Búsqueda de vectores admite la búsqueda híbrida, un patrón de arquitectura popular en la recuperación de información (RI) que combina la búsqueda semántica y la búsqueda por palabras clave (también llamada búsqueda basada en tokens). Con la búsqueda híbrida, los desarrolladores pueden aprovechar las ventajas de ambos enfoques, lo que les permite ofrecer una mayor calidad de búsqueda.
En esta página se explican los conceptos de búsqueda híbrida, búsqueda semántica y búsqueda basada en tokens, y se incluyen ejemplos de cómo configurar la búsqueda basada en tokens y la búsqueda híbrida:
- ¿Por qué es importante la búsqueda híbrida?
- Ejemplo: cómo usar la búsqueda basada en tokens
- Ejemplo: Cómo usar la búsqueda híbrida
- Empezar a usar la búsqueda híbrida
- Conceptos adicionales
¿Por qué es importante la búsqueda híbrida?
Como se describe en el resumen de Vector Search, la búsqueda semántica con Vector Search puede encontrar elementos con similitud semántica mediante consultas.
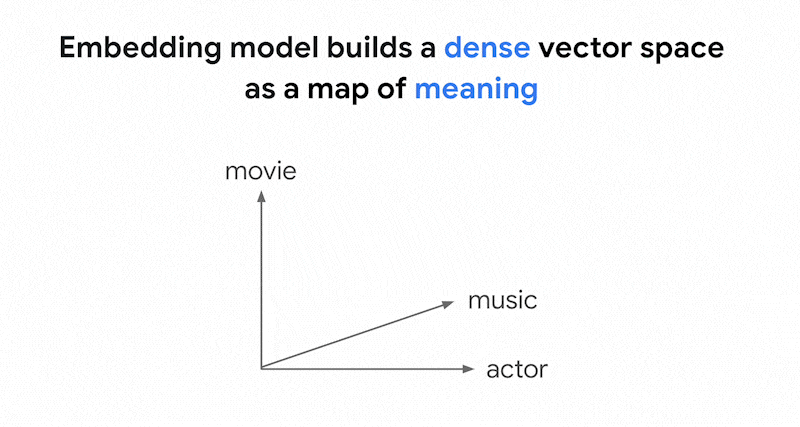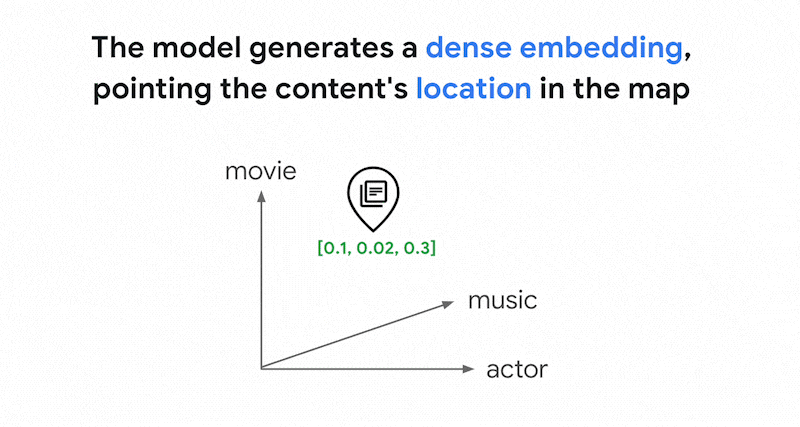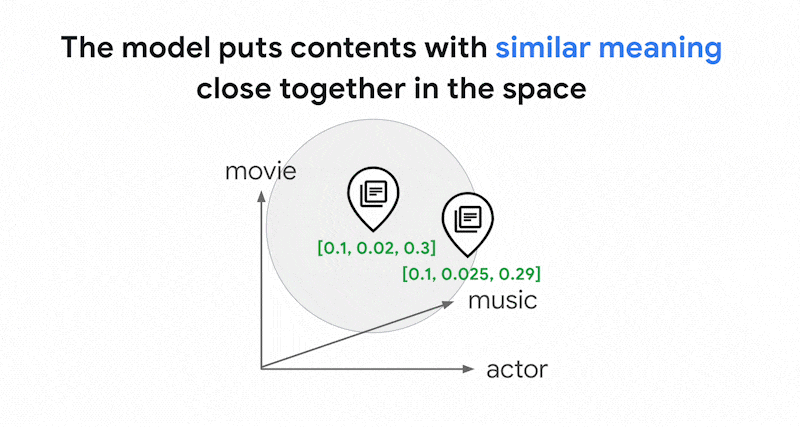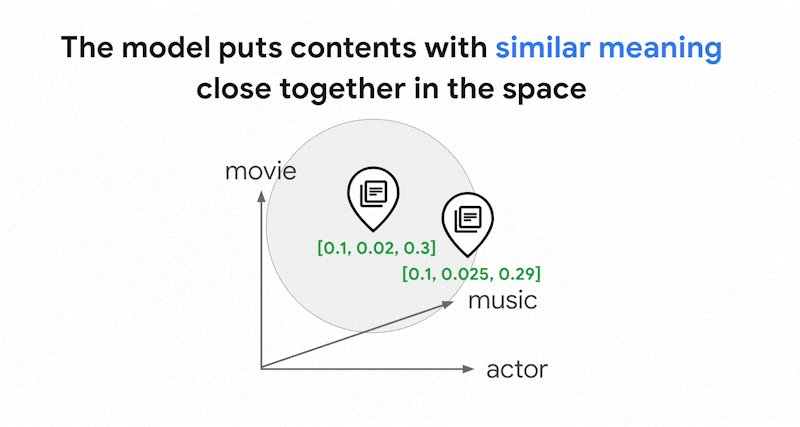
Los modelos de incrustaciones, como Vertex AI Embeddings, crean un espacio vectorial como mapa de significados de contenido. Cada inserción de texto o multimodal es una ubicación en el mapa que representa el significado de algún contenido. Por ejemplo, si un modelo de inserción toma un texto que habla de películas en un 10%, de música en un 2 % y de actores en un 30%, podría representar este texto con una inserción [0.1, 0.02,
0.3]. Con la búsqueda de vectores, puedes encontrar rápidamente otras incrustaciones en su vecindario. Esta búsqueda por el significado del contenido se denomina "búsqueda semántica".
