Configura un entorno antes de iniciar un experimento de Vertex AI Neural Architecture Search.
Antes de empezar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Si utilizas un proveedor de identidades (IdP) externo, primero debes iniciar sesión en la CLI de gcloud con tu identidad federada.
-
Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init -
Después de inicializar gcloud CLI, actualízala e instala los componentes necesarios:
gcloud components update gcloud components install beta
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Si utilizas un proveedor de identidades (IdP) externo, primero debes iniciar sesión en la CLI de gcloud con tu identidad federada.
-
Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init -
Después de inicializar gcloud CLI, actualízala e instala los componentes necesarios:
gcloud components update gcloud components install beta
- Para conceder a todos los usuarios de Neural Architecture Search el rol Usuario de Vertex AI (
roles/aiplatform.user), ponte en contacto con el administrador de tu proyecto. - Instala Docker.
Si usas un sistema operativo basado en Linux, como Ubuntu o Debian, añade tu nombre de usuario al grupo
dockerpara poder ejecutar Docker sin usarsudo:sudo usermod -a -G docker ${USER}Puede que tengas que reiniciar el sistema después de añadirte al grupo
docker. - Abre Docker. Para asegurarte de que Docker se está ejecutando, ejecuta el siguiente comando de Docker, que devuelve la hora y la fecha actuales:
docker run busybox date
- Usa
gcloudcomo asistente de credenciales para Docker:gcloud auth configure-docker
-
(Opcional) Si quieres ejecutar el contenedor con una GPU de forma local, instala
nvidia-docker. -
Especifica un nombre para el nuevo contenedor. El nombre debe ser único en todos los segmentos de Cloud Storage.
BUCKET_NAME="YOUR_BUCKET_NAME"
Por ejemplo, usa el nombre de tu proyecto con
-vertexai-nasal final:PROJECT_ID="YOUR_PROJECT_ID" BUCKET_NAME=${PROJECT_ID}-vertexai-nas
-
Comprueba el nombre del segmento que has creado.
echo $BUCKET_NAME
-
Selecciona una región para tu contenedor y define una
REGIONvariable de entorno.Usa la misma región en la que tienes previsto ejecutar los trabajos de Neural Architecture Search.
Por ejemplo, el siguiente código crea
REGIONy le asigna el valorus-central1:REGION=us-central1
-
Crea el nuevo segmento:
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
- En Servicio, seleccione API de Vertex AI.
- En Región, selecciona la región por la que quieras filtrar.
- En Cuota, selecciona un nombre de acelerador cuyo prefijo sea Entrenamiento de modelo personalizado.
- En el caso de las GPUs V100, el valor es GPUs Nvidia V100 para entrenamiento de modelos personalizados por región.
- En el caso de las CPUs, el valor puede ser CPUs de entrenamiento de modelos personalizados para tipos de máquinas N1 o E2 por región. El número de la CPU representa la unidad de CPUs. Si quieres 8
highmem-16CPUs, solicita una cuota de 8 * 16 = 128 unidades de CPU. También debes introducir el valor que quieras para region.
Configura las variables de entorno básicas:
gcloud config set project PROJECT_ID gcloud auth login gcloud auth application-default loginConfigura la autenticación de Docker para tu registro de artefactos:
# example: REGION=europe-west4 gcloud auth configure-docker REGION-docker.pkg.dev(Opcional) Configura un entorno virtual de Python 3. Se recomienda usar Python 3, pero no es obligatorio:
sudo apt install python3-pip && \ pip3 install virtualenv && \ python3 -m venv --system-site-packages ~/./nas_venv && \ source ~/./nas_venv/bin/activateInstala bibliotecas adicionales:
pip install google-cloud-storage==2.6.0 pip install pyglove==0.1.0Crea una cuenta de servicio:
gcloud iam service-accounts create NAME \ --description=DESCRIPTION \ --display-name=DISPLAY_NAMEAsigna los roles
aiplatform.userystorage.objectAdmina la cuenta de servicio:gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:NAME@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/aiplatform.user gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:NAME@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/storage.objectAdminAbre una nueva terminal de Shell.
