합니다.%%bigquery regions_by_country SELECT country_code, country_name, COUNT(DISTINCT region_code) AS num_regions FROM `bigquery-public-data.google_trends.international_top_terms` WHERE refresh_date = DATE_SUB(CURRENT_DATE, INTERVAL 1 DAY) GROUP BY country_code, country_name ORDER BY num_regions DESC;
참고:
%%bigquery명령어에 사용 가능한 인수에 대한 자세한 내용은 클라이언트 라이브러리 매직 문서를 참조하세요.셀 실행을 클릭합니다.
다음 셀에서 다음 명령어를 입력하여 방금 읽은 쿼리 결과의 처음 몇 행을 확인합니다.
regions_by_country.head()셀 실행을 클릭합니다.
Pandas DataFrame
regions_by_country를 표시할 수 있게 되었습니다.
BigQuery 클라이언트 라이브러리를 직접 사용하여 데이터 쿼리
이 섹션에서는 Python용 BigQuery 클라이언트 라이브러리를 직접 사용하여 데이터를 Python 노트북으로 읽습니다.
클라이언트 라이브러리를 사용하면 쿼리를 보다 세부적으로 제어할 수 있고 쿼리 및 작업을 위한 더욱 복잡한 구성도 가능해집니다. Pandas와 함께 라이브러리의 통합을 사용하면 선언형 SQL의 기능을 명령형 코드(Python)와 결합하여 데이터를 분석, 시각화, 변환할 수 있습니다.
참고: 다양한 Python 데이터 분석, 데이터 랭글링, 시각화 라이브러리(예: numpy, pandas, matplotlib) 등을 사용할 수 있습니다. 이 중 일부 라이브러리는 DataFrame 객체를 기반으로 합니다.
다음 셀에서 다음 Python 코드를 입력하여 Python용 BigQuery 클라이언트 라이브러리를 가져오고 클라이언트를 초기화합니다.
from google.cloud import bigquery client = bigquery.Client()BigQuery 클라이언트는 BigQuery API에서 메시지를 주고받는 데 사용됩니다.
셀 실행을 클릭합니다.
다음 셀에서 다음 코드를 입력하여 시간이 지나면서 날짜별로 겹치는 미국
top_terms의 일일 상위 검색어 비율을 가져옵니다. 각 날짜의 상위 검색어를 살펴보고 전날, 2일 전, 3일 전 등(한 달간의 날짜 쌍)의 상위 검색어와 겹치는 비율을 확인할 계획입니다.sql = """ WITH TopTermsByDate AS ( SELECT DISTINCT refresh_date AS date, term FROM `bigquery-public-data.google_trends.top_terms` ), DistinctDates AS ( SELECT DISTINCT date FROM TopTermsByDate ) SELECT DATE_DIFF(Dates2.date, Date1Terms.date, DAY) AS days_apart, COUNT(DISTINCT (Dates2.date || Date1Terms.date)) AS num_date_pairs, COUNT(Date1Terms.term) AS num_date1_terms, SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)) AS overlap_terms, SAFE_DIVIDE( SUM(IF(Date2Terms.term IS NOT NULL, 1, 0)), COUNT(Date1Terms.term) ) AS pct_overlap_terms FROM TopTermsByDate AS Date1Terms CROSS JOIN DistinctDates AS Dates2 LEFT JOIN TopTermsByDate AS Date2Terms ON Dates2.date = Date2Terms.date AND Date1Terms.term = Date2Terms.term WHERE Date1Terms.date <= Dates2.date GROUP BY days_apart ORDER BY days_apart; """ pct_overlap_terms_by_days_apart = client.query(sql).to_dataframe() pct_overlap_terms_by_days_apart.head()
사용되는 SQL은 Python 문자열로 캡슐화된 후
query()메서드로 전달되어 쿼리를 실행합니다.to_dataframe메서드는 쿼리가 완료될 때까지 기다린 후 BigQuery Storage API를 사용하여 결과를 Pandas DataFrame에 다운로드합니다.셀 실행을 클릭합니다.
쿼리 결과의 처음 몇 행이 코드 셀 아래에 나타납니다.
days_apart num_date_pairs num_date1_terms overlap_terms pct_overlap_terms 0 0 32 800 800 1.000000 1 1 31 775 203 0.261935 2 2 30 750 73 0.097333 3 3 29 725 31 0.042759 4 4 28 700 23 0.032857
BigQuery 클라이언트 라이브러리 사용 방법에 대한 자세한 내용은 빠른 시작, 클라이언트 라이브러리 사용을 참조하세요.
Vertex AI Workbench에서 BigQuery 통합을 사용하여 데이터 쿼리
BigQuery 통합은 데이터 쿼리를 위한 두 가지 추가 메서드를 제공합니다. 이러한 메서드는 %%bigquery 매직 명령어를 사용하는 것과 다릅니다.
셀 내 쿼리 편집기는 노트북 파일 내에서 사용할 수 있는 셀 유형입니다.
