有了 Vertex AI Neural Architecture Search,您就能搜尋準確度、延遲、記憶體、以上三者組合或自訂指標的最佳神經架構。
判斷 Vertex AI 神經架構搜尋是否最適合我
- Vertex AI Neural Architecture Search 是一項高階最佳化工具,可用於找出準確度最高的神經架構,不論是否有延遲、記憶體或自訂指標等限制皆可。可能的神經架構選項搜尋空間可能會達到 10^20 的規模。這項技術在過去幾年已成功產生多個頂尖電腦視覺模型,包括 Nasnet、MNasnet、EfficientNet、NAS-FPN 和 SpineNet。
- 類神經架構搜尋並非解決方案,您無法只提供資料,就期待不經過實驗就能獲得良好結果。這是實驗工具。
- 神經架構搜尋不適用於超參數調整,例如調整學習率或最佳化工具設定。這項功能僅適用於架構搜尋。請勿將超參數調整與神經架構搜尋結合。
- 不建議在訓練資料有限的情況下,或在某些類別非常罕見的不平衡資料集中使用神經架構搜尋。如果您因資料不足,已為基準訓練使用大量擴增資料,則不建議使用神經架構搜尋。
- 建議您先嘗試其他傳統和常規的機器學習方法和技巧,例如超參數調整。只有在使用傳統方法後未能獲得更多效益時,才應使用類神經架構搜尋。
- 您應該有一個內部團隊負責模型微調,他們對架構參數有基本概念,可以修改及嘗試。這些架構參數可包括核數大小、管道數量或連線數量,以及其他可能的參數。如果您有要探索的搜尋空間,神經架構搜尋就非常實用,可在探索大型搜尋空間 (最多 10^20 個架構選項) 時,至少縮短約六個月的工程時間。
- 類神經架構搜尋功能適用於願意花費數千美元進行實驗的企業客戶。
- 神經架構搜尋不只限於視覺應用。目前只提供以視覺為基礎的預先建構搜尋空間和預先建構訓練器,但客戶也可以自行提供非視覺搜尋空間和訓練器。
- Neural Architecture Search 不會使用 supernet (oneshot-NAS 或以權重共用為基礎的 NAS) 方法,因為這類方法只會提供您自己的資料,並將其用作解決方案。自訂超級網域需要花費數月時間,與超級網路不同,神經架構搜尋可高度自訂,以定義自訂搜尋空間和獎勵。自訂服務大約需要一到兩天才能完成。
- 全球 8 個區域支援類神經架構搜尋。查看所在地區的供應情形。
使用神經架構搜尋前,也請參閱下列有關預期成本、結果增益和 GPU 配額需求的部分。
預期成本、成效提升和 GPU 配額需求

