Antes de ejecutar un trabajo de búsqueda de arquitectura neuronal para buscar un modelo óptimo, define tu tarea de proxy. La búsqueda de etapa 1 usa una representación mucho más pequeña de un entrenamiento de modelos completo, que suele terminar en dos horas. Esta representación se denomina tarea de proxy y reduce el costo de búsqueda de manera significativa. Cada prueba durante la búsqueda entrena un modelo mediante la configuración de la tarea de proxy.
En las siguientes secciones, se describe lo que implica la aplicación del diseño de tareas de proxy:
- Enfoques para crear una tarea de proxy.
- Requisitos de una buena tarea de proxy.
- Cómo usar las tres herramientas de diseño de tareas de proxy para encontrar la tarea óptima, lo que reduce el costo de búsqueda y mantiene la calidad de esta.
Enfoques para crear una tarea de proxy
Existen tres enfoques comunes para crear una tarea de proxy, que incluyen lo siguiente:
- Usar menos pasos de entrenamiento.
- Usar un conjunto de datos de entrenamiento con submuestras.
- Usar un modelo reducido.
Usar menos pasos de entrenamiento
La forma más sencilla de crear una tarea de proxy es reducir la cantidad de pasos de entrenamiento para tu entrenador e informar una puntuación al controlador en función de este entrenamiento parcial.
Usar un conjunto de datos de entrenamiento con submuestras.
En esta sección, se describe el uso de un conjunto de datos de entrenamiento con submuestras para una búsqueda de arquitectura y una búsqueda de políticas de magnificación.
Búsqueda de arquitectura
Se puede crear una tarea de proxy mediante un conjunto de datos de entrenamiento con submuestras durante la búsqueda de arquitectura. Sin embargo, cuando se realice el submuestreo, sigue estos lineamientos:
- Distribuye los datos de forma aleatoria entre fragmentos.
- Si los datos de entrenamiento están desequilibrados, usa el submuestreo para balancearlos.
Búsqueda de políticas de magnificación mediante la magnificación automática
Omite esta sección si no ejecutas una búsqueda de magnificación y solo ejecutas la búsqueda normal de arquitectura. Usa la magnificación automática para buscar una política de magnificación. Es conveniente realizar una submuestra de los datos de entrenamiento y ejecutar un entrenamiento completo que reducir la cantidad de pasos de entrenamiento. Ejecutar el entrenamiento completo con una magnificación alta mantiene las puntuaciones más estables. Además, usa los datos de entrenamiento reducidos para mantener el costo de búsqueda más bajo.
Tarea de proxy basada en un modelo reducido
También puedes reducir la escala verticalmente del modelo en relación con el modelo de referencia para crear una tarea de proxy. Esto también puede ser útil cuando deseas separar la búsqueda de diseño de bloque de la búsqueda de escala.
Sin embargo, si reduces la escala del modelo y quieres usar una restricción de latencia, usa una restricción de latencia más estricta para el modelo reducido. Sugerencia: Puedes reducir la escala verticalmente del modelo de referencia y medir su latencia para establecer esta restricción de latencia más estricta.
Para el modelo de reducción de escala, también puedes reducir la cantidad de magnificación y regularización en comparación con el modelo de referencia original.
Ejemplos de un modelo con escala reducida verticalmente
Para las tareas de visión artificial en las que entrenas en imágenes, existen tres maneras comunes de reducir la escala de un modelo:
- Reducir el ancho del modelo: una cantidad de canales.
- Reducir la profundidad del modelo: una cantidad de capas y bloques que se repiten.
- Reducir ligeramente el tamaño de la imagen de entrenamiento (para que no elimine atributos) o recortar las imágenes de entrenamiento si tu tarea lo permite.
Lectura sugerida: El informe de EfficientNet proporciona excelentes estadísticas sobre el escalamiento de modelos para las tareas de visión artificial. También explica cómo se relacionan las tres formas de escalamiento.
La búsqueda de Spinnaker es otro ejemplo de escalamiento de modelos que se usa con Neural Architecture Search. Para la búsqueda de la etapa 1, reduce la cantidad de canales y el tamaño de la imagen.
Tarea de proxy basada en una combinación
Los enfoques funcionan de forma independiente y se pueden combinar en diferentes grados para crear una tarea de proxy.
Requisitos de una buena tarea de proxy
Una tarea de proxy debe cumplir con ciertos requisitos antes de que pueda otorgar una recompensa estable al controlador y mantener la calidad de la búsqueda.
Correlación de rangos entre la búsqueda de la etapa 1 y el entrenamiento completo de la etapa 2
Cuando se usa una tarea de proxy para la búsqueda de Neural Architecture Search, una suposición clave de una búsqueda exitosa es que, si el modelo A funciona mejor que el modelo B durante entrenamiento de la tarea de proxy de la etapa 1, el modelo A también tendrá un mejor rendimiento que el modelo B en el entrenamiento completo de la etapa 2. Para validar esta suposición, debes evaluar la correlación de rangos entre las recompensas de las búsquedas de la etapa 1 y el entrenamiento completo de la etapa 2 en alrededor de 10-20 modelos en tu espacio de búsqueda. Estos modelos se denominan modelos de candidato de correlación.
En la figura a continuación, se muestra un ejemplo de una correlación deficiente (puntuación de correlación = -0.03), lo que hace que esta tarea de proxy sea una mala opción para una búsqueda:
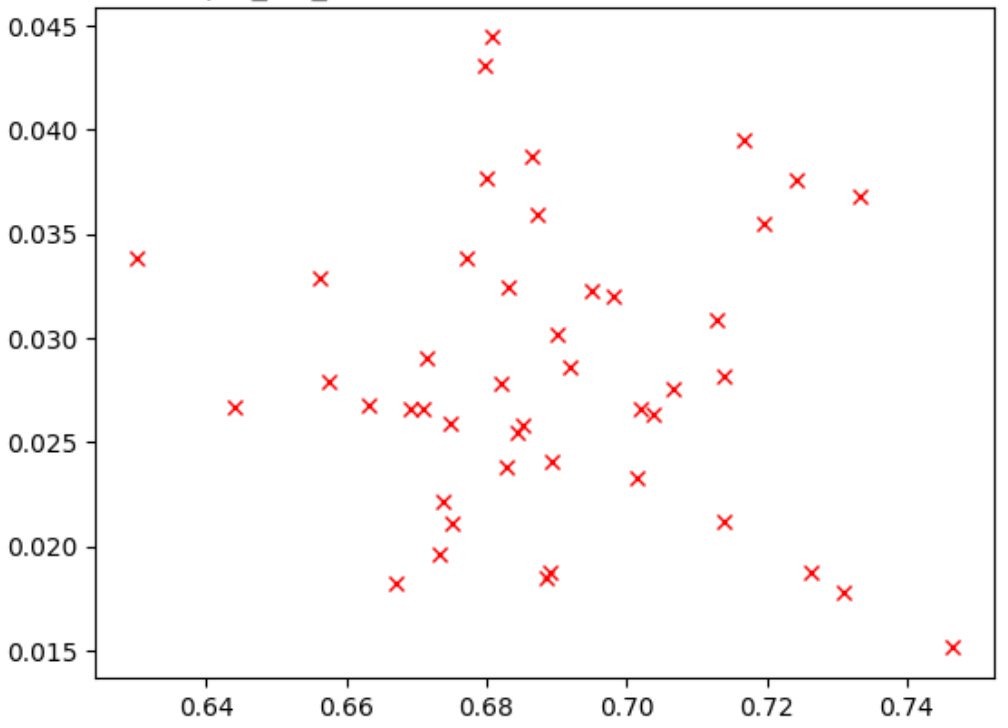
Cada punto del diagrama representa un modelo candidato de correlación.
El eje x representa las puntuaciones de entrenamiento completo de etapa 2 de los modelos, y el eje y representa las puntuaciones de la tarea de proxy de etapa 1 para los mismos modelos.
