本頁提供 Vertex AI Model Monitoring 總覽。
監控總覽
您可以視需要或定期執行監控作業,追蹤表格模型的品質。如果您已設定快訊,Vertex AI Model Monitoring 會在指標超過指定門檻時通知您。
舉例來說,假設您有一個可預測顧客終身價值的模型。隨著顧客習慣改變,預測顧客支出的因素也會改變。因此,您先前用來訓練模型的特徵和特徵值,可能已不適合用於今天的推論。資料的這種偏差稱為漂移。
當偏差超過指定門檻時,Vertex AI Model Monitoring 會追蹤並發出快訊。接著重新評估或重新訓練模型,確保模型運作正常。
舉例來說,Vertex AI Model Monitoring 可以提供視覺化內容,如下圖所示,其中疊加了兩個資料集的兩張圖表。這項視覺化功能可讓您快速比較兩組資料,並查看差異。

Vertex AI Model Monitoring 版本
Vertex AI Model Monitoring 提供兩種服務:v2 和 v1。
Model Monitoring v2 為預先發布版,是最新推出的服務,可將所有監控工作與模型版本建立關聯。相較之下,Model Monitoring v1 已正式發布,並在 Vertex AI 端點上設定。
如需生產環境等級的支援,並想監控部署在 Vertex AI 端點上的模型,請使用 Model Monitoring v1。如要用於其他用途,請使用 Model Monitoring v2,這個版本不僅提供 Model Monitoring v1 的所有功能,還具備更多優勢。詳情請參閱各版本的總覽:
對於現有的 Model Monitoring v1 使用者,Model Monitoring v1 會維持原狀。您不需要遷移至 Model Monitoring v2。如要遷移,您可以同時使用這兩個版本,直到完全遷移至 Model Monitoring 第 2 版為止,避免在遷移期間出現監控落差。
模型監控 v2 總覽
設定模型監控並執行監控工作後,您可以使用 Model Monitoring v2 追蹤一段時間內的指標。您可以視需要執行監控工作,也可以設定排程。使用排定的執行作業時,模型監控功能會根據您定義的排程,自動執行監控工作。