圖表顯示典型的神經架構搜尋曲線。Y-axis 會顯示試用獎勵,X-axis 則會顯示啟動的試用次數。隨著試驗次數增加,控制器就會開始尋找更優質的模型。因此,獎勵會開始增加,接著獎勵變化和獎勵成長會開始減少,並顯示收斂。在收斂點,試驗次數可能會因搜尋空間大小而異,但大約為 2000 次試驗。每個測試都是較小版本的完整訓練,稱為「proxy-task」,在兩個 Nvidia V100 GPU 上執行約一到兩小時。客戶可在任何時間點手動停止搜尋,並在收斂點出現前找到比基準更高的獎勵模型。建議您等到收斂點出現後再選擇較佳的結果。搜尋完成後,下一個階段是選出前 10 個試驗 (模型),並對這些試驗進行完整訓練。
(選用) 試用預先建構的 MNasNet 搜尋空間和訓練程式
在這個模式中,請觀察搜尋曲線或大約 25 次的試驗,並使用預先建構的 MNasNet 搜尋空間和訓練程式進行試驗。

在圖表中,最佳第 1 階段獎勵從試驗 1 的 ~0.30 開始攀升,到試驗 17 時達到 ~0.37。由於取樣是隨機的,因此實際執行的結果可能會有些許差異,但最佳獎勵應會略有增加。請注意,這仍是玩具測試,不代表任何概念驗證或公開基準測試驗證。
這次執行作業的費用明細如下:
- 階段 1:
- 試驗次數:25
- 每個試用方案的 GPU 數量:2
- GPU 類型:TESLA_T4
- 每個測試的 CPU 數量:1
- CPU 類型:n1-highmem-16
- 單一試驗訓練的平均時間:3 小時
- 並行測試數量:6
- 已使用的 GPU 配額:(每個測試的 GPU 數量 * 並行測試數量) = 12 個 GPU。請使用 us-central1 地區進行試駕,並在同一個地區中代管訓練資料。無需額外配額。
- 執行時間:(總試驗次數 * 每次試驗的訓練時間)/(並行試驗數量) = 12 小時
- GPU 時數:(總試驗次數 * 每個試驗的訓練時間 * 每個試驗的 GPU 數量) = 150 個 T4 GPU 時數
- CPU 時數:(總試驗次數 * 每個試驗的訓練時間 * 每個試驗的 CPU 數量) = 75 n1-highmem-16 小時
- 費用:約 $185 美元。您可以提早停止工作,以降低成本。如要計算確切價格,請參閱定價頁面。
由於這是玩具執行,因此不需要針對第 1 階段的模型執行完整的第 2 階段訓練。如要進一步瞭解如何執行第 2 階段,請參閱教學課程 3。
這次執行作業會使用 MnasNet 筆記本。
(選用) 執行預先建構的 MNasNet 搜尋空間和訓練程式,進行概念驗證 (PoC)