Observa el punto más alto. Este modelo otorgó la puntuación de tarea de proxy más alta (eje y), pero tiene un rendimiento bajo durante el entrenamiento completo de etapa 2 (eje x) en comparación con otros modelos. Por el contrario, en la figura a continuación, se muestra un ejemplo de una buena correlación (puntuación de correlación = 0.67), lo que hace que esta tarea de proxy sea una buena candidata para una búsqueda:
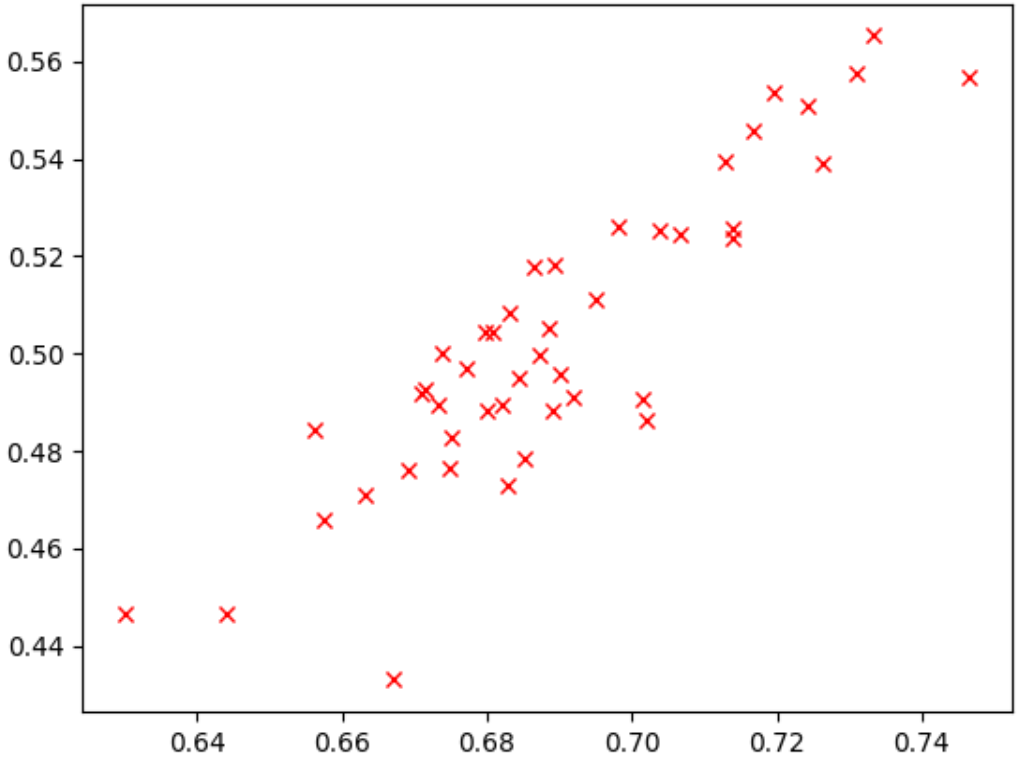
Si tu búsqueda implica una restricción de latencia, verifica que también haya una correlación buena para los valores de latencia.
Ten en cuenta que las recompensas de modelo de candidato de correlación tienen un buen rango y un muestreo aceptable del rango de recompensas. De lo contrario, no puedes evaluar la correlación de rangos. Por ejemplo, si todas las recompensas de etapa 1 de los modelos candidatos para la correlación se centran en solo dos valores, 0.9 y 0.1, entonces esto no proporciona suficiente variación de muestreo.
Verificación de variación
Otro requisito de una tarea de proxy es que no debe tener una gran variación en la precisión ni su puntuación de latencia cuando se repite varias veces para el mismo modelo sin ningún cambio. Si esto sucede, le dará una señal ruidosa al controlador. Se proporciona una herramienta para medir esta varianza.
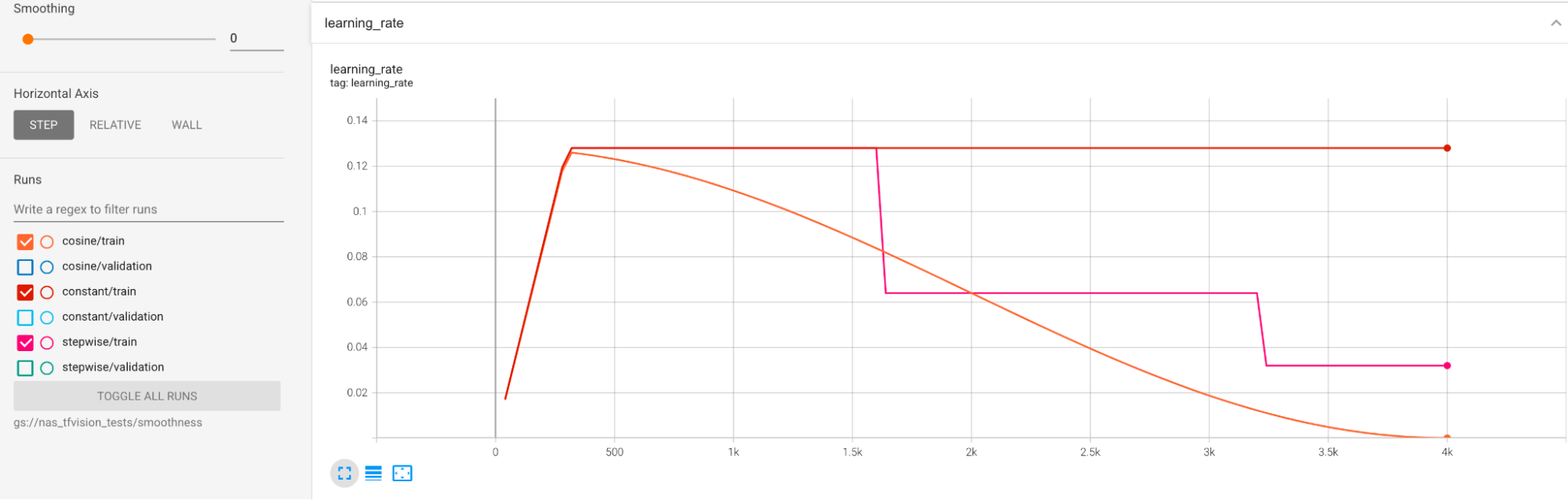
Se proporcionan ejemplos para mitigar una gran varianza durante el entrenamiento. Una forma es usar cosine decay como el programa de tasa de aprendizaje. En el siguiente diagrama, se comparan tres estrategias de tasa de aprendizaje:

El diagrama más bajo corresponde a una tasa de aprendizaje constante. Cuando la puntuación se modifica al final del entrenamiento, un pequeño cambio en la cantidad reducida de pasos de entrenamiento puede causar un gran cambio en la recompensa de la tarea de proxy final. Para que la recompensa de la tarea de proxy sea más estable, es mejor usar una disminución de coseno de la tasa de aprendizaje, como lo muestran las puntuaciones de validación correspondientes en el diagrama superior. Observa cómo el diagrama superior se vuelve más fluido al final del entrenamiento. En el diagrama del medio, se muestra la puntuación correspondiente a la disminución gradual de la tasa de aprendizaje. Es mejor que la tasa constante, pero aún no es tan uniforme como la disminución del coseno, y también requiere un ajuste manual.
Los programas de tasa de aprendizaje se muestran a continuación:
Fluidez adicional
Si usas una magnificación importante, es posible que la curva de validación aún no sea lo suficientemente uniforme con la disminución del coseno. El uso de una magnificación importante indica la falta de datos de entrenamiento. En este caso, no se recomienda el uso de la búsqueda de arquitectura neuronal, por lo que te sugerimos que uses la búsqueda de aumento.
Si el aumento grande no es la causa y ya probaste la disminución del coseno, pero aún deseas lograr más suavidad, usa la media móvil exponencial para TensorFlow-2 o media ponderada estocásica para PyTorch. Consulta este punto de código para ver un ejemplo en el que se usa un optimizador de media móvil exponencial con TensorFlow 2 y este ejemplo de promediación con ponderación estocástica para PyTorch.
