Esta guía para principiantes es una introducción al entrenamiento personalizado en Vertex AI. El entrenamiento personalizado se refiere al entrenamiento de un modelo con un framework de AA como TensorFlow, PyTorch o XGBoost.
Objetivos de aprendizaje
Nivel de experiencia de Vertex AI: Principiante
Tiempo de lectura estimado: 15 minutos
Qué aprenderás:
- Beneficios de usar un servicio administrado para el entrenamiento personalizado.
- Prácticas recomendadas para empaquetar el código de entrenamiento.
- Cómo enviar y supervisar un trabajo de entrenamiento.
¿Por qué usar un servicio de entrenamiento administrado?
Imagina que estás trabajando en un nuevo problema de AA. Abres un notebook, importas tus datos y ejecutas la experimentación. En esta situación, crearás un modelo con el framework de AA que elijas y ejecutarás celdas de notebook para ejecutar un ciclo de entrenamiento. Cuando finalice el entrenamiento, evalúa los resultados del modelo, realiza cambios y, luego, vuelve a ejecutar el entrenamiento. Este flujo de trabajo es útil para experimentar, pero a medida que comienzas a pensar en la compilación de aplicaciones de producción con AA, es posible que ejecutar las celdas de tu notebook de manera manual no sea la opción más conveniente.
Por ejemplo, si tu conjunto de datos y modelo son grandes, puedes probar el entrenamiento distribuido. Además, en una configuración de producción, es poco probable que solo necesites entrenar tu modelo una vez. Con el tiempo, volverás a entrenar tu modelo para asegurarte de que se mantenga actualizado y produzca resultados valiosos. Cuando desees automatizar la experimentación a gran escala o volver a entrenar modelos para una aplicación de producción, usar un servicio de entrenamiento de AA administrado simplificará tus flujos de trabajo.
En esta guía, se proporciona una introducción al entrenamiento de modelos personalizados en Vertex AI. Debido a que el servicio de entrenamiento está completamente administrado, Vertex AI aprovisiona de forma automática los recursos de procesamiento, realiza la tarea de entrenamiento y garantiza la eliminación de los recursos de procesamiento una vez que finaliza el trabajo de entrenamiento. Ten en cuenta que existen personalizaciones, funciones y formas de interfaz adicionales con el servicio que no se tratan aquí. El objetivo de esta guía es proporcionar una descripción general. Para obtener más información, consulta la documentación de Vertex AI Training.
Descripción general del entrenamiento personalizado
El entrenamiento de modelos personalizados en Vertex AI sigue este flujo de trabajo estándar:
Empaqueta el código de tu aplicación de entrenamiento
Configura y envia un trabajo de entrenamiento personalizado
Supervisa el trabajo de entrenamiento personalizado
Empaqueta el código de la aplicación de entrenamiento
La ejecución de un trabajo de entrenamiento personalizado en Vertex AI se realiza con contenedores. Los contenedores son paquetes del código de tu aplicación, en este caso el código de entrenamiento, junto con dependencias como las versiones específicas de bibliotecas necesarias para ejecutar el código. Además de ayudar con la administración de dependencias, los contenedores pueden ejecutarse prácticamente en cualquier lugar, lo que permite una mayor portabilidad. Empaquetar el código de entrenamiento con sus parámetros y dependencias en un contenedor para crear un componente portátil es un paso importante cuando se mueven las aplicaciones de AA de prototipado a producción.
Antes de iniciar un trabajo de entrenamiento personalizado, deberás empaquetar tu aplicación de entrenamiento. La aplicación de entrenamiento en este caso hace referencia a uno o varios archivos que realizan tareas como cargar datos, procesar previamente datos, definir un modelo y ejecutar un ciclo de entrenamiento. El servicio de entrenamiento de Vertex AI ejecuta cualquier código que proporciones, por lo que depende completamente de los pasos que incluyas en tu aplicación de entrenamiento.
Vertex AI proporciona contenedores previamente compilados para TensorFlow, PyTorch, XGBoost y Scikit-learn. Estos contenedores se actualizan con regularidad e incluyen bibliotecas comunes que puedes necesitar en tu código de entrenamiento. Puedes elegir ejecutar tu código de entrenamiento con uno de estos contenedores o crear un contenedor personalizado que tenga preinstalados tu código de entrenamiento y dependencias.
Hay tres opciones para empaquetar tu código en Vertex AI:
- Envía un solo archivo de Python.
- Crea una distribución de fuente de Python.
- Usar contenedores personalizados.
Archivo de Python
Esta opción es adecuada para realizar experimentos rápidos. Puedes usar esta opción si todo el código necesario para ejecutar tu aplicación de entrenamiento está en un archivo de Python y uno de los contenedores de entrenamiento de Vertex AI compilado previamente tiene todas las bibliotecas necesarias para ejecutar tu aplicación. Para ver un ejemplo de empaquetado de la aplicación de entrenamiento como un solo archivo de Python, consulta el instructivo del notebook Entrenamiento personalizado y predicción por lotes.
