No Vector Search, é possível restringir as pesquisas de correspondência de vetor a um subconjunto do índice usando regras booleanas. Os predicados booleanos informam ao Vector Search quais vetores do índice devem ser ignorados. Nesta página, você aprenderá como a filtragem funciona, verá exemplos e maneiras de consultar seus dados de maneira eficiente com base na semelhança vetorial.
Com a pesquisa de vetor, é possível restringir os resultados por restrições categóricas e numéricas. Adicionar restrições ou "filtrar" os resultados do índice é útil por vários motivos, como os seguintes exemplos:
Melhoria na relevância dos resultados: a pesquisa de vetores é uma ferramenta avançada para encontrar itens semanticamente parecidos. A filtragem pode ser usada para remover resultados irrelevantes dos resultados da pesquisa, como itens que não estão no idioma, na categoria, no preço ou no período corretos.
Número reduzido de resultados: a pesquisa de vetor pode retornar um grande número de resultados, especialmente para grandes conjuntos de dados. A filtragem pode ser usada para reduzir o número de resultados a um número mais gerenciável, ao mesmo tempo em que retorna os resultados mais relevantes.
Resultados segmentados: é possível usar a filtragem para personalizar os resultados da pesquisa de acordo com as necessidades e preferências individuais do usuário. Por exemplo, um usuário pode querer filtrar os resultados para incluir apenas itens com uma classificação alta anteriormente ou que se enquadram em uma faixa de preço específica.
Atributos vetoriais
Em uma pesquisa por similaridade de vetor em um banco de dados de vetores, cada vetor é descrito por zero ou mais atributos. Esses atributos são conhecidos como tokens para restrições de token e valores para restrições numéricas. Essas restrições podem ser aplicadas a cada uma das várias categorias de atributos, também conhecidas como namespaces.
No exemplo de aplicativo a seguir, os vetores são marcados com color, um price e um shape:
coloreprice, eshapesão namespaces.redebluesão tokens do namespacecolor.squareecirclesão tokens do namespaceshape.100e50são valores do namespaceprice.
Especificar atributos vetoriais
- Para especificar um "círculo vermelho":
{color: red}, {shape: circle}. - Para especificar um "quadrado vermelho ou azul":
{color: red, blue}, {shape: square}. - Para especificar um objeto sem cor, omita o namespace "color"
no campo
restricts. - Para especificar restrições numéricas para um objeto, anote o namespace e o valor no campo apropriado do tipo. O valor int precisa ser especificado em
value_int, o valor flutuante precisa ser especificado emvalue_float, e o valor duplo precisa ser especificado emvalue_double. Somente um tipo de número deve ser usado para um determinado namespace.
Para informações sobre o esquema usado para especificar esses dados, consulte Especificar namespaces e tokens nos dados de entrada.
Consultas
- As consultas expressam um operador lógico AND em namespaces e um operador lógico OR
em cada namespace. Uma consulta que especifica
{color: red, blue}, {shape: square, circle}corresponde a todos os pontos de banco de dados que satisfazem(red || blue) && (square || circle). - Uma consulta que especifica
{color: red}corresponde a todos os objetosredde qualquer tipo, sem restrição deshape. - As restrições numéricas nas consultas exigem
namespace, um dos valores numéricos devalue_int,value_floatevalue_double, e o operadorop. - O operador
opéLESS,LESS_EQUAL,EQUAL,GREATER_EQUALouGREATER. Por exemplo, se o operadorLESS_EQUALfor usado, os pontos de dados estarão qualificados se o valor deles for menor ou igual ao valor usado na consulta.