La búsqueda semántica con inserciones y la búsqueda de vectores pueden ayudar a que los sistemas informáticos sean tan inteligentes como los bibliotecarios o el personal de las tiendas con experiencia. Las inserciones se pueden usar para vincular diferentes datos empresariales con sus significados; por ejemplo, consultas y resultados de búsqueda, textos e imágenes, actividades de los usuarios y productos recomendados, textos en inglés y textos en japonés, o datos de sensores y condiciones de alerta. Con esta función, las inserciones se pueden usar en una gran variedad de casos prácticos.
¿Por qué combinar la búsqueda semántica con la búsqueda basada en palabras clave?
La búsqueda semántica no abarca todos los requisitos posibles de las aplicaciones de recuperación de información, como la generación aumentada de recuperación (RAG). La búsqueda semántica solo puede encontrar datos que el modelo de inserción pueda interpretar. Por ejemplo, las consultas o los conjuntos de datos con números de producto o SKUs arbitrarios, nombres de producto nuevos que se hayan añadido recientemente y nombres en clave de propiedad corporativa no funcionan con la búsqueda semántica porque no se incluyen en el conjunto de datos de entrenamiento del modelo de inserción. Estos datos se denominan "fuera del dominio".
En estos casos, tendrías que combinar la búsqueda semántica con la búsqueda basada en palabras clave (también llamada búsqueda basada en tokens) para formar una búsqueda híbrida. Con la búsqueda híbrida, puedes aprovechar tanto la búsqueda semántica como la basada en tokens para conseguir una mayor calidad de búsqueda.
Uno de los sistemas de búsqueda híbridos más populares es la Búsqueda de Google. El servicio incorporó la búsqueda semántica en el 2015 con el modelo RankBrain, además de su algoritmo de búsqueda por palabras clave basado en tokens. Con la introducción de la búsqueda híbrida, la Búsqueda de Google pudo mejorar significativamente la calidad de las búsquedas al cumplir dos requisitos: buscar por significado y buscar por palabra clave.