Ejecuta el comando de clonación de Git:
git clone https://github.com/google/vertex-ai-nas.git
Configurar un segmento de Cloud Storage
En esta sección se muestra cómo crear un nuevo contenedor. Puedes usar un segmento ya creado, pero debe estar en la misma región en la que ejecutes los trabajos de AI Platform. Además, si no forma parte del proyecto que estás usando para ejecutar Neural Architecture Search, debes conceder acceso explícitamente a las cuentas de servicio de Neural Architecture Search.
Solicitar cuota de dispositivos adicional para el proyecto
Los tutoriales usan aproximadamente cinco máquinas con CPU y no requieren ninguna cuota adicional. Después de completar los tutoriales, ejecuta tu trabajo de Neural Architecture Search.
La tarea de Neural Architecture Search entrena un lote de modelos en paralelo. Cada modelo entrenado corresponde a una prueba.
Consulta la sección sobre configuración de number-of-parallel-trials
para estimar la cantidad de CPUs y GPUs necesarias para una tarea de búsqueda.
Por ejemplo, si cada prueba usa 2 GPUs T4 y asignas number-of-parallel-trials a 20, necesitarás una cuota total de 40 GPUs T4 para una tarea de búsqueda. Además, si cada prueba usa highmem-16 CPUs, necesitarás 16 unidades de CPU por prueba, lo que supone 320 unidades de CPU para 20 pruebas paralelas.
Sin embargo, pedimos un mínimo de 10 cuotas de pruebas paralelas (o 20 cuotas de GPU).
La cuota inicial predeterminada de GPUs varía según la región y el tipo de GPU y suele ser 0, 6 o 12 para Tesla_T4, y 0 o 6 para Tesla_V100. La cuota inicial predeterminada de CPUs varía según la región y suele ser de 20, 450 o 2200.
Opcional: Si tienes previsto ejecutar varios trabajos de búsqueda en paralelo, aumenta el requisito de cuota. Solicitar una cuota no implica que se te cobre inmediatamente. Se te cobrará cuando ejecutes una tarea.
Si no tienes suficiente cuota e intentas iniciar un trabajo que necesita más recursos de los que tienes, no se iniciará y se mostrará un error similar al siguiente:
Exception: Starting job failed: {'code': 429, 'message': 'The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd', 'status': 'RESOURCE_EXHAUSTED', 'details': [{'@type': 'type.googleapis.com/google.rpc.DebugInfo', 'detail': '[ORIGINAL ERROR] generic::resource_exhausted: com.google.cloud.ai.platform.common.errors.AiPlatformException: code=RESOURCE_EXHAUSTED, message=The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd, cause=null [google.rpc.error_details_ext] { code: 8 message: "The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd" }'}]}
En algunos casos, si se inician varios trabajos para el mismo proyecto al mismo tiempo y la cuota no es suficiente para todos ellos, uno de los trabajos permanecerá en estado de cola y no empezará a entrenarse. En ese caso, cancela el trabajo en cola y solicita más cuota o espera a que finalice el trabajo anterior.
Puedes solicitar la cuota de dispositivos adicional en la página Cuotas.
Puede aplicar filtros para encontrar la cuota que quiera editar:

Una vez que hayas creado una solicitud de cuota, recibirás un Case number y correos de seguimiento sobre el estado de tu solicitud. La aprobación de una cuota de GPU puede tardar entre dos y cinco días hábiles. Por lo general, se tarda entre dos y tres días en aprobar una cuota de entre 20 y 30 GPUs, mientras que se pueden tardar cinco días hábiles en aprobar una cuota de aproximadamente 100 GPUs. La aprobación de una cuota de CPU puede tardar hasta dos días hábiles.
Sin embargo, si una región tiene una gran escasez de un tipo de GPU, no hay ninguna garantía, aunque la cuota solicitada sea pequeña.
En este caso, es posible que se te pida que elijas otra región u otro tipo de GPU. En general, es más fácil conseguir GPUs T4 que V100. Las GPUs T4 tardan más tiempo real, pero son más rentables.
Para obtener más información, consulta Solicitar un ajuste de cuota.
Configurar el registro de artefactos de un proyecto
Debes configurar un registro de artefactos para tu proyecto y la región en la que insertes tus imágenes de Docker.
