Vertex AI 提供兩種方式,可使用訓練完成的預測模型預測未來值:線上推論和批次推論。
線上推論是同步要求。如要依據應用程式輸入內容發出要求,或是需要及時進行推論,您可以選用「線上推論」模式。
批次推論要求為非同步要求。如果您不需要立即取得回覆,並想透過單一要求處理累積的資料,即可使用這類工作。
本頁說明如何使用批次推論預測未來值。如要瞭解如何使用線上推論預測值,請參閱取得預測模型的線上推論結果。
您可以直接透過模型資源要求批次推論。
您可以要求提供附帶說明的推論結果 (也稱為特徵屬性),瞭解模型如何得出推論結果。本機特徵重要性值會顯示各項特徵對推論結果的影響程度。如需概念總覽,請參閱「預測功能屬性」。
如要瞭解批次推論的定價,請參閱「表格工作流程定價」。
事前準備
提出批次推論要求前,請先訓練模型。
輸入資料
批次推論要求的輸入資料是模型用來建立預測的資料。您可以透過下列其中一種格式來提供輸入資料:
- Cloud Storage 中的 CSV 物件
- BigQuery 資料表
建議您輸入資料的格式與訓練模型時使用的格式相同。舉例來說,如果您使用 BigQuery 中的資料訓練模型,最好使用 BigQuery 資料表做為批次推論的輸入。由於 Vertex AI 會將所有 CSV 輸入欄位視為字串,混合使用訓練和輸入資料格式可能會導致錯誤。
資料來源必須包含表格資料,其中包含用於訓練模型的所有欄 (順序不限)。您可以加入訓練資料中沒有的資料欄,或是訓練資料中有的資料欄,但排除在訓練用途之外。這些額外資料欄會納入輸出內容,但不會影響預測結果。
輸入資料規定
預測模型的輸入內容必須符合下列規定:
- 時間資料欄中的所有值都必須存在且有效。
- 推論要求中使用的所有資料欄都必須出現在輸入資料中。如果資料欄為空白或不存在,Vertex AI 會自動填補資料。
- 輸入資料和訓練資料的資料頻率必須相符。如果時間序列中缺少資料列,您必須根據適當的網域知識手動插入這些資料列。
- 系統會從推論中移除時間戳記重複的時間序列。如要納入這些時間戳記,請移除重複的時間戳記。
- 為要預測的每個時間序列提供歷來資料。如要取得最準確的預測結果,資料量應等於在模型訓練期間設定的內容視窗。舉例來說,如果內容視窗為 14 天,請提供至少 14 天的歷史資料。如果提供的資料較少, Vertex AI 會以空白值填補資料。
- 預測會從時間序列的第一列開始 (依時間排序),目標資料欄中會有空值。時間序列中的空值必須是連續的。舉例來說,如果目標資料欄是依時間排序,單一時間序列就不能出現
1、2、null、3、4、null、null等值。如果是 CSV 檔案,Vertex AI 會將空字串視為空值;如果是 BigQuery,則原生支援空值。
BigQuery 資料表
如果選擇 BigQuery 資料表做為輸入內容,請務必符合下列條件:
- BigQuery 資料來源資料表不得超過 100 GB。
- 如果資料表位於其他專案,您必須在該專案中將
BigQuery Data Editor角色授予 Vertex AI 服務帳戶。
CSV 檔案
如果選擇 Cloud Storage 中的 CSV 物件做為輸入內容,請務必確認下列事項:
- 資料來源開頭必須是包含欄名稱的標題列。
- 每個資料來源物件不得超過 10 GB。您可以加入多個檔案,容量上限為 100 GB。
- 如果 Cloud Storage 值區位於不同專案,則必須在該專案中,將
Storage Object Creator角色授予 Vertex AI 服務帳戶。 - 所有字串都必須以雙引號 (") 括住。
輸出格式
批次推論要求的輸出格式不一定要與輸入格式相同。舉例來說,如果您使用 BigQuery 資料表做為輸入內容,可以將預測結果輸出至 Cloud Storage 中的 CSV 物件。
向模型提出批次推論要求
如要提出批次推論要求,可以使用 Google Cloud 控制台或 Vertex AI API。輸入資料來源可以是儲存在 Cloud Storage bucket 中的 CSV 物件,也可以是 BigQuery 資料表。視您提交的輸入資料量而定,批次推論工作可能需要一些時間才能完成。
Google Cloud 控制台
使用 Google Cloud 控制台要求批次推論。
- 在 Google Cloud 控制台的 Vertex AI 專區中,前往「Batch inferences」(批次推論) 頁面。
- 按一下「建立」開啟「新批次推論」視窗。
- 如要「定義批次推論」,請完成下列步驟:
- 輸入批次推論的名稱。
- 在「模型名稱」部分,選取要用於這項批次推論的模型名稱。
- 在「版本」部分,選取模型版本。
- 在「選取來源」部分,選取來源輸入資料是 Cloud Storage 中的 CSV 檔案,還是 BigQuery 中的資料表。
- 如果是 CSV 檔案,請指定 CSV 輸入檔案所在的 Cloud Storage 位置。
