In diesem Abschnitt werden Vertex AI-Dienste beschrieben, die Sie bei der Implementierung von Vorgängen für maschinelles Lernen (MLOps) mit Ihrem ML-Workflow unterstützen.
Nachdem Ihre Modelle bereitgestellt wurden, müssen sie mit den sich ändernden Daten aus der Umgebung Schritt halten, um eine optimale Leistung zu erzielen und relevant zu bleiben. MLOps bestehen aus einer Reihe von Verfahren, die die Stabilität und Zuverlässigkeit Ihrer ML-Systeme verbessern.
Vertex AI-MLOps-Tools unterstützen Sie bei der Zusammenarbeit von KI-Teams und bei der Verbesserung Ihrer Modelle durch Monitoring von Vorhersagemodellen, Benachrichtigungen, Diagnosen und praktisch nutzbare Erläuterungen. Alle Tools sind modular aufgebaut, sodass Sie sie nach Bedarf in Ihre vorhandenen Systeme einbinden können.
Weitere Informationen zu MLOps finden Sie unter Continuous Delivery und Pipelines zur Automatisierung beim maschinellen Lernen und im Leitfaden zu MLOps.
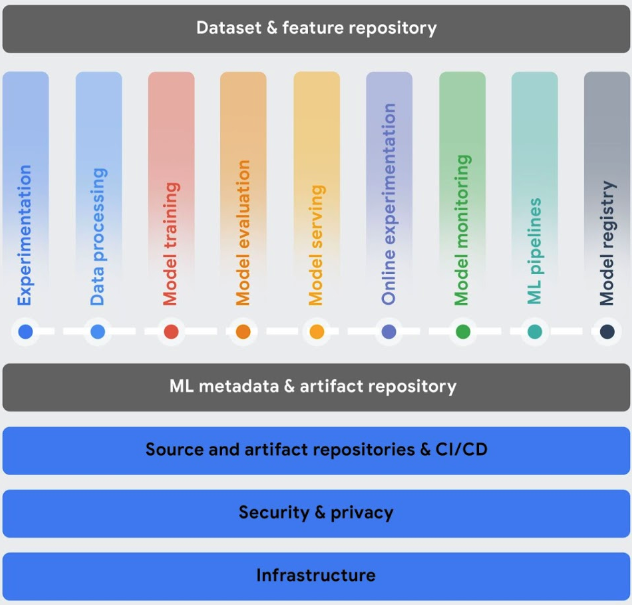
Workflows orchestrieren: Das manuelle Training und die Bereitstellung Ihrer Modelle kann zeitaufwendig und fehleranfällig sein, insbesondere wenn Sie die Prozesse oft wiederholen müssen.
- Vertex AI Pipelines hilft Ihnen, dabei Ihre ML-Workflows zu automatisieren, zu überwachen und zu steuern.
In Ihrem ML-System verwendete Metadaten verfolgen: In Data Science ist es wichtig, die in Ihrem ML-Workflow verwendeten Parameter, Artefakte und Messwerte zu verfolgen, insbesondere wenn Sie den Workflow oft wiederholen.
- Mit Vertex ML Metadata können Sie die Metadaten, Parameter und Artefakte aufzeichnen, die in Ihrem ML-System verwendet werden. Anschließend können Sie diese Metadaten abfragen, um die Leistung Ihres ML-Systems oder die davon generierten Artefakte zu analysieren, zu debuggen und zu prüfen.
Bestes Modell für einen Anwendungsfall identifizieren: Wenn Sie neue Trainingsalgorithmen ausprobieren, müssen Sie wissen, welches trainierte Modell die beste Leistung erzielt.
Mit Vertex AI Experiments können Sie verschiedene Modellarchitekturen, Hyperparameter und Trainingsumgebungen verfolgen und analysieren, um das beste Modell für Ihren Anwendungsfall zu ermitteln.
Mit Vertex AI TensorBoard können Sie ML-Tests verfolgen, visualisieren und vergleichen, um die Leistung Ihrer Modelle zu messen.
Modellversionen verwalten: Durch das Hinzufügen von Modellen zu einem zentralen Repository können Sie Modellversionen im Auge behalten.
- Vertex AI Model Registry bietet eine Übersicht über Ihre Modelle, sodass Sie neue Versionen besser organisieren, verfolgen und trainieren können. Mit Model Registry können Sie Modelle bewerten, Modelle an einem Endpunkt bereitstellen, Batchvorhersagen erstellen und Details zu bestimmten Modellen und Modellversionen aufrufen.
Features verwalten: Wenn Sie ML-Features über Teams hinweg wiederverwenden, benötigen Sie eine schnelle und effiziente Möglichkeit, die Features freizugeben und bereitzustellen.
- Vertex AI Feature Store bietet ein zentrales Repository zum Organisieren, Speichern und Bereitstellen von ML-Features. Durch die Verwendung eines zentralen Feature Store kann eine Organisation ML-Features in großem Maßstab wiederverwenden und die Geschwindigkeit der Entwicklung und Bereitstellung neuer ML-Anwendungen erhöhen.
Modellqualität überwachen: Ein in der Produktion bereitgestelltes Modell funktioniert am besten mit Vorhersageeingabedaten, die den Trainingsdaten ähneln. Wenn die Eingabedaten von den Daten abweichen, die zum Trainieren des Modells verwendet wurden, kann sich die Leistung des Modells verschlechtern, auch wenn sich das Modell selbst nicht geändert hat.
- Vertex AI Model Monitoring überwacht Modelle auf Abweichungen zwischen Training und Bereitstellung und auf Vorhersageabweichungen und sendet Ihnen Benachrichtigungen, wenn die eingehenden Vorhersagedaten zu weit von der Trainingsbasis abweichen. Sie können die Benachrichtigungen und Featureverteilungen verwenden, um zu bewerten, ob Sie Ihr Modell neu trainieren müssen.
KI- und Python-Anwendungen skalieren: Ray ist ein Open-Source-Framework zur Skalierung von KI- und Python-Anwendungen. Ray bietet die Infrastruktur für verteiltes Computing und parallele Verarbeitung für Ihren ML-Workflow („maschinelles Lernen“).
- Ray in Vertex AI wurde so entwickelt, dass Sie denselben Open-Source-Ray-Code zum Schreiben von Programmen und Entwickeln von Anwendungen in Vertex AI mit minimalen Änderungen verwenden können. Anschließend können Sie die Einbindungen von Vertex AI in andere Google Cloud-Dienste wie Vertex AI-Vorhersagen und BigQuery als Teil Ihres ML-Workflows verwenden.