Os exemplos de código a seguir identificam atributos vetoriais no aplicativo de exemplo:
[
{
"namespace": "price",
"value_int": 20,
"op": "LESS"
},
{
"namespace": "length",
"value_float": 0.3,
"op": "GREATER_EQUAL"
},
{
"namespace": "width",
"value_double": 0.5,
"op": "EQUAL"
}
]
Lista de bloqueio
Para permitir cenários mais avançados, o Google aceita uma forma de negação conhecida como tokens de lista de bloqueio. Quando uma consulta coloca um token na lista de bloqueio, as correspondências são excluídas de qualquer ponto de dados que tenha o token bloqueado. Se um namespace de consulta tiver apenas tokens bloqueados, todos os pontos não listados explicitamente corresponderão, da mesma maneira que um namespace vazio corresponde a todos os pontos.
Os pontos de dados também podem negar um token, excluindo correspondências com qualquer consulta que especifique esse token.
Por exemplo, defina os seguintes pontos de dados com os tokens especificados:
A: {} // empty set matches everything
B: {red} // only a 'red' token
C: {blue} // only a 'blue' token
D: {orange} // only an 'orange' token
E: {red, blue} // multiple tokens
F: {red, !blue} // deny the 'blue' token
G: {red, blue, !blue} // An unlikely edge-case
H: {!blue} // deny-only (similar to empty-set)
O sistema se comporta da seguinte maneira:
- Os namespaces de consulta vazios são caracteres curingas correspondentes. Por exemplo,
Q:
{}corresponde a DB:{color:red}. Os namespaces de ponto de dados vazios não são caracteres curinga correspondentes. Por exemplo, Q:
{color:red}não corresponde a DB:{}.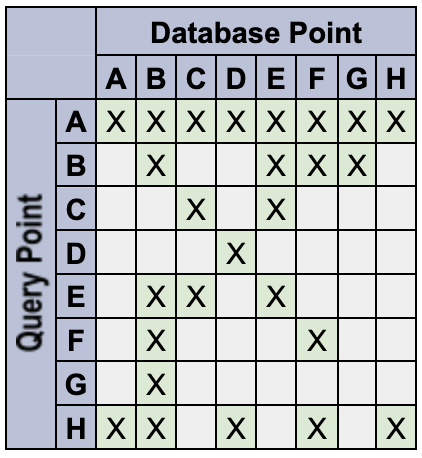
Especificar namespaces e tokens ou valores nos dados de entrada
Para informações sobre como estruturar os dados de entrada no geral, consulte Formato e estrutura de dados de entrada.
As guias a seguir mostram como especificar os namespaces e tokens associados a cada vetor de entrada.
JSON
Para o registro de cada vetor, adicione um campo chamado
restrictspara conter uma matriz de objetos, cada um deles um namespace.- Cada objeto precisa ter um campo chamado
namespace. Esse campo é o namespaceTokenNamespace.namespace. - O valor do campo
allow, se presente, é uma matriz de strings. Essa matriz de strings é a listaTokenNamespace.string_tokens. - O valor do campo
deny, se presente, é uma matriz de strings. Essa matriz de strings é a listaTokenNamespace.string_denylist_tokens.
- Cada objeto precisa ter um campo chamado
Veja a seguir dois registros de exemplo no formato JSON:
[
{
"id": "42",
"embedding": [
0.5,
1
],
"restricts": [
{
"namespace": "class",
"allow": [
"cat",
"pet"
]
},
{
"namespace": "category",
"allow": [
"feline"
]
}
]
},
{
"id": "43",
"embedding": [
0.6,
1
],
"sparse_embedding": {
"values": [
0.1,
0.2
],
"dimensions": [
1,
4
]
},
"restricts": [
{
"namespace": "class",
"allow": [
"dog",
"pet"
]
},
{
"namespace": "category",
"allow": [
"canine"
]
}
]
}
]
Para o registro de cada vetor, adicione um campo chamado
numeric_restrictspara conter uma matriz de objetos, cada um deles um namespace.- Cada objeto precisa ter um campo chamado
namespace. Esse campo é o namespaceNumericRestrictNamespace.namespace. - Cada objeto precisa ter
value_int,value_floatouvalue_double. - Cada objeto precisa ter um campo chamado
op. Este campo é apenas para consultas.
