在启动 Vertex AI 神经架构搜索实验之前,请先设置环境。
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
如果您使用的是外部身份提供方 (IdP),则必须先使用联合身份登录 gcloud CLI。
-
如需初始化 gcloud CLI,请运行以下命令:
gcloud init -
初始化 gcloud CLI 后,对其进行更新并安装所需组件:
gcloud components update gcloud components install beta
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Vertex AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
如果您使用的是外部身份提供方 (IdP),则必须先使用联合身份登录 gcloud CLI。
-
如需初始化 gcloud CLI,请运行以下命令:
gcloud init -
初始化 gcloud CLI 后,对其进行更新并安装所需组件:
gcloud components update gcloud components install beta
- 如需向所有神经架构搜索用户授予 Vertex AI User 角色 (
roles/aiplatform.user),请与您的项目管理员联系。 - 安装 Docker。
如果您使用的是基于 Linux 的操作系统(例如 Ubuntu 或 Debian),请将您的用户名添加到
docker群组,这样您就可以在不使用sudo的情况下运行 Docker:sudo usermod -a -G docker ${USER}在将您自己添加到
docker群组之后,您可能需要重启系统。 - 打开 Docker。要确保 Docker 正在运行,请运行以下 Docker 命令以返回当前时间和日期:
docker run busybox date
- 使用
gcloud作为 Docker 的凭据帮助程序:gcloud auth configure-docker
-
(可选)如果要在本地使用 GPU 运行容器,请安装
nvidia-docker。 -
为新存储分区指定名称。该名称在 Cloud Storage 的所有存储分区中必须是唯一的。
BUCKET_NAME="YOUR_BUCKET_NAME"
例如,使用附加了
-vertexai-nas的项目名称:PROJECT_ID="YOUR_PROJECT_ID" BUCKET_NAME=${PROJECT_ID}-vertexai-nas