- 如果是 BigQuery 資料表,請指定資料表所在的專案 ID、BigQuery 資料集 ID,以及 BigQuery 資料表或檢視區塊 ID。
- 在「Batch inference output」(批次推論輸出) 中,選取「CSV」或「BigQuery」。
- 如果是 CSV 檔案,請指定 Vertex AI 儲存輸出內容的 Cloud Storage bucket。
- 如果是 BigQuery,您可以指定專案 ID 或現有資料集:
- 如要指定專案 ID,請在「Google Cloud 專案 ID」欄位中輸入專案 ID。Vertex AI 會為您建立新的輸出資料集。
- 如要指定現有資料集,請在「Google Cloud 專案 ID」欄位中輸入 BigQuery 路徑,例如
bq://projectid.datasetid。
- 選填。如果輸出目的地是 BigQuery 或 Cloud Storage 上的 JSONL,除了推論結果,您也可以啟用特徵歸因。如要啟用這項功能,請選取「為這個模型啟用特徵歸因」。Cloud Storage 中的 CSV 檔案不支援特徵屬性。 瞭解詳情。
- 選用:模型監控
批次推論分析功能目前為預先發布版。如要將偏斜偵測設定新增至批次推論工作,請參閱「必要條件」。
- 按一下以開啟「為這項批次推論工作啟用模型監控功能」。
- 選取「訓練資料來源」。輸入所選訓練資料來源的資料路徑或位置。
- 選用:在「警告門檻」下方,指定觸發警告的門檻。
- 在「通知電子郵件」部分,輸入一或多個以半形逗號分隔的電子郵件地址,以便在模型超過快訊門檻時收到通知。
- 選用:如要新增通知管道,請新增 Cloud Monitoring 管道,以便在模型超過快訊門檻時收到通知。您可以選取現有的 Cloud Monitoring 管道,也可以按一下「管理通知管道」建立新管道。控制台支援 PagerDuty、Slack 和 Pub/Sub 通知管道。
- 點選「建立」。
API:BigQuery
REST
您可以使用 batchPredictionJobs.create 方法要求批次推論。
使用任何要求資料之前,請先替換以下項目:
- LOCATION_ID:儲存模型及執行批次推論工作的區域。例如:
us-central1。 - PROJECT_ID:您的專案 ID
- BATCH_JOB_NAME:批次作業的顯示名稱
- MODEL_ID:用於進行推論的模型 ID
-
INPUT_URI:BigQuery 資料來源的參照。在表單中:
bq://bqprojectId.bqDatasetId.bqTableId
-
OUTPUT_URI:BigQuery 目的地 (寫入推論結果的位置) 的參照。指定專案 ID,並視需要指定現有資料集 ID。請使用下列格式:
bq://bqprojectId.bqDatasetId
bq://bqprojectId
- GENERATE_EXPLANATION:預設值為 false。設為 true 即可啟用功能出處。詳情請參閱「預測功能的特徵歸因」。
HTTP 方法和網址:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
JSON 要求主體:
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": "OUTPUT_URI"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
如要傳送要求,請選擇以下其中一個選項:
curl
將要求主體儲存在名為 request.json 的檔案中,然後執行下列指令:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
將要求主體儲存在名為 request.json 的檔案中,然後執行下列指令:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
您應該會收到如下的 JSON 回應:
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "bigquery",
"bigquerySource": {
"inputUri": "INPUT_URI"
}
},
"outputConfig": {
"predictionsFormat": "bigquery",
"bigqueryDestination": {
"outputUri": bq://12345
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
},
"manualBatchTuningParameters": {
"batchSize": 4
},
"outputInfo": {
"bigqueryOutputDataset": "bq://12345.reg_model_2020_10_02_06_04