Antes, crear un buscador híbrido era una tarea compleja. Al igual que con la Búsqueda de Google, tienes que crear y gestionar dos tipos diferentes de buscadores (búsqueda semántica y búsqueda basada en tokens), así como combinar y clasificar los resultados de ambos. Con la compatibilidad con la búsqueda híbrida en Vector Search, puedes crear tu propio sistema de búsqueda híbrida con un solo índice de Vector Search, personalizado según los requisitos de tu empresa.
Cómo funciona la búsqueda basada en tokens
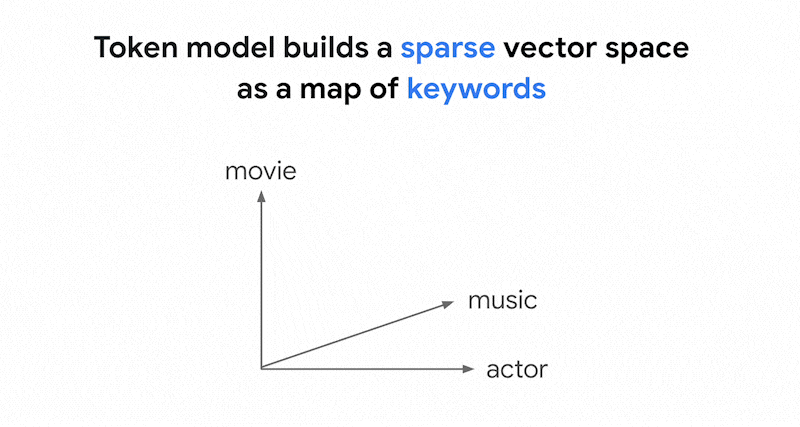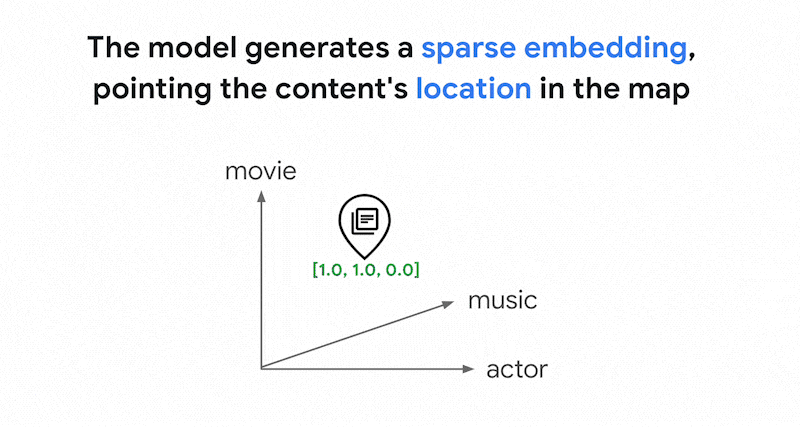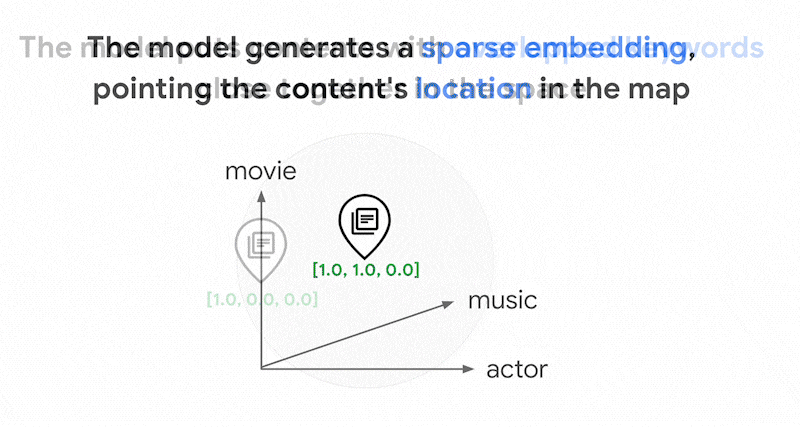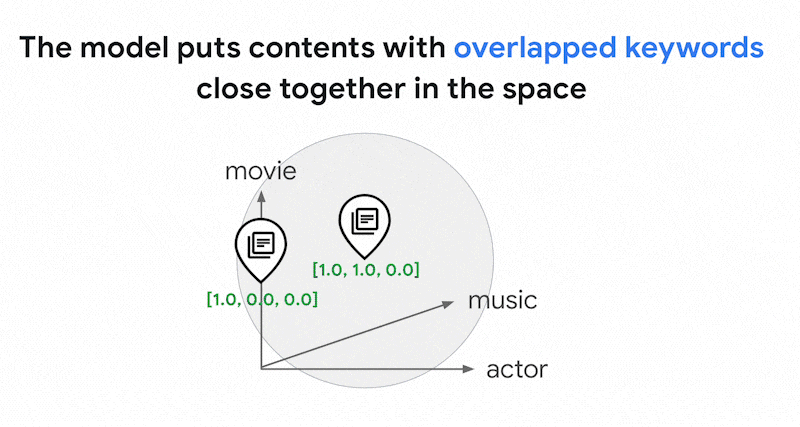
¿Cómo funciona la búsqueda basada en tokens en la búsqueda vectorial? Después de dividir el texto en tokens (como palabras o subpalabras), puedes usar algoritmos de inserción dispersa populares, como TF-IDF, BM25 o SPLADE, para generar una inserción dispersa del texto.
