Antes de ejecutar un trabajo de Neural Architecture Search para buscar un modelo óptimo, define tu tarea proxy. Stage1-search usa una representación mucho más pequeña de un entrenamiento de modelo completo que suele completarse en dos horas. Esta representación se denomina tarea proxy y reduce significativamente el coste de búsqueda. Cada prueba durante la búsqueda entrena un modelo con los ajustes de la tarea proxy.
En las siguientes secciones se describe lo que implica aplicar el diseño de tareas proxy:
- Métodos para crear una tarea de proxy.
- Requisitos de una buena tarea proxy.
- Cómo usar las tres herramientas de diseño de tareas proxy para encontrar la tarea proxy óptima, que reduce el coste de búsqueda y mantiene la calidad de la búsqueda.
Métodos para crear una tarea proxy
Hay tres enfoques habituales para crear una tarea proxy, que incluyen los siguientes:
- Usa menos pasos de entrenamiento.
- Usa un conjunto de datos de entrenamiento submuestreado.
- Usa un modelo reducido.
Usar menos pasos de entrenamiento
La forma más sencilla de crear una tarea proxy es reducir el número de pasos de entrenamiento de tu entrenador y enviar una puntuación al controlador basada en este entrenamiento parcial.
Usar un conjunto de datos de entrenamiento submuestreado
En esta sección se describe el uso de un conjunto de datos de entrenamiento submuestreado para buscar tanto una arquitectura como una política de aumento.
Búsqueda de arquitectura
Se puede crear una tarea proxy usando un conjunto de datos de entrenamiento submuestreado durante la búsqueda de la arquitectura. Sin embargo, cuando se aplique un submuestreo, sigue estas directrices:
- Mezcla los datos de forma aleatoria entre los fragmentos.
- Si los datos de entrenamiento no están equilibrados, haz un muestreo para equilibrarlos.
Búsqueda de políticas de aumento mediante el aumento automático
Omite esta sección si no estás realizando una búsqueda de aumento únicamente y solo estás realizando la búsqueda de arquitectura normal. Usa auto-augment para buscar la política de aumento. Es preferible submuestrear los datos de entrenamiento y ejecutar un entrenamiento completo que reducir el número de pasos de entrenamiento. Si ejecutas el entrenamiento completo con un aumento considerable, las puntuaciones serán más estables. Además, usa los datos de entrenamiento reducidos para mantener el coste de búsqueda más bajo.
Tarea proxy basada en un modelo reducido
También puedes reducir el tamaño del modelo en relación con el modelo de referencia para crear una tarea proxy. También puede ser útil cuando quieras separar la búsqueda de diseño de bloques de la búsqueda de escalado.
Sin embargo, cuando reduces el tamaño del modelo y quieres usar una restricción de latencia, utiliza una restricción de latencia más estricta para el modelo reducido. Nota: Puedes reducir el modelo de referencia y medir su latencia para definir esta restricción de latencia más estricta.
En el caso del modelo reducido, también puedes disminuir la cantidad de aumento y regularización en comparación con el modelo de referencia original.
Ejemplos de un modelo reducido
En las tareas de visión artificial en las que se entrena con imágenes, hay tres formas habituales de reducir el tamaño de un modelo:
- Reducción de la anchura del modelo: número de canales.
- Reducción de la profundidad del modelo: número de capas y repeticiones de bloques.
- Reducir ligeramente el tamaño de las imágenes de entrenamiento (para que no se eliminen las características) o recortar las imágenes de entrenamiento si tu tarea lo permite.
Lectura recomendada: el artículo sobre EfficientNet proporciona información valiosa sobre el escalado de modelos para tareas de visión artificial. También se explica cómo se relacionan entre sí las tres formas de escalado.
La búsqueda de Spinenet es otro ejemplo de escalado de modelos que se usa con Neural Architecture Search. En la búsqueda de la fase 1, se reduce el número de canales y el tamaño de la imagen.
Tarea de proxy basada en una combinación
Los enfoques funcionan de forma independiente y se pueden combinar en diferentes grados para crear una tarea proxy.
Requisitos de una buena tarea de proxy
Una tarea proxy debe cumplir ciertos requisitos para poder ofrecer una recompensa estable al controlador y mantener la calidad de la búsqueda.
Correlación de rangos entre la búsqueda de la fase 1 y el entrenamiento completo de la fase 2
Cuando se usa una tarea proxy para la búsqueda de arquitectura neuronal, una suposición clave para que la búsqueda sea correcta es que, si el modelo A tiene un mejor rendimiento que el modelo B durante la fase 1 del entrenamiento de la tarea proxy, el modelo A tendrá un mejor rendimiento que el modelo B en la fase 2 del entrenamiento completo. Para validar esta suposición, debes evaluar la correlación de rango entre las recompensas de la búsqueda de la fase 1 y del entrenamiento completo de la fase 2 en entre 10 y 20 modelos de tu espacio de búsqueda. Estos modelos se denominan modelos de candidatos a correlación.
En la siguiente figura se muestra un ejemplo de una correlación deficiente (puntuación de correlación = -0,03), lo que hace que esta tarea proxy no sea una buena candidata para una búsqueda:
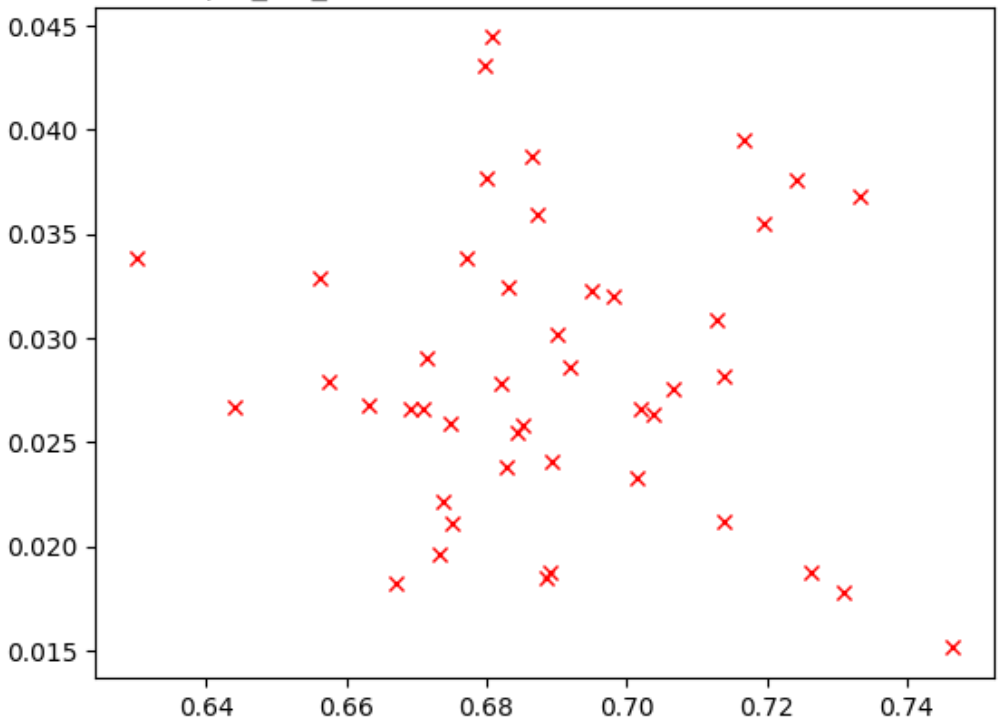
Cada punto del gráfico representa un modelo candidato de correlación.
El eje x representa las puntuaciones de entrenamiento completo de la fase 2 de los modelos, y el eje y representa las puntuaciones de la tarea proxy de la fase 1 de los mismos modelos.
Observa el punto más alto. Este modelo obtuvo la puntuación más alta en la tarea proxy (eje y), pero su rendimiento fue bajo durante la fase 2 del entrenamiento completo (eje x) en comparación con otros modelos. Por el contrario, la siguiente imagen muestra un ejemplo de una buena correlación (puntuación de correlación = 0,67), lo que convierte a esta tarea proxy en una buena candidata para una búsqueda:
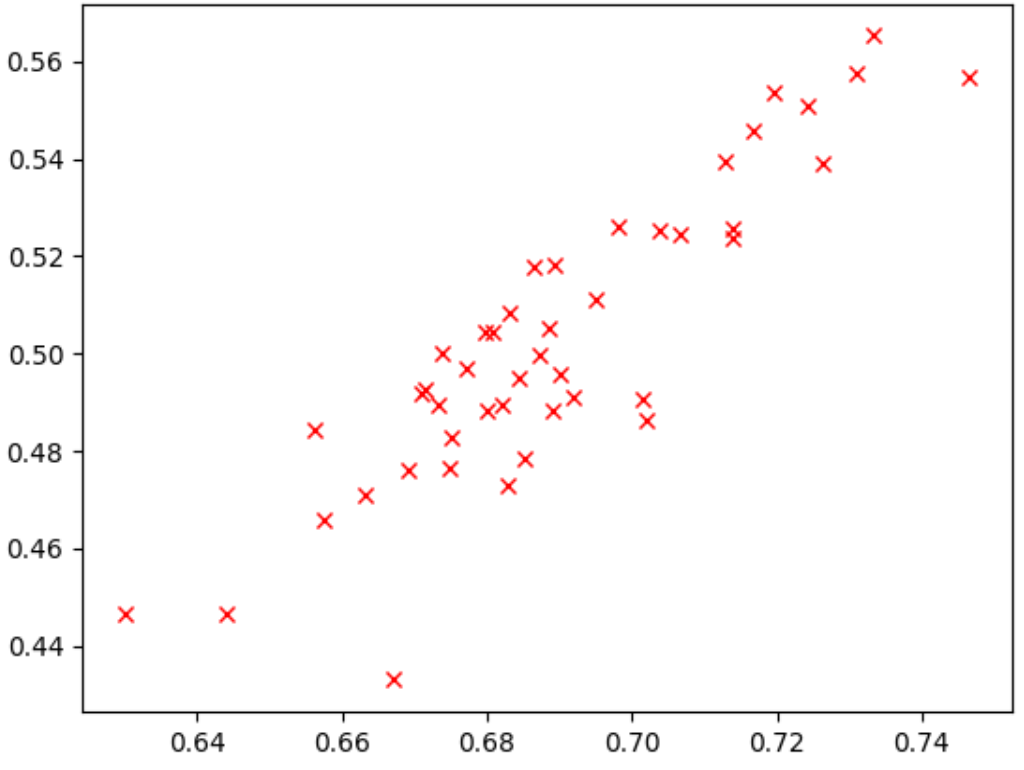
Si tu búsqueda implica una restricción de latencia, verifica también que haya una buena correlación entre los valores de latencia.