Ve a la página Artifact Registry de tu proyecto. Si aún no lo has hecho, habilita la API de Artifact Registry en tu proyecto:
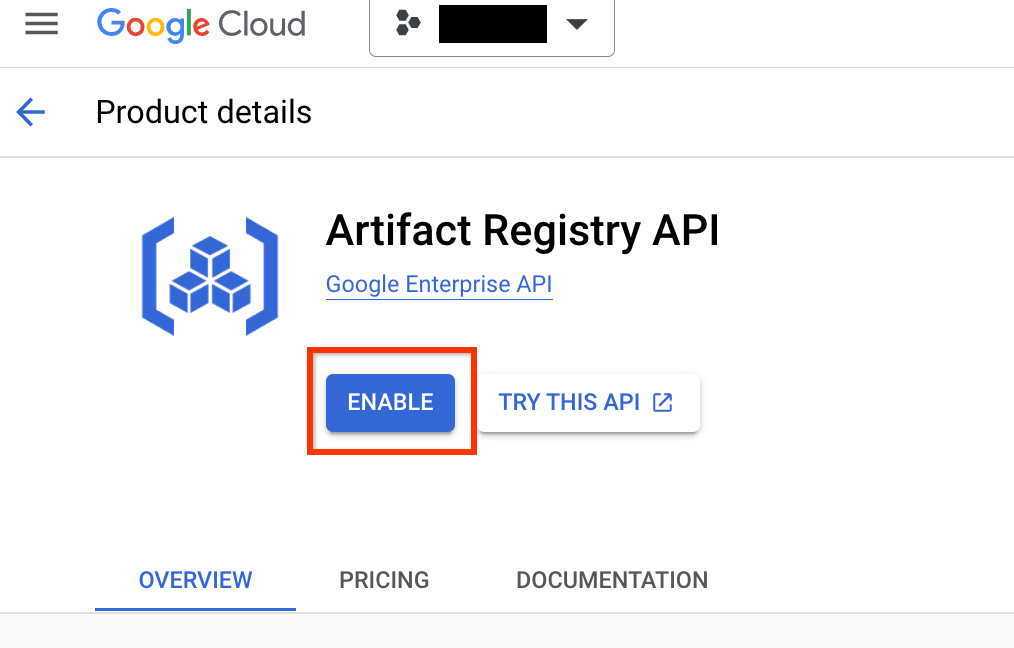
Una vez habilitada, empieza a crear un repositorio haciendo clic en CREAR REPOSITORIO:
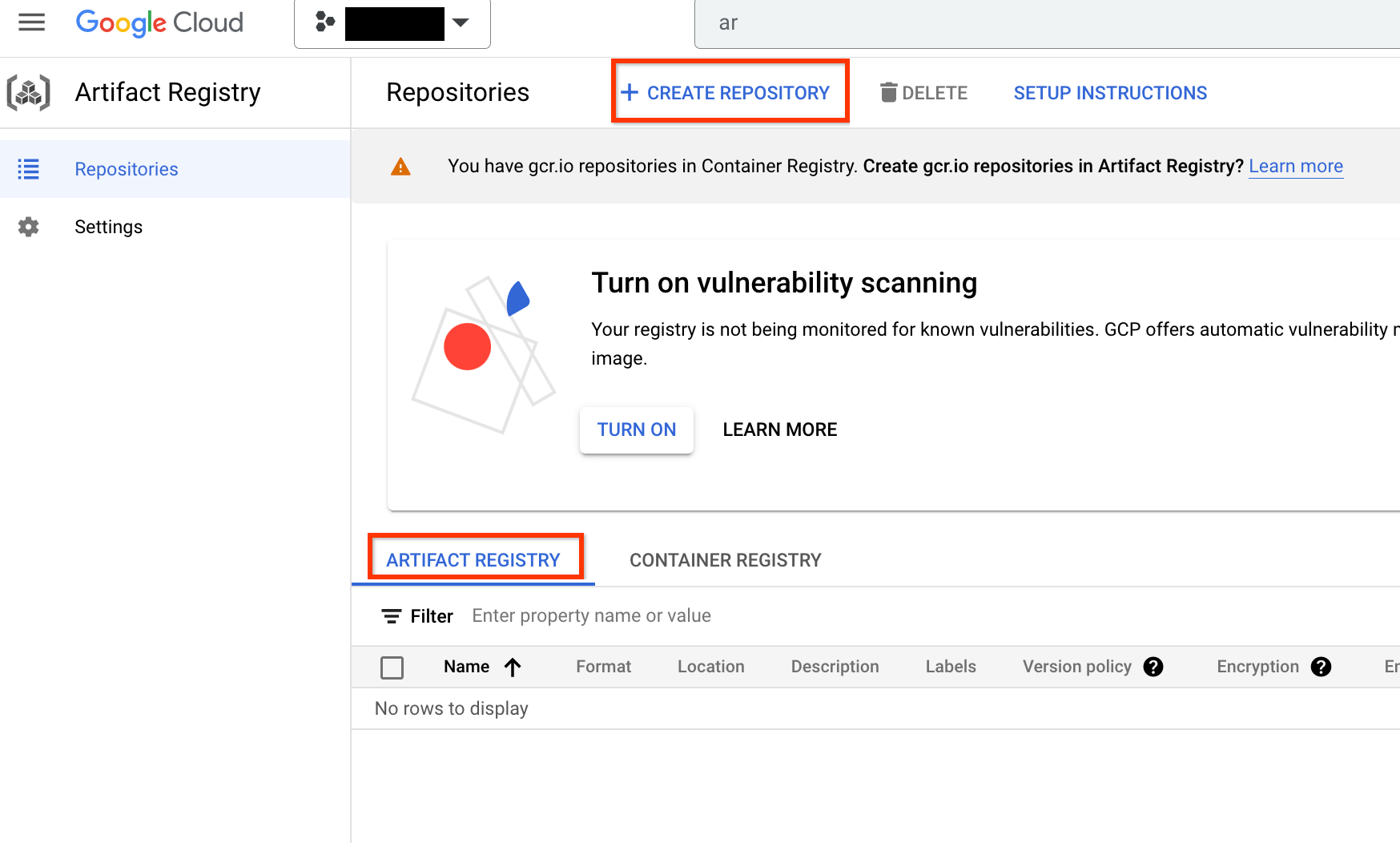
Elige Nombre como nas, Formato como Docker y Tipo de ubicación como Región. En Región, selecciona la ubicación en la que ejecutas los trabajos y, a continuación, haz clic en CREAR.
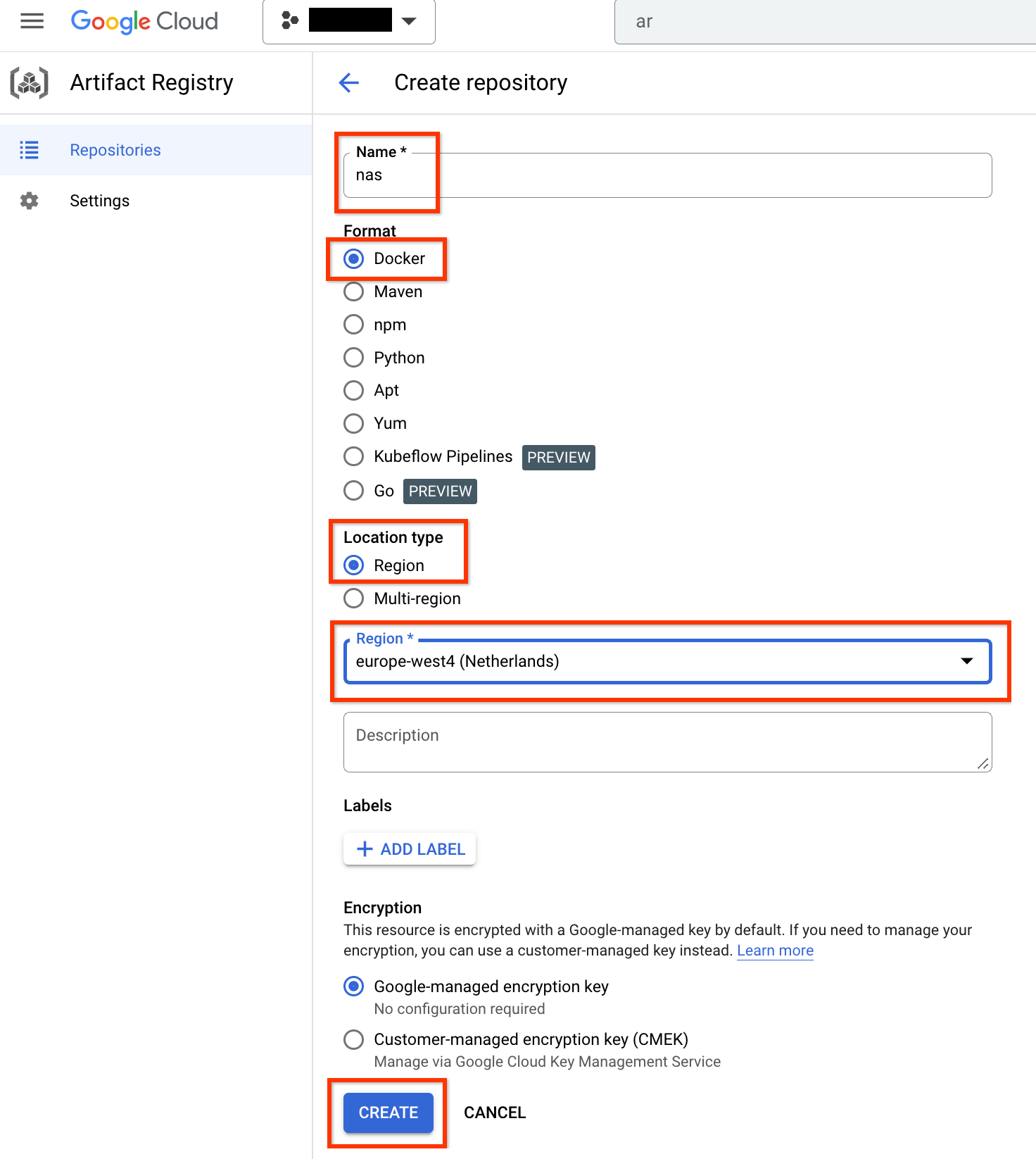
Debería crearse el repositorio de Docker que quieras, tal como se muestra a continuación:
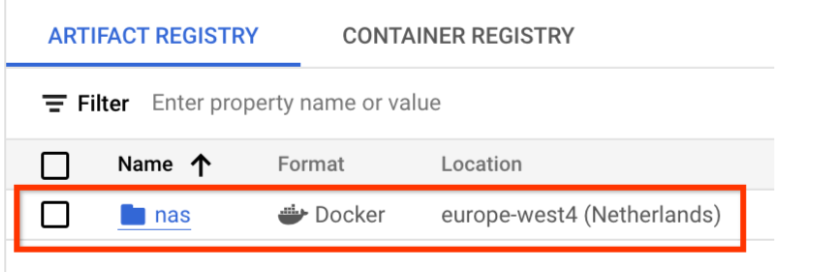