JupyterLab에서 독립형 쿼리 편집기가 별도의 탭으로 열립니다.
셀 내
셀 내 쿼리 편집기를 사용하여 BigQuery 테이블의 데이터를 쿼리하려면 다음 단계를 완료합니다.
JupyterLab에서 노트북(IPYNB) 파일을 열거나 새 파일을 만듭니다.
셀 내 쿼리 편집기를 만들려면 셀을 클릭한 후 셀 오른쪽에 있는 BigQuery 통합 버튼을 클릭합니다. 또는 마크다운 셀에
#@BigQuery를 입력합니다.BigQuery 통합은 셀을 셀 내 쿼리 편집기로 변환합니다.
#@BigQuery아래의 새 행에서 BigQuery의 지원되는 문 및 SQL 언어를 사용하여 쿼리를 작성합니다. 쿼리에서 오류가 감지되면 쿼리 편집기의 오른쪽 상단에 오류 메시지가 나타납니다. 쿼리가 유효하면 처리할 예상 바이트 수가 표시됩니다.쿼리 제출을 클릭합니다. 쿼리 결과가 나타납니다. 기본적으로 쿼리 결과는 페이지당 100행으로 페이지가 나뉘고 총 1,000행으로 제한되지만 결과 테이블 하단에서 이 설정을 변경할 수 있습니다. 쿼리 편집기에서는 쿼리를 확인하는 데 필요한 데이터로만 쿼리를 유지합니다. 노트북 셀에서 이 쿼리를 다시 실행하면 원하는 경우 전체 결과 세트를 검색하기 위해 한도를 조정할 수 있습니다.
쿼리 및 DataFrame으로 로드를 클릭하여 Python용 BigQuery 클라이언트 라이브러리를 가져오고, 노트북에서 쿼리를 실행하는 코드 세그먼트가 포함된 새 셀을 자동으로 추가할 수 있습니다. 그리고
df라는 Pandas DataFrame에 결과를 저장합니다.
독립형
독립형 쿼리 편집기를 사용하여 BigQuery 테이블의 데이터를 쿼리하려면 다음 단계를 완료합니다.
JupyterLab의 노트북에서의 BigQuery 창에서 테이블을 마우스 오른쪽 버튼으로 클릭하고 테이블 쿼리를 선택하거나 테이블을 더블클릭하여 엽니다. 별도의 탭에서 설명을 클릭한 다음 쿼리 테이블 링크를 클릭합니다.
BigQuery의 지원되는 문 및 SQL 언어를 사용하여 쿼리를 작성합니다. 쿼리에서 오류가 감지되면 쿼리 편집기의 오른쪽 상단에 오류 메시지가 나타납니다. 쿼리가 유효하면 처리할 예상 바이트 수가 표시됩니다.
쿼리 제출을 클릭합니다. 쿼리 결과가 나타납니다. 기본적으로 쿼리 결과는 페이지당 100행으로 페이지가 나뉘고 총 1,000행으로 제한되지만 결과 테이블 하단에서 이 설정을 변경할 수 있습니다. 쿼리 편집기에서는 쿼리를 확인하는 데 필요한 데이터로만 쿼리를 유지합니다. 노트북 셀에서 이 쿼리를 다시 실행하면 원하는 경우 전체 결과 세트를 검색하기 위해 한도를 조정할 수 있습니다.
DataFrame 코드 복사를 클릭하여 Python용 BigQuery 클라이언트 라이브러리를 가져오고, 노트북 셀에서 쿼리를 실행하고,
df라는 Pandas DataFrame에 결과를 저장합니다. 이 코드를 실행할 노트북 셀에 붙여넣습니다.
쿼리 기록 보기 및 쿼리 재사용
JupyterLab에서 쿼리 기록을 탭으로 보려면 다음 단계를 수행합니다.
JupyterLab 탐색 메뉴에서
BigQuery in Notebooks(Notebooks의 BigQuery)를 클릭하여 BigQuery 창을 엽니다.BigQuery 창에서 아래로 스크롤하여 쿼리 기록을 클릭합니다.
쿼리 목록이 다음과 같은 태스크를 수행할 수 있는 새 탭에서 열립니다.
- 작업 ID, 쿼리 실행 시기, 소요 시간에 대한 자세한 내용을 보려면 쿼리를 클릭합니다.
- 쿼리를 수정하거나 다시 실행하거나 나중에 사용할 수 있도록 노트북에 복사하려면 편집기에서 쿼리 열기를 클릭합니다.
다음 단계
BigQuery 테이블의 데이터를 시각화하는 방법의 예시는 JupyterLab 내에서 BigQuery의 데이터 탐색 및 시각화 참조하기
BigQuery에서 쿼리를 작성하는 방법에 대한 자세한 내용은 대화형 및 일괄 쿼리 작업 실행 참조하기
BigQuery 데이터 세트 액세스 제어 방법 알아보기