本页面介绍了使用 AutoML 的表格数据历程。如需了解 AutoML 和自定义训练之间的主要区别,请参阅选择训练方法。
表格数据用例
假设您在一家数字零售商的营销部门工作。您和您的团队正在根据客户角色创建个性化的电子邮件程序。您已经创建了角色和营销电子邮件。现在,您需要创建这样一个系统,即使是新客户,也可以根据零售偏好和消费行为将其划分为相应角色。为了最大限度地提高客户互动度,您还需要预测其消费习惯,以便优化发送电子邮件时间。
因为您是数字零售商,所以您拥有有关客户及其购买的数据。但新客户呢?传统方法能够为具有较长消费历史的现有客户计算这些值,但面对历史数据很少的客户时则表现不佳。如果能创建一个系统来预测这些值,加快对所有客户开展个性化营销的速度该有多好?
幸运的是,机器学习和 Vertex AI 可以很好地解决这些问题。
本指南将引导您逐步了解将如何 Vertex AI 用于 AutoML 数据集和模型,并说明 Vertex AI 旨在解决的问题类型。
Vertex AI 的工作原理是什么?
Vertex AI 应用监督式机器学习来实现所需的结果。 算法和训练方法的具体细节因数据类型和用例而异。机器学习有许多不同的子类别,用于解决不同的问题,并在不同的约束条件下工作。
您使用示例数据训练机器学习模型。Vertex AI 使用表格(结构化)数据来训练机器学习模型,以便对新数据进行推理。数据集中的一列(称为目标)是您的模型将学习预测的内容。其他一些数据列是模型将从中学习模式的输入(称为特征)。只需更改目标列和训练选项,即可使用同一些输入特征构建多种模型。在邮件营销的示例中,这意味着您可以利用相同的输入特征但不同的目标推理来构建模型。一个模型可以预测客户的角色(分类目标),另一个模型可以预测客户的每月支出(数值目标),再一个模型可以预测未来 3 个月产品的每日需求(多个数值目标)。
Vertex AI 工作流
Vertex AI 使用标准机器学习工作流:
- 收集数据:根据您想要实现的结果,确定训练和测试模型所需的数据。
- 准备数据:确保您的数据格式正确且已加标签。
- 训练:设置参数并构建模型。
- 评估:审核模型指标。
- 部署和预测:使您的模型可供使用
在开始收集数据之前,先思考您要尝试解决的问题。从而了解您的数据要求。
数据准备
评估您的使用场景
从您的问题着手:您想要实现什么结果?
目标列是什么类型的数据?您可以访问多少数据? 根据您的答案,Vertex AI 会创建必要的模型来解析您的用例:
- 二元分类模型可预测二元结果(二者选一)。此模型类型用于是非问题。例如,您可能想要构建一个二元分类模型来预测客户是否会购买订阅。一般而言,二元分类问题所需的数据比其他模型类型少。
- 多类别分类模型可从三个或更多个互不关联的类别中预测一个类别。使用此模型类型进行分类。例如,作为零售商,您可能希望构建一个多类别分类模型来将客户划分为不同的角色。
- 回归模型可预测连续值。例如,作为零售商,您可能希望构建一个回归模型来预测客户下个月的支出。
- 预测模型可预测一系列值。例如,作为零售商,您可能希望预测未来 3 个月的产品每日需求,以便提前备妥适当数量的商品库存。
表格数据预测与分类和回归在两个主要方面有所不同:
在分类和回归中,目标的预测值仅取决于同一行中特征列的值。在预测中,预测值还取决于目标和特征的上下文值。
在回归和分类问题中,输出是一个值。在预测问题中,输出是一系列值。
收集数据
确定用例后,收集用于创建所需模型的数据。
 确定用例后,您需要收集数据来训练模型。数据搜寻和准备是构建机器学习模型的关键步骤。可用的数据会决定您能够解决什么类型的问题。您有多少可用数据?您的数据是否与您要回答的问题相关?在收集数据时,请牢记以下关键注意事项。
确定用例后,您需要收集数据来训练模型。数据搜寻和准备是构建机器学习模型的关键步骤。可用的数据会决定您能够解决什么类型的问题。您有多少可用数据?您的数据是否与您要回答的问题相关?在收集数据时,请牢记以下关键注意事项。
选择相关特征
特征是用于模型训练的输入属性。特征帮助模型识别模式以进行推理,因此它们需要与您的问题相关。例如,要构建一个预测信用卡交易是否属于欺诈的模型,您需要构建一个包含交易详细信息(如买方、卖方、金额、日期和时间以及购买的商品)的数据集。其他有用的特征包括买方和卖方的相关历史信息,以及购买的商品涉及欺诈的频率。还有哪些可能相关的其他特征?
