Si ya realizaste los instructivos, en esta página, se describen las prácticas recomendadas para Neural Architecture Search. En la primera sección, se resume un flujo de trabajo completo que puedes seguir para tu trabajo en Neural Architecture Search. En las otras secciones, se proporciona una descripción detallada de cada paso. Te recomendamos que revises toda la página antes de ejecutar tu primer trabajo de Neural Architecture Search.
Flujo de trabajo sugerido
A continuación, se resume un flujo de trabajo sugerido para Neural Architecture Search y se proporcionan vínculos a las secciones correspondientes a fin de obtener más detalles:
- Divide tu conjunto de datos de entrenamiento para la búsqueda de etapa 1.
- Asegúrate de que tu espacio de búsqueda cumpla con nuestros lineamientos.
- Ejecuta el entrenamiento completo con tu modelo de referencia y obtén una curva de validación.
- Ejecuta las herramientas de diseño de tareas de proxy para encontrar la mejor tarea de proxy.
- Realiza las verificaciones finales de tu tarea de proxy.
- Establece la cantidad adecuada de pruebas totales y pruebas paralelas y, luego, inicia la búsqueda.
- Supervisa el diagrama de búsqueda y detenlo cuando alcance una convergencia, muestre una gran cantidad de errores o no muestre signos de convergencia.
- Ejecuta el entrenamiento completo con las primeras 10 pruebas elegidas de tu búsqueda para el resultado final. Para el entrenamiento completo, puedes usar más magnificación o pesos entrenados previamente a fin de obtener el mejor rendimiento posible.
- Analiza las métricas y los datos guardados de la búsqueda, y saca conclusiones para futuras iteraciones de espacio de búsqueda.
Búsqueda típica de Neural Architecture Search
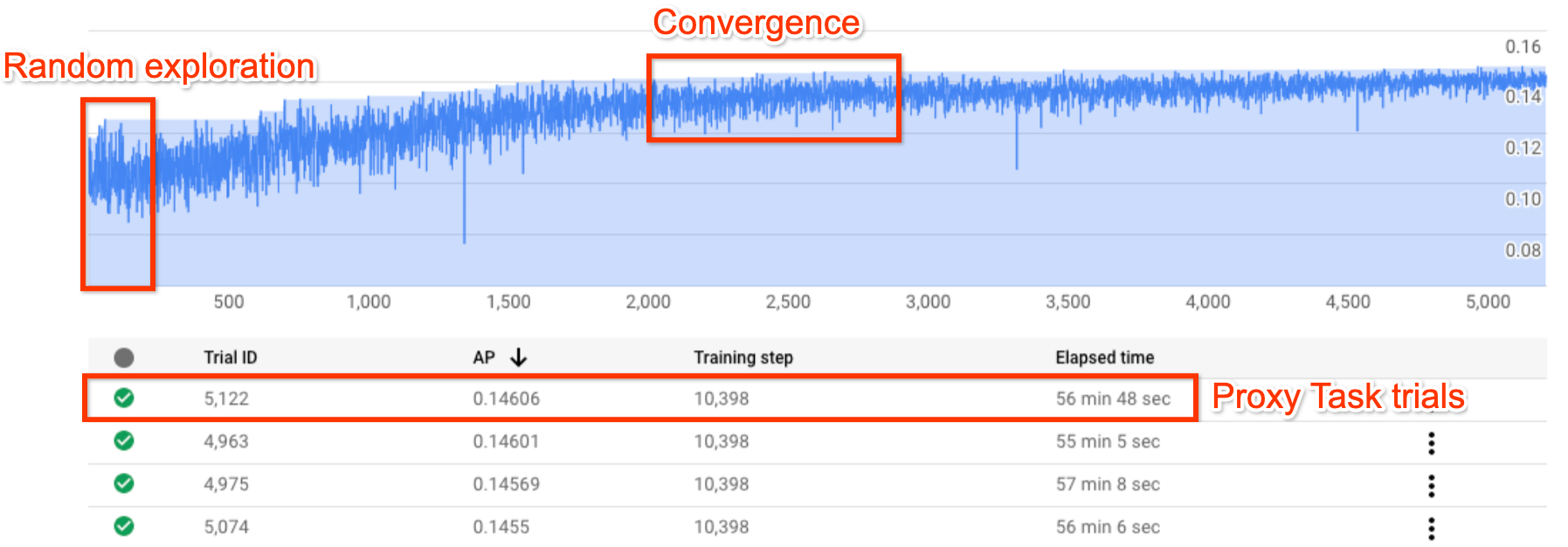
En la figura anterior, se muestra una curva de búsqueda típica de Neural Architecture Search.