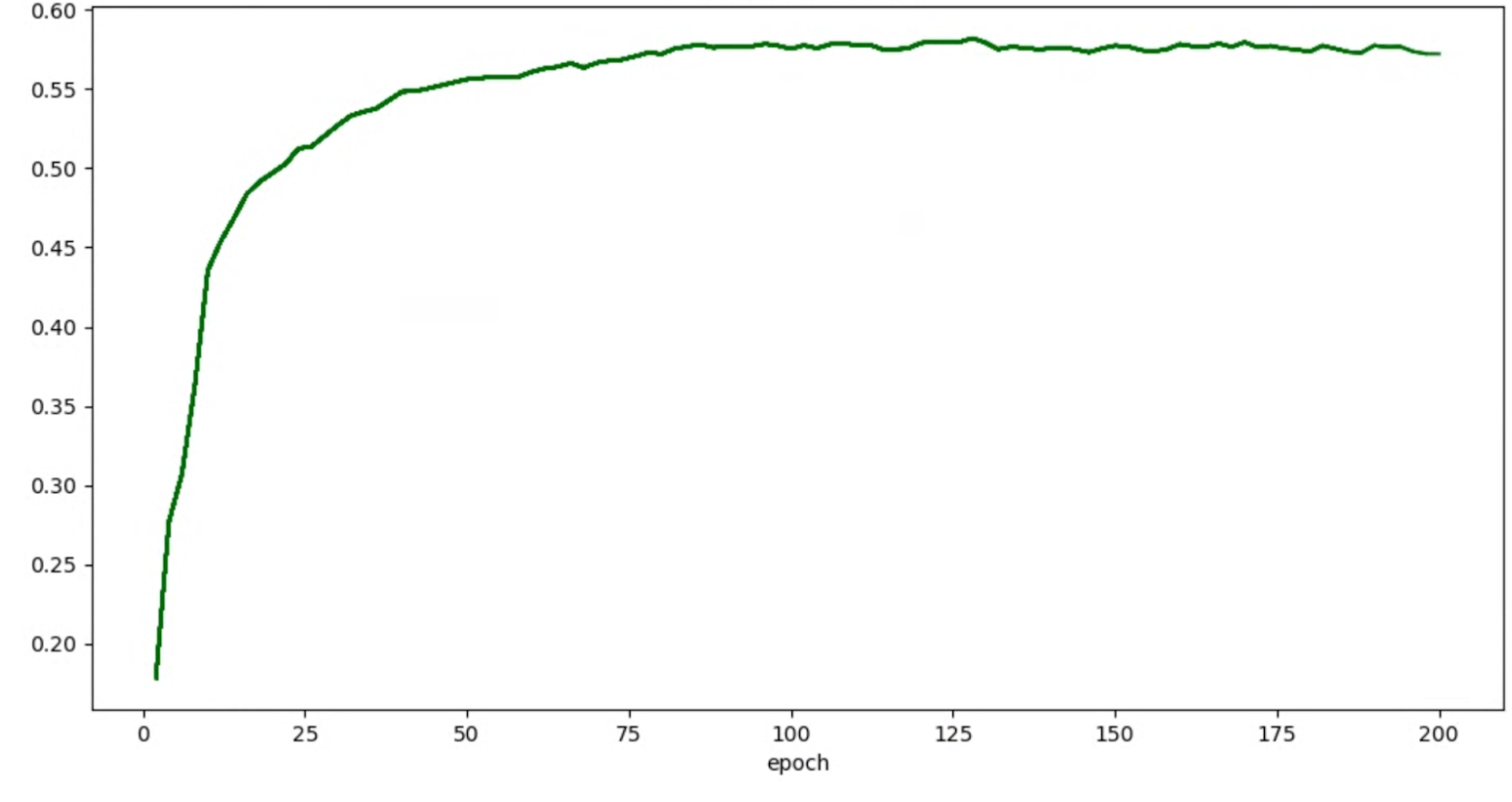
Si tus grafos de exactitud/ciclo de entrenamiento para las pruebas se ven de la siguiente manera:

Luego, puedes aplicar las técnicas de suavizamiento mencionadas antes (como el promedio ponderado estocástico o el uso de la media móvil exponencial) para obtener un grafo más coherente como el siguiente:
Errores de memoria insuficiente (OOM) y tasa de aprendizaje
La arquitectura del espacio de búsqueda puede generar modelos mucho más grandes que el modelo de referencia. Es posible que hayas ajustado el tamaño del lote para tu modelo de referencia, pero esta configuración puede fallar cuando los modelos más grandes se muestreen durante la búsqueda, lo que genera errores OOM. En este caso, debes reducir el tamaño del lote.
El otro tipo de error que aparece es el error NaN (no un número). Debes reducir la tasa de aprendizaje inicial o agregar recorte de gradientes.
Como se mencionó en instructivo-2, si más del 20% de tus modelos de espacio de búsqueda muestran puntuaciones no válidas, no ejecutarás la búsqueda completa. Nuestras herramientas de diseño de tareas de proxy proporcionan una forma de evaluar la tasa de fallas.
Herramientas de diseño de tareas de proxy
En las secciones anteriores, se analizan los principios del diseño de tareas de proxy. En esta sección, se proporcionan tres herramientas de diseño de tarea de proxy para encontrar de forma automática la tarea de proxy óptima en función de los diferentes enfoques de diseño y cuál reúnetodos los requisitos.
Cambios de código obligatorios
Primero debes modificar un poco el código del entrenador para que pueda interactuar con las herramientas de diseño de la tarea de proxy durante un proceso iterativo.
El tf_vision/train_lib.py muestra un ejemplo. Primero debes importar nuestra biblioteca:
from google.cloud.visionsolutions.nas.proxy_task import proxy_task_utils
Antes de que comience un ciclo de entrenamiento en tu bucle de entrenamiento, verifica si necesitas detener el entrenamiento antes de tiempo, ya que la herramienta de diseño de tareas de proxy quiere que uses nuestra biblioteca:
if proxy_task_utils.get_stop_training(
model_dir,
end_training_cycle_step=<last-training-step-idx done so far>,
total_training_steps=<total-training-steps>):
break
Una vez que se completa cada ciclo de entrenamiento en el bucle de entrenamiento, actualiza la puntuación de precisión nueva, el paso de inicio y finalización del ciclo de entrenamiento, el tiempo del ciclo de entrenamiento en segundos y los pasos de entrenamiento totales.
proxy_task_utils.update_trial_training_accuracy_metric(
model_dir=model_dir,
accuracy=<latest accuracy value>,
begin_training_cycle_step=<beginning training step for this cycle>,
end_training_cycle_step=<end training step for this cycle>,
training_cycle_time_in_secs=<training cycle time (excluding validation)>,
total_training_steps=<total-training-steps>)
Ten en cuenta que el tiempo del ciclo de entrenamiento no debe incluir tiempo para la evaluación de la puntuación de validación. Asegúrate de que el entrenador calcule las puntuaciones de validación con frecuencia (frecuencia de evaluación) para que tengas suficientes muestras de la curva de validación. Si usas la restricción de latencia, actualiza la métrica de latencia después de latencia de procesamiento:
proxy_task_utils.update_trial_training_latency_metric(
model_dir=model_dir,
latency=<measured_latency>)
La herramienta de selección de modelos requiere la carga de puntos de control anteriores para la iteración sucesiva.
Para habilitar la reutilización de un punto de control anterior, agrega una marca a tu entrenador como se muestra en tf_vision/cloud_search_main.py:
parser.add_argument(
"--retrain_use_search_job_checkpoint",
type=cloud_nas_utils.str_2_bool,
default=False,
help="True to use previous NAS search job checkpoint."
)
Carga este punto de control antes de entrenar tu modelo:
if FLAGS.retrain_use_search_job_checkpoint:
prev_checkpoint_dir = cloud_nas_utils.get_retrain_search_job_model_dir(
retrain_search_job_trials=FLAGS.retrain_search_job_trials,
retrain_search_job_dir=FLAGS.retrain_search_job_dir)
logging.info("Setting checkpoint to %s.", prev_checkpoint_dir)
# Now set your checkpoint using 'prev_checkpoint_dir'.
También necesitas el metric-id correspondiente a los valores de exactitud y latencia que informa tu entrenador. Si tu recompensa de entrenador (que a veces es una combinación de exactitud y latencia) es diferente de la exactitud, asegúrate de informar también la métrica de solo precisión mediante other_metrics de tu entrenador.