Una explicación simplificada de las inserciones dispersas es que son vectores que representan el número de veces que aparece cada palabra o subpalabra en el texto. Las inserciones dispersas típicas no tienen en cuenta la semántica del texto.

Podría haber miles de palabras diferentes en los textos. Por lo tanto, esta inserción suele tener decenas de miles de dimensiones, y solo unas pocas dimensiones tienen valores distintos de cero. Por eso se denominan "sparse" embeddings. La mayoría de sus valores son ceros. Este espacio de inserción disperso funciona como un mapa de palabras clave, similar a un índice de libros.
En este espacio de inserción disperso, puedes encontrar inserciones similares buscando la vecindad de una inserción de consulta. Estas inserciones son similares en cuanto a la distribución de las palabras clave usadas en sus textos.
Este es el mecanismo básico de la búsqueda basada en tokens con incrustaciones dispersas. Con la búsqueda híbrida de Vector Search, puedes combinar incrustaciones densas y dispersas en un solo índice vectorial y ejecutar consultas con incrustaciones densas, dispersas o ambas. El resultado es una combinación de búsqueda semántica y resultados de búsqueda basados en tokens.
La búsqueda híbrida también ofrece una latencia de consulta más baja que un buscador basado en tokens con un diseño de índice invertido. Al igual que la búsqueda de vectores para la búsqueda semántica, cada consulta con inserciones densas o dispersas se completa en milisegundos, incluso con millones o miles de millones de elementos.
Ejemplo: Cómo usar la búsqueda basada en tokens
Para explicar cómo usar la búsqueda basada en tokens, en las siguientes secciones se incluyen ejemplos de código que generan incrustaciones dispersas y crean un índice con ellas en la búsqueda de vectores.
Para probar este código de ejemplo, usa el cuaderno Combinación de búsqueda semántica y por palabras clave: tutorial de búsqueda híbrida con Vertex AI Vector Search.
El primer paso es preparar un archivo de datos para crear un índice de inserciones dispersas, basado en el formato de datos descrito en Formato y estructura de los datos de entrada.
En JSON, el archivo de datos tiene este aspecto:
{"id": "3", "sparse_embedding": {"values": [0.1, 0.2], "dimensions": [1, 4]}}
{"id": "4", "sparse_embedding": {"values": [-0.4, 0.2, -1.3], "dimensions": [10, 20, 30]}}
Cada elemento debe tener una propiedad sparse_embedding que tenga propiedades values y dimensions. Las inserciones dispersas tienen miles de dimensiones con algunos valores distintos de cero. Este formato de datos funciona de forma eficiente porque solo contiene los valores distintos de cero con sus posiciones en el espacio.
Preparar un conjunto de datos de muestra
Como conjunto de datos de muestra, usaremos el conjunto de datos Google Merch Shop, que tiene unas 200 filas de productos de la marca Google.
0 Google Sticker
1 Google Cloud Sticker
2 Android Black Pen
3 Google Ombre Lime Pen
4 For Everyone Eco Pen
...