- Cada objeto precisa ter um campo chamado
Veja a seguir dois registros de exemplo no formato JSON:
[
{
"id": "42",
"embedding": [
0.5,
1
],
"numeric_restricts": [
{
"namespace": "size",
"value_int": 3
},
{
"namespace": "ratio",
"value_float": 0.1
}
]
},
{
"id": "43",
"embedding": [
0.6,
1
],
"sparse_embedding": {
"values": [
0.1,
0.2
],
"numeric_restricts": [
{
"namespace": "weight",
"value_double": 0.3
}
]
}
}
]
Avro
Os registros Avro usam o seguinte esquema:
{
"type": "record",
"name": "FeatureVector",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "embedding",
"type": {
"type": "array",
"items": "float"
}
},
{
"name": "sparse_embedding",
"type": [
"null",
{
"type": "record",
"name": "sparse_embedding",
"fields": [
{
"name": "values",
"type": {
"type": "array",
"items": "float"
}
},
{
"name": "dimensions",
"type": {
"type": "array",
"items": "long"
}
}
]
}
]
},
{
"name": "restricts",
"type": [
"null",
{
"type": "array",
"items": {
"type": "record",
"name": "Restrict",
"fields": [
{
"name": "namespace",
"type": "string"
},
{
"name": "allow",
"type": [
"null",
{
"type": "array",
"items": "string"
}
]
},
{
"name": "deny",
"type": [
"null",
{
"type": "array",
"items": "string"
}
]
}
]
}
}
]
},
{
"name": "numeric_restricts",
"type": [
"null",
{
"type": "array",
"items": {
"name": "NumericRestrict",
"type": "record",
"fields": [
{
"name": "namespace",
"type": "string"
},
{
"name": "value_int",
"type": [ "null", "int" ],
"default": null
},
{
"name": "value_float",
"type": [ "null", "float" ],
"default": null
},
{
"name": "value_double",
"type": [ "null", "double" ],
"default": null
}
]
}
}
],
"default": null
},
{
"name": "crowding_tag",
"type": [
"null",
"string"
]
}
]
}
CSV
Restrições de token
Para o registro de cada vetor, adicione pares de formato
name=valueseparados por vírgula para especificar restrições de namespace do token. O mesmo nome pode ser repetido se houver vários valores em um namespace.Por exemplo,
color=red,color=bluerepresenta esteTokenNamespace:{ "namespace": "color" "string_tokens": ["red", "blue"] }Para o registro de cada vetor, adicione pares de formato
name=!valueseparados por vírgula para especificar o valor excluído das restrições de namespace do token.Por exemplo,
color=!redrepresenta esteTokenNamespace:{ "namespace": "color" "string_blacklist_tokens": ["red"] }
Restrições numéricas
Para o registro de cada vetor, adicione pares de formato
#name=numericValueseparados por vírgula com o sufixo do tipo de número para especificar restrições numéricas de namespace.O sufixo do tipo de número é
ipara int,fpara flutuante edpara duplo. O mesmo nome não pode ser repetido, porque precisa haver um único valor associado por namespace.Por exemplo,
#size=3irepresenta esteNumericRestrictNamespace:{ "namespace": "size" "value_int": 3 }#ratio=0.1frepresenta esteNumericRestrictNamespace:{ "namespace": "ratio" "value_float": 0.1 }#weight=0.3drepresenta esteNumericRestriction:{ "namespace": "weight" "value_double": 0.3 }Confira um exemplo de ponto de dados com
id: "6",embedding: [7, -8.1],sparse_embedding: {values: [0.1, -0.2, 0.5],dimensions: [40, 901, 1111]}}, tag de distanciamento detest, lista de permissões de token decolor: red, blue, lista de bloqueio de token decolor: purplee restrição numérica deratiocom0.1flutuante:6,7,-8.1,40:0.1,901:-0.2,1111:0.5,crowding_tag=test,color=red,color=blue,color=!purple, ratio=0.1f