Ten en cuenta que las recompensas de los modelos candidatos a correlación tienen un buen intervalo y un muestreo decente del intervalo de recompensas. Si no es así, no podrá evaluar la correlación de rangos. Por ejemplo, si todas las recompensas de la fase 1 de los modelos candidatos a correlación se centran en solo dos valores (0,9 y 0,1), no se obtiene suficiente variación de muestreo.
Comprobación de varianza
Otro requisito de una tarea proxy es que no debe tener una gran variación en la precisión ni en la latencia cuando se repite varias veces para el mismo modelo sin ningún cambio. Si esto ocurre, se envía una señal ruidosa al mando. Se proporciona una herramienta para medir esta varianza.
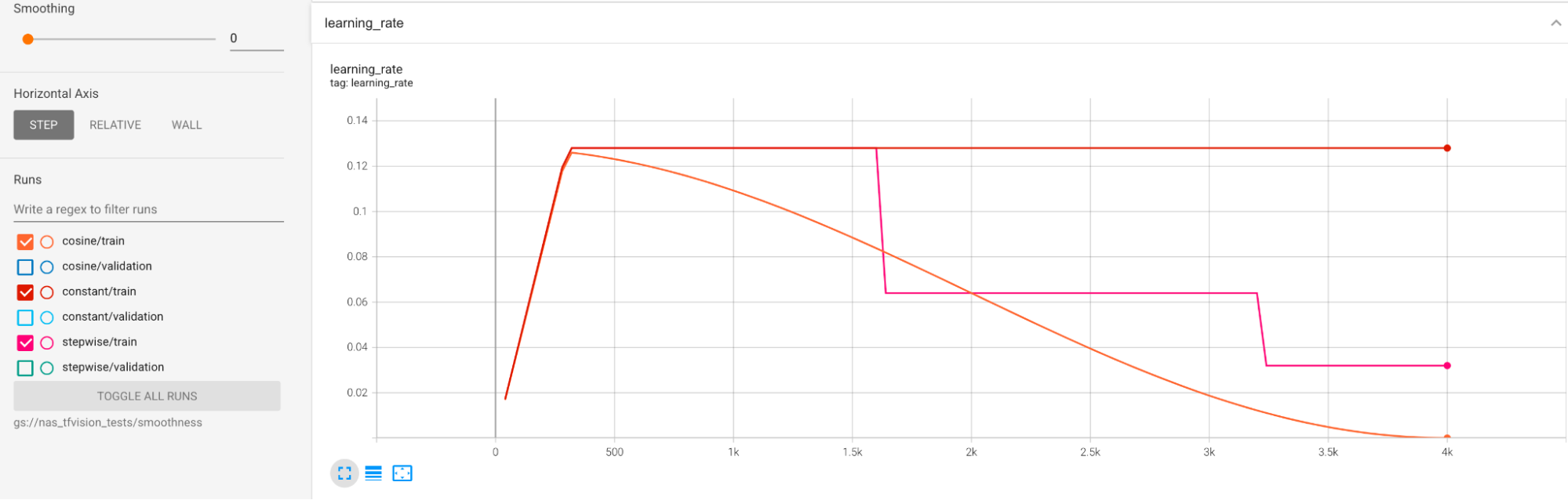
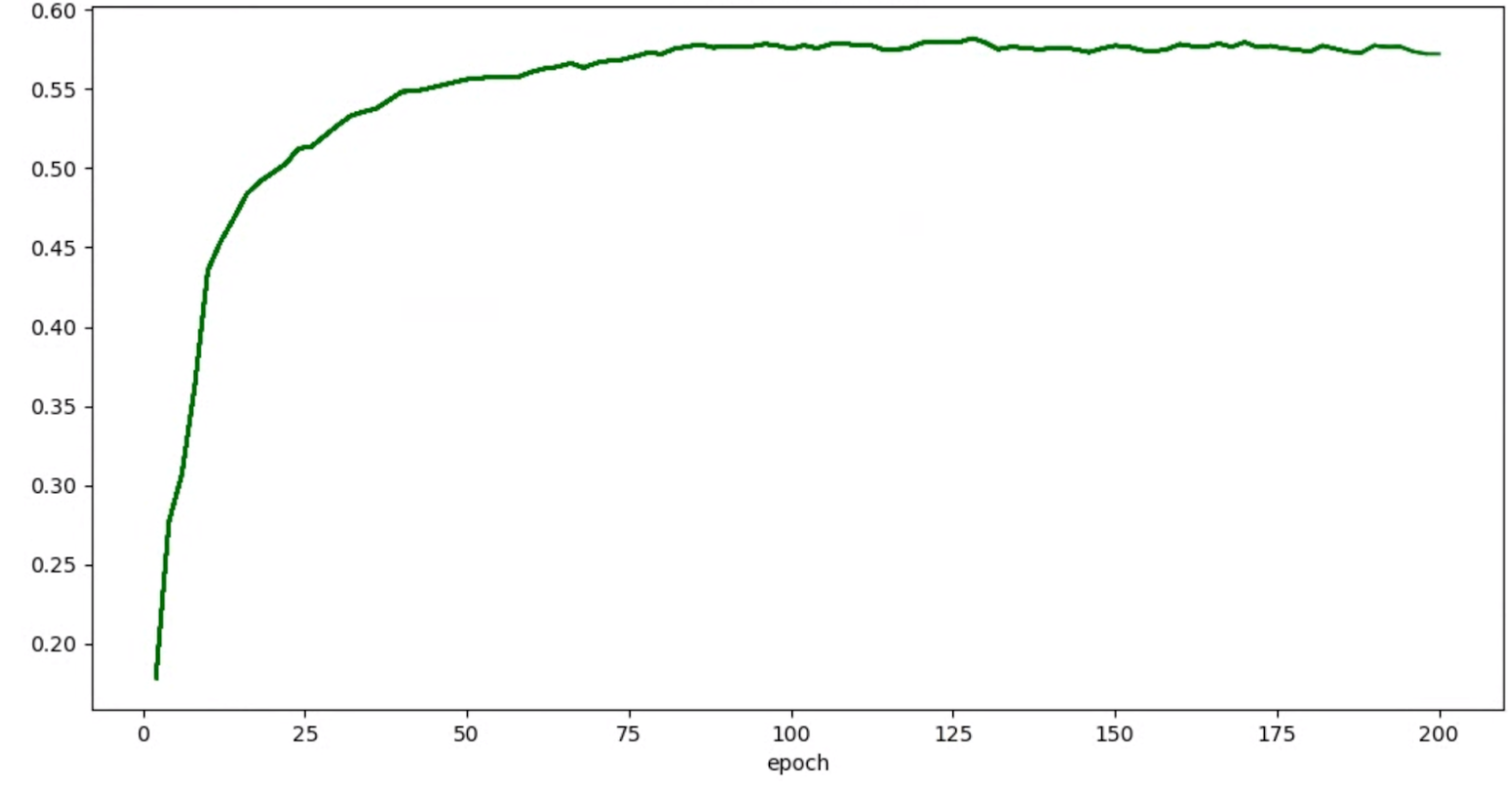
Se proporcionan ejemplos para mitigar la gran varianza durante el entrenamiento. Una forma de hacerlo es usar cosine decay como programación de la tasa de aprendizaje. En el siguiente gráfico se comparan tres estrategias de tasa de aprendizaje:

El gráfico inferior corresponde a una tasa de aprendizaje constante. Cuando la puntuación varía mucho al final del entrenamiento, un pequeño cambio en la elección del número reducido de pasos de entrenamiento puede provocar un gran cambio en la recompensa final de la tarea proxy. Para que la recompensa de la tarea proxy sea más estable, es mejor usar una disminución de la tasa de aprendizaje del coseno, como se muestra en las puntuaciones de validación correspondientes del gráfico superior. Observa cómo la gráfica más alta se suaviza hacia el final del entrenamiento. El gráfico central muestra la puntuación correspondiente a la reducción gradual de la tasa de aprendizaje. Es mejor que la tasa constante, pero no es tan fluida como la disminución del coseno y también requiere ajustes manuales.