監控目標
您監控的指標和門檻會對應至監控目標。 您可以為每個模型版本指定一或多個監控目標。下表詳細列出各項目標:
| 目標 | 說明 | 特徵資料類型 | 支援的指標 |
|---|---|---|---|
| 輸入特徵資料偏移 |
評估輸入特徵值分布情形與基準資料分布情形的差異。 |
Categorical:布林值、字串、類別 |
|
| 數值:浮點數、整數 | 詹森-香農散度 | ||
| 輸出推論資料偏移 |
測量模型推論資料分布情形與基準資料分布情形的比較結果。 |
Categorical:布林值、字串、類別 |
|
| 數值:浮點數、整數 | 詹森-香農散度 | ||
| 特徵歸因 |
與基準相比,評估特徵對模型推論的貢獻度變化。舉例來說,您可以追蹤重要性極高的特徵是否突然下降。 |
所有資料類型 | SHAP 值 (SHapley Additive exPlanations) |
輸入特徵和輸出推論偏移
模型部署到正式環境後,輸入資料可能會與模型訓練資料不同,或正式環境的特徵資料分布情況可能會隨時間大幅變動。模型監控 V2 可監控正式環境資料分布與訓練資料的比較結果,或追蹤正式環境資料分布隨時間的演變。
同樣地,對於推論資料,模型監控 v2 可以監控預測結果的分布情形與訓練資料或實際運作資料分布情形相比,隨時間的變化。
特徵歸因
特徵歸因會指出模型中的各項特徵對每個指定執行個體推論結果的影響程度。歸因分數與特徵對模型推論的影響力成正比。通常會標示正負號,指出特徵是否會推升或降低推論結果。所有特徵的歸因加總必須等於模型的推論分數。
透過監控特徵歸因,Model Monitoring v2 可追蹤特徵對模型推論的貢獻度隨時間的變化。如果重要特徵的歸因分數有所變化,通常表示特徵已變更,可能會影響模型推論的準確度。
如要進一步瞭解功能歸因和指標,請參閱「以功能為準的說明」和「取樣 Shapley 方法」。
如何設定模型監控第 2 版
您必須先在 Vertex AI Model Registry 中註冊模型。如果您在 Vertex AI 以外提供模型,則不需要上傳模型構件。接著建立模型監控器,並與模型版本建立關聯,然後定義模型結構。對於部分模型 (例如 AutoML 模型),系統會提供結構定義。