如果您想盡可能複製已發布的 MNasnet 結果,可以使用這個模式。根據論文指出,MnasNet 在 Pixel 手機上達到 75.2% 的最高準確率,延遲時間為 78 毫秒,比 MobileNetV2 快 1.8 倍,準確度高出 0.5%,比 NASNet 快 2.3 倍,準確度高出 1.2%。不過,這個範例會使用 GPU 而非 TPU 進行訓練,並使用雲端 CPU (n1-highmem-8) 評估延遲時間。在這個範例中,在雲端 CPU (n1-highmem-8) 上,MNasNet 的 Stage2 最高準確率為 75.2%,延遲時間為 50 毫秒。
這次執行作業的費用明細如下:
第 1 階段搜尋:
- 試驗次數:2000
- 每個試用方案的 GPU 數量:2
- GPU 類型:TESLA_T4
- 單一試驗訓練的平均時間:3 小時
- 並行測試數量:10
- 使用的 GPU 配額:(每個測試的 GPU 數量 * 並行測試數量) = 20 個 T4 GPU。由於這個數字超過預設配額,請透過專案 UI 建立配額要求。詳情請參閱 setting_up_path。
- 執行時間:(總試驗次數 * 每個試驗的訓練時間)/(並行試驗數量)/24 = 25 天。注意:工作會在 14 天後結束。在該期限過後,您可以使用單一指令輕鬆恢復搜尋作業,再執行 14 天。如果 GPU 配額較高,執行時間就會隨之減少。
- GPU 時數:(總試驗次數 * 每個試驗的訓練時間 * 每個試驗的 GPU 數量) = 12000 小時的 T4 GPU。
- 費用:約$15,000 美元
使用前 10 個模型進行第 2 階段完整訓練:
- 試驗次數:10
- 每個試用方案的 GPU 數量:4
- GPU 類型:TESLA_T4
- 單一試驗訓練的平均時間:約 9 天
- 並行測試數量:10
- 使用的 GPU 配額:(每個測試的 GPU 數量 * 並行測試數量) = 40 個 T4 GPU。由於這個數字高於預設配額,請透過專案 UI 建立配額要求。詳情請參閱 setting_up_path。您也可以使用 20 個 T4 GPU 執行這項作業,方法是執行兩次工作,每次執行五個模型,而不是同時執行所有 10 個模型。
- 執行時間:(總試驗次數 * 每個試驗的訓練時間)/(平行試驗次數)/24 = 約 9 天
- GPU 時數:(總試驗次數 * 每個試驗的訓練時間 * 每個試驗的 GPU 數量) = 8960 個 T4 GPU 時數。
- 費用:約$8,000 美元
總費用:約 $23,000 美元。如要計算確切價格,請參閱定價頁面。注意:這個範例不是一般訓練工作。完整訓練作業會在四個 TESLA_T4 GPU 上執行約九天。