A continuación, se muestran las programaciones de la tasa de aprendizaje:
Suavizado adicional
Si usas una gran cantidad de aumentos, es posible que la curva de validación no sea lo suficientemente suave con la disminución del coseno. El uso de aumento de datos indica una falta de datos de entrenamiento. En este caso, no se recomienda usar Neural Architecture Search, sino augmentation-search.
Si la causa no es el aumento excesivo y ya has probado la desintegración del coseno, pero quieres conseguir más fluidez, usa la media móvil exponencial en TensorFlow 2 o la media ponderada estocástica en PyTorch. Consulta este puntero de código para ver un ejemplo de uso del optimizador de media móvil exponencial con TensorFlow 2 y este ejemplo de media ponderada estocástica para PyTorch.
Si los gráficos de precisión o de épocas de las pruebas tienen este aspecto:
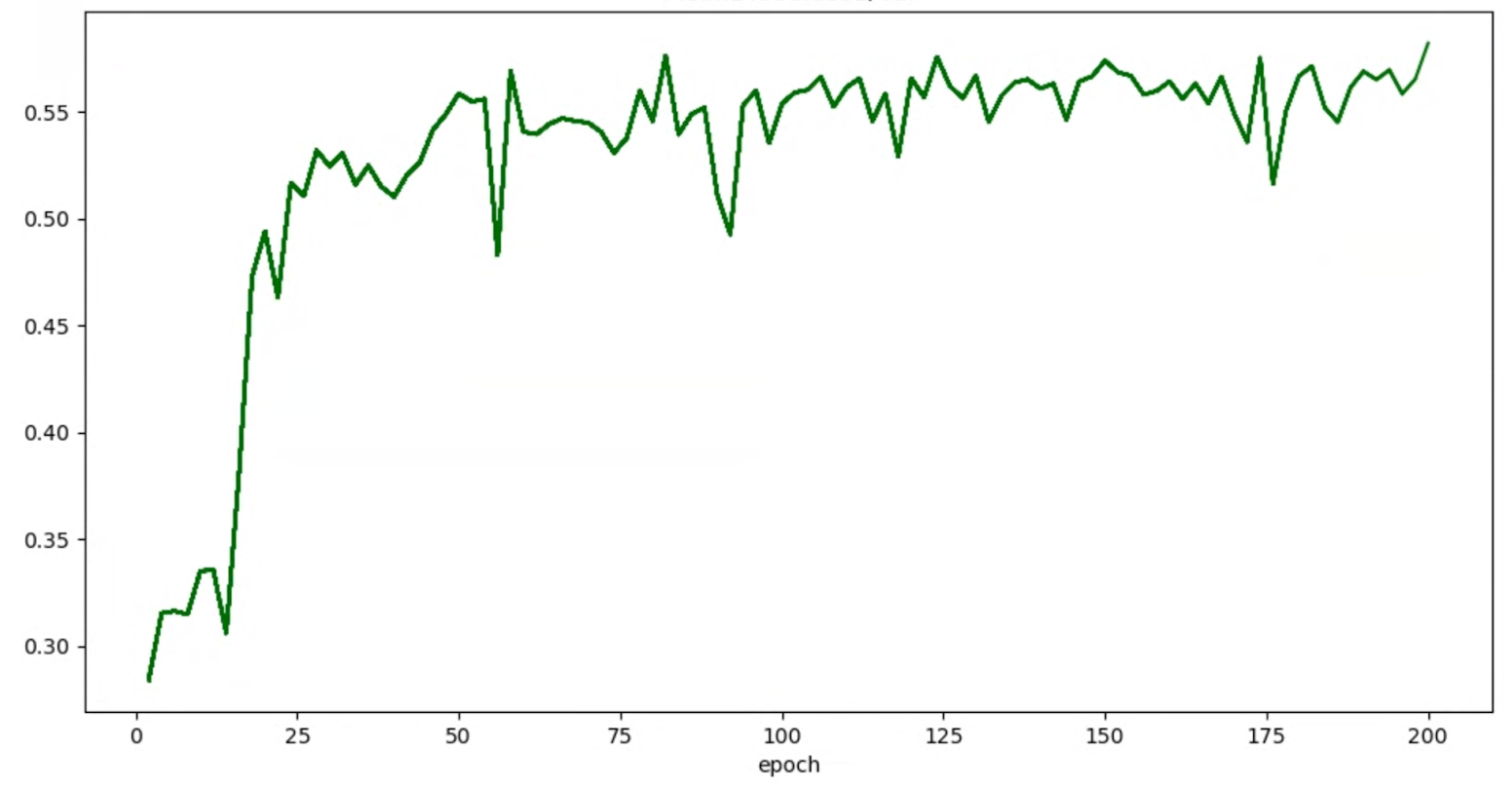
A continuación, puedes aplicar las técnicas de suavizado mencionadas anteriormente (como el promedio ponderado estocástico o el promedio móvil exponencial) para obtener un gráfico más coherente, como el siguiente:
Errores relacionados con la falta de memoria y la tasa de aprendizaje
El espacio de búsqueda de arquitectura puede generar modelos mucho más grandes que tu base. Es posible que hayas ajustado el tamaño del lote de tu modelo de referencia, pero este ajuste puede fallar cuando se muestrean modelos más grandes durante la búsqueda, lo que provoca errores de falta de memoria. En ese caso, debes reducir el tamaño del lote.
El otro tipo de error que aparece es un error NaN (no es un número). Debes reducir la tasa de aprendizaje inicial o añadir un recorte de gradiente.
Como se menciona en el tutorial-2, si más del 20% de los modelos de espacio de búsqueda devuelven puntuaciones no válidas, no se realiza la búsqueda completa. Nuestras herramientas de diseño de tareas proxy ofrecen una forma de evaluar la tasa de errores.
Herramientas de diseño de tareas proxy
En las secciones anteriores se han tratado los principios del diseño de tareas proxy. En esta sección se proporcionan tres herramientas de diseño de tareas proxy para encontrar automáticamente la tarea proxy óptima en función de los diferentes enfoques de diseño y de cuál cumple todos los requisitos.
Cambios de código obligatorios
Primero debes modificar ligeramente tu código de entrenador para que pueda interactuar con las herramientas de diseño de proxy-task durante un proceso iterativo.
En tf_vision/train_lib.py se muestra un ejemplo. Primero debes importar nuestra biblioteca:
from google.cloud.visionsolutions.nas.proxy_task import proxy_task_utils
Antes de que empiece un ciclo de entrenamiento en tu bucle de entrenamiento, comprueba si tienes que detener el entrenamiento antes de tiempo, ya que la herramienta de diseño de tareas proxy quiere que uses nuestra biblioteca:
if proxy_task_utils.get_stop_training(
model_dir,
end_training_cycle_step=<last-training-step-idx done so far>,
total_training_steps=<total-training-steps>):
break
Después de que se complete cada ciclo de entrenamiento en el bucle de entrenamiento, actualiza la nueva puntuación de precisión, el paso de inicio y fin del ciclo de entrenamiento, el tiempo del ciclo de entrenamiento en segundos y el número total de pasos de entrenamiento.
proxy_task_utils.update_trial_training_accuracy_metric(
model_dir=model_dir,
accuracy=<latest accuracy value>,
begin_training_cycle_step=<beginning training step for this cycle>,
end_training_cycle_step=<end training step for this cycle>,
training_cycle_time_in_secs=<training cycle time (excluding validation)>,
total_training_steps=<total-training-steps>)
Ten en cuenta que el tiempo del ciclo de entrenamiento no debe incluir el tiempo de evaluación de la puntuación de validación. Asegúrate de que tu entrenador calcule las puntuaciones de validación con frecuencia (evaluation_frequency) para que tengas suficientes muestras de tu curva de validación. Si usas la restricción de latencia, actualiza la métrica de latencia después de calcularla:
proxy_task_utils.update_trial_training_latency_metric(
model_dir=model_dir,
latency=<measured_latency>)
La herramienta de selección de modelos requiere
la carga del punto de control anterior para la iteración sucesiva.
Para habilitar la reutilización de un punto de control anterior, añade una marca a tu entrenador
como se muestra en tf_vision/cloud_search_main.py:
parser.add_argument(
"--retrain_use_search_job_checkpoint",
type=cloud_nas_utils.str_2_bool,
default=False,
help="True to use previous NAS search job checkpoint."
)
Carga este punto de control antes de entrenar el modelo:
if FLAGS.retrain_use_search_job_checkpoint:
prev_checkpoint_dir = cloud_nas_utils.get_retrain_search_job_model_dir(
retrain_search_job_trials=FLAGS.retrain_search_job_trials,
retrain_search_job_dir=FLAGS.retrain_search_job_dir)
logging.info("Setting checkpoint to %s.", prev_checkpoint_dir)
# Now set your checkpoint using 'prev_checkpoint_dir'.
También necesita el metric-id correspondiente a los valores de precisión y latencia
que le haya proporcionado su entrenador. Si la recompensa de tu entrenador (que a veces es una combinación de precisión y latencia) es diferente de la precisión, asegúrate de también informar de la métrica de solo precisión mediante other_metrics de tu entrenador.
