假設您已執行教學課程,本頁將概略說明類神經架構搜尋的最佳做法。第一節將概述完整的工作流程,您可以按照這個流程執行神經架構搜尋作業。其他各節會詳細說明每個步驟。強烈建議您在執行第一個神經架構搜尋工作之前,先詳閱整個頁面。
建議的工作流程
我們在此概要說明神經架構搜尋的建議工作流程,並提供對應章節的連結,方便您進一步瞭解相關資訊:
- 將訓練資料集拆分為第 1 階段搜尋。
- 請務必遵守搜尋空間的相關規範。
- 使用基準模型執行完整訓練,並取得驗證曲線。
- 執行代理程式工作設計工具,找出最佳代理程式工作。
- 對 Proxy 工作進行最終檢查。
- 設定適當的總測試次數和並行測試次數,然後開始搜尋。
- 監控搜尋圖表,並在圖表收斂或顯示大量錯誤,或沒有收斂跡象時停止搜尋。
- 針對搜尋結果中選出的前 10 個最佳試驗,執行完整訓練,以取得最終結果。如要進行完整訓練,您可以使用更多增強或預先訓練的權重,以獲得最佳效能。
- 分析搜尋內容中儲存的指標/資料,並就日後的搜尋空間迭代作業做出結論。
一般神經架構搜尋

上圖顯示典型的神經架構搜尋曲線。這裡的 Y-axis 會顯示試用獎勵,X-axis 則會顯示目前已啟動的試用次數。前 100 到 200 次嘗試大多是控制器對搜尋空間進行隨機探索。在這些初步探索期間,由於搜尋空間中會嘗試許多類型的模型,因此獎勵會顯示出很大的差異。隨著試驗次數增加,控制器就會開始尋找更優質的模型。因此,獎勵會先開始增加,然後獎勵變化和獎勵成長開始減少,進而顯示收斂。收斂的試驗次數可能因搜尋空間大小而異,但通常約為 2000 次試驗。
類神經架構搜尋的兩個階段:代理任務和完整訓練
類神經架構搜尋的運作程序分為兩個階段:
搜尋階段 1 會使用完整訓練作業的表示法,通常會在 1 到 2 小時內完成。這類表示法稱為proxy 工作,可協助降低搜尋成本。
在第 2 階段進行完整訓練時,會為第 1 階段搜尋結果中分數最高的 10 個模型進行完整訓練。由於搜尋具有隨機性,因此階段 1 搜尋的最高模型,可能不是階段 2 完整訓練的最高模型,因此建議您選取完整訓練的模型池。
由於控制器會從較小的代理程式工作取得獎勵信號,而不是完整的訓練,因此為工作找到最佳代理程式工作非常重要。
類神經架構搜尋費用
神經架構搜尋成本計算方式如下:
search-cost = num-trials-to-converge * avg-proxy-task-cost。假設proxy-task 的運算時間約為完整訓練時間的 1/30,且收斂所需的試驗次數約為 2000 次,則搜尋成本會變成約 67 * full-training-cost。
由於類神經架構搜尋的成本高昂,建議您花時間調整 Proxy 工作,並在第一次搜尋時使用較小的搜尋空間。
在神經架構搜尋的兩個階段之間分割資料集
假設您已為基準訓練建立訓練資料和驗證資料,建議您將資料集分割為以下兩個階段的 NAS 神經架構搜尋:
- 第 1 階段搜尋訓練:約 90% 的訓練資料
第 1 階段搜尋驗證:約 10% 的訓練資料
階段 2 - 完整訓練:100% 的訓練資料
階段 2:完整訓練驗證:100% 的驗證資料
階段 2 的完整訓練資料拆分方式與一般訓練相同。不過,stage1-search 會使用分割的訓練資料進行驗證。在第 1 階段和第 2 階段使用不同的驗證資料,有助於偵測資料集分割所造成的任何模型搜尋偏差。請務必先將訓練資料充分洗牌,再進一步分割,且最後 10% 的訓練資料分割結果,其分布情形應與原始驗證資料相似。