-
检查您创建的存储分区名称。
echo $BUCKET_NAME
-
为您的存储桶选择一个区域,并设置
REGION环境变量。使用您计划在其中运行神经架构搜索作业的区域。
例如,以下代码会创建
REGION并将其设置为us-central1:REGION=us-central1
-
创建新的存储桶:
gcloud storage buckets create gs://$BUCKET_NAME --location=$REGION
- 对于服务,请选择 Vertex AI API。
- 对于区域,请选择要过滤的区域。
- 对于配额,请选择前缀为自定义模型训练的加速器名称。
- 对于 V100 GPU,该值为每个区域的自定义模型训练 Nvidia V100 GPU。
- 对于 CPU,该值可以为每个区域的 N1/E2 机器类型的自定义模型训练 CPU。CPU 的数量表示 CPU 单位。如果您需要 8 个
highmem-16CPU,则申请 8 * 16 = 128 个 CPU 单元的配额。此外,输入所需的区域值。
设置基本环境变量:
gcloud config set project PROJECT_ID gcloud auth login gcloud auth application-default login为工件注册表设置 docker 身份验证:
# example: REGION=europe-west4 gcloud auth configure-docker REGION-docker.pkg.dev(可选)配置 Python 3 虚拟环境。建议使用 Python 3,但这不是必需的:
sudo apt install python3-pip && \ pip3 install virtualenv && \ python3 -m venv --system-site-packages ~/./nas_venv && \ source ~/./nas_venv/bin/activate安装其他库:
pip install google-cloud-storage==2.6.0 pip install pyglove==0.1.0创建服务账号:
gcloud iam service-accounts create NAME \ --description=DESCRIPTION \ --display-name=DISPLAY_NAME将