Por ejemplo, en el siguiente ejemplo, se muestran las métricas de solo precisión y latencia que informa nuestro entrenador compilado previamente:
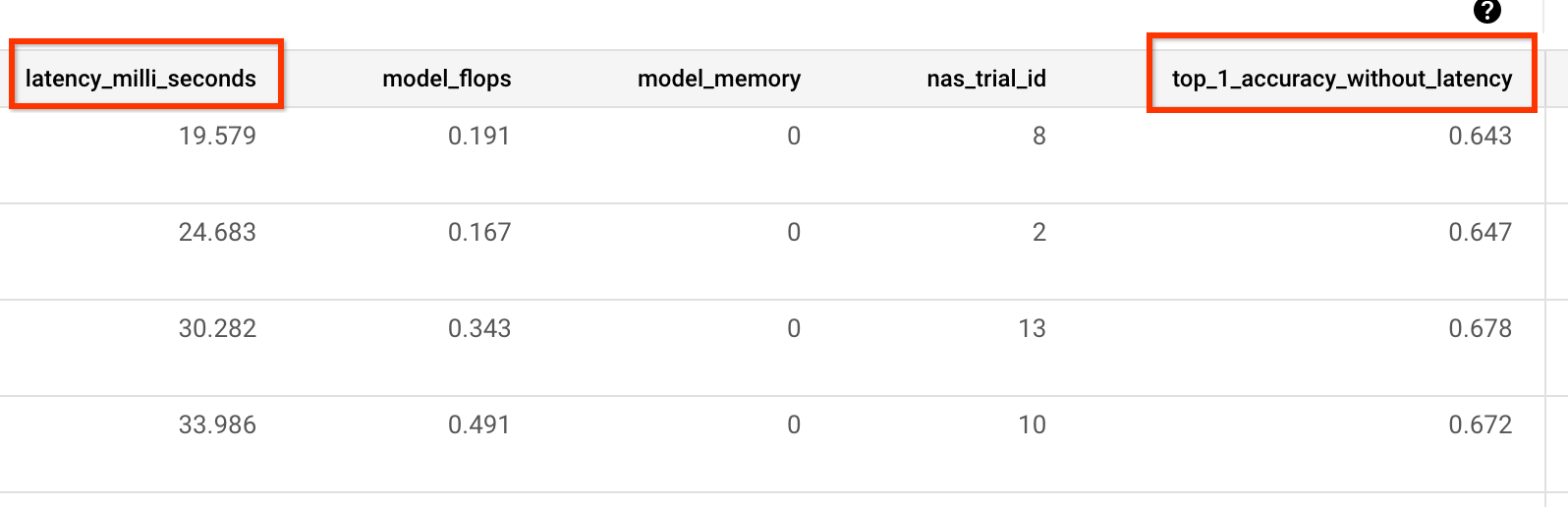
Medición de la varianza
Después de modificar tu código de entrenador, el primer paso es medir la varianza para tu entrenador. Para la medición de la varianza, modifica la configuración del entrenamiento de referencia de lo siguiente:
- Reducir los pasos de entrenamiento para que se ejecuten durante aproximadamente una hora con solo una o dos GPUs. Necesitamos una pequeña muestra del entrenamiento completo.
- Use la tasa de aprendizaje de disminución de coseno y establece sus pasos de la misma manera que estos pasos reducidos, de modo que la tasa de aprendizaje sea casi cero hacia el final.
La herramienta de medición de la varianza toma una muestra de un modelo del espacio de búsqueda y se asegura de que este modelo pueda comenzar a entrenar sin generar errores OOM o NAN, ejecuta cinco copias de este modelo con tu configuración durante aproximadamente una hora, e informa la varianza y la fluidez de la puntuación de entrenamiento. El costo total de ejecutar esta herramienta es aproximadamente el mismo que ejecutar cinco modelos con tu configuración durante aproximadamente una hora.
Inicia el trabajo de medición de la varianza con la ejecución del siguiente comando (necesitas una cuenta de servicio):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
####### Variance measurement related parameters ######
proxy_task_variance_measurement_docker_id=${USER}_variance_measurement_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id}
# The command below passes 'dummy' arguments for the training docker.
# You need to modify them for your own docker.
python3 vertex_nas_cli.py measure_proxy_task_variance \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id} \
--project_id=${project_id} \
--service_account=${service_account} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Una vez que inicies este trabajo de medición de la varianza, obtendrás un vínculo de trabajo. El nombre del trabajo debe comenzar con el prefijo Variance_Measurement. A continuación, se muestra un ejemplo de IU de trabajo:
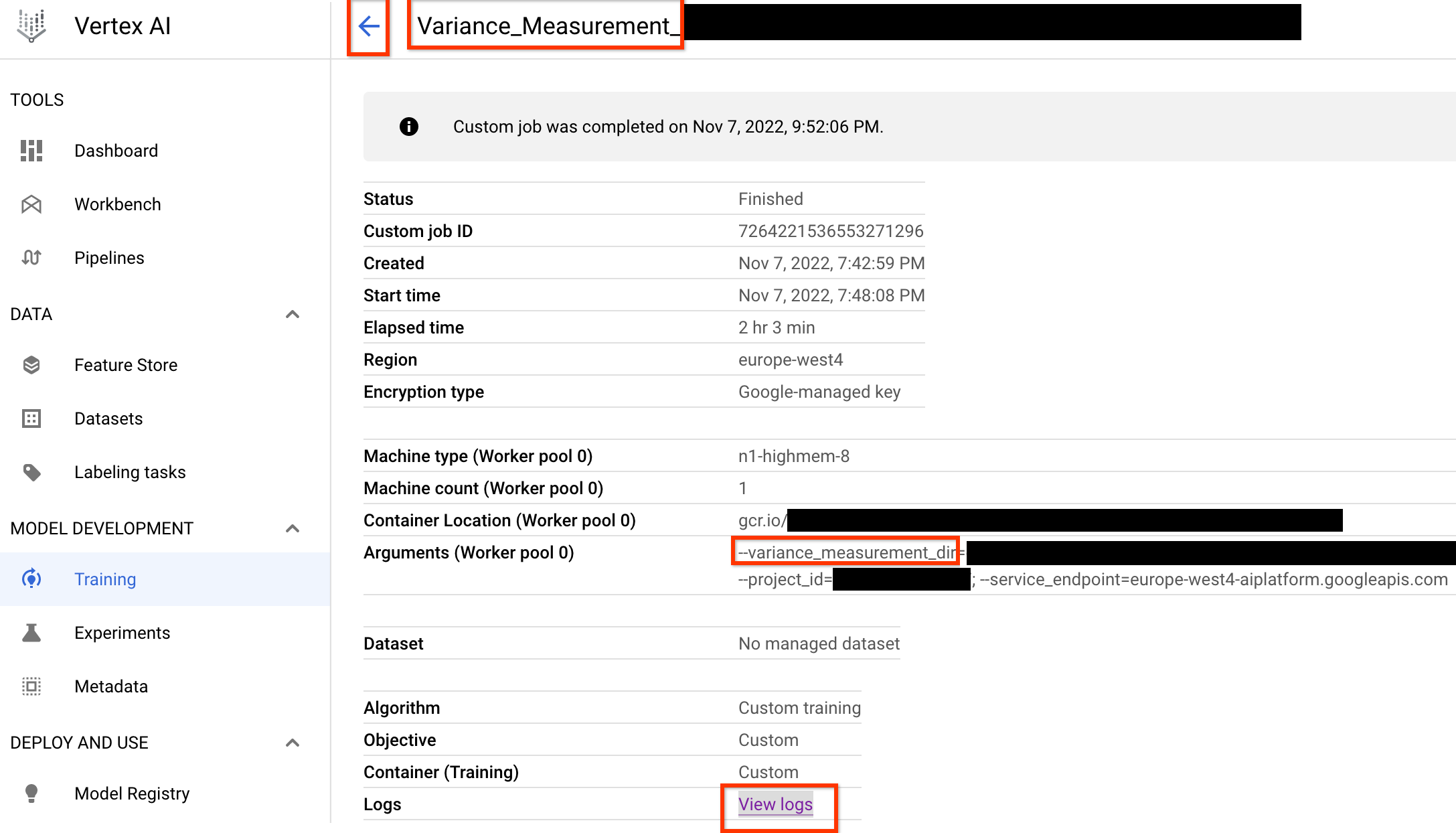
variance_measurement_dir contendrá todos los resultados y puedes verificar los registros si haces clic en el vínculo Ver registros.
De forma predeterminada, este trabajo usa una CPU en la nube para ejecutarse en segundo plano como un trabajo personalizado y, luego, inicia y administra los trabajos de NAS secundarios.
Bajo los trabajos NAS, verás un trabajo llamado Find_workable_model_<your job name>. Este trabajo hará un muestreo de tu espacio de búsqueda para encontrar un modelo, lo que no genera ningún error. Una vez que se encuentra este modelo, el trabajo de medición de la varianza inicia otro trabajo NAS <your job name>, que ejecuta cinco copias de este modelo para la cantidad de pasos de entrenamiento que configuraste antes. Una vez que finaliza el entrenamiento de estos modelos, el trabajo de medición de la varianza mide su varianza y fluidez en las puntuaciones, y las informa en sus registros:
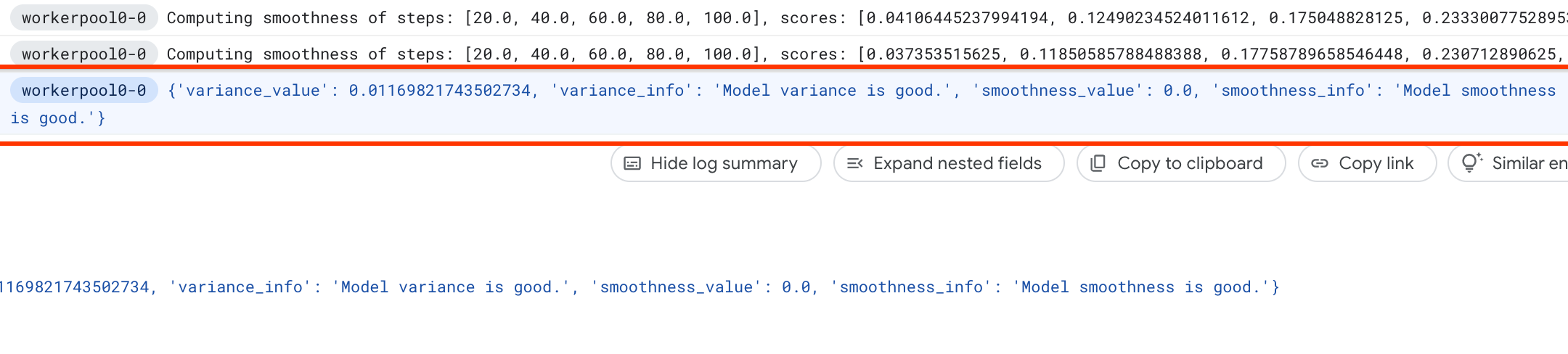
Si la varianza es alta, puedes explorar las técnicas que se enumeran aquí.