197 Google Recycled Black Backpack
198 Google Cascades Unisex Zip Sweater
199 Google Cascades Womens Zip Sweater
200 Google Cloud Skyline Backpack
201 Google City Black Tote Backpack
Preparar un vectorizador TF-IDF
Con este conjunto de datos, entrenaremos un vectorizador, un modelo que genera inserciones dispersas a partir de un texto. En este ejemplo se usa TfidfVectorizer en scikit-learn, que es un vectorizador básico que usa el algoritmo TF-IDF.
from sklearn.feature_extraction.text import TfidfVectorizer
# Make a list of the item titles
corpus = df.title.tolist()
# Initialize TfidfVectorizer
vectorizer = TfidfVectorizer()
# Fit and Transform
vectorizer.fit_transform(corpus)
La variable corpus contiene una lista de 200 nombres de elementos, como "Google
Sticker" o "Chrome Dino Pin". A continuación, el código los transfiere al vectorizador llamando a la función fit_transform(). De esta forma, el vectorizador se prepara para generar incrustaciones dispersas.
El vectorizador TF-IDF intenta dar más peso a las palabras distintivas del conjunto de datos (como "Camisas" o "Dino") en comparación con las palabras triviales (como "El", "un" o "de") y cuenta cuántas veces se usan esas palabras distintivas en el documento especificado. Cada valor de una inserción dispersa representa la frecuencia de cada palabra en función de los recuentos. Para obtener más información sobre TF-IDF, consulta ¿Cómo funcionan TF-IDF y TfidfVectorizer?
En este ejemplo, usamos la tokenización básica a nivel de palabra y la vectorización TF-IDF para simplificar. En el desarrollo de producción, puedes elegir otras opciones de tokenización y vectorización para generar inserciones dispersas en función de tus requisitos. En el caso de los tokenizadores, en muchos casos, los tokenizadores de subpalabras funcionan bien en comparación con la tokenización a nivel de palabra y son opciones populares. En el caso de los vectorizadores, BM25 es una opción popular como versión mejorada de TF-IDF. SPLADE es otro algoritmo de vectorización popular que toma algunas semánticas para la inserción dispersa.
Obtener una inserción dispersa
Para que el vectorizador sea más fácil de usar con la búsqueda vectorial, definiremos una función de envoltorio, get_sparse_embedding():
def get_sparse_embedding(text):
# Transform Text into TF-IDF Sparse Vector
tfidf_vector = vectorizer.transform([text])
# Create Sparse Embedding for the New Text
values = []
dims = []
for i, tfidf_value in enumerate(tfidf_vector.data):
values.append(float(tfidf_value))
dims.append(int(tfidf_vector.indices[i]))
return {"values": values, "dimensions": dims}
Esta función transfiere el parámetro "text" al vectorizador para generar una inserción dispersa. A continuación, conviértelo al formato {"values": ...., "dimensions": ...} que hemos mencionado antes para crear un índice disperso de búsqueda vectorial.
Puedes probar esta función:
text_text = "Chrome Dino Pin"
get_sparse_embedding(text_text)
Debería mostrar la siguiente inserción dispersa:
{'values': [0.6756557405747007, 0.5212913389979028, 0.5212913389979028],
'dimensions': [157, 48, 33]}
Crear un archivo de datos de entrada
En este ejemplo, generaremos embeddings dispersos para los 200 elementos.
items = []
for i in range(len(df)):
id = i
title = df.title[i]
sparse_embedding = get_sparse_embedding(title)
items.append({"id": id, "title": title, "sparse_embedding": sparse_embedding})
Este código genera la siguiente línea para cada elemento:
{
'id': 0,
'title': 'Google Sticker',
'sparse_embedding': {
'values': [0.933008728540452, 0.359853737603667],
'dimensions': [191, 78]
}
}
A continuación, guárdalos como un archivo JSONL llamado "items.json" y súbelo a un segmento de Cloud Storage.
# output as a JSONL file and save to bucket
with open("items.json", "w") as f:
for item in items:
f.write(f"{item}\n")
! gcloud storage cp items.json $BUCKET_URI
Crear un índice de incrustaciones dispersas en Vector Search
A continuación, crearemos e implementaremos un índice de incrustación dispersa en la búsqueda de vectores. Este es el mismo procedimiento que se describe en la guía de inicio rápido de búsqueda vectorial.