Por ejemplo, en el siguiente ejemplo se muestran las métricas de precisión y latencia que genera nuestro entrenador prediseñado:
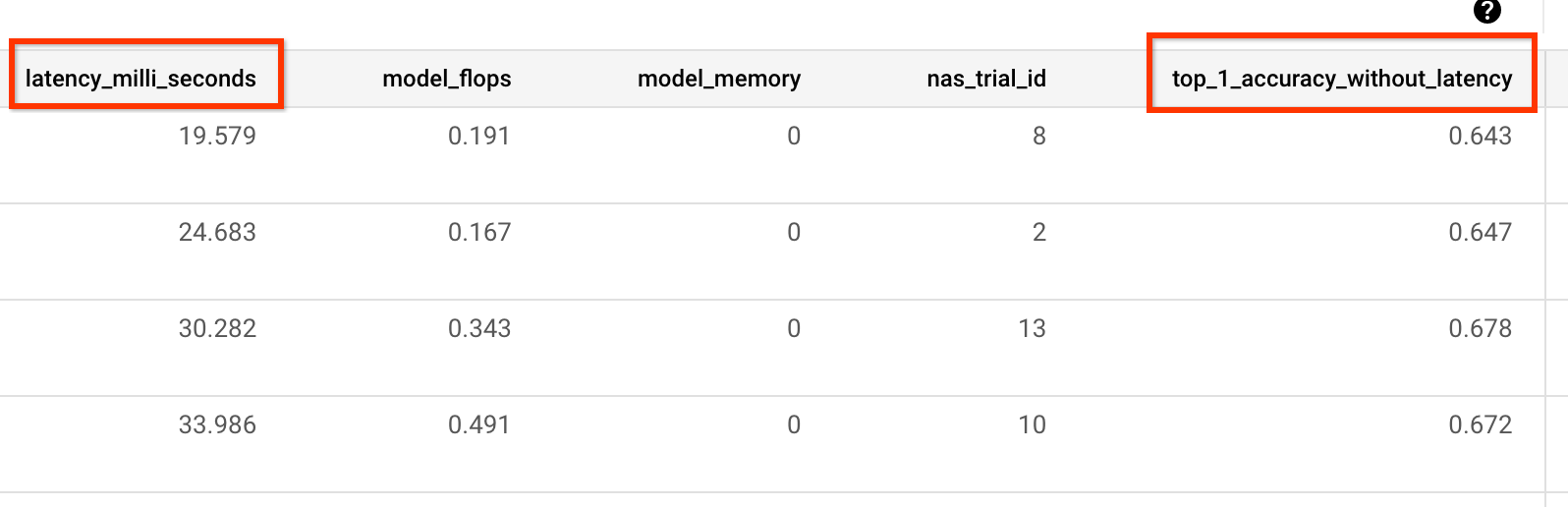
Medición de la varianza
Una vez que haya modificado su código de entrenador, el primer paso es medir la varianza de su entrenador. Para medir la varianza, modifica la configuración de entrenamiento de referencia de lo siguiente:
- reducir los pasos de entrenamiento para que se ejecute durante aproximadamente una hora con solo una o dos GPUs. Necesitamos una pequeña muestra de entrenamiento completo.
- Usa la tasa de aprendizaje de desintegración del coseno y define sus pasos para que sean los mismos que estos pasos reducidos, de modo que la tasa de aprendizaje sea casi cero al final.
La herramienta de medición de varianza toma una muestra de un modelo del espacio de búsqueda, comprueba que este modelo pueda empezar a entrenarse sin dar errores de falta de memoria o NAN, ejecuta cinco copias de este modelo con tus ajustes durante aproximadamente una hora y, a continuación, informa de la varianza y la fluidez de la puntuación de entrenamiento. El coste total de ejecutar esta herramienta es aproximadamente el mismo que el de ejecutar cinco modelos con tus ajustes durante aproximadamente una hora.
Inicia el trabajo de medición de varianza ejecutando el siguiente comando (necesitas una cuenta de servicio):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
####### Variance measurement related parameters ######
proxy_task_variance_measurement_docker_id=${USER}_variance_measurement_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id}
# The command below passes 'dummy' arguments for the training docker.
# You need to modify them for your own docker.
python3 vertex_nas_cli.py measure_proxy_task_variance \
--proxy_task_variance_measurement_docker_id=${proxy_task_variance_measurement_docker_id} \
--project_id=${project_id} \
--service_account=${service_account} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Una vez que inicies este trabajo de medición de variaciones, obtendrás un enlace al trabajo. El nombre del trabajo debe empezar por el prefijo Variance_Measurement. A continuación, se muestra un ejemplo de interfaz de usuario de un trabajo:
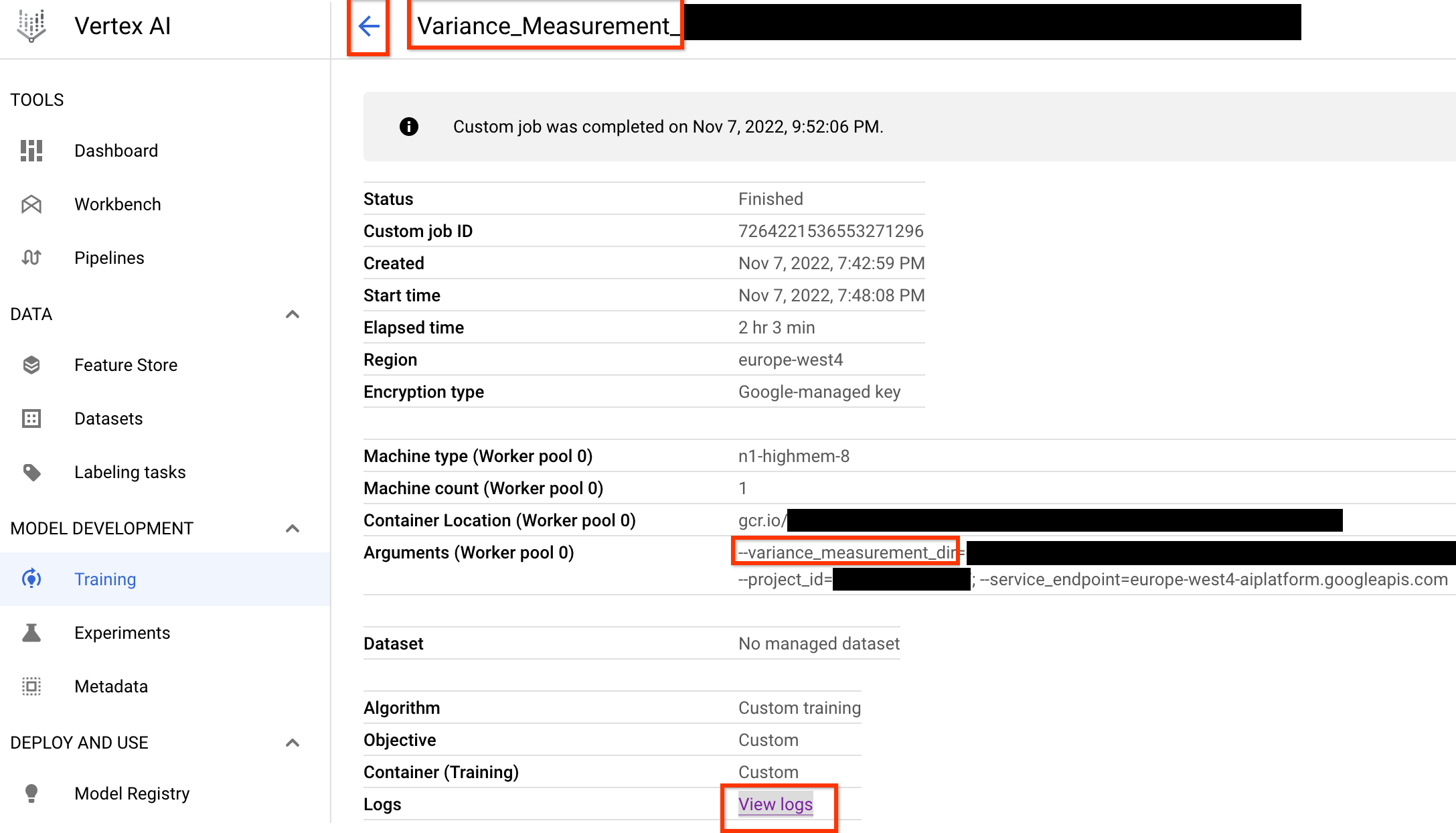
El variance_measurement_dir contendrá todos los resultados y podrás consultar los registros haciendo clic en el enlace Ver registros.
De forma predeterminada, este trabajo usa una CPU en la nube para ejecutarse en segundo plano como un trabajo personalizado y, a continuación, inicia y gestiona los trabajos NAS secundarios.