Selección del modelo
Una vez que hayas verificado que tu entrenador no tiene una varianza alta, los siguientes pasos son los siguientes:
- encontrar alrededor de 10 modelos-candidatos-correlación
- calcula sus puntuaciones de entrenamiento completas, que actuarán como referencia cuando calcules las puntuaciones de correlación de la tarea de proxy para diferentes opciones de tareas de proxy más adelante.
Nuestra herramienta de forma automática y eficiente encuentra estos modelos candidatos para la correlación y garantiza que tengan una buena distribución de puntuación tanto para la exactitud como para la latencia a fin de que el cálculo de la correlación futura tenga una buena base. Para esto, la herramienta hace lo siguiente:
- Muestra de manera aleatoria de modelos
N_beginde tu espacio de búsqueda. Para este ejemplo, supongamos que esN_begin = 30. La herramienta los entrena durante un 1/30 de tiempo completo de entrenamiento. - Rechazar cinco de 30 modelos, que no suman más a la distribución de precisión y latencia. En la siguiente figura, se muestra esto como ejemplo. Los modelos rechazados se muestran como puntos rojos:
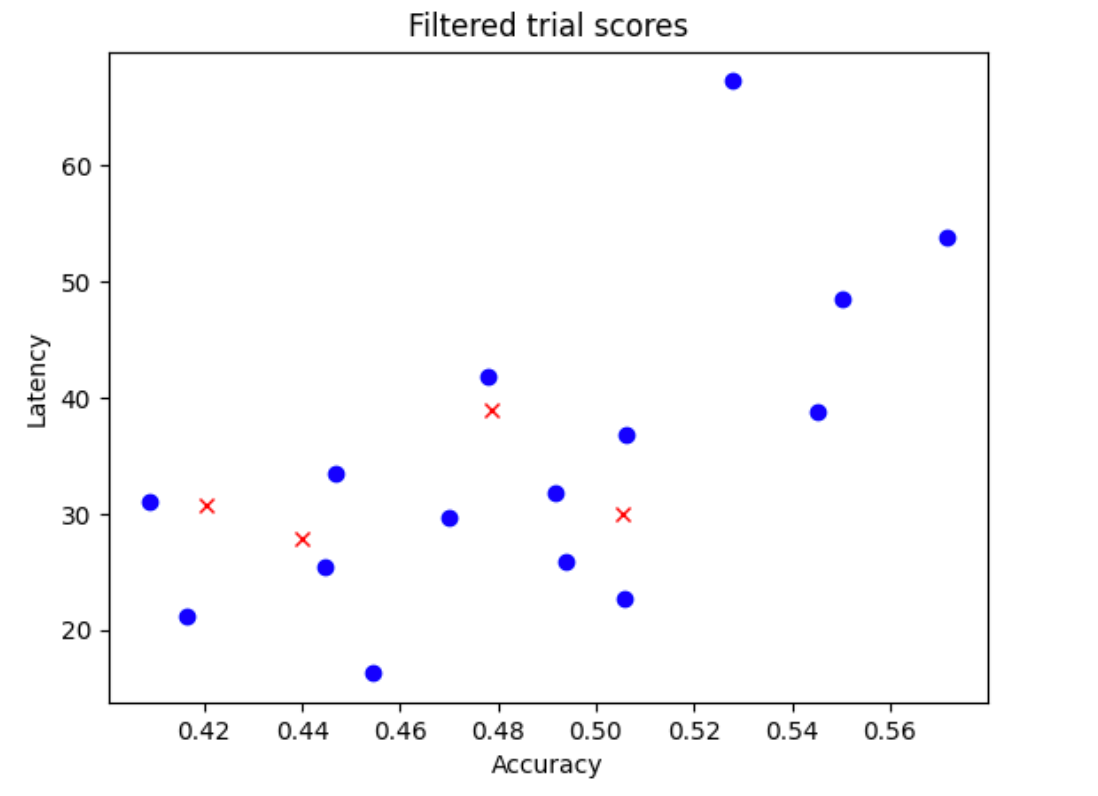
- Entrena los 25 modelos seleccionados para 1/25 de tiempo completo de entrenamiento y, luego, rechaza cinco modelos más según las puntuaciones hasta ahora. Ten en cuenta que el entrenamiento de los 25 modelos se continúa desde su punto de control anterior.
- Repite este proceso hasta que solo queden modelos
Ncon una buena distribución. - Entrena estos últimos modelos
Nhasta su finalización.
La configuración predeterminada para N_begin es 30 y se puede encontrar como START_NUM_MODELS en el archivo proxy_task/proxy_task_model_selection_lib_constants.py.
La configuración predeterminada para N es 10 y se puede encontrar como FINAL_NUM_MODELS en el archivo proxy_task/proxy_task_model_selection_lib_constants.py.
El costo adicional de este proceso de selección de modelos se calcula de la siguiente manera:
= (30*1/30 + 25*1/25 + 20*1/20 + 15*1/15 + 10*(remaining-training-time-fraction)) * full-training-time
= (4 + 10*(0.81)) * full-training-time
~= 12 * full-training-time
Sin embargo, permanece por encima de la configuración de N=10. La herramienta de búsqueda de tarea de proxy más adelante ejecuta estos modelos N en paralelo. Por lo tanto, asegúrate de tener suficiente cuota de GPU para esto. Por ejemplo, si tu tarea de proxy usa dos GPU para un modelo, debes tener una cuota de al menos 2*N GPU.
Para el trabajo de selección de modelos, usa la misma partición de conjunto de datos que el trabajo de entrenamiento completo de etapa 2 y usa la misma configuración de entrenador para tu entrenamiento completo de referencia.
Ahora estás listo para iniciar el trabajo de selección de modelos mediante la ejecución del siguiente comando (necesitas una cuenta de servicio):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task model-selection related parameters ######
proxy_task_model_selection_docker_id=${USER}_model_selection_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
# The value below depends on your accelerator quota. By default
# the model-selection job runs 30 trials. However, depending on
# your quota, you can choose to only run 10 trials in parallel at a time.
# However, lowering this number can increase the overall runtime for the job.
max_parallel_nas_trial=<num parallel trials>
# The value below is the 'metric-id' corresponding to the accuracy ONLY
# metric reported by your trainer. Note that this metric may
# be different from the 'reward'.
accuracy_metric_id=<set accuracy metric id used by your trainer>
latency_metric_id=<set latency metric id used by your trainer>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py select_proxy_task_models \
--service_account=${service_account} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--max_parallel_nas_trial=${max_parallel_nas_trial} \
--accuracy_metric_id=${accuracy_metric_id} \
--latency_metric_id=${latency_metric_id} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Una vez que inicies este trabajo del controlador de selección de modelos, se recibirá un vínculo de trabajo. El nombre del trabajo comienza con el prefijo Model_Selection_. A continuación, se muestra un ejemplo de IU de trabajo:
model_selection_dir contiene todas las salidas. Haz clic en el vínculo View logs para verificar los registros.
De forma predeterminada, este trabajo del controlador de selección de modelos usa una CPU en Google Cloud para ejecutarse en segundo plano como un trabajo personalizado y, luego, inicia y administra los trabajos NAS secundarios para cada iteración de la selección del modelo.
Cada trabajo NAS secundario tiene un nombre como <your_job_name>_iter_3 (excepto la iteración 0). Solo se ejecuta una iteración a la vez. En cada iteración, la cantidad de modelos (cantidad de pruebas) y aumenta la duración del entrenamiento. Al final de cada iteración, cada trabajo de NAS guarda el archivo gs://<job-output-dir>/search/filtered_trial_scores.png, que muestra de forma visual qué modelos se rechazaron en esta iteración.