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Java
在試用這個範例之前,請先按照Java使用用戶端程式庫的 Vertex AI 快速入門中的操作說明進行設定。 詳情請參閱 Vertex AI Java API 參考說明文件。
如要向 Vertex AI 進行驗證,請設定應用程式預設憑證。 詳情請參閱「為本機開發環境設定驗證」。
在下列範例中,請將 INSTANCES_FORMAT 和 PREDICTIONS_FORMAT 替換為 `bigquery`。如要瞭解如何替換其他預留位置,請參閱本節的「REST 和 CMD LINE」分頁。Python
如要瞭解如何安裝或更新 Python 適用的 Vertex AI SDK,請參閱「安裝 Python 適用的 Vertex AI SDK」。 詳情請參閱 Python API 參考說明文件。
API:Cloud Storage
REST
您可以使用 batchPredictionJobs.create 方法要求批次推論。
使用任何要求資料之前,請先替換以下項目:
- LOCATION_ID:儲存模型及執行批次推論工作的區域。例如:
us-central1。 - PROJECT_ID:
- BATCH_JOB_NAME:批次作業的顯示名稱
- MODEL_ID:用於進行推論的模型 ID
-
URI:含有訓練資料的 Cloud Storage 值區路徑 (URI)。
可以有多個。每個 URI 的格式如下:
gs://bucketName/pathToFileName
-
OUTPUT_URI_PREFIX:Cloud Storage 目的地的路徑,推論結果會寫入該處。Vertex AI 會將批次推論寫入這個路徑中,以時間戳記命名的子目錄。將這個值設為下列格式的字串:
gs://bucketName/pathToOutputDirectory
- GENERATE_EXPLANATION:預設值為 false。設為 true 即可啟用功能出處。只有在輸出目的地為 JSONL 時,才能使用這個選項。 Cloud Storage 中的 CSV 檔案不支援特徵屬性。詳情請參閱「預測功能的特徵歸因」。
HTTP 方法和網址:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs
JSON 要求主體:
{
"displayName": "BATCH_JOB_NAME",
"model": "projects/PROJECT_ID/locations/LOCATION_ID/models/MODEL_ID",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
URI1,...
]
},
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"generate_explanation": GENERATE_EXPLANATION
}
如要傳送要求,請選擇以下其中一個選項:
curl
將要求主體儲存在名為 request.json 的檔案中,然後執行下列指令:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs"
PowerShell
將要求主體儲存在名為 request.json 的檔案中,然後執行下列指令:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs" | Select-Object -Expand Content
您應該會收到如下的 JSON 回應:
{
"name": "projects/PROJECT_ID/locations/LOCATION_ID/batchPredictionJobs/67890",
"displayName": "batch_job_1 202005291958",
"model": "projects/12345/locations/us-central1/models/5678",
"state": "JOB_STATE_PENDING",
"inputConfig": {
"instancesFormat": "csv",
"gcsSource": {
"uris": [
"gs://bp_bucket/reg_mode_test"
]
}
},
"outputConfig": {
"predictionsFormat": "csv",
"gcsDestination": {
"outputUriPrefix": "OUTPUT_URI_PREFIX"
}
},
"dedicatedResources": {
"machineSpec": {
"machineType": "n1-standard-32",
"acceleratorCount": "0"
},
"startingReplicaCount": 2,
"maxReplicaCount": 6
}