資料量少或不平衡
不建議在訓練資料有限的情況下,或在某些類別非常罕見的不平衡資料集上使用架構搜尋功能。如果您因資料不足而已使用大量擴增資料進行基準訓練,則不建議使用模型搜尋功能。
在這種情況下,您可能只需要執行 augmentation-search 來搜尋最佳增強政策,而不需要搜尋最佳架構。
搜尋空間設計
架構搜尋不應與擴充搜尋或超參數搜尋 (例如學習率或最佳化工具設定) 混用。架構搜尋的目標是在只有架構差異的情況下,比較模型 A 和模型 B 的成效。因此,增強和超參數設定應保持不變。
完成架構搜尋後,您可以將擴充搜尋設為不同的階段。
神經架構搜尋的搜尋空間大小可達 10^20。不過,如果搜尋範圍較大,您可以將搜尋範圍劃分為互斥的部分。舉例來說,您可以先從解碼器或首字節中,單獨搜尋編碼器。如果您仍想對所有這些選項進行聯合搜尋,可以針對先前找到的最佳個別選項,建立較小的搜尋空間。
(選用) 設計搜尋空間時,您可以從區塊設計調整模型。請先使用縮小的模型進行區塊設計搜尋。這麼做可以大幅降低代理程式工作執行階段的成本。接著,您可以進行單獨搜尋,以放大模型。詳情請參閱
Examples of scaled down models。
最佳化訓練和搜尋時間
在執行神經架構搜尋之前,請務必為基準模型最佳化訓練時間。這樣一來,您就能在長期內節省成本。以下是一些可用來最佳化訓練的選項:
- 盡量加快資料載入速度:
- 請確認資料所在的值區與工作所在的區域相同。
- 如果使用 TensorFlow,請參閱
Best practice summary。您也可以嘗試使用 TFRecord 格式儲存資料。 - 如果使用 PyTorch,請按照指南進行有效的 PyTorch 訓練。
- 使用分散式訓練,充分運用多個加速器或多台機器。
- 使用混合精確度訓練,大幅提升訓練速度並減少記憶體用量。如要瞭解 TensorFlow 混合精確度訓練,請參閱
Mixed Precision。 - 有些加速器 (例如 A100) 通常更符合成本效益。
- 調整批次大小,確保 GPU 使用率達到最高。下圖顯示 GPU 未充分使用 (50%)。
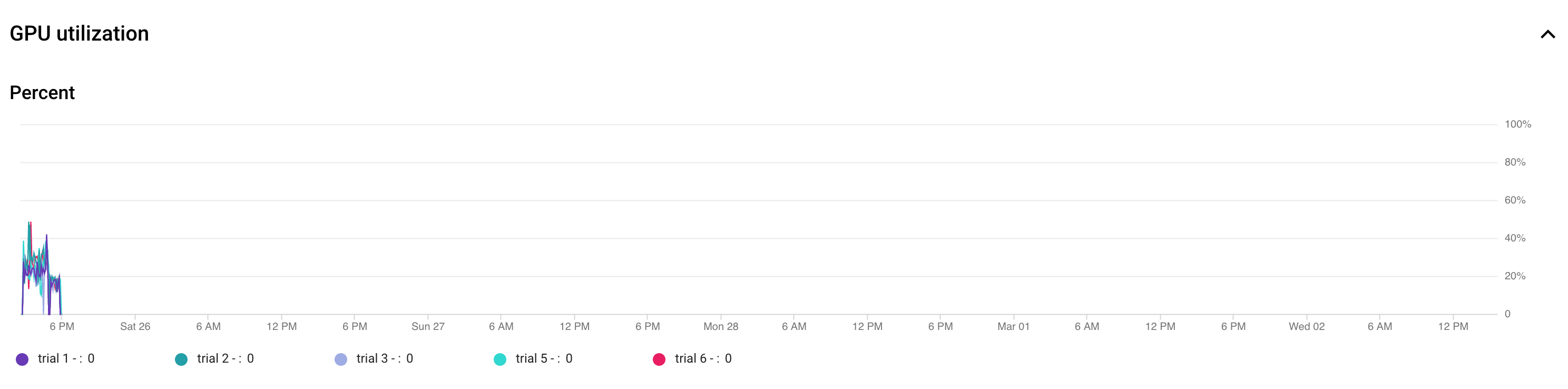 增加批次大小有助於更充分利用 GPU。不過,請謹慎增加批次大小,因為這可能會增加搜尋期間記憶體不足的錯誤。
增加批次大小有助於更充分利用 GPU。不過,請謹慎增加批次大小,因為這可能會增加搜尋期間記憶體不足的錯誤。 - 如果某些架構區塊與搜尋空間無關,您可以嘗試為這些區塊載入預先訓練的檢查點,以便加快訓練速度。預先訓練的查核點應與搜尋空間相同,且不得引入偏差。舉例來說,如果搜尋空間只適用於解碼器,則編碼器可以使用預先訓練的檢查點。
每個搜尋測試的 GPU 數量
每個試驗使用較少的 GPU,以縮短啟動時間。舉例來說,2 個 GPU 需要 5 分鐘才能啟動,而 8 個 GPU 則需要 20 分鐘。每個試驗使用 2 個 GPU 執行類神經架構搜尋工作代理程式工作,效率會更高。
搜尋廣告活動的總試驗次數和平行試驗
試用版設定
搜尋並選取最佳代理程式工作後,即可啟動完整搜尋。我們無法事先得知需要進行多少次試驗才能收斂。收斂的試驗次數可能會因搜尋空間大小而異,但通常約為 2,000 次試驗。