這次執行作業會使用 MnasNet 筆記本。
使用搜尋空間和訓練程式
我們會提供一般自訂使用者的預估費用。您的需求可能會因訓練工作、使用的 GPU 和 CPU 而異。如這篇文章所述,您需要至少 20 個 GPU 配額才能進行端對端執行作業。注意:成效提升幅度完全取決於您的任務。我們只能提供 MNasnet 等範例,做為效能提升的參考範例。
這項假設的自訂執行作業的費用詳細資訊如下:
第 1 階段搜尋:
- 試驗次數:2,000 次
- 每個試用方案的 GPU 數量:2
- GPU 類型:TESLA_T4
- 單一試驗訓練的平均時間:1.5 小時
- 並行測試數量:10
- 使用的 GPU 配額:(每個測試的 GPU 數量 * 並行測試數量) = 20 個 T4 GPU。由於這個數字超過預設配額,您必須透過專案 UI 建立配額要求。詳情請參閱「為專案要求額外的裝置配額」。
- 執行時間:(總試驗次數 * 每個試驗的訓練時間)/(並行試驗數量)/24 = 12.5 天
- GPU 時數:(總試驗次數 * 每個試驗的訓練時間 * 每個試驗的 GPU 數量) = 6000 個 T4 GPU 時數。
- 費用:約 $7,400 美元
使用前 10 個模型進行第 2 階段完整訓練:
- 試驗次數:10
- 每個試用方案的 GPU 數量:2
- GPU 類型:TESLA_T4
- 單一試驗平均訓練時間:約 4 天
- 並行測試數量:10
- 使用的 GPU 配額:(每個測試的 GPU 數量 * 並行測試數量) = 20 個 T4 GPU。**由於這個數字超過預設配額,您必須透過專案 UI 建立配額要求。詳情請參閱「為專案要求額外的裝置配額」。請參閱相同的說明文件,瞭解自訂配額需求。
- 執行時間:(總試驗次數 * 每個試驗的訓練時間)/(並行試驗數量)/24 = 約 4 天
- GPU 時數:(總試驗次數 * 每個試驗的訓練時間 * 每個試驗的 GPU 數量) = 1920 個 T4 GPU 時數。
- 費用:約 $2,400 美元
如要進一步瞭解 Proxy 工作設計成本,請參閱「Proxy 工作設計」。成本與訓練 12 個模型相近 (圖中的第 2 個階段使用 10 個模型):
- 使用的 GPU 配額:與圖中的第 2 階段執行作業相同。
- 費用:(12/10) * 10 個模型的階段 2 費用 = 約$2,880 美元
總費用:約 $12,680 美元。如要計算確切價格,請參閱定價頁面。