También puedes ejecutar el siguiente comando:
gcloud storage cat gs://<path to 'model_selection_dir'>/MODEL_SELECTION_STATE.json
que te muestra un resumen de las iteraciones y el estado actual del trabajo del controlador de selección de modelos, el nombre del trabajo y los vínculos para cada iteración:
{
"start_num_models": 30,
"final_num_models": 10,
"num_models_to_remove_per_iter": 5,
"accuracy_metric_id": "top_1_accuracy_without_latency",
"latency_metric_id": "latency_milli_seconds",
"iterations": [
{
"num_trials": 30,
"trials_to_retrain": [
"27",
"16",
...,
"14"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2111217356469436416",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2111217356469436416/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/6909239809479278592",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/6909239809479278592/cpu?project=my-project",
"desired_training_step_pct": 2.0
},
...,
{
"num_trials": 15,
"trials_to_retrain": [
"14",
...,
"5"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/7045544066951413760",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/7045544066951413760/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/2790768318993137664",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2790768318993137664/cpu?project=my-project",
"desired_training_step_pct": 28.57936507936508
},
{
"num_trials": 10,
"trials_to_retrain": [],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2742864796394192896",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2742864796394192896/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/1490864099985195008",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/1490864099985195008/cpu?project=my-project",
"desired_training_step_pct": 101.0
}
]
}
La última iteración tiene la cantidad final de modelos de referencia con una buena distribución de puntuaciones. Estos modelos y sus puntuaciones se usan para la búsqueda de tarea de proxy en el siguiente paso. Si el rango de puntuación de latencia y precisión final para los modelos de referencia parece mejor o cercano a tu modelo de referencia existente, lo que proporciona una buena indicación temprana sobre tu espacio de búsqueda. Si el rango de puntuación de latencia y exactitud final es mucho peor que el modelo de referencia, revisa tu espacio de búsqueda.
Ten en cuenta que si falla más del 20% de tus pruebas en la primera iteración, cancela tu trabajo de selección de modelos y, luego, identifica la causa raíz de las fallas. Puede tratarse de un problema con tu espacio de búsqueda o la configuración del tamaño del lote y la tasa de aprendizaje.
Usar un dispositivo de latencia local para la selección del modelo
Si quieres usar un dispositivo de latencia local para la selección del modelo, ejecuta el comando select_proxy_task_models sin el Docker de latencia y las marcas de latencia de Docker, ya que no quieres iniciar el Docker de latencia en Google Cloud. Luego, usa el comando run_latency_calculator_local que se describe en el Instructivo 4 para iniciar el trabajo de la calculadora de latencia local. En lugar de pasar la marca --search_job_id, pasa la marca --controller_job_id con el ID de trabajo numérico de selección de modelos que obtienes después de ejecutar el comando select_proxy_task_models.
Reanuda el trabajo del controlador de selección de modelos
En las siguientes situaciones, se requiere que reanudes el trabajo del controlador de selección de modelos:
- El trabajo del controlador de selección de modelos superiores se cierra (casos poco frecuentes).
- Cancelas por accidente el trabajo del controlador de selección de modelos.
Primero, no canceles el trabajo de iteración NAS secundario (pestaña NAS) si ya se está ejecutando. Luego, para reanudar el trabajo del controlador de selección de modelos superiores, ejecuta el comando select_proxy_task_models como antes, pero esta vez pasa la marca --previous_model_selection_dir y establécela en el directorio de salida para el trabajo de controlador de selección de modelo anterior. El trabajo del controlador de selección de modelos reanudado carga su estado anterior desde el directorio y continúa funcionando como antes.
Búsqueda de tarea de proxy
Después de encontrar los modelos candidatos y sus puntuaciones de entrenamiento completo, el siguiente paso es usarlos para evaluar las puntuaciones de correlación en las diferentes opciones de tarea de proxy y elegir la tarea de proxy óptima. Nuestra herramienta de búsqueda de tareas de proxy puede encontrar automáticamente una tarea de proxy, que ofrece lo siguiente:
- El costo de búsqueda de NAS más bajo.
- Cumple con un umbral mínimo de requisitos de correlación después de proporcionarle una definición de espacio de búsqueda de tarea de proxy.
Recuperación, hay tres dimensiones comunes para buscar una tarea de proxy óptima, que incluyen lo siguiente:
- Cantidad reducida de pasos de entrenamiento.
- Cantidad reducida de datos de entrenamiento.
- Escalamiento reducido del modelo.
Puedes crear un espacio de búsqueda de tarea de proxy discreto si muestras estas dimensiones como se muestra a continuación:
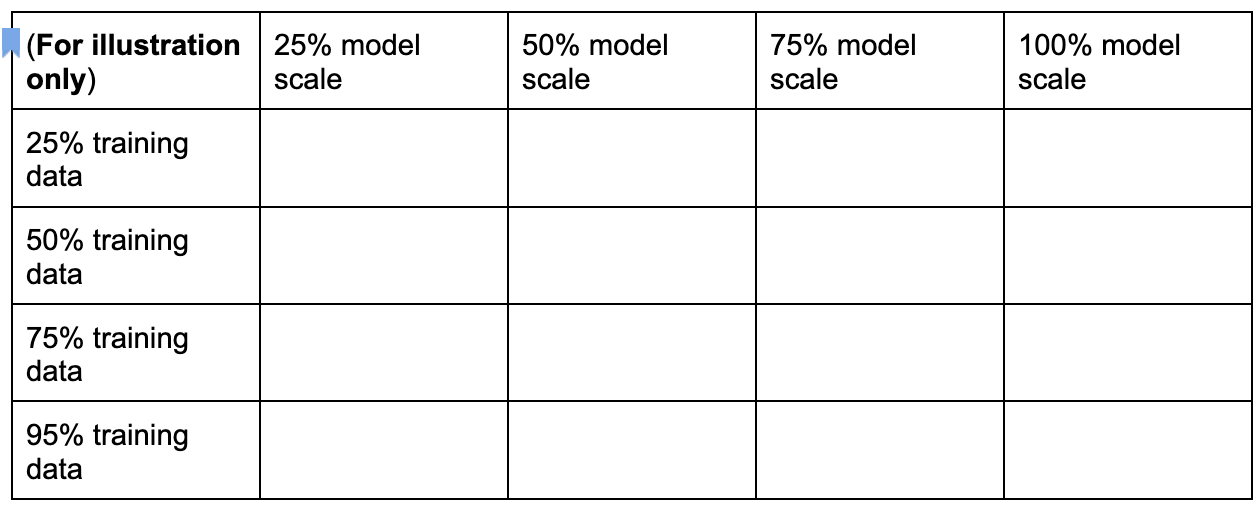
Los números de porcentaje anteriores solo se establecen como una sugerencia aproximada y un ejemplo. En la práctica, puedes elegir cualquier opción discreta.
Ten en cuenta que no incluimos la dimensión de pasos de entrenamiento en el espacio de búsqueda anterior. Esto se debe a que la herramienta de búsqueda de tarea de proxy determina el paso de entrenamiento óptimo según una elección de tarea de proxy.
Considera una elección de tarea de proxy de [50% training data, 25% model scale]. Establece la cantidad de pasos de entrenamiento en la misma cantidad que para el entrenamiento del modelo de referencia completo.
Cuando se evalúa esta tarea de proxy, la herramienta de búsqueda de tareas del proxy inicia el entrenamiento de los modelos de correlación de candidatos, supervisa sus puntuaciones de precisión actuales y calcula de forma continua la puntuación de correlación de clasificación (usando las puntuaciones de entrenamiento completas pasadas para los modelos de referencia):

Por lo tanto, la herramienta de búsqueda de tarea de proxy puede detener el entrenamiento de tarea de proxy una vez que se obtiene la correlación deseada (como 0.65), o también se puede detener de forma anticipada si se supera la cuota de costo de búsqueda (como el límite de 3 horas por tarea de proxy). Por lo tanto, no necesitas buscar de forma explícita en los pasos de entrenamiento. La herramienta de búsqueda de tareas del proxy evalúa cada tarea de proxy de tu espacio de búsqueda discreto como una búsqueda de cuadrícula y te proporciona la mejor opción.
