Vertex AI provides a managed training service that enables you to operationalize large scale model training. You can use Vertex AI to run training applications based on any machine learning (ML) framework on Google Cloud infrastructure. For the following popular ML frameworks, Vertex AI also has integrated support that simplifies the preparation process for model training and serving:
This page explains the benefits of custom training on Vertex AI, the workflow involved, and the various training options that are available.
Vertex AI operationalizes training at scale
There are several challenges to operationalizing model training. These challenges include the time and cost needed to train models, the depth of skills required to manage the compute infrastructure, and the need to provide enterprise-level security. Vertex AI addresses these challenges while providing a host of other benefits.
Fully managed compute infrastructure
|
|
Model training on Vertex AI is a fully managed service that requires no administration of physical infrastructure. You can train ML models without the need to provision or manage servers. You only pay for the compute resources that you consume. Vertex AI also handles job logging, queuing, and monitoring. |
High-performance
|
|
Vertex AI training jobs are optimized for ML model training, which can provide faster performance than directly running your training application on a GKE cluster. You can also identify and debug performance bottlenecks in your training job by using Cloud Profiler. |
Distributed training
|
|
Reduction Server is an all-reduce algorithm in Vertex AI that can increase throughput and reduce latency of multi-node distributed training on NVIDIA graphics processing units (GPUs). This optimization helps reduce the time and cost of completing large training jobs. |
Hyperparameter optimization
|
|
Hyperparameter tuning jobs run multiple trials of your training application using different hyperparameter values. You specify a range of values to test and Vertex AI discovers the optimal values for your model within that range. |
Enterprise security
|
|
Vertex AI provides the following enterprise security features:
|
ML operations (MLOps) integrations
|
|
Vertex AI provides a suite of integrated MLOps tools and features that you can use for the following purposes:
|
Workflow for custom training
The following diagram shows a high-level overview of the custom training workflow on Vertex AI. The sections that follow describe each step in detail.
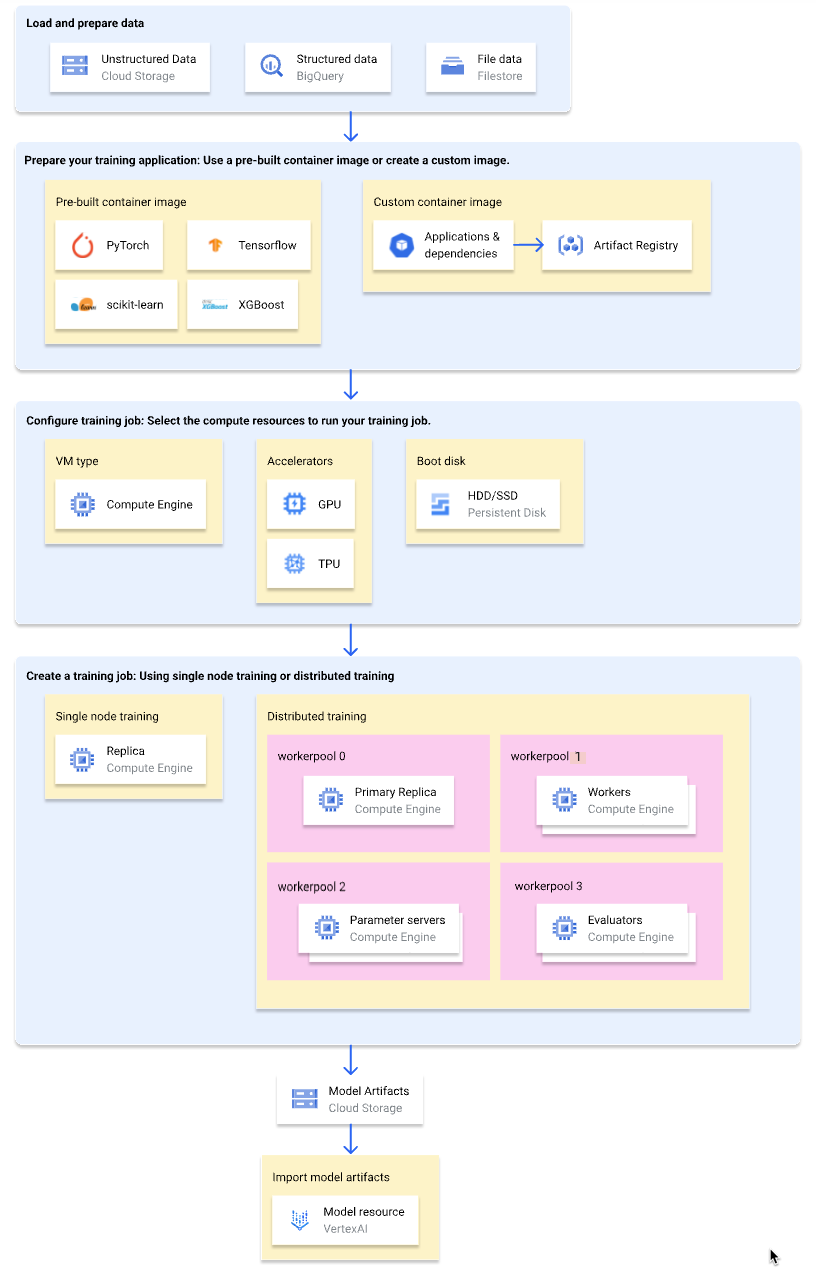
Load and prepare training data
For the best performance and support, use one of the following Google Cloud services as your data source:
You can also specify a Vertex AI managed dataset as the data source when using a training pipeline to train your model. Training a custom model and an AutoML model using the same dataset lets you compare the performance of the two models.
Prepare your training application
To prepare your training application for use on Vertex AI, do the following:
- Implement training code best practices for Vertex AI.
