En la búsqueda de vectores, puedes restringir las búsquedas de coincidencias de vectores a un subconjunto del índice mediante reglas booleanas. Los predicados booleanos indican a la búsqueda de vectores qué vectores del índice se deben ignorar. En esta página, aprenderás cómo funciona el filtrado, verás ejemplos y descubrirás formas de consultar tus datos de forma eficiente en función de la similitud de los vectores.
Con la búsqueda vectorial, puedes restringir los resultados por restricciones categóricas y numéricas. Añadir restricciones o "filtrar" los resultados del índice es útil por varios motivos, como los siguientes:
Mejora de la relevancia de los resultados: Vector Search es una herramienta eficaz para encontrar elementos semánticamente similares. Los filtros se pueden usar para eliminar resultados irrelevantes de los resultados de búsqueda, como elementos que no estén en el idioma, la categoría, el precio o el periodo correctos.
Número de resultados reducido: la búsqueda vectorial puede devolver un gran número de resultados, sobre todo en el caso de conjuntos de datos grandes. El filtrado se puede usar para reducir el número de resultados a una cantidad más manejable, sin dejar de devolver los resultados más relevantes.
Resultados segmentados: se pueden usar filtros para personalizar los resultados de búsqueda según las necesidades y preferencias de cada usuario. Por ejemplo, un usuario puede querer filtrar los resultados para que solo se incluyan los elementos que haya valorado positivamente en el pasado o que se encuentren dentro de un intervalo de precios específico.
Atributos de vector
En una búsqueda de similitud vectorial en una base de datos de vectores, cada vector se describe mediante cero o más atributos. Estos atributos se conocen como tokens en el caso de las restricciones de tokens y valores en el caso de las restricciones numéricas. Estas restricciones se pueden aplicar desde cada una de las categorías de atributos, también conocidas como espacios de nombres.
En la siguiente aplicación de ejemplo, los vectores se etiquetan con color, price y shape:
color,priceyshapeson espacios de nombres.redyblueson tokens del espacio de nombrescolor.squareycircleson tokens del espacio de nombresshape.100y50son valores del espacio de nombresprice.
Especificar atributos de vector
- Para especificar un "círculo rojo",
{color: red}, {shape: circle}. - Para especificar un "cuadrado rojo o azul", escribe
{color: red, blue}, {shape: square}. - Para especificar un objeto sin color, omite el espacio de nombres "color" en el campo
restricts. - Para especificar restricciones numéricas de un objeto, anota el espacio de nombres y el valor en el campo correspondiente del tipo. El valor Int debe especificarse en
value_int, el valor Float envalue_floaty el valor Double envalue_double. Solo se debe usar un tipo de número para un espacio de nombres determinado.
Para obtener información sobre el esquema que se usa para especificar estos datos, consulta Especificar espacios de nombres y tokens en los datos de entrada.
Consultas
- Las consultas expresan un operador lógico AND entre espacios de nombres y un operador lógico OR en cada espacio de nombres. Una consulta que especifica
{color: red, blue}, {shape: square, circle}coincide con todos los puntos de la base de datos que cumplen(red || blue) && (square || circle). - Una consulta que especifica
{color: red}coincide con todos los objetosredde cualquier tipo, sin restricciones enshape. - Las restricciones numéricas en las consultas requieren
namespace, uno de los valores numéricos devalue_int,value_floatyvalue_double, y el operadorop. - El operador
opes uno de los siguientes:LESS,LESS_EQUAL,EQUAL,GREATER_EQUALyGREATER. Por ejemplo, si se usa el operadorLESS_EQUAL, los puntos de datos son aptos si su valor es menor o igual que el valor usado en la consulta.