aiplatform.user和storage.objectAdmin角色授予服务账号:gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:NAME@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/aiplatform.user gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:NAME@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/storage.objectAdmin打开新的 Shell 终端。
运行 Git 克隆命令:
git clone https://github.com/google/vertex-ai-nas.git
设置 Cloud Storage 存储桶
本部分演示如何创建新存储桶。您可以使用现有存储桶,但它所在区域必须与您正在运行 AI Platform 作业的区域相同。此外,如果该存储桶不在您用于运行神经架构搜索的项目中,则您必须明确授予对神经架构搜索服务账号的访问权限。
为项目申请额外的设备配额
教程使用大约五台 CPU 机器,不需要任何额外的配额。运行教程后,请运行您的神经架构搜索作业。
神经架构搜索作业会并行训练一批模型。每个经过训练的模型对应一个试验。参阅设置 number-of-parallel-trials 部分,估算搜索作业需要的 CPU 和 GPU 数量。例如,如果每个试验使用 2 个 T4 GPU 并且您将 number-of-parallel-trials 设置为 20,则一个搜索作业需要的总配额为 40 个 T4 GPU。此外,如果每个试验都使用 highmem-16 CPU,则每个试验需要 16 个 CPU 单元,20 个并行试验需要 320 个 CPU 单元。但是,我们至少需要 10 个并行试验配额(或 20 个 GPU 配额)。GPU 的默认初始配额因区域和 GPU 类型而异,Tesla_T4 通常为 0、6 或 12,Tesla_V100 通常为 0 或 6。CPU 的默认初始配额因区域而异,通常为 20、450 或 2,200。
可选:如果您计划并行运行多个搜索作业,请提高配额要求。 申请配额后您无需立即付费,在运行作业后才需要付费。
如果您没有足够的配额,并尝试启动需要超出配额的资源的作业,则作业不会启动,并显示如下所示的错误:
Exception: Starting job failed: {'code': 429, 'message': 'The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd', 'status': 'RESOURCE_EXHAUSTED', 'details': [{'@type': 'type.googleapis.com/google.rpc.DebugInfo', 'detail': '[ORIGINAL ERROR] generic::resource_exhausted: com.google.cloud.ai.platform.common.errors.AiPlatformException: code=RESOURCE_EXHAUSTED, message=The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd, cause=null [google.rpc.error_details_ext] { code: 8 message: "The following quota metrics exceed quota limits: aiplatform.googleapis.com/custom_model_training_cpus,aiplatform.googleapis.com/custom_model_training_nvidia_v100_gpus,aiplatform.googleapis.com/custom_model_training_pd_ssd" }'}]}
在某些情况下,如果同一项目的多个作业同时启动,并且配额不足以支持所有作业,则其中一个作业将保持排队状态,不会开始训练。在这种情况下,请取消排队的作业,然后申请更多配额或等待上一个作业完成。
您可以从配额页面申请额外的设备配额。您可以应用过滤条件来查找需要修改的配额:
创建配额申请后,您会收到一个 Case number 和关于请求状态的后续电子邮件。GPU 配额审批可能需要大约两到五个工作日。通常,20-30 个 GPU 的配额申请会较快获批,大约需要两到三天,100 个 GPU 的配额申请则可能需要五个工作日。CPU 配额审批最多需要两个工作日。但是,如果某个区域的某个 GPU 类型严重短缺,那么即使申请的配额较小,也无法保证获批。在这种情况下,可能会要求您选择其他区域或 GPU 类型。一般而言,T4 GPU 比 V100 更容易获得。T4 GPU 更耗时,但也更经济实惠。
如需了解详情,请参阅申请配额调整。
为您的项目设置工件注册表
您必须为推送 Docker 映像的项目和区域设置工件注册表。
转到项目的工件注册表页面。如果尚未启用工件注册表 API,请先为项目启用:
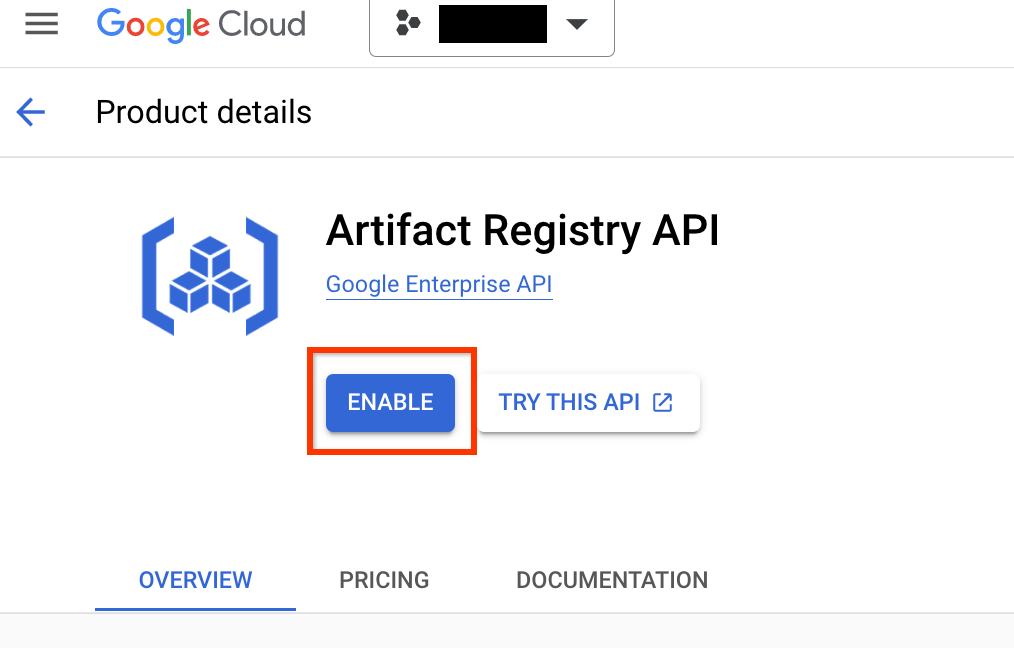
启用后,点击创建代码库以开始创建新的代码库:
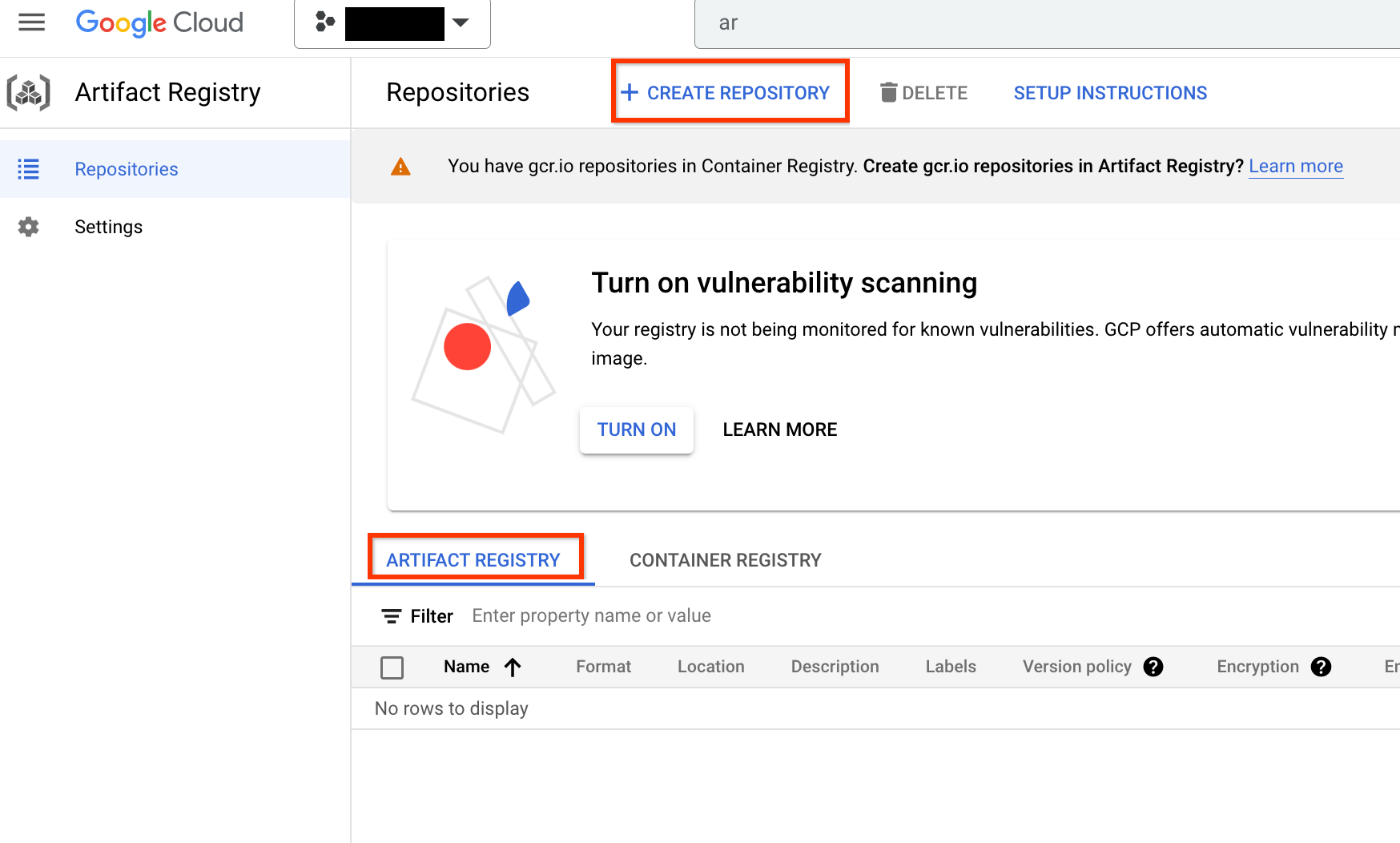
选择名称作为 nas,选择格式作为 Docker,然后选择位置类型作为区域。对于区域,选择运行作业的位置,然后点击创建。
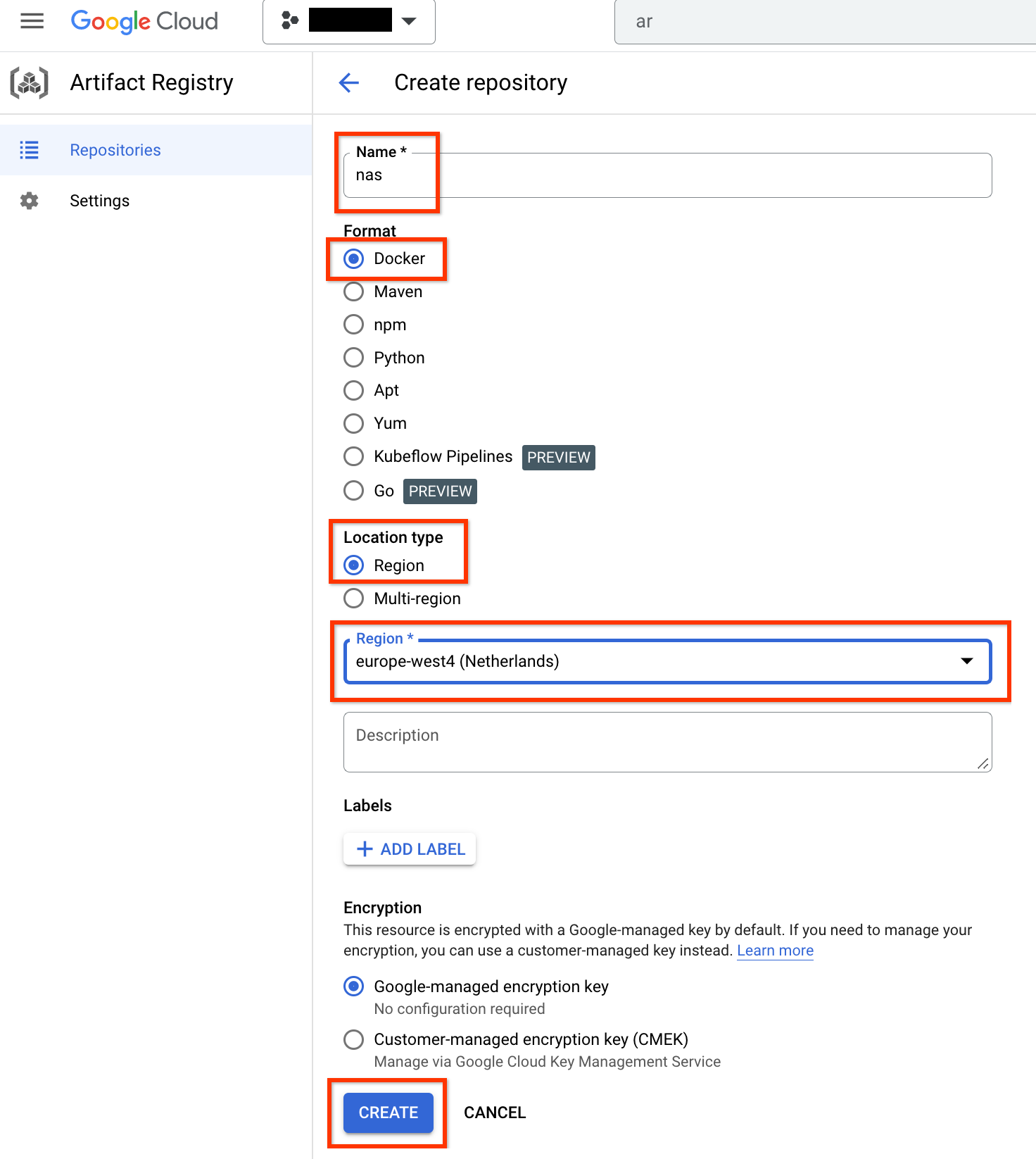
这应该会创建您所需的 Docker 代码库,如下所示:
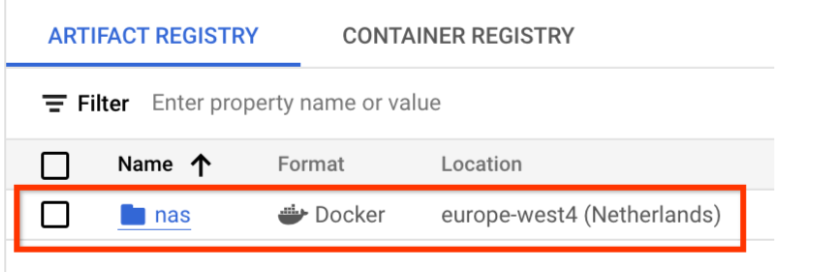
您还需要设置身份验证以将 docker 推送到此代码库。下面的本地环境设置部分包含此步骤。
设置本地环境
您可以在本地环境中使用 Bash shell 运行这些步骤,也可以在 Vertex AI Workbench 实例中通过笔记本运行这些步骤。
设置服务账号
在运行 NAS 作业之前,您必须先设置服务账号。您可以在本地环境中使用 Bash shell 运行这些步骤,也可以在 Vertex AI Workbench 实例中通过笔记本运行这些步骤。
例如,以下命令在项目 my-nas-project 中创建名为 my-nas-sa 的服务账号,它具有 aiplatform.user 和 storage.objectAdmin 角色:
gcloud iam service-accounts create my-nas-sa \
--description="Service account for NAS" \
--display-name="NAS service account"
gcloud projects add-iam-policy-binding my-nas-project \
--member=serviceAccount:my-nas-sa@my-nas-project.iam.gserviceaccount.com \
--role=roles/aiplatform.user
gcloud projects add-iam-policy-binding my-nas-project \
--member=serviceAccount:my-nas-sa@my-nas-project.iam.gserviceaccount.com \
--role=roles/storage.objectAdmin
下载代码
如需启动神经架构搜索实验,您需要下载示例 Python 代码,其中包含预构建的训练程序、搜索空间定义和关联的客户端库。
运行以下步骤以下载源代码。