# create Index
my_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name = f"vs-hybridsearch-index-{UID}",
contents_delta_uri = BUCKET_URI,
dimensions = 768,
approximate_neighbors_count = 10,
)
Para usar el índice, debes crear un endpoint de índice. Funciona como una instancia de servidor que acepta solicitudes de consulta para tu índice.
# create IndexEndpoint
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name = f"vs-quickstart-index-endpoint-{UID}",
public_endpoint_enabled = True
)
Con el endpoint de índice, despliega el índice especificando un ID de índice desplegado único.
DEPLOYED_INDEX_ID = f"vs_quickstart_deployed_{UID}"
# deploy the Index to the Index Endpoint
my_index_endpoint.deploy_index(
index = my_index, deployed_index_id = DEPLOYED_INDEX_ID
)
Después de esperar a que se complete la implementación, ya podemos ejecutar una consulta de prueba.
Ejecutar una consulta con un índice de inserciones dispersas
Para ejecutar una consulta con un índice de inserciones dispersas, debe crear un objeto HybridQuery
para encapsular la inserción dispersa del texto de la consulta, como en el siguiente ejemplo:
from google.cloud.aiplatform.matching_engine.matching_engine_index_endpoint import HybridQuery
# create HybridQuery
query_text = "Kids"
query_emb = get_sparse_embedding(query_text)
query = HybridQuery(
sparse_embedding_dimensions=query_emb['dimensions'],
sparse_embedding_values=query_emb['values'],
)
En este ejemplo de código se usa el texto "Kids" para la consulta. Ahora, ejecuta una consulta con el objeto HybridQuery.
# build a query request
response = my_index_endpoint.find_neighbors(
deployed_index_id=DEPLOYED_INDEX_ID,
queries=[query],
num_neighbors=5,
)
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
print(f"{title:<40}")
Debería obtener un resultado como el siguiente:
Google Blue Kids Sunglasses
Google Red Kids Sunglasses
YouTube Kids Coloring Pencils
YouTube Kids Character Sticker Sheet
De los 200 elementos, el resultado contiene los nombres de los elementos que tienen la palabra clave "Kids".
Ejemplo: cómo usar la búsqueda híbrida
En este ejemplo se combina la búsqueda basada en tokens con la búsqueda semántica para crear una búsqueda híbrida en Vector Search.
Cómo crear un índice híbrido
Para crear un índice híbrido, cada elemento debe tener tanto "embedding" (para la inserción densa) como "sparse_embedding":
items = []
for i in range(len(df)):
id = i
title = df.title[i]
dense_embedding = get_dense_embedding(title)
sparse_embedding = get_sparse_embedding(title)
items.append(
{"id": id, "title": title,
"embedding": dense_embedding,
"sparse_embedding": sparse_embedding,}
)
items[0]
La función get_dense_embedding() usa la API Vertex AI Embedding para generar embeddings de texto
con hasta 768 dimensiones. Ahora, las inserciones densas y dispersas se combinan en el siguiente formato:
{
"id": 0,
"title": "Google Sticker",
"embedding":
[0.022880317643284798,
-0.03315234184265137,
...
-0.03309667482972145,
0.04621824622154236],
"sparse_embedding": {
"values": [0.933008728540452, 0.359853737603667],
"dimensions": [191, 78]
}
}
El resto del proceso es el mismo que en el ejemplo de cómo usar la búsqueda basada en tokens: sube el archivo JSONL al segmento de Cloud Storage, crea un índice de búsqueda vectorial con el archivo y despliega el índice en el endpoint del índice.
Ejecutar una consulta híbrida
Después de implementar el índice híbrido, puedes ejecutar una consulta híbrida:
# create HybridQuery
query_text = "Kids"
query_dense_emb = get_dense_embedding(query_text)
query_sparse_emb = get_sparse_embedding(query_text)
query = HybridQuery(
dense_embedding=query_dense_emb,
sparse_embedding_dimensions=query_sparse_emb['dimensions'],
sparse_embedding_values=query_sparse_emb['values'],
rrf_ranking_alpha=0.5,
)
Para el texto de la consulta "Niños", genera representaciones densas y dispersas de la palabra y encapsúlalas en el objeto HybridQuery. La diferencia con el HybridQuery anterior es que se han añadido dos parámetros: dense_embedding y rrf_ranking_alpha.