- Determine a type of container image to use.
- Package your training application into a supported format based on the selected container image type.
Implement training code best practices
Your training application should implement the training code best practices for Vertex AI. These best practices relate to the ability of your training application to do the following:
- Access Google Cloud services.
- Load input data.
- Enable autologging for experiment tracking.
- Export model artifacts.
- Use the environment variables of Vertex AI.
- Ensure resilience to VM restarts.
Select a container type
Vertex AI runs your training application in a Docker container image. A Docker container image is a self-contained software package that includes code and all dependencies, which can run in almost any computing environment. You can either specify the URI of a prebuilt container image to use, or create and upload a custom container image that has your training application and dependencies pre-installed.
The following table shows the differences between prebuilt and custom container images:
| Specifications | Prebuilt container images | Custom container images |
|---|---|---|
| ML framework | Each container image is specific to an ML framework. | Use any ML framework or use none. |
| ML framework version | Each container image is specific to an ML framework version. | Use any ML framework version, including minor versions and nightly builds. |
| Application dependencies | Common dependencies for the ML framework are pre-installed. You can specify additional dependencies to install in your training application. | Pre-install the dependencies that your training application needs. |
| Application delivery format |
|
Pre-install the training application in the custom container image. |
| Effort to set up | Low | High |
| Recommended for | Python training applications based on an ML framework and framework version that has a prebuilt container image available. |
|
Package your training application
After you've determined the type of container image to use, package your training application into one of the following formats based on the container image type:
Single Python file for use in a prebuilt container
Write your training application as a single Python file and use the Vertex AI SDK for Python to create a
CustomJoborCustomTrainingJobclass. The Python file is packaged into a Python source distribution and installed to a prebuilt container image. Delivering your training application as a single Python file is suitable for prototyping. For production training applications, you'll likely have your training application arranged into more than one file.Python source distribution for use in a prebuilt container
Package your training application into one or more Python source distributions and upload them to a Cloud Storage bucket. Vertex AI installs the source distributions to a prebuilt container image when you create a training job.
Custom container image
Create your own Docker container image that has your training application and dependencies pre-installed, and upload it to Artifact Registry. If your training application is written in Python, you can perform these steps by using one Google Cloud CLI command.
Configure training job
A Vertex AI training job performs the following tasks:
- Provisions one (single node training) or more (distributed training) virtual machines (VMs).
- Runs your containerized training application on the provisioned VMs.
- Deletes the VMs after the training job completes.
Vertex AI offers three types of training jobs for running your training application:
-
A custom job (
CustomJob) runs your training application. If you're using a prebuilt container image, model artifacts are output to the specified Cloud Storage bucket. For custom container images, your training application can also output model artifacts to other locations. -
A hyperparameter tuning job (
HyperparameterTuningJob) runs multiple trials of your training application using different hyperparameter values until it produces model artifacts with the optimal performing hyperparameter values. You specify the range of hyperparameter values to test and the metrics to optimize for. -
A training pipeline (
CustomTrainingJob) runs a custom job or hyperparameter tuning job and optionally exports the model artifacts to Vertex AI to create a model resource. You can specify a Vertex AI managed dataset as your data source.
When creating a training job, specify the compute resources to use for running your training application and configure your container settings.
Compute configurations
Specify the compute resources to use for a training job. Vertex AI supports single-node training, where the training job runs on one VM, and distributed training, where the training job runs on multiple VMs.
The compute resources that you can specify for your training job are as follows:
VM machine type
Different machine types offer different CPUs, memory size, and bandwidth.
Graphics processing units (GPUs)
You can add one or more GPUs to A2 or N1 type VMs. If your training application is designed to use GPUs, adding GPUs can significantly improve performance.
Tensor Processing Units (TPUs)
TPUs are designed specifically for accelerating machine learning workloads. When using a TPU VM for training, you can specify only one worker pool. That worker pool can have only one replica.
Boot disks
You can use SSDs (default) or HDDs for your boot disk. If your training application reads and writes to disk, using SSDs can improve performance. You can also specify the size of your boot disk based on the amount of temporary data that your training application writes to disk. Boot disks can have between 100 GiB (default) and 64,000 GiB. All VMs in a worker pool must use the same type and size of boot disk.
Container configurations
The container configurations that you need to make depend on whether you're using a prebuilt or custom container image.
Prebuilt container configurations:
- Specify the URI of the prebuilt container image that you want to use.
- If your training application is packaged as a Python source distribution, specify the Cloud Storage URI where the package is located.
- Specify the entry point module of your training application.
- Optional: Specify a list of command-line arguments to pass to the entry point module of your training application.
Custom container configurations:
- Specify the URI of your custom container image, which can be a URI from Artifact Registry or Docker Hub.
- Optional: Override the
ENTRYPOINTorCMDinstructions in your container image.
Create a training job
After your data and training application are prepared, run your training application by creating one of the following training jobs:
To create the training job, you can use the Google Cloud console, Google Cloud CLI, Vertex AI SDK for Python, or the Vertex AI API.
(Optional) Import model artifacts into Vertex AI
Your training application likely outputs one or more model artifacts to a specified location, usually a Cloud Storage bucket. Before you can get predictions in Vertex AI from your model artifacts, first import the model artifacts into Vertex AI Model Registry.
Like container images for training, Vertex AI gives you the choice of using prebuilt or custom container images for predictions. If a prebuilt container image for predictions is available for your ML framework and framework version, we recommend using a prebuilt container image.
What's next
- Get predictions from your model.
- Evaluate your model.
- Try the Hello custom training
tutorial for step-by-step instructions on training a TensorFlow Keras image
classification model on Vertex AI.