El Y-axis muestran las recompensas de las pruebas y el X-axis muestra la cantidad de pruebas que se iniciaron hasta el momento.
Las primeras 100 a 200 pruebas son, en su mayoría, exploraciones aleatorias del espacio de búsqueda del controlador.
Durante estas exploraciones iniciales, las recompensas muestran una gran variación porque se prueban muchos tipos de modelos en el espacio de búsqueda.
A medida que aumenta la cantidad de pruebas, el controlador comienza a encontrar mejores modelos. Por lo tanto, al principio, las recompensas comienzan a aumentar y, luego, los pares recompensa-variación y recompensa-crecimiento comienzan a disminuir y muestran la convergencia. La cantidad de pruebas en las que aparece la convergencia puede variar según el tamaño del espacio de búsqueda, pero, por lo general, es de alrededor de 2,000 pruebas.
Las dos etapas de la búsqueda de Neural Architecture Search: la tarea de proxy y el entrenamiento completo
Neural Architecture Search tiene dos etapas:
La búsqueda de la etapa 1 usa una representación mucho más pequeña del entrenamiento completo, que suele terminar en 1 a 2 horas. Esta representación se denomina tarea de proxy y ayuda a mantener el costo de búsqueda bajo.
La etapa 2 implica realizar un entrenamiento completo en los 10 modelos principales de la búsqueda de la etapa 1. Debido a la naturaleza estocástica de la búsqueda, el modelo principal de la búsqueda de la etapa 1 puede no ser el modelo principal del entrenamiento completo de la etapa 2, por lo tanto, es importante seleccionar un grupo de modelos para el entrenamiento completo.
Dado que el controlador obtiene la señal de recompensa de la tarea de proxy más pequeña en lugar del entrenamiento completo, es importante encontrar una tarea de proxy óptima para tu tarea.
Costo de Neural Architecture Search
El costo de Neural Architecture Search tiene los siguientes valores: search-cost = num-trials-to-converge * avg-proxy-task-cost.
Si suponemos que el tiempo de procesamiento de la proxy-task es de alrededor de 1/30 del tiempo completo del entrenamiento y que la cantidad de pruebas necesarias para la convergencia es de alrededor de 2,000, entonces el costo de la búsqueda será de 67 * full-training-cost.
Dado que el costo de la búsqueda de Neural Architecture Search es alto, es recomendable que dediques tiempo a ajustar tu tarea de proxy y que uses un espacio de búsqueda más pequeño para tu primera búsqueda.
División del conjunto de datos dividido en dos etapas para la búsqueda de Neural Architecture Search
Si suponemos que ya tienes datos de entrenamiento y datos de validación para tu entrenamiento de referencia, se recomienda la siguiente división del conjunto de datos para las dos etapas de la búsqueda de Neural Architecture Search:
- Entrenamiento de búsqueda de la etapa 1: Alrededor del 90% de los datos de entrenamiento
Validación de la búsqueda de la etapa 1: Alrededor del 10% de los datos de entrenamiento
Entrenamiento completo de la etapa 2: El 100% de los datos de entrenamiento
Validación del entrenamiento completo de la etapa 2: El 100% de los datos de validación
La división de datos del entrenamiento completo de la etapa 2 es la misma que la del entrenamiento normal. Sin embargo, la búsqueda de la etapa 1 usa una división de datos de entrenamiento para la validación. El uso de datos de validación diferentes en la etapa 1 y la etapa 2 ayuda a detectar cualquier sesgo de búsqueda de modelos debido a la división del conjunto de datos. Asegúrate de que los datos de entrenamiento estén bien redistribuidos antes de particionarlos aún más y que la división final de los datos de entrenamiento del 10% tenga una distribución similar a la de los datos de validación originales.