Esta vez, imprimiremos las distancias de cada elemento:
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
dense_dist = neighbor.distance if neighbor.distance else 0.0
sparse_dist = neighbor.sparse_distance if neighbor.sparse_distance else 0.0
print(f"{title:<40}: dense_dist: {dense_dist:.3f}, sparse_dist: {sparse_dist:.3f}")
En cada objeto neighbor, hay una propiedad distance que tiene la distancia entre la consulta y el elemento con la inserción densa, y una propiedad sparse_distance que tiene la distancia con la inserción dispersa. Estos valores son distancias invertidas, por lo que un valor más alto significa una distancia más corta.
Si ejecutas una consulta con HybridQuery, obtendrás el siguiente resultado:
Google Blue Kids Sunglasses : dense_dist: 0.677, sparse_dist: 0.606
Google Red Kids Sunglasses : dense_dist: 0.665, sparse_dist: 0.572
YouTube Kids Coloring Pencils : dense_dist: 0.655, sparse_dist: 0.478
YouTube Kids Character Sticker Sheet : dense_dist: 0.644, sparse_dist: 0.468
Google White Classic Youth Tee : dense_dist: 0.645, sparse_dist: 0.000
Google Doogler Youth Tee : dense_dist: 0.639, sparse_dist: 0.000
Google Indigo Youth Tee : dense_dist: 0.637, sparse_dist: 0.000
Google Black Classic Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Chrome Dino Glow-in-the-Dark Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Google Bike Youth Tee : dense_dist: 0.629, sparse_dist: 0.000
Además de los resultados de búsqueda basados en tokens que tienen la palabra clave "Niños", también se incluyen resultados de búsqueda semántica. Por ejemplo, se incluye "Google White Classic Youth Tee" porque el modelo de inserción sabe que "Youth" y "Kids" son semánticamente similares.
Para combinar los resultados de la búsqueda semántica y la basada en tokens, la búsqueda híbrida usa Reciprocal Rank Fusion (RRF). Para obtener más información sobre RRF y cómo especificar el parámetro rrf_ranking_alpha, consulte ¿Qué es la fusión de rango recíproco?
Reclasificación
La fusión de clasificación recíproca proporciona una forma de combinar la clasificación de los resultados de búsqueda semántica y basada en tokens. En muchos sistemas de recuperación de información o recomendación de producción, los resultados se someterán a algoritmos de clasificación de precisión adicionales, lo que se conoce como "reranking". Gracias a la combinación de la recuperación rápida a nivel de milisegundo con la búsqueda vectorial y la reclasificación precisa de los resultados, puedes crear sistemas de varias fases que proporcionen una mayor calidad de búsqueda o un mejor rendimiento de las recomendaciones.
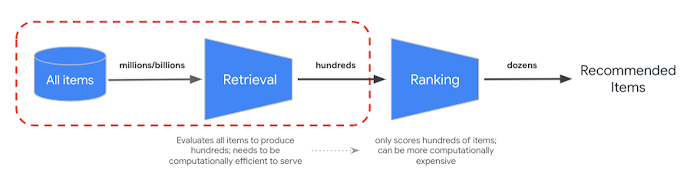
La API Vertex AI Ranking ofrece una forma de implementar la clasificación basada en la relevancia genérica entre el texto de la consulta y los textos de los resultados de búsqueda con el modelo preentrenado. TensorFlow Ranking también ofrece una introducción sobre cómo diseñar y entrenar modelos de aprendizaje para clasificar (LTR) para la reclasificación avanzada que se puede personalizar para diferentes requisitos empresariales.
Empezar a usar la búsqueda híbrida
Los siguientes recursos pueden ayudarte a empezar a usar la búsqueda híbrida en Vector Search.
Recursos de búsqueda híbrida
- Combinar la búsqueda semántica y por palabras clave: tutorial de búsqueda híbrida con Vertex AI Vector Search: cuaderno de ejemplo para empezar a usar la búsqueda híbrida
- Formato y estructura de los datos de entrada: formato de los datos de entrada para crear un índice de inserción disperso
- Consultar el índice público para obtener los vecinos más cercanos: cómo ejecutar consultas con la búsqueda híbrida
- La fusión de rangos recíprocos supera a Condorcet y a los métodos de aprendizaje de rangos individuales: análisis del algoritmo RRF
Recursos de Vector Search
Conceptos adicionales
En las siguientes secciones se describen con más detalle TF-IDF y TfidfVectorizer, Reciprocal Rank Fusion y el parámetro alfa.