這些第 1 階段搜尋成本是指搜尋作業,直到達到收斂點並獲得最佳成效增益為止。不過,請不要等到搜尋結果收斂後再進行。如果搜尋獎勵曲線開始上升,您可以使用目前最佳的模型執行第 2 階段完整訓練,預期成效提升幅度會較小,搜尋成本也會較低。舉例來說,針對前面顯示的搜尋圖表,請不要等到達到 2,000 次試驗才進行收斂。您可能會在 700 或 1,200 次試驗中找到更好的模型,並可針對這些模型執行第 2 階段的完整訓練。您隨時可以提早停止搜尋,以降低成本。您也可以在搜尋執行期間並行執行第 2 階段完整訓練,但請務必確保有足夠的 GPU 配額來支援額外並行工作。
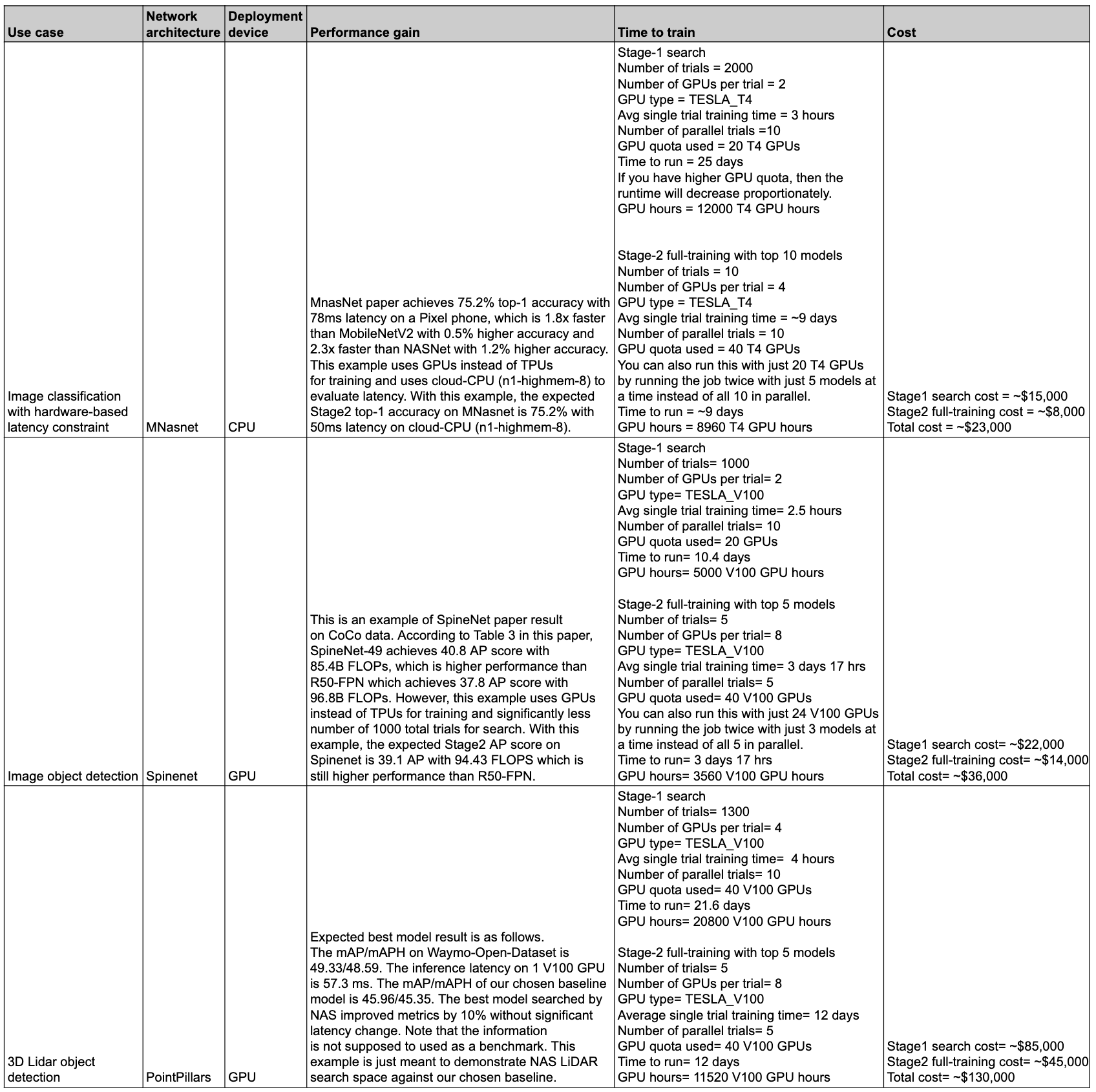
效能和成本摘要
下表列出一些資料點,說明不同用途以及相關成效和費用。
用途和功能
類神經架構搜尋功能既靈活又好用。新手使用者無須額外設定,即可使用預先建立的搜尋空間、預先建立的訓練程式和筆記本,開始探索 Vertex AI 神經架構搜尋功能,以便針對資料集進行探索。同時,專家使用者也可以將神經架構搜尋與自訂訓練器、自訂搜尋空間和自訂推論裝置搭配使用,甚至將架構搜尋擴展至非視覺應用程式。
神經架構搜尋提供預先建立的訓練程式和搜尋空間,可在 GPU 上執行下列用途:
- 使用公開資料集的 TensorFlow 訓練工具,在筆記本中發布結果
- 僅用於教學課程範例的 PyTorch 訓練器
- PyTorch 3D 醫學圖像區隔搜尋空間範例
- 以 PyTorch 為基礎的 MNasNet 分類
- 針對指定裝置的延遲和記憶體限制搜尋
- 其他以 Tensorflow 為基礎的預先建構先進搜尋空間,並附上程式碼
- 模型縮放
- 資料擴增
您可以輕鬆運用類神經架構搜尋提供的完整功能,針對自訂架構和用途進行調整:
- 神經架構搜尋語言,可針對可能的神經架構定義自訂搜尋空間,並將此搜尋空間與自訂訓練器程式碼整合。
- 可立即使用的預先建構先進搜尋空間,並附上程式碼。
- 隨時可用的預先建構訓練器,內含可在 GPU 上執行的程式碼。
- 這項代管服務可用於架構搜尋,包括
- 神經架構搜尋控制器,可對搜尋空間取樣,找出最佳架構。
- 預先建構的 Docker/程式庫,以及程式碼,可用於計算自訂硬體的延遲/FLOP/記憶體。
- 教學課程,教導使用 NAS。
- 一組設計 Proxy 工作所需的工具。
- 使用 Vertex AI 訓練 PyTorch 的效率指南和範例。
- 程式庫支援自訂指標報表和分析。
- Google Cloud 主控台 UI,可用於監控及管理工作。