En NAS jobs (Tareas de NAS), verás una tarea llamada
Find_workable_model_<your job name>. Este trabajo tomará una muestra de tu espacio de búsqueda para encontrar un modelo que no genere ningún error. Una vez que se encuentra un modelo de este tipo, la tarea de medición de varianza inicia otra tarea de NAS <your job name>, que ejecuta cinco copias de este modelo durante el número de pasos de entrenamiento que hayas definido anteriormente. Una vez que se ha completado el entrenamiento de estos modelos, el trabajo de medición de la varianza mide la varianza y la fluidez de la puntuación, y registra estos datos en sus registros:
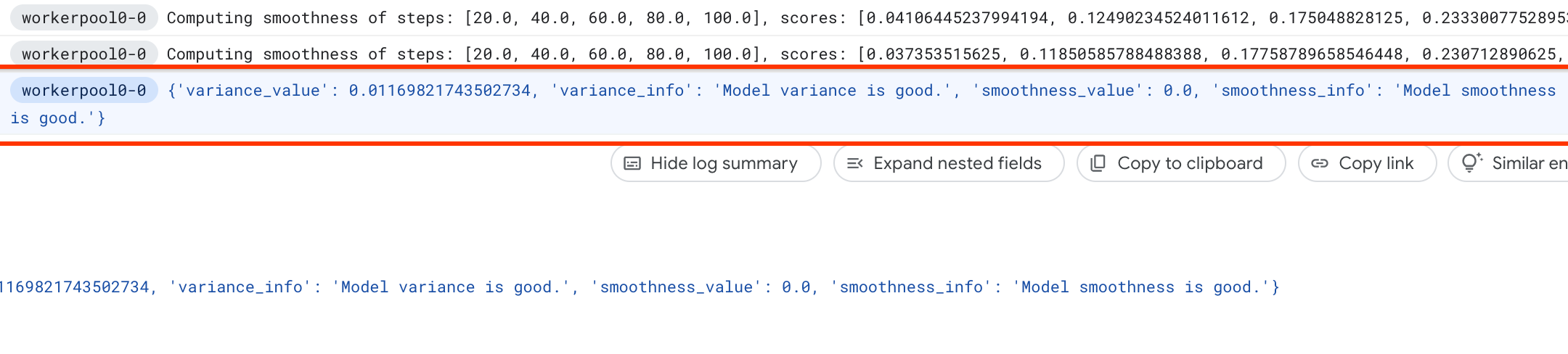
Si la varianza es alta, puedes consultar las técnicas que se indican aquí.
Selección de modelos
Una vez que hayas verificado que tu entrenador no tiene una varianza alta, sigue estos pasos:
- para encontrar unos 10 modelos candidatos de correlación
- Calcula las puntuaciones de entrenamiento completo, que servirán de referencia cuando calcules las puntuaciones de correlación de tareas proxy para diferentes opciones de tareas proxy más adelante.
Nuestra herramienta busca de forma automática y eficiente estos modelos candidatos a correlación y se asegura de que tengan una buena distribución de puntuaciones tanto en precisión como en latencia para que el cálculo de la correlación futura tenga una buena base. Para ello, la herramienta hace lo siguiente:
- Muestrea aleatoriamente
N_beginmodelos de tu espacio de búsqueda. En este ejemplo, supongamos queN_begin = 30. La herramienta los entrena durante 1/30 del tiempo de entrenamiento completo. - Rechaza cinco de los 30 modelos, que no aportan más a la distribución de la precisión y la latencia. En la siguiente imagen se muestra un ejemplo. Los modelos rechazados se muestran como puntos rojos:
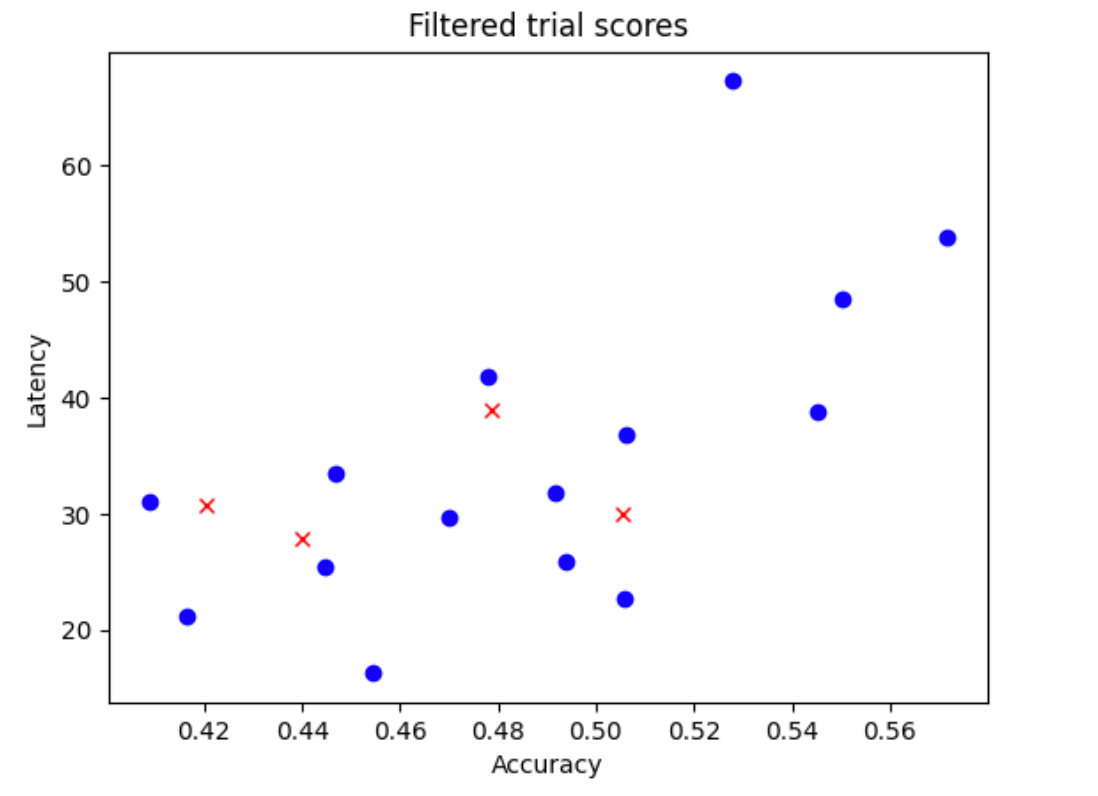
- Entrena los 25 modelos seleccionados durante 1/25 del tiempo de entrenamiento completo y, a continuación, rechaza cinco modelos más en función de las puntuaciones obtenidas hasta el momento. Ten en cuenta que el entrenamiento de los 25 modelos continúa desde su último punto de control.
- Repite este proceso hasta que solo queden
Nmodelos con una buena distribución. - Entrena estos últimos
Nmodelos hasta completarlos.
El valor predeterminado de N_begin es 30 y se puede encontrar como START_NUM_MODELS
en el archivo proxy_task/proxy_task_model_selection_lib_constants.py.
El valor predeterminado de N es 10 y se puede encontrar como FINAL_NUM_MODELS
en el archivo proxy_task/proxy_task_model_selection_lib_constants.py.
El coste adicional de este proceso de selección de modelos se calcula de la siguiente manera:
= (30*1/30 + 25*1/25 + 20*1/20 + 15*1/15 + 10*(remaining-training-time-fraction)) * full-training-time
= (4 + 10*(0.81)) * full-training-time
~= 12 * full-training-time
Sin embargo, no superes el ajuste N=10. La herramienta de búsqueda de tareas proxy
ejecuta posteriormente estos modelos N en paralelo. Por lo tanto, asegúrate de tener suficiente cuota de GPU para ello. Por ejemplo, si tu tarea proxy usa dos GPUs para un modelo, debes tener una cuota de al menos 2*N GPUs.
En la tarea de selección de modelos, usa la misma partición del conjunto de datos que en la tarea de entrenamiento completo de la fase 2 y la misma configuración del entrenador que en el entrenamiento completo de referencia.
Ahora puedes iniciar el trabajo de selección de modelo ejecutando el siguiente comando (necesitas una cuenta de servicio):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task model-selection related parameters ######
proxy_task_model_selection_docker_id=${USER}_model_selection_${DATE}
# Use the service account that you set-up for your project.
service_account=<your service account>
job_name=<your job name>
# The value below depends on your accelerator quota. By default
# the model-selection job runs 30 trials. However, depending on
# your quota, you can choose to only run 10 trials in parallel at a time.
# However, lowering this number can increase the overall runtime for the job.
max_parallel_nas_trial=<num parallel trials>
# The value below is the 'metric-id' corresponding to the accuracy ONLY
# metric reported by your trainer. Note that this metric may
# be different from the 'reward'.
accuracy_metric_id=<set accuracy metric id used by your trainer>
latency_metric_id=<set latency metric id used by your trainer>
############################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py select_proxy_task_models \
--service_account=${service_account} \
--proxy_task_model_selection_docker_id=${proxy_task_model_selection_docker_id} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--max_parallel_nas_trial=${max_parallel_nas_trial} \
--accuracy_metric_id=${accuracy_metric_id} \
--latency_metric_id=${latency_metric_id} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Una vez que inicies este trabajo de controlador de selección de modelo, recibirás un enlace al trabajo. El nombre del trabajo empieza por el prefijo Model_Selection_. A continuación, se muestra un ejemplo de interfaz de usuario de un trabajo:
El model_selection_dir contiene todos los resultados. Consulta los registros
haciendo clic en el enlace View logs.
De forma predeterminada, este trabajo de controlador de selección de modelos usa
una CPU en Google Cloud para ejecutarse en segundo plano
como un trabajo personalizado y, a continuación, inicia y gestiona trabajos NAS secundarios para cada iteración de la selección de modelos.
Cada trabajo de NAS secundario tiene un nombre, como <your_job_name>_iter_3 (excepto en la iteración 0).
Solo se ejecuta una iteración a la vez. En cada iteración, el número de modelos (número de pruebas) se reduce y la duración del entrenamiento aumenta. Al final de cada iteración, cada trabajo de NAS guarda un archivo gs://<job-output-dir>/search/filtered_trial_scores.png que muestra visualmente qué modelos se han rechazado en esa iteración.