请考虑简介中提到的零售商电子邮件营销用例。以下是您可能需要的一些特征列:
- 购买的商品清单(包括品牌、类别、价格、折扣)
- 购买的商品数量(前一天、过去一周、过去一个月、过去一年)
- 消费金额(前一天、过去一周、过去一个月、过去一年)
- 每件商品每天的售出总数
- 每件商品每天的库存总数
- 是否针对特定日期开展促销活动
- 已知的购物者统计学特征概况
包括足够的数据
 一般而言,您拥有的训练样本越多,得到的结果就越好。所需的样本数据量也会随着您试图解决的问题的复杂性而变化。与多类别模型相比,生成一个精确的二元分类模型所需的数据更少,因为从两个类别中预测一个比从多个类别中预测一个来得简单。
一般而言,您拥有的训练样本越多,得到的结果就越好。所需的样本数据量也会随着您试图解决的问题的复杂性而变化。与多类别模型相比,生成一个精确的二元分类模型所需的数据更少,因为从两个类别中预测一个比从多个类别中预测一个来得简单。
完美的公式是不存在的,但我们建议至少具有以下示例数据:
- 分类问题:50 行 x 特征数量
- 预测问题:
- 5000 行 x 特征数
- 时序标识符列中的 10 个唯一值 x 特征数量
- 回归问题:200 x 特征数量
捕获差异
您的数据集应捕获问题空间的多样性。模型在训练过程中看到的样本越多样,就越容易对新的或较不常见的样本具备普适性。设想一下,如果您仅使用冬季的购买数据来训练零售模型,那么模型是否能够成功预测夏季服装偏好或购买行为?
准备数据
 在确定可用数据后,您需要确保数据适合用于训练。如果您的数据存在偏差或包含缺失或错误的值,这会影响模型的质量。在开始训练模型之前,请注意以下事项。
了解详情。
在确定可用数据后,您需要确保数据适合用于训练。如果您的数据存在偏差或包含缺失或错误的值,这会影响模型的质量。在开始训练模型之前,请注意以下事项。
了解详情。
防止数据泄露和训练-应用偏差
数据泄露是指您在训练期间使用的输入特征“泄露”了试图预测的目标的相关信息,而这类信息在应用模型时无从获得。要检测是否存在数据泄露,您可检测是否有与目标列高度相关的特征被包括为输入特征之一。例如,如果您正在构建一个模型来预测客户是否将在下个月注册订阅,而其中一个输入特征是该客户的未来订阅付款情况。这会使模型在测试期间展现出超高的性能,但部署到生产环境中后却黯然失色,因为在应用模型时无法获得未来的订阅付款信息。
训练-应用偏差是指训练时使用的输入特征与在应用模型时提供给模型的输入特征不同,导致模型在生产环境中效果不佳。例如,建立一个模型来预测每小时的温度,但训练时使用的数据只包含每周的温度。另一个例子:对于预测学生辍学的模型,在训练数据中始终提供学生的分数,但在应用模型时却不提供此信息。
了解您的训练数据对于防止数据泄露和训练-应用偏差非常重要:
- 在使用任何数据之前,请确保您知道数据的含义以及是否应将其用作特征