En los siguientes ejemplos de código se identifican los atributos de vector en la aplicación de ejemplo:
[
{
"namespace": "price",
"value_int": 20,
"op": "LESS"
},
{
"namespace": "length",
"value_float": 0.3,
"op": "GREATER_EQUAL"
},
{
"namespace": "width",
"value_double": 0.5,
"op": "EQUAL"
}
]
Lista de no permitidas
Para habilitar escenarios más avanzados, Google admite una forma de negación conocida como tokens de lista de denegación. Cuando una consulta incluye un token en una lista de denegación, se excluyen las coincidencias de cualquier punto de datos que tenga el token incluido en la lista de denegación. Si un espacio de nombres de consulta solo tiene tokens incluidos en la lista de denegación, todos los puntos que no estén incluidos explícitamente en la lista de denegación coincidirán, exactamente igual que si el espacio de nombres estuviera vacío.
Los puntos de datos también pueden incluir un token en una lista de denegación, lo que excluye las coincidencias con cualquier consulta que especifique ese token.
Por ejemplo, define los siguientes puntos de datos con los tokens especificados:
A: {} // empty set matches everything
B: {red} // only a 'red' token
C: {blue} // only a 'blue' token
D: {orange} // only an 'orange' token
E: {red, blue} // multiple tokens
F: {red, !blue} // deny the 'blue' token
G: {red, blue, !blue} // An unlikely edge-case
H: {!blue} // deny-only (similar to empty-set)
El sistema se comporta de la siguiente manera:
- Los espacios de nombres de consultas vacías son comodines que coinciden con todo. Por ejemplo, Q:
{}coincide con DB:{color:red}. Los espacios de nombres de puntos de datos vacíos no son comodines que coincidan con todo. Por ejemplo, Q:
{color:red}no coincide con DB:{}.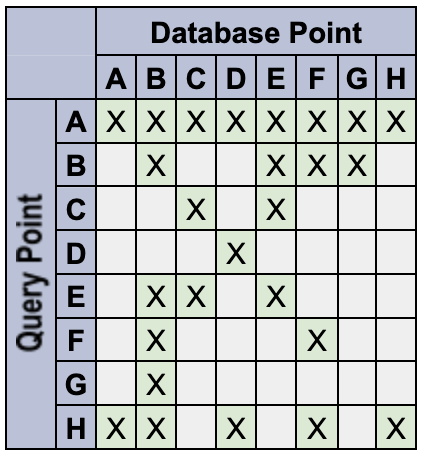
Especificar espacios de nombres, tokens o valores en los datos de entrada
Para obtener información sobre cómo estructurar los datos de entrada en general, consulta el artículo Formato y estructura de los datos de entrada.
En las pestañas siguientes se muestra cómo especificar los espacios de nombres y los tokens asociados a cada vector de entrada.
JSON
En el registro de cada vector, añade un campo llamado
restrictspara incluir una matriz de objetos, cada uno de los cuales es un espacio de nombres.- Cada objeto debe tener un campo llamado
namespace. Este campo es elTokenNamespace.namespace, espacio de nombres. - El valor del campo
allow, si está presente, es un array de cadenas. Esta matriz de cadenas es la listaTokenNamespace.string_tokens. - El valor del campo
deny, si está presente, es un array de cadenas. Esta matriz de cadenas es la listaTokenNamespace.string_denylist_tokens.
- Cada objeto debe tener un campo llamado
A continuación se muestran dos registros de ejemplo en formato JSON:
[
{
"id": "42",
"embedding": [
0.5,
1
],
"restricts": [
{
"namespace": "class",
"allow": [
"cat",
"pet"
]
},
{
"namespace": "category",
"allow": [
"feline"
]
}
]
},
{
"id": "43",
"embedding": [
0.6,
1
],
"sparse_embedding": {
"values": [
0.1,
0.2
],
"dimensions": [
1,
4
]
},
"restricts": [
{
"namespace": "class",
"allow": [
"dog",
"pet"
]
},
{
"namespace": "category",
"allow": [
"canine"
]
}
]
}
]
En cada registro de vector, añada un campo llamado
numeric_restrictspara incluir una matriz de objetos, cada uno de los cuales es una restricción numérica.- Cada objeto debe tener un campo llamado
namespace. Este campo es elNumericRestrictNamespace.namespace, espacio de nombres. - Cada objeto debe tener uno de los valores
value_int,value_floatyvalue_double. - Ningún objeto debe tener un campo llamado
op. Este campo solo se usa para consultas.