Lo que sigue es un ejemplo de definición de espacio de búsqueda de tarea de proxy MnasNet mnasnet_proxy_task_config_generator, definido en el archivo proxy_task/proxy_task_search_spaces.py, para demostrar cómo puedes definir tu propio espacio de búsqueda:
# MNasnet training-data size choices.
MNASNET_TRAINING_DATA_PCT_LIST = [25, 50, 75, 95]
# Training data path regex pattern.
_TRAINING_DATA_PATH_REGEX = r"gs://.*/.*"
def update_mnasnet_proxy_training_data(
baseline_docker_args_map: Dict[str, Any],
training_data_pct: int) -> Optional[Dict[str, Any]]:
"""Updates MNasnet baseline docker to use a certain training_data_pct."""
proxy_task_docker_args_map = copy.deepcopy(baseline_docker_args_map)
# Imagenet training data path looks like:
# gs://<path to imagenet data>/train-00[0-7]??-of-01024.
if not re.match(_TRAINING_DATA_PATH_REGEX,
baseline_docker_args_map["training_data_path"]):
raise ValueError(
"Training data path %s does not match the desired pattern." %
baseline_docker_args_map["training_data_path"])
root_path, _ = baseline_docker_args_map["training_data_path"].rsplit("/", 1)
if training_data_% == 25:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-1][0-4]?-of-01024*")
elif training_data_% == 50:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-4]??-of-01024*")
elif training_data_% == 75:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-6][0-4]?-of-01024*")
elif training_data_% == 95:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-8][0-4]?-of-01024*")
else:
logging.warning("Mnasnet training_data_% %d is not supported.",
training_data_pct)
return None
proxy_task_docker_args_map["validation_data_path"] = os.path.join(
root_path, "train-009[0-4]?-of-01024")
return proxy_task_docker_args_map
def mnasnet_proxy_task_config_generator(
baseline_docker_args_map: Dict[str, Any]
) -> List[proxy_task_utils.ProxyTaskConfig]:
"""Returns a list of proxy-task configs to be evaluated for MNasnet.
Args:
baseline_docker_args_map: A set of baseline training-docker arguments in
the form of a dictionary of {'key', val}. The different proxy-task
configs to try can be built by modifying this baseline.
Returns:
A list of proxy-task configs to be evaluated for this
proxy-task search space.
"""
proxy_task_config_list = []
# NOTE: Will not search over model-scale for MNasnet.
for training_data_% in MNASNET_TRAINING_DATA_PCT_LIST:
proxy_task_docker_args_map = update_mnasnet_proxy_training_data(
baseline_docker_args_map=baseline_docker_args_map,
training_data_pct=training_data_pct)
if not proxy_task_docker_args_map:
continue
proxy_task_name = "mnasnet_proxy_training_data_pct_{}".format(
training_data_pct)
proxy_task_config_list.append(
proxy_task_utils.ProxyTaskConfig(
name=proxy_task_name, docker_args_map=proxy_task_docker_args_map))
return proxy_task_config_list
En este ejemplo, creamos un espacio de búsqueda simple sobre el porcentaje de datos de entrenamiento 25, 50, 75 y 95 (ten en cuenta que el 100% de los datos de entrenamiento sonno se usa para la búsqueda de etapa 1).
La función mnasnet_proxy_task_config_generator toma una plantilla de referencia común de los argumentos de Docker de entrenamiento y, luego, los modifica para cada tamaño de datos de entrenamiento de tarea de proxy deseado. Luego, muestra una lista de configuración de tarea de proxy que la herramienta de búsqueda de tarea de proxy procesa más tarde una por una en el mismo orden. Cada archivo de configuración de tarea de proxy tiene name y docker_args_map, que es un mapa clave-valor para los argumentos de Docker de tarea de proxy.
Puedes implementar tu propia definición de espacio de búsqueda según tus propios requisitos y diseñar tus propios espacios de búsqueda de tareas de proxy, incluso para más de las dos dimensiones de datos de entrenamiento reducidos o escala de modelo reducida. Sin embargo, no se recomienda buscar de forma explícita en los pasos de entrenamiento, ya que implica un procesamiento repetido desperdiciado. Permite que la herramienta de búsqueda de tarea de proxy controle esta dimensión por ti.
Para tu primera búsqueda de tareas de proxy, puedes intentar reducir solo los datos de entrenamiento (al igual que el ejemplo MnasNet) y omite la reducción de escala del modelo porque el escalamiento del modelo puede incluir varios parámetros en lugar de image-size, num-filters onum-blocks.
En la mayoría de los casos, los datos de entrenamiento reducidos (y la búsqueda implícita en los pasos de entrenamiento reducidos) son suficientes para encontrar una buena tarea de proxy.
Establece la cantidad de pasos de entrenamiento en el número que se usa en el entrenamiento de modelo de referencia completo.
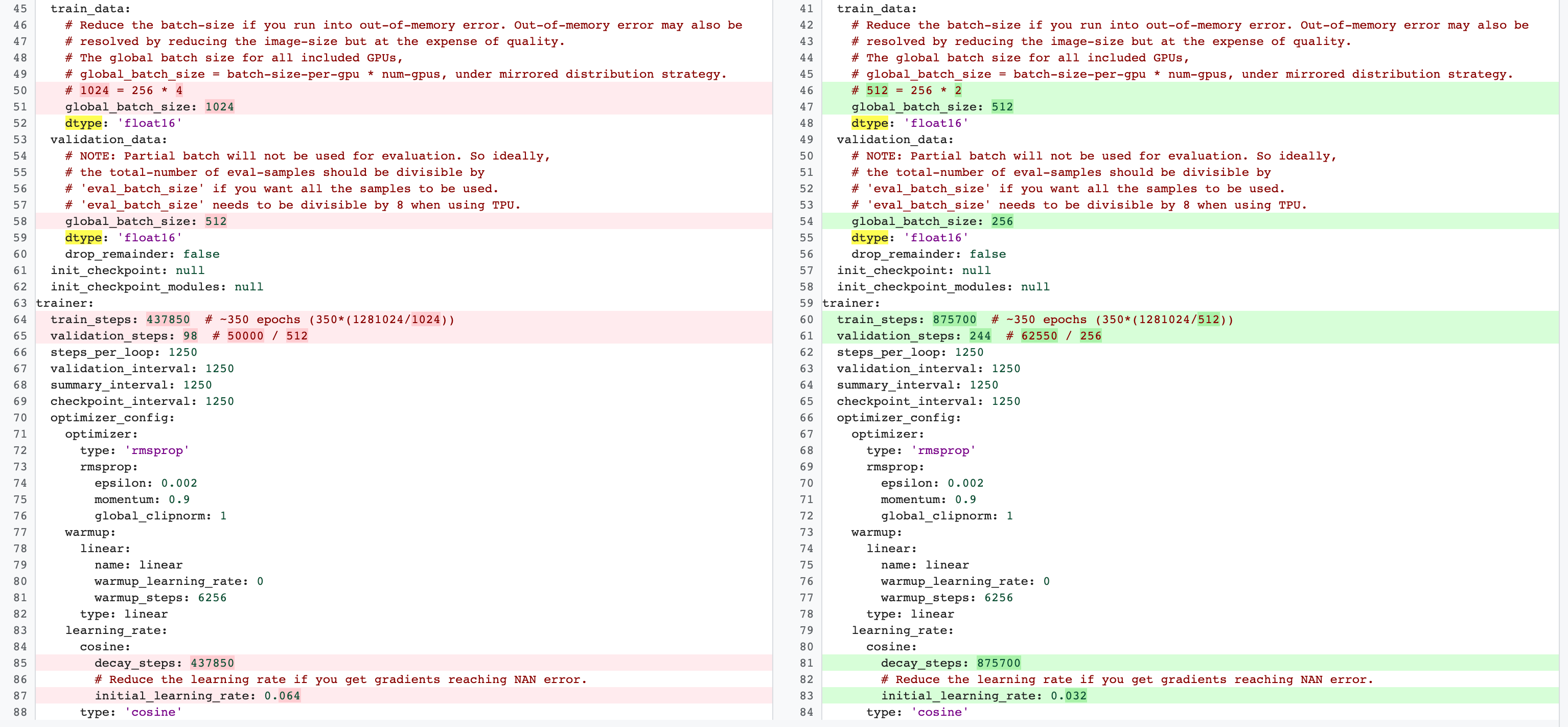
Existen diferencias entre las configuraciones de entrenamiento completo de etapa 2 y de entrenamiento de tarea de proxy de etapa 1. Para la tarea del proxy, debes reducir el batch-size en comparación con la configuración de entrenamiento del modelo de referencia completo para usar solo 2 GPUs o 4 GPUs.
Por lo general, el entrenamiento completo usa 4 GPUs, 8 GPUs o más, pero la tarea de proxy solo usa 2 GPUs o 4 GPUs.
Otra diferencia es la división del entrenamiento y la validación.