在模型監控器中,您可以選擇指定預設設定,例如監控目標、訓練資料集、監控輸出位置和通知設定。詳情請參閱「設定模型監控」。
建立模型監控器後,您可以視需要執行監控工作,或排定定期工作,持續監控模型。執行工作時,除非您提供其他監控設定,否則模型監控會使用模型監控器中設定的預設設定。舉例來說,如果您提供不同的監控目標或比較資料集,模型監控會使用工作的設定,而非模型監控器的預設設定。詳情請參閱「執行監控工作」。
定價
預先發布版期間,Model Monitoring v2 不會產生費用。您仍須支付其他服務的使用費,例如 Cloud Storage、BigQuery、Vertex AI 批次推論、Vertex Explainable AI 和 Cloud Logging。
筆記本教學課程
下列教學課程會示範如何使用 Vertex AI SDK for Python,為模型設定 Model Monitoring v2。
模型監控 v2:自訂模型批次推論工作
模型監控 v2:自訂模型線上推論
Model Monitoring v2:Vertex AI 外部模型
模型監控 v1 總覽
為維持模型效能,Model Monitoring v1 會監控模型的推論輸入資料,偵測特徵偏差和偏移情形:
當正式環境和模型訓練作業的特徵資料分布情況不同時,就會發生訓練/應用偏差。如果有原始訓練資料,可以啟用偏差偵測功能,監控模型是否出現訓練/應用偏差情形。
推論偏移:當正式環境的特徵資料分布情況隨時間大幅變動時,就會發生推論偏移。如果沒有原始訓練資料,可以啟用偏移偵測功能,監控輸入資料的變化趨勢。
您可以同時啟用偏差和偏移偵測功能。
模型監控 v1 支援類別和數值特徵的特徵偏差和偏移偵測:
類別特徵是受可能值數量限制的資料,通常會依據質性屬性分組。例如產品類型、國家/地區或顧客類型等類別。
數值特徵可以是任何數值資料。例如體重和身高。
當模型特徵的偏差或偏移超過您設定的快訊門檻時,模型監控 v1 會傳送電子郵件快訊給您。您也可以查看每個特徵的分布情形,評估是否需要重新訓練模型。
計算偏移
如要偵測 v1 的偏移情形,Vertex AI Model Monitoring 會使用 TensorFlow Data Validation (TFDV) 計算分布情形和距離分數。