建議您為 --max_nas_trial 設定非常高的值:約 5,000 到 10,000,然後如果搜尋圖表顯示收斂,就提早取消搜尋工作。您也可以使用 search_resume 指令,繼續執行先前的搜尋工作。不過,您無法從其他搜尋繼續作業中繼續搜尋。因此,您只能恢復原始搜尋作業一次。
並行試驗設定
階段 1 搜尋工作會一次並行執行 --max_parallel_nas_trial 次測試,以便執行批次處理作業。這對於縮短搜尋作業的整體執行時間至關重要。您可以計算搜尋預期天數:
days-required-for-search = (trials-to-converge / max-parallel-nas-trial) * (avg-trial-duration-in-hours / 24)
注意:您一開始可以使用 3000 粗略估算 trials-to-converge,這是不錯的起始上限。您一開始可以使用 2 小時來粗略估算 avg-trial-duration-in-hours,這是每個 Proxy 工作所需時間的上限。建議您使用 --max_parallel_nas_trial 設定值約 20 到 50,具體取決於專案的加速器配額和 days-required-for-search。舉例來說,如果您將 --max_parallel_nas_trial 設為 20,且每個 Proxy 工作會使用兩個 NVIDIA T4 GPU,則您應至少保留 40 個 NVIDIA T4 GPU 的配額。--max_parallel_nas_trial 設定不會影響整體搜尋結果,但會影響 days-required-for-search。max_parallel_nas_trial 的設定值可以更小,例如約 10 個 (20 個 GPU),但您應該粗略估算 days-required-for-search,並確保其在 工作逾時限制 內。
根據預設,stage2-full-training 工作通常會並行訓練所有試驗。通常是同時執行的前 10 個試驗。不過,如果每個階段 2 完整訓練試驗都使用太多 GPU (例如每個試驗使用 8 個 GPU),且您沒有足夠的配額,則可以手動以批次方式執行階段 2 工作,例如先為前 5 次試驗執行階段 2 完整訓練,然後再為接下來的 5 次試驗執行另一個階段 2 完整訓練。
預設工作逾時時間
預設的 NAS 工作逾時時間為 14 天,逾時後系統會取消工作。如果您預計要執行的工作時間較長,可以嘗試再執行一次搜尋作業,最多再執行 14 天。總而言之,您可以執行 28 天的搜尋作業 (包括暫停)。
失敗試驗次數上限設定
失敗的測試次數上限應設為 max_nas_trial 設定值的 1/3 左右。當失敗的測試次數達到此上限時,工作就會取消。
停止搜尋的時機
請在下列情況下停止搜尋:
搜尋曲線開始收斂 (變異數減少):
注意:如果沒有使用延遲限制,或是使用硬式延遲限制搭配寬鬆的延遲限制,則曲線可能不會顯示獎勵增加,但仍應顯示收斂。這是因為控制器在搜尋初期可能就已達到良好的準確度。超過 20% 的測試顯示無效獎勵 (失敗):

即使經過約 500 次嘗試,搜尋曲線也不會增加或收斂 (如上圖所示)。如果獎勵增加或變化減少,您就可以繼續。