También puedes ejecutar el siguiente comando:
gcloud storage cat gs://<path to 'model_selection_dir'>/MODEL_SELECTION_STATE.json
que muestra un resumen de las iteraciones y el estado actual del trabajo del controlador de selección de modelos, el nombre del trabajo y enlaces para cada iteración:
{
"start_num_models": 30,
"final_num_models": 10,
"num_models_to_remove_per_iter": 5,
"accuracy_metric_id": "top_1_accuracy_without_latency",
"latency_metric_id": "latency_milli_seconds",
"iterations": [
{
"num_trials": 30,
"trials_to_retrain": [
"27",
"16",
...,
"14"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2111217356469436416",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2111217356469436416/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/6909239809479278592",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/6909239809479278592/cpu?project=my-project",
"desired_training_step_pct": 2.0
},
...,
{
"num_trials": 15,
"trials_to_retrain": [
"14",
...,
"5"
],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/7045544066951413760",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/7045544066951413760/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/2790768318993137664",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2790768318993137664/cpu?project=my-project",
"desired_training_step_pct": 28.57936507936508
},
{
"num_trials": 10,
"trials_to_retrain": [],
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2742864796394192896",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2742864796394192896/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/1490864099985195008",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/1490864099985195008/cpu?project=my-project",
"desired_training_step_pct": 101.0
}
]
}
La última iteración tiene el número final de modelos de referencia con una buena distribución de puntuaciones. Estos modelos y sus puntuaciones se usan para la búsqueda de tareas proxy en el siguiente paso. Si la precisión final y el intervalo de puntuación de latencia de los modelos de referencia son mejores o similares a los de tu modelo de referencia, tendrás una buena indicación inicial sobre tu espacio de búsqueda. Si el intervalo de puntuación final de precisión y latencia es significativamente peor que el valor de referencia, vuelve a revisar el espacio de búsqueda.
Ten en cuenta que, si más del 20% de las pruebas de la primera iteración fallan, debes cancelar el trabajo de selección de modelos e identificar la causa principal de los fallos. Puede que haya un problema con tu espacio de búsqueda o con los ajustes del tamaño de lote y la tasa de aprendizaje.
Usar un dispositivo de latencia local para seleccionar el modelo
Para usar el dispositivo de latencia local para la selección de modelos, ejecuta el comando select_proxy_task_models sin el Docker de latencia y sin las marcas de Docker de latencia, ya que no quieres iniciar el Docker de latencia en Google Cloud. A continuación, usa el comando run_latency_calculator_local descrito en el tutorial 4 para iniciar la tarea de la calculadora de latencia local. En lugar de pasar la marca --search_job_id, pasa la marca --controller_job_id con el ID de trabajo de selección de modelo numérico que obtienes después de ejecutar el comando select_proxy_task_models.
Reanudar la tarea del controlador de selección de modelo
En las siguientes situaciones, debes reanudar el trabajo del controlador de selección de modelos:
- El trabajo del controlador de selección del modelo principal falla (caso poco habitual).
- Cancelas por error el trabajo del controlador de selección de modelo.
En primer lugar, no canceles la tarea de iteración de NAS secundaria (pestaña NAS) si ya se está ejecutando. A continuación, para reanudar el trabajo del controlador de selección del modelo principal, ejecuta el comando select_proxy_task_models como antes, pero esta vez pasa la marca --previous_model_selection_dir y asígnala al directorio de salida del trabajo del controlador de selección del modelo anterior. El trabajo del controlador de selección de modelos reanudado carga su estado anterior del directorio y sigue funcionando como antes.
Búsqueda de tareas proxy
Una vez que se han encontrado los modelos candidatos a correlación y sus puntuaciones de entrenamiento completo, el siguiente paso es usarlos para evaluar las puntuaciones de correlación de las diferentes tareas proxy y elegir la tarea proxy óptima. Nuestra herramienta de búsqueda de tareas de proxy puede encontrar automáticamente una tarea de proxy, que ofrece lo siguiente:
- El coste de búsqueda de NAS más bajo.
- Cumple un umbral de requisito de correlación mínimo después de proporcionarle una definición de espacio de búsqueda de tareas proxy.
Recuerda que hay tres dimensiones comunes para buscar una tarea proxy óptima, que son las siguientes:
- Se ha reducido el número de pasos de entrenamiento.
- Se reduce la cantidad de datos de entrenamiento.
- Se ha reducido la escala del modelo.
Puedes crear un espacio de búsqueda de tareas proxy discreto muestreando estas dimensiones, tal como se muestra a continuación:
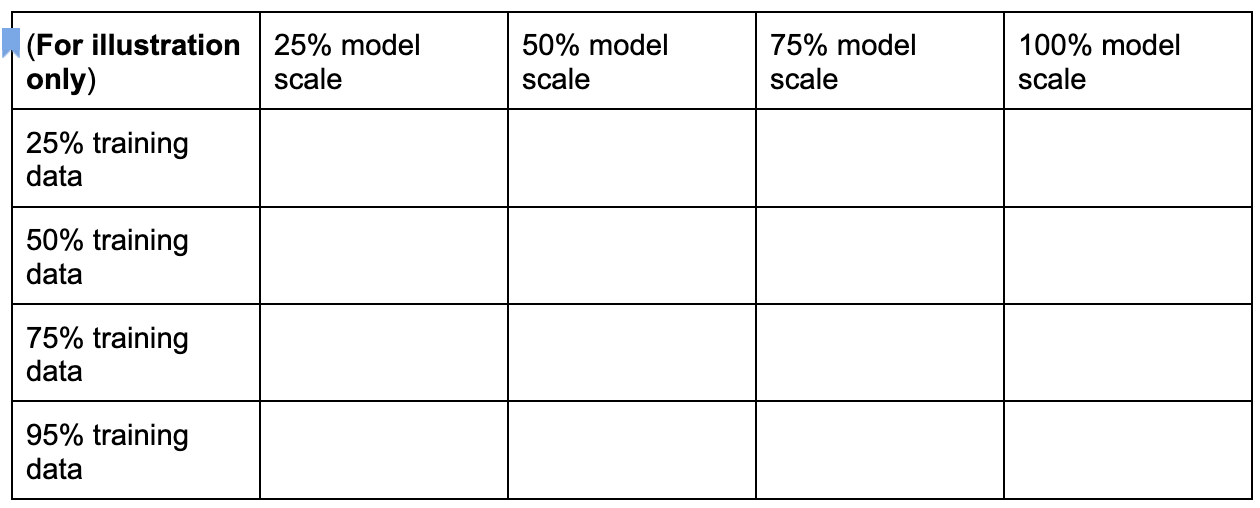
Los porcentajes que se indican arriba son solo una sugerencia aproximada y un ejemplo. En la práctica, puedes elegir cualquier opción discreta.
Ten en cuenta que no hemos incluido la dimensión training-steps en el espacio de búsqueda anterior. Esto se debe a que la herramienta de búsqueda proxy-task
determina el paso de entrenamiento óptimo dada una opción de proxy-task.
Considera la opción de proxy-tarea de
[50% training data, 25% model scale]. Define el número de pasos de entrenamiento con el mismo valor que en el entrenamiento de referencia completo.
Al evaluar esta tarea proxy, la herramienta de búsqueda de tareas proxy inicia el entrenamiento de los modelos candidatos a correlación, monitoriza sus puntuaciones de precisión actuales y calcula continuamente la puntuación de correlación de rango (usando las puntuaciones de entrenamiento completo anteriores de los modelos de referencia):

Por lo tanto, la herramienta de búsqueda de tareas proxy puede detener el entrenamiento de tareas proxy una vez que se obtiene la correlación deseada (por ejemplo, 0,65) o también puede detenerse antes si se supera la cuota de coste de búsqueda (por ejemplo, un límite de 3 horas por tarea proxy). Por lo tanto, no es necesario que busques explícitamente los pasos de entrenamiento. La herramienta de búsqueda de tareas proxy evalúa cada tarea proxy de tu espacio de búsqueda discreto como una búsqueda de cuadrícula y te ofrece la mejor opción.
A continuación, se muestra un ejemplo de definición de espacio de búsqueda de MnasNet proxy-task
mnasnet_proxy_task_config_generator,
definido en el archivo proxy_task/proxy_task_search_spaces.py,
para mostrar cómo puedes definir tu propio espacio de búsqueda:
# MNasnet training-data size choices.
MNASNET_TRAINING_DATA_PCT_LIST = [25, 50, 75, 95]
# Training data path regex pattern.
_TRAINING_DATA_PATH_REGEX = r"gs://.*/.*"
def update_mnasnet_proxy_training_data(
baseline_docker_args_map: Dict[str, Any],
training_data_pct: int) -> Optional[Dict[str, Any]]:
"""Updates MNasnet baseline docker to use a certain training_data_pct."""
proxy_task_docker_args_map = copy.deepcopy(baseline_docker_args_map)
# Imagenet training data path looks like:
# gs://<path to imagenet data>/train-00[0-7]??-of-01024.
if not re.match(_TRAINING_DATA_PATH_REGEX,
baseline_docker_args_map["training_data_path"]):
raise ValueError(
"Training data path %s does not match the desired pattern." %
baseline_docker_args_map["training_data_path"])
root_path, _ = baseline_docker_args_map["training_data_path"].rsplit("/", 1)
if training_data_% == 25:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-1][0-4]?-of-01024*")
elif training_data_% == 50:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-4]??-of-01024*")
elif training_data_% == 75:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-6][0-4]?-of-01024*")
elif training_data_% == 95:
proxy_task_docker_args_map["training_data_path"] = os.path.join(
root_path, "train-00[0-8][0-4]?-of-01024*")
else:
logging.warning("Mnasnet training_data_% %d is not supported.",
training_data_pct)
return None
proxy_task_docker_args_map["validation_data_path"] = os.path.join(
root_path, "train-009[0-4]?-of-01024")
return proxy_task_docker_args_map
def mnasnet_proxy_task_config_generator(
baseline_docker_args_map: Dict[str, Any]
) -> List[proxy_task_utils.ProxyTaskConfig]:
"""Returns a list of proxy-task configs to be evaluated for MNasnet.