"outputInfo": {
"gcsOutputDataset": "OUTPUT_URI_PREFIX/prediction-batch_job_1 202005291958-2020-09-30T02:58:44.341643Z"
}
"state": "JOB_STATE_PENDING",
"createTime": "2020-09-30T02:58:44.341643Z",
"updateTime": "2020-09-30T02:58:44.341643Z",
}
Python
如要瞭解如何安裝或更新 Python 適用的 Vertex AI SDK,請參閱「安裝 Python 適用的 Vertex AI SDK」。 詳情請參閱 Python API 參考說明文件。
擷取批次推論結果
Vertex AI 會將批次推論的輸出內容傳送至您指定的目的地,可以是 BigQuery 或 Cloud Storage。
系統不支援特徵歸因的 Cloud Storage 輸出。
BigQuery
輸出資料集
如果您使用 BigQuery,批次推論的輸出內容會儲存在輸出資料集中。如果您已提供資料集給 Vertex AI,資料集名稱 (BQ_DATASET_NAME) 就是您先前提供的名稱。如果您未提供輸出資料集,Vertex AI 會為您建立一個。如要查看名稱 (BQ_DATASET_NAME),請按照下列步驟操作:
- 前往 Google Cloud 控制台的 Vertex AI「Batch inferences」(批次推論) 頁面。
- 選取您建立的推論。
-
輸出資料集位於「匯出位置」。資料集名稱的格式如下:
prediction_MODEL_NAME_TIMESTAMP
輸出資料表
輸出資料集包含下列一或多個輸出資料表:
-
推論表
這份資料表包含輸入資料中的每一列,其中要求了推論 (即 TARGET_COLUMN_NAME = null)。舉例來說,如果輸入內容包含目標資料欄的 14 個空值項目 (例如未來 14 天的銷售量),推論要求會傳回 14 個資料列,也就是每天的銷售量。如果推論要求超過模型的預測範圍,Vertex AI 只會傳回預測範圍內的推論結果。
-
錯誤驗證表格
這個表格的每個資料列,都代表在批次推論前匯總階段遇到的非重大錯誤。每個非重大錯誤都對應到輸入資料中的一列,Vertex AI 無法針對該列傳回預測結果。
-
錯誤表格
這個表格的每一列都代表批次推論期間發生的非重大錯誤。每個非重大錯誤都對應到輸入資料中的一列,Vertex AI 無法針對該列傳回預測資料。
預測表格
資料表名稱 (BQ_PREDICTIONS_TABLE_NAME) 的格式為 `predictions_`,後面加上批次推論工作開始時的時間戳記:predictions_TIMESTAMP
如要擷取推論資料表:
Vertex AI 會將推論結果儲存在 predicted_TARGET_COLUMN_NAME.value 欄中。
如果您使用時間融合轉換器 (TFT) 訓練模型,可以在 predicted_TARGET_COLUMN_NAME.tft_feature_importance 欄中找到 TFT 可解讀性輸出內容。
這個資料欄會再細分為下列項目:
context_columns:預測特徵,其內容視窗值會做為 TFT 長短期記憶 (LSTM) 編碼器的輸入。context_weights:與預測執行個體各項context_columns相關聯的特徵重要性權重。horizon_columns:預測特徵,其預測範圍值會做為 TFT 長短期記憶 (LSTM) 解碼器的輸入。horizon_weights:與預測執行個體各項horizon_columns相關聯的特徵重要性權重。attribute_columns:預測功能,與時間無關。attribute_weights:與每個attribute_columns相關聯的權重。
如果您的模型
已針對分位數損失進行最佳化,且分位數集包含中位數,則 predicted_TARGET_COLUMN_NAME.value 是中位數的推論值。否則,predicted_TARGET_COLUMN_NAME.value 是集合中最低分位數的推論值。舉例來說,如果您的分位數集為 [0.1, 0.5, 0.9],則 value 是分位數 0.5 的推論。如果分位數集為 [0.1, 0.9],則 value 是分位數 0.1 的推論。
此外,Vertex AI 會在下列資料欄中儲存分位數值和推論:
-
predicted_TARGET_COLUMN_NAME.quantile_values:分位數的值,是在模型訓練期間設定。例如0.1、0.5和0.9。 -
predicted_TARGET_COLUMN_NAME.quantile_predictions:與分位數值相關聯的推論值。