- 在“训练”标签页中检查相关性。应将高相关性数据标记出来,进行检查。
- 训练-应用偏差:确保仅为模型提供在应用模型时以完全相同的形式提供的输入特征。
清理缺失、不完整和不一致的数据
样本数据中有缺失和不准确的值是很常见的。在将数据用于训练之前,请花些时间进行检查,并尽可能提高数据质量。缺失值越多,您的数据对训练机器学习模型的效用就越小。
- 请检查您的数据是否存在缺失值。如果可能,请更正这些值;如果列设置为可以为 Null,则将这些值保留为空。Vertex AI 可以处理缺失值,但如果所有值都可用,您更有可能获得最佳结果。
- 对于预测,请检查训练行之间的时间间隔是否一致。Vertex AI 可以处理缺失值,但如果所有行都可用,您更有可能获得最佳结果。
- 通过更正或删除数据错误或干扰数据来清理数据。使数据保持一致:检查拼写、缩写和格式设置。
分析导入的数据
导入数据集后,Vertex AI 可以提供您的数据集的概览。检查导入的数据集以确保每一列都具有正确的变量类型。 Vertex AI 将根据列值自动检测变量类型,但您最好逐个检查。您还应该检查每列是否可为 Null,这一属性决定了列是否可以包含缺失值或 NULL 值。
训练模型
导入数据集后,下一步是训练模型。Vertex AI 使用默认设置也能生成可靠的机器学习模型,但建议您根据自己的用例调整一些参数。
选择尽可能多的特征列来进行训练,但要检查每列以确保其适合训练。在选择特征时,请牢记以下事项:
- 不要选择会产生干扰数据的特征列,例如每行具有唯一值的随机分配的标识符列。
- 确保您理解每个特征列及其值。
- 如果要利用一个数据集创建多个模型,请移除不属于当前推理问题的目标列。
- 回想一下公平原则:您训练模型使用的特征是否会导致对边缘群体的偏见或不公平决策?
Vertex AI 如何使用您的数据集
您的数据集将被拆分为训练集、验证集和测试集。默认拆分 Vertex AI 应用取决于您要训练的模型类型。您还可以根据需要指定拆分(手动拆分)。如需了解详情,请参阅 AutoML 模型的数据拆分简介。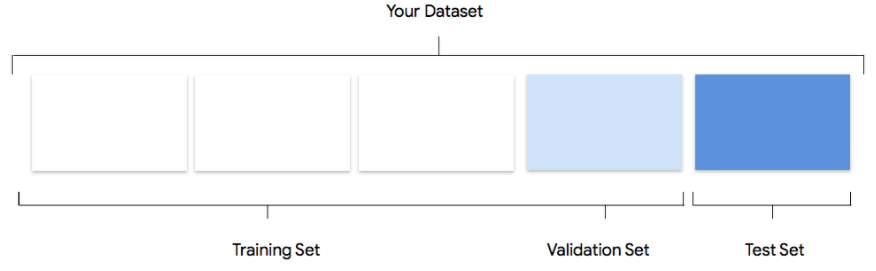
训练集
 您的绝大部分数据都应该划分到训练集中。训练集包含您的模型在训练期间“看到”的数据:它用于学习模型的参数,即神经网络节点之间连接的权重。
您的绝大部分数据都应该划分到训练集中。训练集包含您的模型在训练期间“看到”的数据:它用于学习模型的参数,即神经网络节点之间连接的权重。
验证集
 验证集(有时也称为“开发集”)也用于训练过程。模型学习框架在训练过程的每次迭代期间吸纳了训练数据之后,会根据模型在验证集上的表现来调整模型的超参数,这些超参数是指定模型结构的变量。如果您尝试使用训练集来调整超参数,则很可能会导致模型过度关注训练数据,因而很难泛化到并非精确匹配的样本。使用在一定程度上的新数据集微调模型结构,意味着您的模型将会有更好的泛化效果。