¿Cómo funcionan TF-IDF y TfidfVectorizer?
La función fit_transform() ejecuta dos procesos importantes del algoritmo TF-IDF:
Ajustar: el vectorizador calcula la frecuencia inversa del documento (IDF) de cada término del vocabulario. La IDF refleja la importancia de un término en todo el corpus. Los términos poco frecuentes obtienen puntuaciones de IDF más altas:
IDF(t) = log_e(Total number of documents / Number of documents containing term t)Transformar:
- Tokenización: descompone los documentos en términos individuales (palabras o frases).
Cálculo de la frecuencia de los términos (TF): cuenta con qué frecuencia aparece cada término en cada documento con lo siguiente:
TF(t, d) = (Number of times term t appears in document d) / (Total number of terms in document d)Cálculo de TF-IDF: combina la TF de cada término con la IDF precalculada para crear una puntuación de TF-IDF. Esta puntuación representa la importancia de un término en un documento concreto en relación con todo el corpus.
TF-IDF(t, d) = TF(t, d) * IDF(t)El vectorizador TF-IDF intenta dar más peso a las palabras distintivas del conjunto de datos, como "Camisas" o "Dino", en comparación con las palabras triviales, como "El", "un" o "de", y cuenta cuántas veces se usan esas palabras distintivas en el documento especificado. Cada valor de una inserción dispersa representa la frecuencia de cada palabra en función de los recuentos.
¿Qué es la fusión de rangos recíprocos?
Para combinar los resultados de la búsqueda basada en tokens y de la búsqueda semántica, la búsqueda híbrida usa Reciprocal Rank Fusion (RRF). RRF es un algoritmo que combina varias listas de elementos ordenados en una única clasificación unificada. Es una técnica popular para combinar resultados de búsqueda de diferentes fuentes o métodos de recuperación, especialmente en sistemas de búsqueda híbridos y modelos de lenguaje extensos.
En el caso de la búsqueda híbrida de búsqueda vectorial, la distancia densa y la distancia dispersa se miden en espacios diferentes y no se pueden comparar directamente entre sí. Por lo tanto, RRF funciona de forma eficaz para combinar y clasificar los resultados de los dos espacios diferentes.
Así funciona la RRF:
- Rango recíproco: para cada elemento de una lista ordenada, calcula su rango recíproco. Es decir, se toma el inverso de la posición (rango) del elemento en la lista. Por ejemplo, el elemento que ocupa el primer puesto recibe un rango recíproco de 1/1 = 1, y el elemento que ocupa el segundo puesto recibe 1/2 = 0,5.
- Suma de los rangos recíprocos: suma los rangos recíprocos de cada elemento en todas las listas ordenadas. De este modo, se obtiene una puntuación final para cada elemento.
- Ordenar por puntuación final: ordena los elementos por su puntuación final en orden descendente. Los elementos con las puntuaciones más altas se consideran los más relevantes o importantes.
En resumen, los elementos con una clasificación más alta en los resultados densos y dispersos se mostrarán en la parte superior de la lista. Por lo tanto, el artículo "Google Blue Kids Sunglasses" (Gafas de sol azules para niños de Google) está en la parte superior, ya que tiene una clasificación más alta tanto en los resultados de búsqueda densos como en los dispersos. Los artículos como "Google White Classic Youth Tee" tienen una clasificación baja porque solo tienen clasificaciones en el resultado de búsqueda denso.
Cómo se comporta el parámetro alfa
En el ejemplo de cómo usar la búsqueda híbrida, se asigna el valor 0,5 al parámetro rrf_ranking_alpha
al crear el objeto HybridQuery. Puedes especificar una ponderación para clasificar los resultados de búsqueda densos y dispersos con los siguientes valores de rrf_ranking_alpha:
1o no especificado: la búsqueda híbrida solo usa resultados de búsqueda densos e ignora los resultados de búsqueda dispersos.0: la búsqueda híbrida solo usa resultados de búsqueda dispersos e ignora los resultados de búsqueda densos.0a1: la búsqueda híbrida combina los resultados de denso y disperso con el peso especificado por el valor. 0,5 significa que se combinarán con el mismo peso.