También debes configurar la autenticación para enviar dockers a este repositorio. Este paso se describe en la sección Configuración del entorno local que se muestra a continuación.
Configurar el entorno local
Puedes seguir estos pasos con el shell de Bash en tu entorno local o desde un cuaderno en una instancia de Vertex AI Workbench.
Configurar una cuenta de servicio
Debes configurar una cuenta de servicio antes de ejecutar trabajos de NAS. Puedes seguir estos pasos con el shell de Bash en tu entorno local o desde un cuaderno en una instancia de Vertex AI Workbench.
Por ejemplo, los siguientes comandos crean una cuenta de servicio llamada my-nas-sa
en el proyecto my-nas-project con los roles aiplatform.user y storage.objectAdmin:
gcloud iam service-accounts create my-nas-sa \
--description="Service account for NAS" \
--display-name="NAS service account"
gcloud projects add-iam-policy-binding my-nas-project \
--member=serviceAccount:my-nas-sa@my-nas-project.iam.gserviceaccount.com \
--role=roles/aiplatform.user
gcloud projects add-iam-policy-binding my-nas-project \
--member=serviceAccount:my-nas-sa@my-nas-project.iam.gserviceaccount.com \
--role=roles/storage.objectAdmin
Descargar código
Para iniciar un experimento de búsqueda con arquitectura neuronal, debes descargar el código de Python de ejemplo, que incluye entrenadores prediseñados, definiciones de espacio de búsqueda y bibliotecas de cliente asociadas.
Sigue estos pasos para descargar el código fuente.