如果模型使用機率推論,predicted_TARGET_COLUMN_NAME.value 會包含最佳化目標的最小化器。舉例來說,如果最佳化目標是 minimize-rmse,則 predicted_TARGET_COLUMN_NAME.value 包含平均值。如果是 minimize-mae,predicted_TARGET_COLUMN_NAME.value 則包含中位數值。
如果模型使用機率推論和分位數,Vertex AI 會將分位數值和推論結果儲存在下列資料欄中:
-
predicted_TARGET_COLUMN_NAME.quantile_values:分位數的值,是在模型訓練期間設定。例如0.1、0.5和0.9。 -
predicted_TARGET_COLUMN_NAME.quantile_predictions:與分位數值相關聯的推論值。
如果您已啟用特徵歸因,也可以在推論表格中找到這些特徵。如要存取某項功能的出處資訊 BQ_FEATURE_NAME,請執行下列查詢:
SELECT explanation.attributions[OFFSET(0)].featureAttributions.BQ_FEATURE_NAME FROM BQ_DATASET_NAME.BQ_PREDICTIONS_TABLE_NAME
詳情請參閱「預測功能特徵歸因」。
錯誤驗證表
資料表名稱 (BQ_ERRORS_VALIDATION_TABLE_NAME) 是由 `errors_validation` 加上批次推論工作開始時間的時間戳記所組成:errors_validation_TIMESTAMP
-
前往控制台的「BigQuery」頁面。
前往 BigQuery -
執行下列查詢:
SELECT * FROM BQ_DATASET_NAME.BQ_ERRORS_VALIDATION_TABLE_NAME
- errors_TARGET_COLUMN_NAME
錯誤表格
資料表名稱 (BQ_ERRORS_TABLE_NAME) 是由 `errors_` 加上批次推論工作開始時間的時間戳記所組成:errors_TIMESTAMP
- errors_TARGET_COLUMN_NAME.code
- errors_TARGET_COLUMN_NAME.message
Cloud Storage
如果您指定 Cloud Storage 做為輸出目的地,批次推論要求的結果會以 CSV 物件的形式,傳回至您指定 bucket 中的新資料夾。資料夾名稱是模型名稱,前面加上「prediction-」,後面加上批次推論工作開始的時間戳記。您可以在模型的「批次預測」分頁中找到 Cloud Storage 資料夾名稱。
Cloud Storage 資料夾包含兩種物件:-
推論物件
推論物件的名稱為 `predictions_1.csv`、`predictions_2.csv` 等。其中包含含有資料欄名稱的標題列,以及每個傳回預測結果的資料列。推論值的數量取決於推論輸入和預測範圍。舉例來說,如果輸入內容包含目標資料欄的 14 個空值項目 (例如未來 14 天的銷售量),推論要求會傳回 14 個資料列,也就是每天的銷售量。如果推論要求超過模型的預測範圍,Vertex AI 只會傳回預測範圍內的推論結果。
預測值會以名為 `predicted_TARGET_COLUMN_NAME` 的資料欄傳回。如為分位數預測,輸出資料欄會以 JSON 格式包含分位數推論和分位數值。
-
錯誤物件
錯誤物件的名稱為 `errors_1.csv`、`errors_2.csv` 等。 其中包含標題列,以及輸入資料中 Vertex AI 無法傳回預測結果的每一列 (例如,如果不可為空值的特徵為空值)。
注意:如果結果很大,系統會將其拆分成多個物件。
BigQuery 中的特徵歸因查詢範例
範例 1:判斷單一推論的歸因
請思考以下問題:
在特定商店中,11 月 24 日的產品廣告預估銷售量增加了多少?
對應的查詢如下:
SELECT
* EXCEPT(explanation, predicted_sales),
ROUND(predicted_sales.value, 2) AS predicted_sales,
ROUND(
explanation.attributions[OFFSET(0)].featureAttributions.advertisement,
2
) AS attribution_advertisement
FROM
`project.dataset.predictions`
WHERE
product = 'product_0'
AND store = 'store_0'
AND date = '2019-11-24'
範例 2:判斷全域特徵重要性
請思考以下問題:
各項特徵對整體預測銷售量的影響程度為何?
您可以匯總本機特徵重要性歸因,手動計算全域特徵重要性。對應的查詢如下:
WITH
/*
* Aggregate from (id, date) level attributions to global feature importance.