Este es un ejemplo de los cambios de la configuración de MnasNet que van de 4 GPUs para el entrenamiento completo de etapa 2 a 2 GPUs y una división de validación diferente para la búsqueda de tareas de proxy:
Inicia el trabajo del controlador de búsqueda de tarea de proxy mediante la ejecución del siguiente comando (necesitas una cuenta de servicio):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your NAS job search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task search related parameters ######
proxy_task_search_controller_docker_id=${USER}_proxy_task_search_${DATE}
job_name=<your job name>
# Path to your proxy task search space definition. For ex:
# 'proxy_task.proxy_task_search_spaces.mnasnet_proxy_task_config_generator'
proxy_task_config_generator_module=<path to your proxy task config generator module>
# The previous model-slection job provides the candidate-correlation-models
# and their scores.
proxy_task_model_selection_job_id=<Numeric job id of your previous model-selection>
# During proxy-task search, the proxy-task training is stopped
# when the following correlation score is achieved.
desired_accuracy_correlation=0.65
# During proxy-task search, the proxy-task training is stopped
# if the runtime exceeds this limit: 4 hrs.
training_time_hrs_limit=4
# The proxy-task is marked a good candidate only if the latency
# correlation is also above the required threshold.
# Note: This won't be used if you do not have a latency job.
desired_latency_correlation=0.65
# Early stop a proxy-task evaluation if you already have a better candidate.
# If False, evaluate all proxy-taask candidates.
early_stop_proxy_task_if_not_best=False
# Use the service account that you set-up for your project.
service_account=<your service account>
###################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py search_proxy_task \
--service_account=${service_account} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id} \
--proxy_task_config_generator_module=${proxy_task_config_generator_module} \
--proxy_task_model_selection_job_id=${proxy_task_model_selection_job_id} \
--proxy_task_model_selection_job_region=${region} \
--desired_accuracy_correlation={$desired_accuracy_correlation}\
--training_time_hrs_limit=${training_time_hrs_limit} \
--desired_latency_correlation=${desired_latency_correlation} \
--early_stop_proxy_task_if_not_best=${early_stop_proxy_task_if_not_best} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Después de iniciar este trabajo del controlador de búsqueda de tarea de proxy, se recibe un vínculo de trabajo. El nombre del trabajo comienza con el prefijo Search_controller_. A continuación, se muestra un ejemplo de IU de trabajo:
search_controller_dir contendrá todos los resultados y puedes verificar los registros si haces clic en el vínculo View logs.
De forma predeterminada, este trabajo usa una CPU en la nube para ejecutarse en segundo plano como un trabajo personalizado y, luego, inicia y administra los trabajos de NAS secundarios para cada evaluación de tarea de proxy.
Cada trabajo de NAS de tarea de proxy tiene un nombre como ProxyTask_<your-job-name>_<proxy-task-name>, en el que <proxy-task-name> es lo que proporciona el módulo del generador de configuración de tarea de proxy para cada tarea de proxy. Solo se ejecuta una evaluación de tarea de proxy a la vez.
También puedes ejecutar el siguiente comando:
gcloud storage cat gs://<path to 'search_controller_dir'>/SEARCH_CONTROLLER_STATE.json
Este comando muestra un resumen de todas las evaluaciones de tarea de proxy y el estado actual del trabajo de controlador de búsqueda, el nombre del trabajo y los vínculos para cada evaluación:
{
"proxy_tasks_map": {
"mnasnet_proxy_training_data_pct_25": {
"proxy_task_stats": {
"training_steps": [
1249,
2499,
...,
18749
],
"accuracy_correlation_over_step": [
-0.06666666666666667,
-0.6,
...,
0.7857142857142856
],
"accuracy_correlation_p_value_over_step": [
0.8618005952380953,
0.016666115520282188,
...,
0.005505952380952381
],
"median_accuracy_over_step": [
0.011478611268103123,
0.04956454783678055,
...,
0.32932570576667786
],
"median_training_time_hrs_over_step": [
0.11611097933475001,
0.22913257125276987,
...,
1.6682701704073444
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.6675102778428197,
"final_training_steps": 18512
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_25",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/4173661476642357248",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/4173661476642357248/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/8785347495069745152",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/8785347495069745152/cpu?project=my-project"
},
...,
"mnasnet_proxy_training_data_pct_95": {
"proxy_task_stats": {
"training_steps": [
1249,
...,
18749
],
"accuracy_correlation_over_step": [
-0.3333333333333333,
...,
0.7857142857142856,
-5.0
],
"accuracy_correlation_p_value_over_step": [
0.21637345679012346,
...,
0.005505952380952381,
-5.0
],
"median_accuracy_over_step": [
0.01120645459741354,
...,
0.38238024711608887,
-1.0
],
"median_training_time_hrs_over_step": [
0.11385884770307843,
...,
1.5466042930547819,
-1.0
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.533235285929564,
"final_training_steps": 17108
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_95",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2341822328209408000",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2341822328209408000/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/7575005095213924352",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/7575005095213924352/cpu?project=my-project"
}
},
"best_proxy_task_name": "mnasnet_proxy_training_data_pct_75"
}
El proxy_tasks_map almacena el resultado de cada evaluación de tarea de proxy y best_proxy_task_name registra la mejor tarea de proxy para la búsqueda. Cada entrada de tarea de proxy tiene datos adicionales, como proxy_task_stats, que registra el progreso de la correlación de precisión, sus valores de p, la precisión de la mediana y el tiempo de entrenamiento medio en los pasos de entrenamiento. También registra la correlación relacionada con la latencia, si corresponde, y registra el motivo de la detención de este trabajo (como el límite de tiempo de entrenamiento excedido) y el paso de entrenamiento en el que se detiene. También puedes ver estas estadísticas como trazados si copias el contenido de search_controller_dir en tu carpeta local mediante la ejecución del siguiente comando:
gcloud storage cp gs://<path to 'search_controller_dir'>/* /your/local/dir
e inspeccionar las imágenes de trazado. Por ejemplo, en el siguiente gráfico, se muestra la correlación de precisión con el tiempo de entrenamiento para la mejor tarea de proxy:

Tu búsqueda se completó y encontraste la mejor configuración de tarea de proxy. Debes hacer lo siguiente:
- Establece la cantidad de pasos de entrenamiento en
final_training_stepsde la tarea del proxy ganadora. - Establece los pasos de disminución de coseno de la misma manera que
final_training_steps, de modo que la tasa de aprendizaje casi sea cero hacia el final. - [Opcional] Realiza una evaluación de puntuación de validación al final del entrenamiento, lo que ahorra varios costos de evaluación.
Usa un dispositivo de latencia local para la búsqueda de tareas de proxy
Si quieres usar un dispositivo de latencia local para la búsqueda de tareas de proxy, ejecuta el comando search_proxy_task sin el Docker de latencia y las marcas de latencia de Docker, ya que no quieres iniciar el Docker de latencia en Google Cloud. Luego, usa el comando run_latency_calculator_local que se describe en el Instructivo 4 para iniciar el trabajo de la calculadora de latencia local. En lugar de pasar la marca --search_job_id, pasa la marca --controller_job_id con el ID de trabajo numérico de búsqueda de tarea de proxy que obtienes después de ejecutar el comando search_proxy_task.
Reanuda el trabajo del controlador de búsqueda de la tarea de proxy
En las siguientes situaciones, se requiere que reanudes el trabajo del controlador de búsqueda de la tarea de proxy:
- El trabajo de controlador de búsqueda de tarea de proxy superior se cierra (casos poco frecuentes).
- Cancelas por accidente el trabajo del controlador de búsqueda de la tarea de proxy.
- Quieres ampliar tu espacio de búsqueda de la tarea de proxy más tarde (incluso después de muchos días).
Primero, no canceles el trabajo de iteración NAS secundario (pestaña NAS) si ya se está ejecutando. Luego, para reanudar el trabajo del controlador de búsqueda de la tarea de proxy superior, ejecuta el comando search_proxy_task como antes, pero esta vez pasa la marca --previous_proxy_task_search_dir y configúrala en el directorio de salida para el trabajo anterior del controlador de búsqueda de tarea de proxy. El trabajo del controlador de búsqueda de la tarea de proxy reanudado carga su estado anterior desde el directorio y continúa funcionando como antes.
Comprobaciones finales
Dos verificaciones finales para la tarea de proxy incluyen un rango de recompensas y guardar datos para el análisis posterior a la búsqueda.
Rango de recompensas
La recompensa que se informa al controlador debe estar dentro del rango [1e-3, 10]. Si este no es el caso, puedes escalar artificialmente la recompensa para lograr este objetivo.
Guarda los datos para realizar análisis posteriores a la búsqueda
El código de la tarea de proxy debe guardar las métricas y los datos adicionales en la ubicación de Cloud Storage, lo que podría ser útil para analizar el espacio de búsqueda más adelante. Nuestra plataforma de búsqueda de arquitectura neuronal solo admite el registro de un máximo de cinco other_metrics de punto flotante.
Cualquier métrica adicional debe guardarse en la ubicación de Cloud Storage para realizar análisis posteriores.