Datos pequeños o desequilibrados
No se recomienda la búsqueda de arquitectura con datos de entrenamiento limitados o conjuntos de datos altamente desequilibrados en los que algunas clases son muy poco frecuentes. Si ya usas magnificaciones importantes para el entrenamiento del modelo de referencia debido a la falta de datos, no se recomienda la búsqueda de modelos.
En este caso, solo puedes ejecutar la búsqueda de magnificación para encontrar la mejor política de magnificación en lugar de buscar una arquitectura óptima.
Diseño del espacio de búsqueda
La búsqueda de arquitectura no debe mezclarse con la búsqueda de magnificación ni la búsqueda de hiperparámetros (como la tasa de aprendizaje o la configuración del optimizador). El objetivo de la búsqueda de arquitectura es comparar el rendimiento del modelo A con el modelo B cuando solo hay diferencias basadas en la arquitectura. Por lo tanto, la configuración de magnificación y de hiperparámetros debe ser la misma.
La búsqueda de magnificación se puede realizar como una etapa diferente después de que se complete la búsqueda de arquitectura.
La Búsqueda de arquitectura neuronal puede alcanzar hasta 10^20 en el tamaño del espacio de búsqueda. Sin embargo, si tu espacio de búsqueda es más grande, puedes dividirlo en partes mutuamente excluyentes. Por ejemplo, puedes buscar el codificador por separado desde el decodificador o el encabezado primero. Si aún deseas realizar una búsqueda conjunta de todos ellos, puedes crear un espacio de búsqueda más pequeño alrededor de las mejores opciones individuales que se encontraron antes.
De manera opcional, puedes ajustar el modelo desde el diseño de bloque cuando diseñas un espacio de búsqueda. La búsqueda de diseño de bloque debe realizarse primero con un modelo de escala reducida. Esto puede permitir que el costo del entorno de ejecución de la tarea de proxy sea mucho más bajo. Luego, puedes hacer una búsqueda separada para escalar el modelo. Para obtener más información, consulta
Examples of scaled down models.
Optimiza el tiempo de entrenamiento y de búsqueda
Antes de ejecutar la búsqueda de Neural Architecture Search, es importante optimizar el tiempo de entrenamiento de tu modelo de referencia. Esto te permitirá ahorrar costos a largo plazo. Estas son algunas de las opciones para optimizar el entrenamiento:
- Maximiza la velocidad de carga de datos:
- Asegúrate de que el bucket en el que residen tus datos se encuentre en la misma región que tu trabajo.
- Si usas TensorFlow, consulta
Best practice summary. También puedes intentar usar el formato TFRecord para tus datos. - Si usas PyTorch, sigue los lineamientos para obtener un entrenamiento eficiente de PyTorch.
- Usa el entrenamiento distribuido para aprovechar varios aceleradores o varias máquinas.
- Usa el entrenamiento de precisión mixto para obtener una aceleración de entrenamiento significativa y una reducción en el uso de la memoria.
Para el entrenamiento de precisión mixta de TensorFlow, consulta
Mixed Precision. - Algunos aceleradores (como A100) suelen ser más rentables.
- Ajusta el tamaño del lote para optimizar el uso de la GPU.
En el siguiente gráfico, se muestra un uso deficiente de las GPU (en un 50%).
 Aumentar el tamaño del lote puede a optimizar el uso de las GPU. Sin embargo, el tamaño del lote debe aumentarse con cuidado, ya que generar más errores de memoria insuficiente durante la búsqueda.
Aumentar el tamaño del lote puede a optimizar el uso de las GPU. Sin embargo, el tamaño del lote debe aumentarse con cuidado, ya que generar más errores de memoria insuficiente durante la búsqueda. - Si ciertos bloques de arquitectura son independientes del espacio de búsqueda, puedes intentar cargar puntos de control previamente entrenados para estos bloques a fin de acelerar el entrenamiento. Los puntos de control previamente entrenados deben ser iguales en el espacio de búsqueda y no deben introducir un sesgo. Por ejemplo, si el espacio de búsqueda es solo para el decodificador, el codificador puede usar puntos de control previamente entrenados.