- 輕鬆使用 Notebook 即可開始搜尋。
- 程式庫支援以專案或工作層級精細度管理 GPU/CPU 資源使用情形。
- 以 Python 為基礎的 Nas-client,可用於建構 Docker、啟動 NAS 工作,以及繼續執行先前的搜尋工作。
- Google Cloud 以控制台 UI 為基礎的客戶服務。
背景
神經架構搜尋是一種自動設計神經網路的技術。在過去幾年,它已成功產生多個最先進的電腦視覺模型,包括:
這些模型在所有 3 個主要類別的電腦視覺問題中都表現出色,包括圖片分類、物件偵測和區隔。
有了 Neural Architecture Search,工程師就能在同一個試驗中,針對準確度、延遲和記憶體最佳化模型,縮短部署模型所需的時間。神經架構搜尋會探索許多不同類型的模型:控制器會提出機器學習模型,然後訓練及評估模型,並重複執行 1, 000 次以上,以找出針對指定裝置的延遲和/或記憶體限制的最佳解決方案。下圖顯示架構搜尋架構的主要元件:

- 模型:包含運算和連結的神經架構。
- 搜尋空間:可設計及最佳化的可能模型 (作業和連結) 空間。
- Trainer docker:使用者可自訂訓練程式碼,訓練及評估模型,並計算模型的準確度。
- 推論裝置:CPU/GPU 等硬體裝置,用於計算模型的延遲時間和記憶體用量。
- 獎勵:結合多項模型指標 (例如準確率、延遲和記憶體),用於將模型分為優良等級。
- 神經架構搜尋控制器:這項協調演算法會 (a) 從搜尋空間中取樣模型、(b) 接收模型獎勵,以及 (c) 提供下一個模型建議集合,以便評估並找出最理想的模型。
使用者設定工作
類神經架構搜尋提供預先建立的訓練程式,可與預先建立的搜尋空間整合,方便您搭配提供的筆記本使用,無須額外設定。
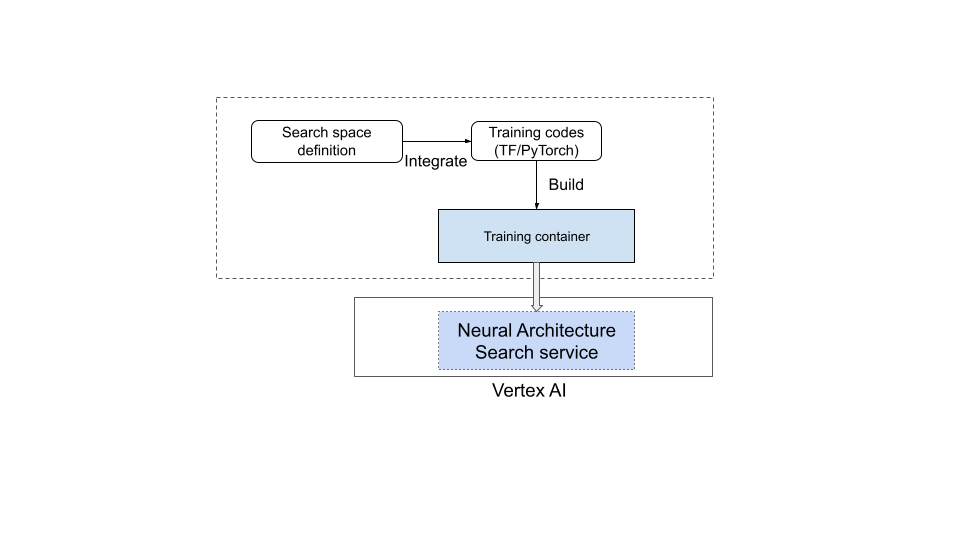
不過,大多數使用者都需要使用自訂訓練程式、自訂搜尋空間、自訂指標 (例如記憶體、延遲和訓練時間),以及自訂獎勵 (準確度和延遲等項目的組合)。如要這樣做,您需要:
- 使用提供的神經架構搜尋語言定義自訂搜尋空間。
- 將搜尋空間定義整合至訓練程式碼。
- 在訓練程式碼中新增自訂指標報表。
- 在訓練員程式碼中新增自訂獎勵。
- 建構訓練容器,並使用該容器啟動類神經架構搜尋工作。
下圖說明瞭這項做法:
正在運作的神經架構搜尋服務
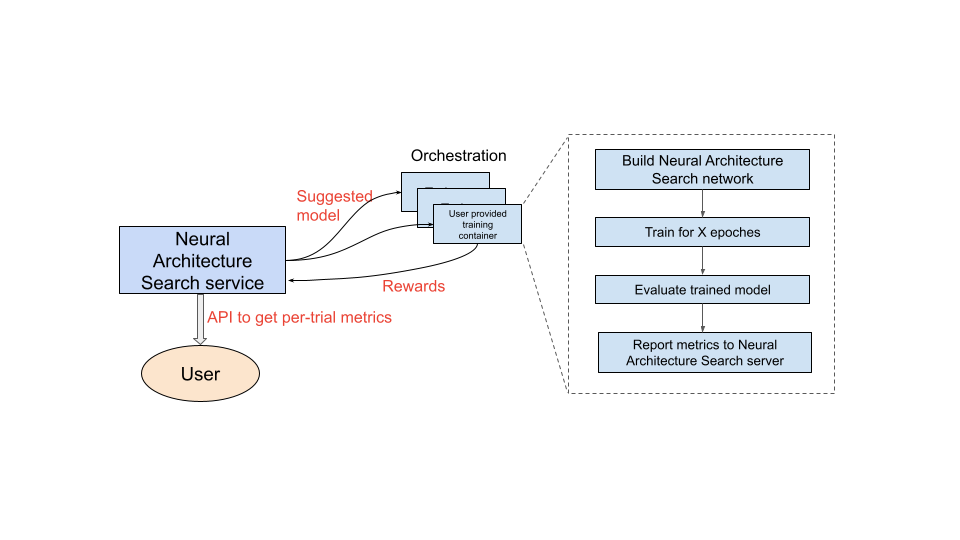