Args:
baseline_docker_args_map: A set of baseline training-docker arguments in
the form of a dictionary of {'key', val}. The different proxy-task
configs to try can be built by modifying this baseline.
Returns:
A list of proxy-task configs to be evaluated for this
proxy-task search space.
"""
proxy_task_config_list = []
# NOTE: Will not search over model-scale for MNasnet.
for training_data_% in MNASNET_TRAINING_DATA_PCT_LIST:
proxy_task_docker_args_map = update_mnasnet_proxy_training_data(
baseline_docker_args_map=baseline_docker_args_map,
training_data_pct=training_data_pct)
if not proxy_task_docker_args_map:
continue
proxy_task_name = "mnasnet_proxy_training_data_pct_{}".format(
training_data_pct)
proxy_task_config_list.append(
proxy_task_utils.ProxyTaskConfig(
name=proxy_task_name, docker_args_map=proxy_task_docker_args_map))
return proxy_task_config_list
En este ejemplo, creamos un espacio de búsqueda sencillo con los valores 25, 50, 75 y 95 de training-data-percent (ten en cuenta que no se usa el 100 % de los datos de entrenamiento para stage1-search).
La función mnasnet_proxy_task_config_generator toma una plantilla de referencia común de argumentos de Docker de entrenamiento y, a continuación, modifica estos argumentos para cada tamaño de datos de entrenamiento de la tarea proxy deseada. A continuación, devuelve una lista de proxy-task-config que la herramienta de búsqueda de proxy-task procesa una a una más adelante en el mismo orden. Cada configuración de proxy-task tiene un name y un docker_args_map, que es un mapa de clave-valor para los argumentos de Docker de proxy-task.
Puedes implementar tu propia definición de espacio de búsqueda según tus requisitos y diseñar tus propios espacios de búsqueda de tareas proxy, incluso para más de las dos dimensiones de datos de entrenamiento reducidos o de escala de modelo reducida. Sin embargo, no es recomendable buscar explícitamente los pasos de entrenamiento, ya que implica un desperdicio de recursos de computación repetidos. Deja que la herramienta de búsqueda de tareas proxy se encargue de esta dimensión.
Para tu primera búsqueda de tareas proxy, puedes probar a reducir solo los datos de entrenamiento (como en el ejemplo de MnasNet) y omitir la reducción de la escala del modelo, ya que esta puede implicar varios parámetros en image-size, num-filters o num-blocks.
En la mayoría de los casos, los datos de entrenamiento reducidos (y la búsqueda implícita en los pasos de entrenamiento reducidos) son suficientes para encontrar una buena tarea proxy.
Define el número de pasos de entrenamiento
en el número utilizado en el entrenamiento de referencia completo.
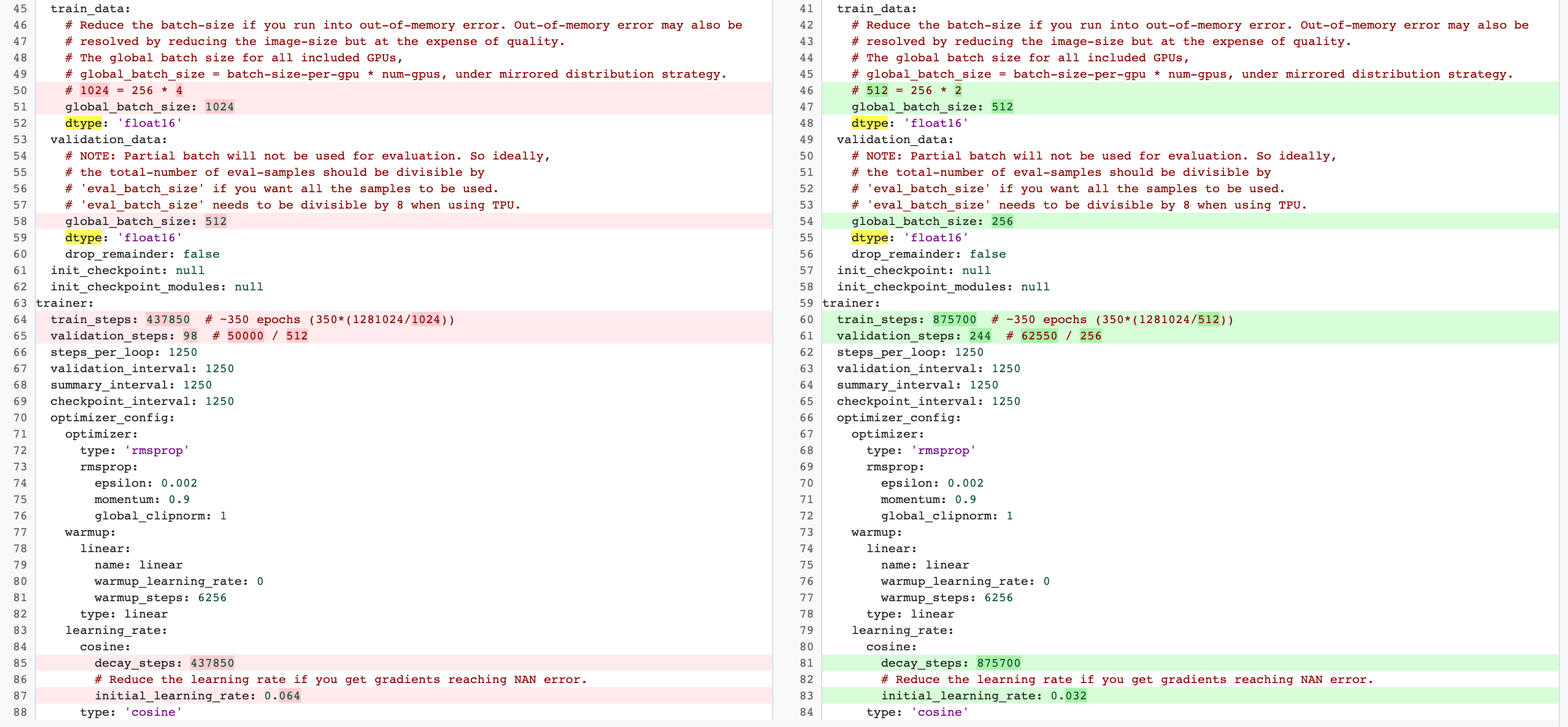
Hay diferencias entre las configuraciones de entrenamiento completo de la fase 2 y las de tareas proxy de la fase 1. En el caso de la tarea de proxy, debes reducir el batch-size en comparación con la configuración de entrenamiento de referencia completa para usar solo 2 o 4 GPUs.
Normalmente, el entrenamiento completo usa 4 GPUs, 8 GPUs o más, pero la tarea proxy solo usa 2 o 4 GPUs.
Otra diferencia es la división entre entrenamiento y validación.
Aquí tienes un ejemplo de los cambios en la configuración de MnasNet al pasar de 4 GPUs para el entrenamiento completo de la fase 2 a 2 GPUs y una división de validación diferente para la búsqueda de tareas proxy:
Inicia el trabajo del controlador de búsqueda proxy-task ejecutando el siguiente comando (necesitas una cuenta de servicio):
DATE="$(date '+%Y%m%d_%H%M%S')"
project_id=<your project-id>
# You can choose any unique docker id below.
trainer_docker_id=${USER}_trainer_${DATE}
trainer_docker_file=<path to your trainer dockerfile>
latency_calculator_docker_id=${USER}_model_selection_${DATE}
latency_calculator_docker_file=${USER}_latency_${DATE}
region=<your job region such as 'us-central1'>
search_space_module=<path to your NAS job search space module>
accelerator_type="NVIDIA_TESLA_V100"
num_gpus=2
# Your bucket should be for your project and in the same region as the job.
root_output_dir=<gs://your-bucket>
# Your latency computation device.
target_device_type="CPU"
####### Proxy task search related parameters ######
proxy_task_search_controller_docker_id=${USER}_proxy_task_search_${DATE}
job_name=<your job name>
# Path to your proxy task search space definition. For ex:
# 'proxy_task.proxy_task_search_spaces.mnasnet_proxy_task_config_generator'
proxy_task_config_generator_module=<path to your proxy task config generator module>
# The previous model-slection job provides the candidate-correlation-models
# and their scores.
proxy_task_model_selection_job_id=<Numeric job id of your previous model-selection>