*/
attributions_aggregated AS (
SELECT
SUM(ABS(attributions.featureAttributions.date)) AS date,
SUM(ABS(attributions.featureAttributions.advertisement)) AS advertisement,
SUM(ABS(attributions.featureAttributions.holiday)) AS holiday,
SUM(ABS(attributions.featureAttributions.sales)) AS sales,
SUM(ABS(attributions.featureAttributions.store)) AS store,
SUM(ABS(attributions.featureAttributions.product)) AS product,
FROM
project.dataset.predictions,
UNNEST(explanation.attributions) AS attributions
),
/*
* Calculate the normalization constant for global feature importance.
*/
attributions_aggregated_with_total AS (
SELECT
*,
date + advertisement + holiday + sales + store + product AS total
FROM
attributions_aggregated
)
/*
* Calculate the normalized global feature importance.
*/
SELECT
ROUND(date / total, 2) AS date,
ROUND(advertisement / total, 2) AS advertisement,
ROUND(holiday / total, 2) AS holiday,
ROUND(sales / total, 2) AS sales,
ROUND(store / total, 2) AS store,
ROUND(product / total, 2) AS product,
FROM
attributions_aggregated_with_total
BigQuery 中的批次推論輸出範例
以酒類銷售資料集為例,在「Ida Grove」市有四家商店:「Ida Grove Food Pride」、「Discount Liquors of Ida Grove」、「Casey's General Store #3757」和「Brew Ida Grove」。store_name 是 series identifier,而四間商店中有三間要求目標資料欄 sale_dollars 的推論結果。由於系統未要求「Discount Liquors of Ida Grove」的預測,因此產生驗證錯誤。
以下是推論所用輸入資料集的摘錄內容:
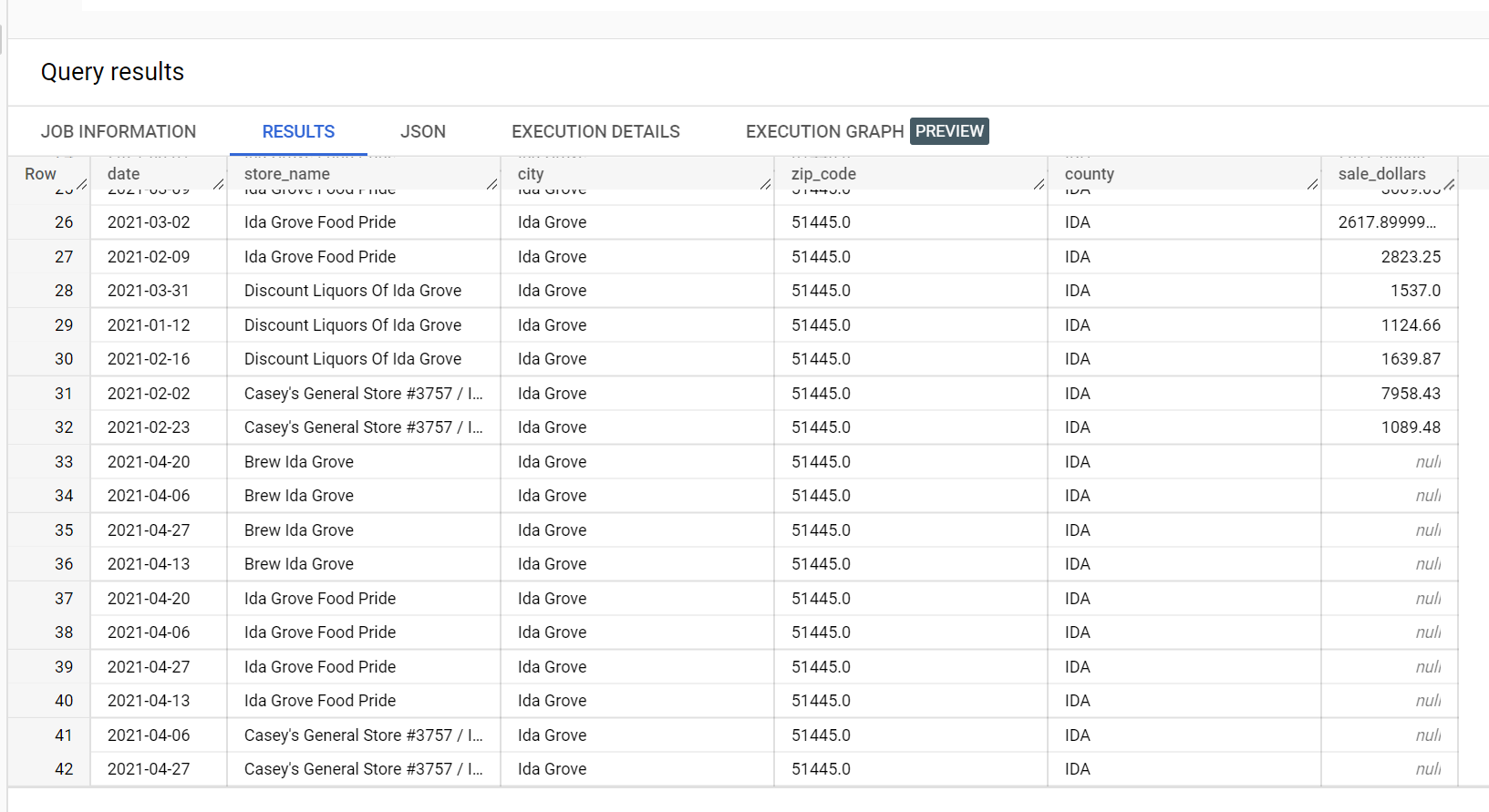
以下是推論結果的摘錄內容:

以下是驗證錯誤的摘錄內容:

針對分位數損失最佳化模型提供的批次推論輸出內容範例
以下範例是針對以分位數損失最佳化的模型,進行批次推論的輸出內容。在這個情境中,預測模型預測了每間商店未來 14 天的銷售額。
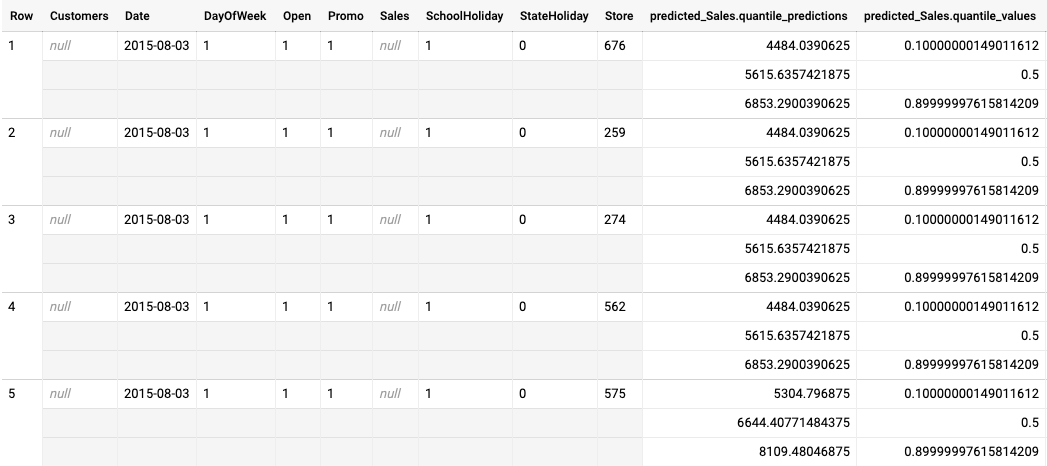
分位數值會顯示在 predicted_Sales.quantile_values 欄中。在本例中,模型預測了 0.1、0.5 和 0.9 分位數的值。
推論值會顯示在 predicted_Sales.quantile_predictions 欄中。
這是銷售價值陣列,會對應至 predicted_Sales.quantile_values 欄中的分位數值。在第一列中,我們看到銷售價值低於 4484.04 的機率為 10%。銷售額低於 5615.64 的機率為 50%。銷售價值低於 6853.29 的機率為 90%。第一列的推論結果以單一值表示,即 5615.64。
後續步驟
- 瞭解批次推論的定價。