验证集(有时也称为“开发集”)也用于训练过程。模型学习框架在训练过程的每次迭代期间吸纳了训练数据之后,会根据模型在验证集上的表现来调整模型的超参数,这些超参数是指定模型结构的变量。如果您尝试使用训练集来调整超参数,则很可能会导致模型过度关注训练数据,因而很难泛化到并非精确匹配的样本。使用在一定程度上的新数据集微调模型结构,意味着您的模型将会有更好的泛化效果。
测试集
 测试集完全不参与训练过程。当模型完成全部训练后,Vertex AI 会将测试集用作一项新挑战来测试模型。通过模型在测试集上的表现,您可以较好地了解模型在使用真实数据时会有怎样的表现。
测试集完全不参与训练过程。当模型完成全部训练后,Vertex AI 会将测试集用作一项新挑战来测试模型。通过模型在测试集上的表现,您可以较好地了解模型在使用真实数据时会有怎样的表现。
评估、测试和部署模型
评估模型
 模型训练结束后,您将收到其性能总结。模型评估指标根据模型针对数据集切片(测试数据集)的表现情况得出。在确定模型是否已准备好用于真实数据时,需要考虑一些关键指标和概念。
模型训练结束后,您将收到其性能总结。模型评估指标根据模型针对数据集切片(测试数据集)的表现情况得出。在确定模型是否已准备好用于真实数据时,需要考虑一些关键指标和概念。
分类指标
得分阈值
考虑一个用于预测客户明年是否会购买夹克的机器学习模型。模型的确定程度需要有多高,才能做出给定客户将购买夹克的预测?在分类模型中,每个推理都分配有一个置信度分数,这个数值衡量模型在多大程度上确定预测的类别是正确的。分数阈值是确定给定分数何时转换为是或否决策的数字;也就是说,分数为该值时,您的模型表示“是的,这个置信度分数足够高,可以得出这个客户将在明年购买一件外套的结论”。
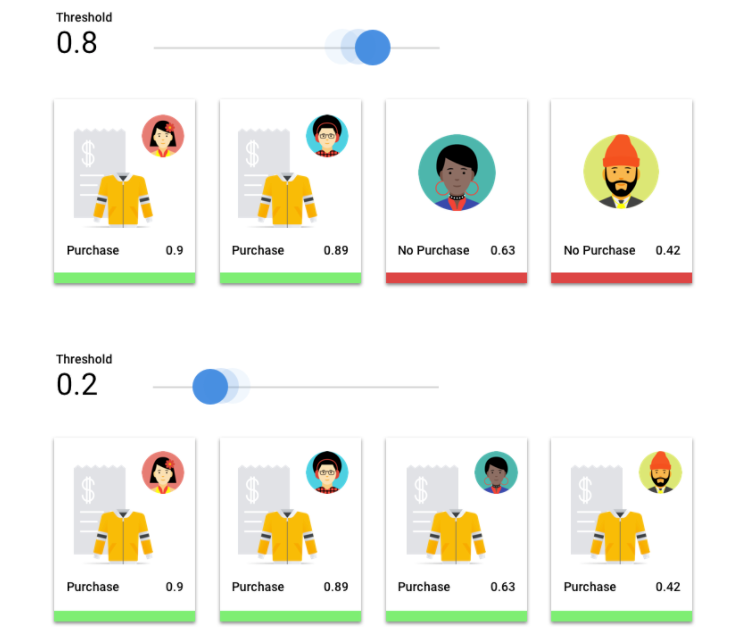
如果分数阈值较低,那么您的模型的分类可能会出错。 因此,分数阈值应基于给定用例确定。
推理结果
应用分数阈值后,模型所做的推理可分为四类。要理解这些类别,我们再次假设一个夹克的二元分类模型。 在这个例子中,正类别(模型尝试预测的内容)是客户“会”在明年购买夹克。
- 真正例:模型对正类别的预测正确。模型正确预测到顾客购买了夹克。
- 假正例:模型对正类别的预测错误。模型预测客户会购买夹克,但他们没有。
- 真负例:模型对负类别的预测正确。模型正确预测到客户没有购买夹克。
- 假负例:模型对负类别的预测错误。模型预测客户不会购买夹克,但他们买了。

精确率和召回率
精确率和召回率指标有助于您了解模型捕获信息的精准度以及遗漏的信息量。详细了解精确率和召回率。
- 精确率是指正确推理的正类别所占的比例。在客户购买的所有推理中,实际购买的比例占多少?