設定要使用的訓練容器後,神經架構搜尋服務就會在多個 GPU 裝置上並行啟動多個訓練容器。您可以控制要同時執行多少個訓練測試,以及要啟動的總測試數量。每個訓練容器都會從搜尋空間提供建議的架構。訓練容器會建構建議的模型、進行訓練/評估,然後將獎勵回報給神經架構搜尋服務。隨著這項程序的進行,神經架構搜尋服務會使用獎勵回饋來找出更優質的模型架構。搜尋完成後,您可以存取報表中的指標,以便進一步分析。
神經架構搜尋使用者歷程總覽
執行神經架構搜尋實驗的整體步驟如下:
設定和定義:
- 找出已標記的資料集,並指定工作類型 (例如偵測或區隔)。
- 自訂訓練程式碼:
- 使用預先建立的搜尋空間,或使用類神經架構搜尋語言定義自訂搜尋空間。
- 將搜尋空間定義整合至訓練程式碼。
- 在訓練程式碼中新增自訂指標報表。
- 在訓練員程式碼中新增自訂獎勵。
- 建構訓練器容器。
- 設定部分訓練 (代理任務) 的搜尋測試參數。搜尋訓練應盡可能快速完成 (例如 30 至 60 分鐘),以便部分訓練模型:
- 取樣模型收集獎勵所需的最低 epoch 數量 (最低 epoch 數量不必確保模型收斂)。
- 超參數 (例如學習率)。
在本機執行搜尋,確保搜尋空間整合容器能正常運作。
啟動 Google Cloud 搜尋 (第 1 階段) 工作,並使用五個測試試驗,驗證搜尋試驗是否符合執行時間和準確度目標。
啟動具有 1,000 次以上試驗的 Google Cloud search (第 1 階段) 工作。
在搜尋過程中,請一併設定定期間隔,以便訓練 (第 2 階段) 前 N 大模型:
- 超參數搜尋的超參數和演算法。第 2 階段通常會使用與第 1 階段相似的設定,但會針對特定參數 (例如訓練步驟/週期和管道數量) 設定更高的值。
- 停止條件 (訓練週期數)。
分析回報的指標和/或以視覺化方式呈現架構,以便取得洞察資訊。
架構搜尋實驗可搭配擴大搜尋實驗,並接著進行擴增搜尋實驗。
說明文件閱讀順序
- (必要) 設定環境
- (必要) 教學課程
- (僅適用於 PyTorch 客戶) 使用雲端資料進行 PyTorch 高效率訓練
- (必要) 最佳做法和建議工作流程
- (必要) Proxy 工作設計
- (僅適用於使用預先建立的訓練程式時) 如何使用預先建立的搜尋空間和預先建立的訓練程式
參考資料
- 使用機器學習技術探索神經網路架構
- MnasNet:邁向自動化設計行動機器學習模型
- EfficientNet:透過 AutoML 和模型資源調度提升準確度和效率
- NAS-FPN:學習可擴充的物件偵測功能金字塔架構
- SpineNet:學習可辨識及定位的尺度排列主幹
- RandAugment