Apigee hybrid pone a tu disposición datos de depuración, analíticas y estado de despliegue. Estos datos los recoge un pod de recogida de datos, que los envía al plano de gestión para que puedas verlos, analizarlos y configurar la monitorización y las alertas.
Acerca de los datos
Todos los servicios de Message Processor (MP) en la depuración de flujos híbridos (cuando se inicia), los análisis y los datos de estado de la implementación a través de TCP a un pod de recogida de datos del clúster. El pod de recogida de datos almacena los datos transmitidos en el sistema de archivos del pod a través de un servicio fluentd.
El agente de recogida de datos universal (UDCA) extrae periódicamente los datos almacenados y los envía al servicio de la plataforma de analíticas unificada (UAP) del plano de gestión. La UAP procesa los datos de analíticas y de estado de implementación entrantes y los pone a tu disposición a través de la interfaz de usuario híbrida o de las APIs de Apigee.
Apigee hybrid implementa el pod de recogida de datos como un ReplicaSet con un mínimo de dos réplicas.
En la siguiente imagen se muestra el proceso de recogida de datos de estado de depuración, analíticas y despliegue:
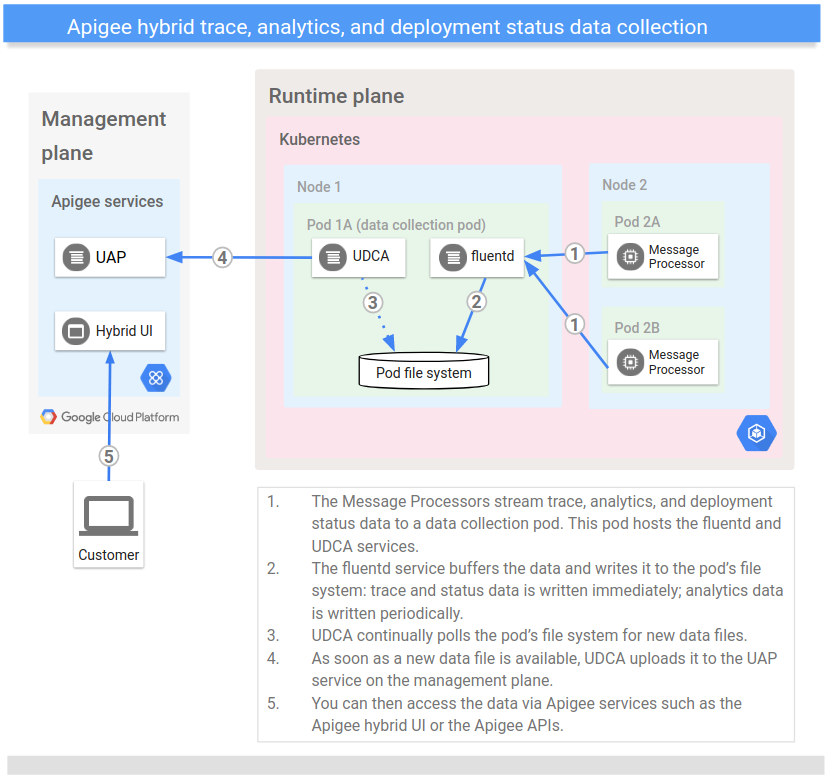
Ten en cuenta que los datos de estado de depuración, analíticas y despliegue no se almacenan en la misma ubicación ni se accede a ellos de la misma forma que a los datos de registro y métricas:
- Los datos de registros y métricas se almacenan en tu proyecto de Google Cloud y se accede a ellos a través de una herramienta como Cloud Operations o la que elijas.
- Por otro lado, los datos de depuración, analíticas y estado de implementación se almacenan en el plano de gestión híbrido y se accede a ellos a través de servicios de Apigee, como la interfaz de usuario híbrida o las APIs de Apigee.
En la siguiente tabla se resumen los datos recogidos por el pod de recogida de datos:
| Tipo de datos | Nombre del conjunto de datos | Descripción | Frecuencia de actualización | APIs |
|---|---|---|---|---|
| Analytics | api |
Datos de uso de la API, como las transacciones por segundo, el uso de la caché, los errores, las latencias, los tamaños de las solicitudes y las respuestas, y el número de tráfico.
Para obtener más información, consulta la descripción general de Apigee Analytics. |
Retraso de hasta 30 segundos | API Admin de Analytics |
| Estado del despliegue | event |
El estado de implementación actual del proxy de API.
Para obtener más información sobre cómo ver esta información, consulta Ver el estado de la implementación. |
Inmediatamente | API Deployments |
| Depurar | debug |
Depurar datos de sesión de proxies de APIs. Estos datos incluyen los parámetros de solicitud y respuesta, así como las transformaciones que se les aplican en el momento de la ejecución de la política. Debido a su tamaño, los datos de depuración, a diferencia de los datos de analíticas y de estado de la implementación, no se recogen todo el tiempo. En su lugar, los datos de depuración se recogen cuando inicias una sesión de depuración. Para obtener más información, consulta Introducción a la depuración. |
Inmediatamente | API de sesión de depuración API de datos de sesión de depuración |
Ver los datos en la interfaz de usuario híbrida
En esta sección se describe cómo ver los datos de estado de depuración, analíticas e implementación en la interfaz de usuario de Apigee hybrid.
Depurar
Se puede acceder a los datos de depuración de los servicios híbridos de la misma forma que a los datos de depuración de Edge, con algunas diferencias, como una mayor compatibilidad con los filtros. Para obtener más información, consulta Introducción a la depuración.
Analytics
Se puede acceder a los datos de Analytics de los servicios híbridos de la misma forma que a los datos de analíticas de Edge. Para obtener más información, consulta el artículo Usar los paneles de control de analíticas de la documentación de Edge.
Estado del despliegue del proxy
Para obtener información sobre cómo ver el estado de los despliegues, consulta Ver el estado de los despliegues.
Configurar la recogida de datos
Para definir cómo y dónde se recogen los datos de depuración, analíticas y estado de la implementación en el pod de recogida de datos, debe configurar el servicio UDCA mediante sus propiedades de configuración. Las propiedades de UDCA incluyen propiedades generales de UDCA, así como propiedades específicas de cada conjunto de datos.
Para configurar la UDCA, haz lo siguiente:
- Abre el archivo
overrides.yamlpara editarlo en tu máquina de administración de Kubernetes, tal como se describe en Gestionar componentes del plano de ejecución. - Define los valores de los ajustes de configuración de UDCA. En el UDCA, puede definir valores personalizados para propiedades como las siguientes:
- Intervalo de sondeo
- Número de réplicas (mínimo y máximo)
- Porcentaje de CPU objetivo (que activa réplicas adicionales)
Para ver una lista completa de las propiedades de UDCA que puedes personalizar, consulta
udca. - Guarda los cambios en el archivo overrides.yaml.
- Aplica los cambios al clúster ejecutando el comando
apigeectl apply, tal como se muestra en el siguiente ejemplo:apigeectl apply -f my-overrides.yaml --org --env env-name
Para obtener más información sobre el comando
apply, consulta Aplica Hybrid a tu clúster.