Cantidad de GPU para cada prueba de búsqueda
Usa una cantidad menor de GPU por prueba para reducir la hora de inicio. Por ejemplo, 2 GPU toman 5 minutos en iniciarse, mientras que 8 GPU toman 20 minutos. Es más eficiente usar 2 GPU por prueba para ejecutar una tarea de proxy de trabajo de búsqueda de arquitectura neuronal.
Total de pruebas y pruebas paralelas de búsqueda
Configuración total de la prueba
Una vez que hayas buscado y seleccionado la mejor tarea de proxy, estará todo listo para iniciar una búsqueda completa. No es posible saber de antemano cuántas pruebas alcanzará la convergencia. La cantidad de pruebas en las que aparece la convergencia puede variar según el tamaño del espacio de búsqueda, pero, por lo general, es de alrededor de 2,000 pruebas.
Recomendamos una configuración muy alta para --max_nas_trial: entre 5,000 y 10,000 y, luego, cancelar el trabajo de búsqueda antes si el diagrama de búsqueda muestra una convergencia.
También tienes la opción de reanudar un trabajo de búsqueda anterior con el comando search_resume.
Sin embargo, no puedes reanudar la búsqueda desde otro trabajo de reanudación de búsqueda.
Por lo tanto, solo puedes reanudar un trabajo de búsqueda original una vez.
Configuración de pruebas paralelas
La tarea de búsqueda de etapa 1 realiza el procesamiento por lotes ejecutando una cantidad de pruebas --max_parallel_nas_trial en paralelo a la vez. Esto es fundamental para reducir el tiempo de ejecución general de la tarea de búsqueda. Puedes calcular la cantidad esperada de días para la búsqueda:days-required-for-search = (trials-to-converge / max-parallel-nas-trial) * (avg-trial-duration-in-hours / 24)
Nota: Inicialmente, puedes usar 3000 como una estimación aproximada de trials-to-converge, que es un buen límite superior para empezar. En un principio, puedes usar 2 horas como una estimación aproximada de avg-trial-duration-in-hours, que es un buen límite superior para el tiempo que tarda cada tarea de proxy.
Se recomienda usar la configuración --max_parallel_nas_trial de entre 20 y 50, según la cuota del acelerador que tenga tu proyecto y days-required-for-search.
Por ejemplo, si estableces --max_parallel_nas_trial en 20 y cada tarea de proxy usa dos GPUs NVIDIA T4, debes haber reservado una cuota de al menos 40 GPUs NVIDIA T4. El parámetro de configuración --max_parallel_nas_trial no afecta el resultado general de la búsqueda, pero sí afecta a days-required-for-search.
También es posible establecer una configuración más pequeña para max_parallel_nas_trial, como alrededor de 10 (20 GPUs), pero debes calcular de forma aproximada el days-required-for-search y asegurarte de que esté dentro del límite de tiempo de espera del trabajo.
Por lo general, el trabajo de entrenamiento completo de la etapa 2 entrena todas las pruebas en paralelo de forma predeterminada. Por lo general, estas son las 10 pruebas principales que se ejecutan en paralelo. Sin embargo, si cada prueba de entrenamiento completo de etapa 2 usa demasiadas GPUs (por ejemplo, ocho GPUa cada una) para tu caso de uso y no tienes una cuota suficiente, puedes ejecutar de forma manual trabajos de etapa 2 en lotes, como ejecutar un entrenamiento completo de etapa 2 para solo cinco pruebas y, luego, ejecutar otro entrenamiento completo de etapa 2 para las 5 pruebas siguientes.
Tiempo de espera predeterminado del trabajo
El tiempo de espera de trabajo de NAS predeterminado se establece en 14 días y, después de eso, el trabajo se cancela. Si prevés que ejecutarás el trabajo por más tiempo, puedes reanudar el trabajo de búsqueda solo una vez más durante 14 días más. En general, puedes ejecutar un trabajo de búsqueda durante 28 días, incluido el currículum.