- Cada objeto debe tener un campo llamado
A continuación se muestran dos registros de ejemplo en formato JSON:
[
{
"id": "42",
"embedding": [
0.5,
1
],
"numeric_restricts": [
{
"namespace": "size",
"value_int": 3
},
{
"namespace": "ratio",
"value_float": 0.1
}
]
},
{
"id": "43",
"embedding": [
0.6,
1
],
"sparse_embedding": {
"values": [
0.1,
0.2
],
"numeric_restricts": [
{
"namespace": "weight",
"value_double": 0.3
}
]
}
}
]
Avro
Los registros Avro usan el siguiente esquema:
{
"type": "record",
"name": "FeatureVector",
"fields": [
{
"name": "id",
"type": "string"
},
{
"name": "embedding",
"type": {
"type": "array",
"items": "float"
}
},
{
"name": "sparse_embedding",
"type": [
"null",
{
"type": "record",
"name": "sparse_embedding",
"fields": [
{
"name": "values",
"type": {
"type": "array",
"items": "float"
}
},
{
"name": "dimensions",
"type": {
"type": "array",
"items": "long"
}
}
]
}
]
},
{
"name": "restricts",
"type": [
"null",
{
"type": "array",
"items": {
"type": "record",
"name": "Restrict",
"fields": [
{
"name": "namespace",
"type": "string"
},
{
"name": "allow",
"type": [
"null",
{
"type": "array",
"items": "string"
}
]
},
{
"name": "deny",
"type": [
"null",
{
"type": "array",
"items": "string"
}
]
}
]
}
}
]
},
{
"name": "numeric_restricts",
"type": [
"null",
{
"type": "array",
"items": {
"name": "NumericRestrict",
"type": "record",
"fields": [
{
"name": "namespace",
"type": "string"
},
{
"name": "value_int",
"type": [ "null", "int" ],
"default": null
},
{
"name": "value_float",
"type": [ "null", "float" ],
"default": null
},
{
"name": "value_double",
"type": [ "null", "double" ],
"default": null
}
]
}
}
],
"default": null
},
{
"name": "crowding_tag",
"type": [
"null",
"string"
]
}
]
}
CSV
Restricciones de tokens
En el registro de cada vector, añade pares separados por comas con el formato
name=valuepara especificar las restricciones del espacio de nombres del token. El mismo nombre se puede repetir si hay varios valores en un espacio de nombres.Por ejemplo,
color=red,color=bluerepresenta esteTokenNamespace:{ "namespace": "color" "string_tokens": ["red", "blue"] }En cada registro de vector, añade pares separados por comas con el formato
name=!valuepara especificar el valor excluido de las restricciones del espacio de nombres del token.Por ejemplo,
color=!redrepresenta esteTokenNamespace:{ "namespace": "color" "string_blacklist_tokens": ["red"] }
Restricciones numéricas
En el registro de cada vector, añade pares separados por comas con el formato
#name=numericValuey el sufijo de tipo de número para especificar las restricciones de espacio de nombres numéricas.El sufijo del tipo de número es
ipara int,fpara float ydpara double. No se debe repetir el mismo nombre, ya que debe haber un único valor asociado por espacio de nombres.Por ejemplo,
#size=3irepresenta esteNumericRestrictNamespace:{ "namespace": "size" "value_int": 3 }#ratio=0.1frepresenta lo siguiente:NumericRestrictNamespace{ "namespace": "ratio" "value_float": 0.1 }#weight=0.3drepresenta lo siguiente:NumericRestriction{ "namespace": "weight" "value_double": 0.3 }A continuación, se muestra un ejemplo de punto de datos con
id: "6",embedding: [7, -8.1],sparse_embedding: {values: [0.1, -0.2, 0.5],dimensions: [40, 901, 1111]}}, etiqueta de aglomeracióntest, lista de tokens permitidoscolor: red, blue, lista de tokens no permitidoscolor: purpley restricción numéricaratiocon el valor flotante0.1:6,7,-8.1,40:0.1,901:-0.2,1111:0.5,crowding_tag=test,color=red,color=blue,color=!purple, ratio=0.1f