- 召回率是模型正确预测的具有此标签的行所占的比例。在本可以识别的所有客户购买中,实际识别出的比例占多少?
根据您的用例,您可能需要针对精确率或召回率进行优化。
其他分类指标
- AUC PR:精确率-召回率 (PR) 曲线下的面积。此值的范围在 0 到 1 之间,值越大表示模型质量越高。
- AUC ROC:接收者操作特征 (ROC) 曲线下的面积。 此值的范围在 0 到 1 之间,值越大表示模型质量越高。
- 精确率:在模型生成的分类推理中,正确推理结果所占的比例。
- 对数损失函数:模型推理结果与目标值之间的交叉熵。此值的范围在零到无穷大之间,值越小表示模型质量越高。
- F1 得分:精确率和召回率的调和平均数。F1 是一个很实用的指标,当您希望在精确率和召回率之间取得平衡,而类别分布又不均匀时,该指标会非常有帮助。
预测和回归指标
模型构建完成后,Vertex AI 会提供各种标准回归指标供您查看。关于如何评估模型,并不存在完美的答案;您应该根据您的问题类型以及希望使用模型实现的目标来考虑评估指标。以下列表简要介绍了 Vertex AI 可以提供的一些指标。
平均绝对误差 (MAE)
MAE 指的是目标值与预测值之间的平均绝对差。 它衡量的是一组推理中误差的平均大小,即目标值与预测值之间的差值。由于 MAE 使用的是绝对值,因此它不考虑关系的方向,也不能说明是性能不佳还是性能过高。评估 MAE 时,值越小表示模型质量越高(0 表示完美的预测模型)。
均方根误差 (RMSE)
RMSE 指的是目标值和预测值之间的平均平方差的平方根。RMSE 对离群值比 MAE 更敏感,因此如果您担心大的误差,那么 RMSE 可能是一个更有用的评估指标。与 MAE 类似,值越小表示模型质量越高(0 表示完美的预测模型)。
均方根对数误差 (RMSLE)
RMSLE 进行对数转换后的 RMSE。RMSLE 对相对误差比对绝对误差更敏感,并且更关心性能不佳而不是性能过高的情况。
观察到的分位数(仅限预测)
对于给定的目标分位数,观察到的分位数显示观察值低于指定的分位数推理值的实际比例。观察到的分位数显示模型与目标分位数的差距或接近程度。两个值之间的差值越小,表示模型质量越高。
弹力 Pinball 损失(仅限预测)
衡量给定目标分位数的模型质量。数字越小表示模型质量越高。您可以比较不同分位数上的已调整的 pinball 损失指标,以确定模型在这些不同分位数之间的相对准确率。
测试模型
评估模型指标是判断模型是否已准备好部署的主要方法,但您也可以使用新数据对其进行测试。上传新数据以查看模型的推理结果是否符合您的预期。根据评估指标或使用新数据进行测试的结果,您可能需要继续改进模型的性能。
部署模型
如果您对模型的性能感到满意,就可以使用该模型了。可能是生产规模的使用,也可能是一次性的推理请求。您可以根据用例的情况以不同方式使用模型。
批量推理
批量推理适合一次处理大量推理请求的情况。批量推理是异步的,也就是说,模型会先处理所有推理请求,然后再返回具有推理值的 CSV 文件或 BigQuery 表格。
在线推理
部署模型使其可用于通过 REST API 处理推理请求。在线推理是同步的(实时),这意味着它将快速返回推理,但每次 API 调用仅接受一个推理请求。如果您的模型是应用的一部分并且您系统的某些部分依赖于快速的推理周转,则在线推理会非常有用。
清理
为避免产生不必要的费用,请在模型未使用时将其取消部署。
使用完模型后,请删除您创建的资源,以避免账号产生不必要的费用。