# During proxy-task search, the proxy-task training is stopped
# when the following correlation score is achieved.
desired_accuracy_correlation=0.65
# During proxy-task search, the proxy-task training is stopped
# if the runtime exceeds this limit: 4 hrs.
training_time_hrs_limit=4
# The proxy-task is marked a good candidate only if the latency
# correlation is also above the required threshold.
# Note: This won't be used if you do not have a latency job.
desired_latency_correlation=0.65
# Early stop a proxy-task evaluation if you already have a better candidate.
# If False, evaluate all proxy-taask candidates.
early_stop_proxy_task_if_not_best=False
# Use the service account that you set-up for your project.
service_account=<your service account>
###################################################
python3 vertex_nas_cli.py build \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--trainer_docker_file=${trainer_docker_file} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_calculator_docker_file=${latency_calculator_docker_file} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id}
# The command below passes 'dummy' arguments for trainer-docker
# and latency-docker. You need to modify them for your own docker.
python3 vertex_nas_cli.py search_proxy_task \
--service_account=${service_account} \
--proxy_task_search_controller_docker_id=${proxy_task_search_controller_docker_id} \
--proxy_task_config_generator_module=${proxy_task_config_generator_module} \
--proxy_task_model_selection_job_id=${proxy_task_model_selection_job_id} \
--proxy_task_model_selection_job_region=${region} \
--desired_accuracy_correlation={$desired_accuracy_correlation}\
--training_time_hrs_limit=${training_time_hrs_limit} \
--desired_latency_correlation=${desired_latency_correlation} \
--early_stop_proxy_task_if_not_best=${early_stop_proxy_task_if_not_best} \
--project_id=${project_id} \
--region=${region} \
--trainer_docker_id=${trainer_docker_id} \
--job_name=${job_name} \
--search_space_module=${search_space_module} \
--accelerator_type=${accelerator_type} \
--num_gpus=${num_gpus} \
--root_output_dir=${root_output_dir} \
--latency_calculator_docker_id=${latency_calculator_docker_id} \
--latency_docker_flags \
dummy_latency_flag1="dummy_latency_val" \
--target_device_type=${target_device_type} \
--search_docker_flags \
dummy_trainer_flag1="dummy_trainer_val"
Después de iniciar este trabajo de controlador de búsqueda de tareas proxy, recibirás un enlace al trabajo. El nombre del trabajo empieza por el prefijo Search_controller_. A continuación, se muestra un ejemplo de interfaz de usuario de un trabajo:
El search_controller_dir contendrá todos los resultados y podrás consultar los registros haciendo clic en el enlace View logs.
De forma predeterminada, este trabajo usa una CPU en la nube para ejecutarse en segundo plano como un trabajo personalizado. Después, inicia y gestiona trabajos NAS secundarios para cada evaluación de tareas proxy.
Cada trabajo NAS de proxy-task
tiene un nombre como ProxyTask_<your-job-name>_<proxy-task-name>
donde <proxy-task-name> es lo que tu
módulo de generador de configuración de proxy-task proporciona para cada proxy-task. Solo se ejecuta una evaluación de proxy-tarea a la vez.
También puedes ejecutar el siguiente comando:
gcloud storage cat gs://<path to 'search_controller_dir'>/SEARCH_CONTROLLER_STATE.json
Este comando muestra un resumen de todas las evaluaciones de proxy-task y el estado actual del trabajo de search-controller, el nombre del trabajo y los enlaces de cada evaluación:
{
"proxy_tasks_map": {
"mnasnet_proxy_training_data_pct_25": {
"proxy_task_stats": {
"training_steps": [
1249,
2499,
...,
18749
],
"accuracy_correlation_over_step": [
-0.06666666666666667,
-0.6,
...,
0.7857142857142856
],
"accuracy_correlation_p_value_over_step": [
0.8618005952380953,
0.016666115520282188,
...,
0.005505952380952381
],
"median_accuracy_over_step": [
0.011478611268103123,
0.04956454783678055,
...,
0.32932570576667786
],
"median_training_time_hrs_over_step": [
0.11611097933475001,
0.22913257125276987,
...,
1.6682701704073444
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.6675102778428197,
"final_training_steps": 18512
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_25",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/4173661476642357248",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/4173661476642357248/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/8785347495069745152",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/8785347495069745152/cpu?project=my-project"
},
...,
"mnasnet_proxy_training_data_pct_95": {
"proxy_task_stats": {
"training_steps": [
1249,
...,
18749
],
"accuracy_correlation_over_step": [
-0.3333333333333333,
...,
0.7857142857142856,
-5.0
],
"accuracy_correlation_p_value_over_step": [
0.21637345679012346,
...,
0.005505952380952381,
-5.0
],
"median_accuracy_over_step": [
0.01120645459741354,
...,
0.38238024711608887,
-1.0
],
"median_training_time_hrs_over_step": [
0.11385884770307843,
...,
1.5466042930547819,
-1.0
],
"latency_correlation": 0.9555555555555554,
"latency_correlation_p_value": 5.5114638447971785e-06,
"stopping_state": "Met desired correlation",
"posted_stop_trials_message": true,
"final_training_time_in_hours": 1.533235285929564,
"final_training_steps": 17108
},
"proxy_task_name": "mnasnet_proxy_training_data_pct_95",
"search_job_name": "projects/123456/locations/europe-west4/nasJobs/2341822328209408000",
"search_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/2341822328209408000/cpu?project=my-project",
"latency_calculator_job_name": "projects/123456/locations/europe-west4/customJobs/7575005095213924352",
"latency_calculator_job_link": "https://console.cloud.google.com/vertex-ai/locations/europe-west4/training/7575005095213924352/cpu?project=my-project"
}
},
"best_proxy_task_name": "mnasnet_proxy_training_data_pct_75"
}
proxy_tasks_map almacena la salida de cada proxy-tarea
de evaluación y best_proxy_task_name registra la mejor proxy-tarea
para la búsqueda. Cada entrada de proxy-tarea tiene datos adicionales, como
proxy_task_stats, que registra el progreso de la
correlación de precisión, sus valores p, la precisión mediana
y el tiempo de entrenamiento mediano en los pasos de entrenamiento. También registra la correlación relacionada con la latencia, si procede, y el motivo por el que se ha detenido este trabajo (por ejemplo, si se ha superado el límite de tiempo de entrenamiento) y el paso de entrenamiento en el que se detiene. También puedes ver estas estadísticas
como gráficos copiando el contenido de search_controller_dir en
tu carpeta local con el siguiente comando:
gcloud storage cp gs://<path to 'search_controller_dir'>/* /your/local/dir
e inspeccionar las imágenes de los gráficos. Por ejemplo, el siguiente gráfico muestra la correlación de la precisión con el tiempo de entrenamiento de la mejor tarea proxy:

Una vez que hayas completado la búsqueda y hayas encontrado la mejor configuración de proxy-task, debes hacer lo siguiente:
- Define el número de pasos de entrenamiento de la tarea proxy
final_training_stepsdel ganador. - Define los pasos de desintegración del coseno igual que
final_training_stepspara que la tasa de aprendizaje sea casi cero al final. - [Opcional] Haz una evaluación de la puntuación de validación al final del entrenamiento, lo que te ahorrará varios costes de evaluación.
Usar un dispositivo de latencia local para la búsqueda de tareas de proxy
Para usar el dispositivo de latencia local para la búsqueda de tareas de proxy, ejecuta el comando search_proxy_task sin el docker de latencia y sin las marcas de docker de latencia, ya que no quieres iniciar el docker de latencia en Google Cloud. A continuación, usa el comando run_latency_calculator_local descrito en el tutorial 4 para iniciar la tarea de la calculadora de latencia local. En lugar de pasar la marca --search_job_id, pasa la marca --controller_job_id con el ID de tarea de búsqueda de proxy numérico que obtienes después de ejecutar el comando search_proxy_task.
Reanudando la tarea del controlador de búsqueda de proxy
En las siguientes situaciones, debes reanudar el trabajo del controlador de búsqueda de tareas de proxy:
- El trabajo del controlador de búsqueda de tareas proxy principal finaliza (caso poco habitual).
- Cancelas por error el trabajo del controlador de búsqueda de tareas proxy.
- Quieres ampliar el espacio de búsqueda de tareas proxy más adelante (incluso después de muchos días).
En primer lugar, no canceles la tarea de iteración de NAS secundaria (pestaña NAS) si ya se está ejecutando. A continuación, para reanudar el trabajo del controlador de búsqueda de la tarea proxy principal, ejecuta el comando search_proxy_task como antes, pero esta vez pasa la marca --previous_proxy_task_search_dir y asígnala al directorio de salida del trabajo del controlador de búsqueda de la tarea proxy anterior. El trabajo del controlador de búsqueda de tareas de proxy reanudado carga su estado anterior del directorio y sigue funcionando como antes.
Comprobaciones finales
Las dos comprobaciones finales de tu tarea de proxy incluyen el intervalo de recompensas y el guardado de datos para el análisis posterior a la búsqueda.
Intervalo de recompensas
La recompensa comunicada al controlador debe estar en el intervalo [1e-3, 10]. Si no es así, puedes escalar artificialmente la recompensa para alcanzar este objetivo.
Guardar datos para analizarlos después de la búsqueda
El código de la tarea de proxy debe guardar las métricas y los datos adicionales en la ubicación de Cloud Storage, lo que puede ser útil para analizar el espacio de búsqueda más adelante. Nuestra plataforma de búsqueda con arquitectura neuronal solo admite que se registren hasta cinco other_metrics de coma flotante.
Las métricas adicionales deben guardarse en la ubicación de Cloud Storage para analizarlas más adelante.