計算基準統計分配:
如果是偏移偵測,基準是訓練資料中特徵值的統計分佈情況。
如果是偏移偵測,基準是過去在正式環境中觀察到的特徵值統計分佈情況。
系統會依下列方式計算類別和數值特徵的分佈:
如果是類別特徵,計算出的分布情況就是特徵每個可能值的例項數量或百分比。
如果是數值特徵,Vertex AI 模型監控功能會將可能的特徵值範圍劃分為等間隔,並計算每個間隔內的特徵值數量或百分比。
基準會在建立 Vertex AI Model Monitoring 工作時計算,只有在更新工作訓練資料集時才會重新計算。
計算在正式環境中看到的最新特徵值統計分布情況。
計算距離分數,比較正式版中最新特徵值的分布情形與基準分布情形:
如果是類別特徵,距離分數會使用 L-infinity 距離計算。
如果是數值特徵,距離分數會使用 Jensen-Shannon 散度計算。
當兩個統計分布之間的距離分數超過您指定的門檻時,Vertex AI Model Monitoring 會將異常狀況識別為偏斜或漂移。
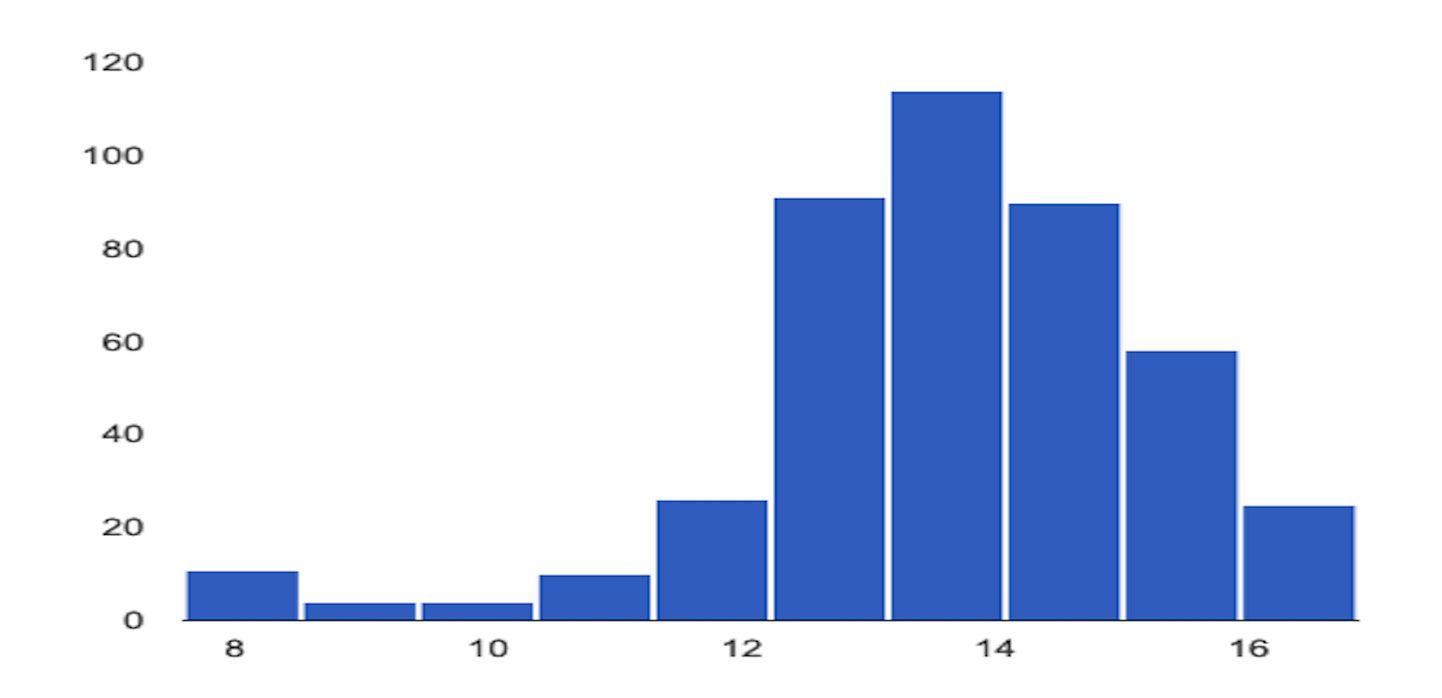
以下範例顯示類別特徵的基準和最新分配情形之間的偏斜或漂移:
基準分配

最新發布版本

以下範例顯示數值特徵的基準和最新分配情形之間的偏斜或漂移:
基準分配
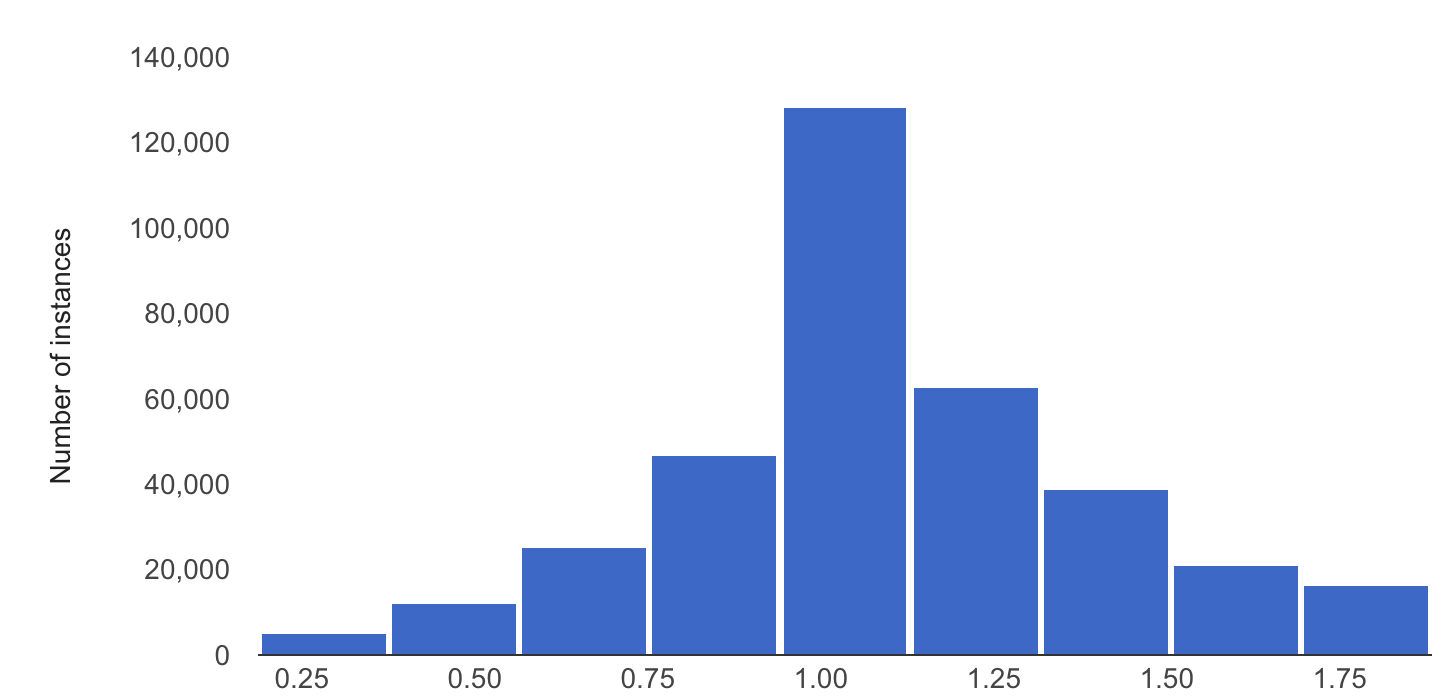
最新發布版本
使用模型監控的注意事項
為提高成本效益,您可以設定推論要求取樣率,監控模型的一小部分正式版輸入內容。
您可以設定頻率,監控已部署模型最近記錄的輸入內容是否出現偏差或偏移。監控頻率會決定每次監控執行作業分析記錄資料的時間範圍或監控時間範圍大小。
您可以為要監控的每項特徵指定快訊門檻。當輸入特徵分布情形與對應基準之間的統計距離超過指定門檻時,系統就會記錄警報。根據預設,系統會監控每個類別和數值特徵,門檻值為 0.3。
線上推論端點可代管多個模型。在端點上啟用偏差或偏移偵測功能時,該端點中託管的所有模型都會共用下列設定參數:
- 偵測類型
- 監控頻率
- 受監控的輸入要求比例
至於其他設定參數,您可以為每個模型設定不同的值。