Configuración de cantidad máxima de pruebas con errores
La cantidad máxima de pruebas con errores debe establecerse en alrededor de un tercio de la configuración de max_nas_trial. El trabajo se cancelará cuando la cantidad de pruebas con errores alcance este límite.
Cuándo detener la búsqueda
Debes detener la búsqueda en los siguientes casos:
La curva de búsqueda comienza a converger (la variación disminuye):
Nota: Si no se usa una restricción de latencia o si la restricción de latencia estricta se usa con un límite de latencia flexible, es posible que la curva no muestre un aumento en la recompensa, pero debería mostrar la convergencia. Esto se debe a que el controlador puede haber encontrado exactitudes al principio de la búsqueda.Más del 20% de tus pruebas muestran recompensas no válidas (fallas):
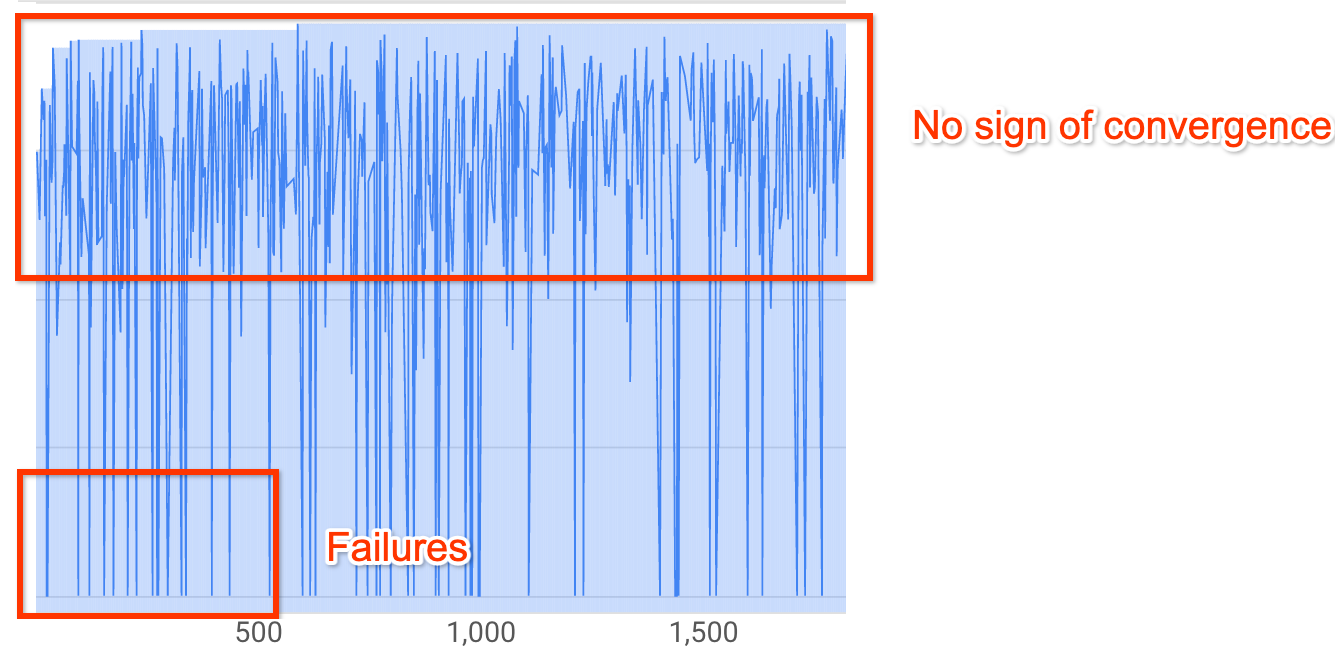
La curva de búsqueda no aumenta ni converge (como se muestra arriba) incluso después de 500 pruebas. Si se muestra un aumento en las recompensas o una disminución de la variación, puedes continuar.