이 문서에서는 엔드 투 엔드 AutoML 파이프라인 및 구성요소를 간략하게 설명합니다. 엔드 투 엔드 AutoML로 모델을 학습시키는 방법은 엔드 투 엔드 AutoML로 모델 학습을 참조하세요.
엔드 투 엔드 AutoML의 테이블 형식 워크플로는 분류 및 회귀 태스크를 위한 완전 AutoML 파이프라인입니다. AutoML API와 비슷하지만 제어할 항목과 자동화할 항목을 선택할 수 있습니다. 전체 파이프라인을 제어하는 대신 파이프라인의 모든 단계를 제어할 수 있습니다. 이러한 파이프라인 제어에는 다음이 포함됩니다.
- 데이터 분할
- 특성 추출
- 아키텍처 검색
- 모델 학습
- 모델 앙상블
- 모델 정제
이점
다음은 엔드 투 엔드 AutoML용 테이블 형식 워크플로의 몇 가지 이점입니다.
- 크기가 수 TB이고 열이 최대 1,000개까지 있는 대규모 데이터 세트를 지원합니다.
- 아키텍처 유형의 검색 공간을 제한하거나 아키텍처 검색을 건너뛰어 안정성을 높이고 학습 시간을 낮출 수 있습니다.
- 학습 및 아키텍처 검색에 사용되는 하드웨어를 수동으로 선택하여 학습 속도를 향상시킬 수 있습니다.
- 정제를 사용하거나 앙상블 크기를 변경하여 모델 크기를 줄이고 지연 시간을 개선할 수 있습니다.
- 변환된 데이터 테이블, 평가된 모델 아키텍처, 기타 다양한 세부정보를 볼 수 있는 강력한 파이프라인 그래프 인터페이스에서 각 AutoML 구성요소를 검사할 수 있습니다.
- 각 AutoML 구성요소는 매개변수, 하드웨어, 뷰 프로세스 상태, 로그 등을 맞춤설정할 수 있게 하는 등 유연성과 투명성이 확장됩니다.
Vertex AI 파이프라인의 엔드 투 엔드 AutoML
엔드 투 엔드 AutoML용 테이블 형식 워크플로는 Vertex AI Pipelines의 관리형 인스턴스입니다.
Vertex AI Pipelines는 Kubeflow 파이프라인을 실행하는 서버리스 서비스입니다. 파이프라인을 사용하여 머신러닝 및 데이터 준비 태스크를 자동화하고 모니터링할 수 있습니다. 파이프라인의 각 단계에서 파이프라인 워크플로 일부를 수행합니다. 예를 들어 파이프라인에 데이터 분할, 데이터 유형 변환, 모델 학습 단계가 포함될 수 있습니다. 단계는 파이프라인 구성요소의 인스턴스이므로 단계에는 입력, 출력, 컨테이너 이미지가 있습니다. 단계 입력은 파이프라인의 입력에서 설정되거나 이 파이프라인 내의 다른 단계의 출력에 따라 달라질 수 있습니다. 이러한 종속 항목은 파이프라인의 워크플로를 방향성 비순환 그래프(DAG)로 정의합니다.
파이프라인 및 구성요소 개요
다음 다이어그램은 엔드 투 엔드 AutoML용 테이블 형식 워크플로의 모델링 파이프라인을 보여줍니다.

파이프라인 구성요소는 다음과 같습니다.
- feature-transform-engine: 특성 추출을 실행합니다. 자세한 내용은 Feature Transform Engine을 참조하세요.
- split-Materialized-data: 구체화된 데이터를 학습 세트, 평가 세트, 테스트 세트로 분할합니다.
입력:
- 구체화된 데이터
materialized_data
출력:
- 구체화된 학습 분할
materialized_train_split - 구체화된 평가 분할
materialized_eval_split - 구체화된 테스트 세트
materialized_test_split
- 구체화된 데이터
- merge-Materialized-splits - 구체화된 평가 분할과 구체화된 학습 분할을 병합합니다.
automl-tabular-stage-1-tuner - 모델 아키텍처를 검색하고 하이퍼파라미터를 조정합니다.
- 아키텍처는 초매개변수 집합으로 정의됩니다.
- 초매개변수에는 모델 유형과 모델 매개변수가 포함됩니다.
- 고려되는 모델 유형은 신경망과 부스팅된 트리입니다.
- 시스템은 고려되는 각 아키텍처에 대해 모델을 학습합니다.
automl-tabular-cv-trainer - 입력 데이터의 여러 부분에 대해 모델을 학습시켜 아키텍처를 교차 검증합니다.
- 고려되는 아키텍처는 이전 단계에서 최상의 결과를 제공한 아키텍처입니다.
- 시스템에서 최상의 아키텍처 약 10개를 선택합니다. 정확한 숫자는 학습 예산에 따라 정의됩니다.
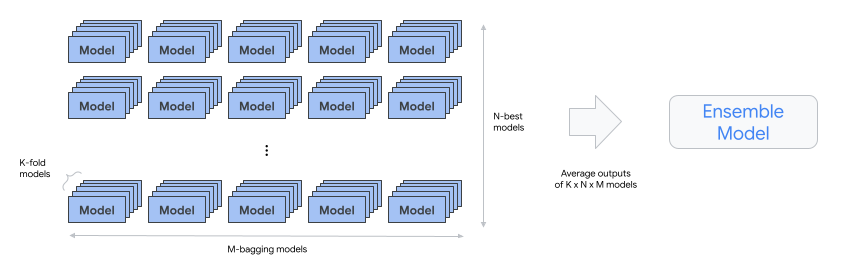
automl-tabular-ensemble - 최종 모델을 생성하는 데 가장 적합한 아키텍처를 앙상블합니다.
- 다음 다이어그램은 배깅을 사용한 K-fold 교차 검증을 보여줍니다.
condition-is-discip - 선택사항. 더 작은 앙상블 모델 버전을 만듭니다.
- 모델이 작을수록 추론의 지연 시간과 비용이 줄어듭니다.
automl-tabular-infra-validator - 학습된 모델이 유효한 모델인지 검증합니다.
model-upload - 모델을 업로드합니다.
condition-is-evaluation - 선택사항. 테스트 세트를 사용하여 평가 측정항목을 계산합니다.