Distribución de fuente de Python
Puedes crear una distribución de fuente de Python que contenga tu aplicación de entrenamiento. Almacenarás tu distribución de origen con el código de entrenamiento y las dependencias en un bucket de Cloud Storage. Para ver un ejemplo de empaquetado de la aplicación de entrenamiento como una distribución de fuente de Python, consulta el instructivo del notebook Entrena, ajusta e implementa un modelo de clasificación de PyTorch.
Contenedor personalizado
Esta opción es útil cuando deseas tener más control sobre tu aplicación o si deseas ejecutar un código que no está escrito en Python. En este caso, deberás escribir un Dockerfile, compilar tu imagen personalizada y enviarla a Artifact Registry. Para ver un ejemplo de creación de contenedores de tu aplicación de entrenamiento, consulta el instructivo del notebook Perfila el rendimiento del entrenamiento de modelos con Profiler.
Estructura de la aplicación de entrenamiento recomendada
Si eliges empaquetar tu código como una distribución de fuente de Python o como un contenedor personalizado, te recomendamos estructurar tu aplicación de la siguiente manera:
training-application-dir/
....setup.py
....Dockerfile
trainer/
....task.py
....model.py
....utils.py
Crea un directorio para almacenar todo el código de la aplicación de entrenamiento, en este caso, training-application-dir. Este directorio contendrá un archivo setup.py si usas una distribución de fuente de Python, o un Dockerfile si usas un contenedor personalizado.
En ambos casos, este directorio de alto nivel también contendrá un subdirectorio trainer, que contiene todo el código para ejecutar el entrenamiento. Dentro de trainer, task.py es el punto de entrada principal de tu aplicación. Este archivo ejecuta el entrenamiento de modelos. Puedes colocar todo el código en este archivo, pero para las aplicaciones de producción, es probable que tengas archivos adicionales, como model.py, data.py o utils.py, por citar unos pocos.
Ejecuta el entrenamiento personalizado
Los trabajos de entrenamiento en Vertex AI aprovisionan automáticamente los recursos de procesamiento, ejecutan el código de la aplicación de entrenamiento y garantizan la eliminación de los recursos de procesamiento una vez que finaliza el trabajo de entrenamiento.
A medida que compilas flujos de trabajo más complicados, es probable que uses el SDK de Vertex AI para Python a fin de configurar, enviar y supervisar tus trabajos de entrenamiento. Sin embargo, la primera vez que ejecutas un trabajo de entrenamiento personalizado, puede ser más fácil usar la Google Cloud consola.
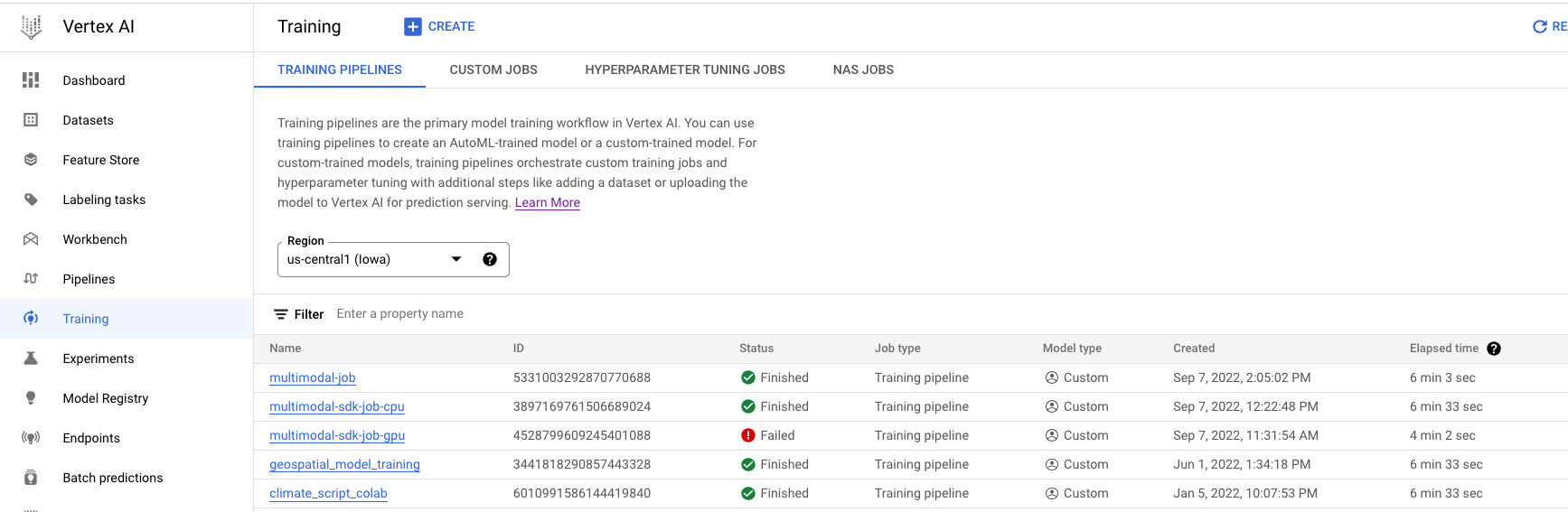
- Navega a Entrenamiento en la sección Vertex AI de la consola de Cloud. Para crear un trabajo de entrenamiento nuevo, haz clic en el botón CREAR.
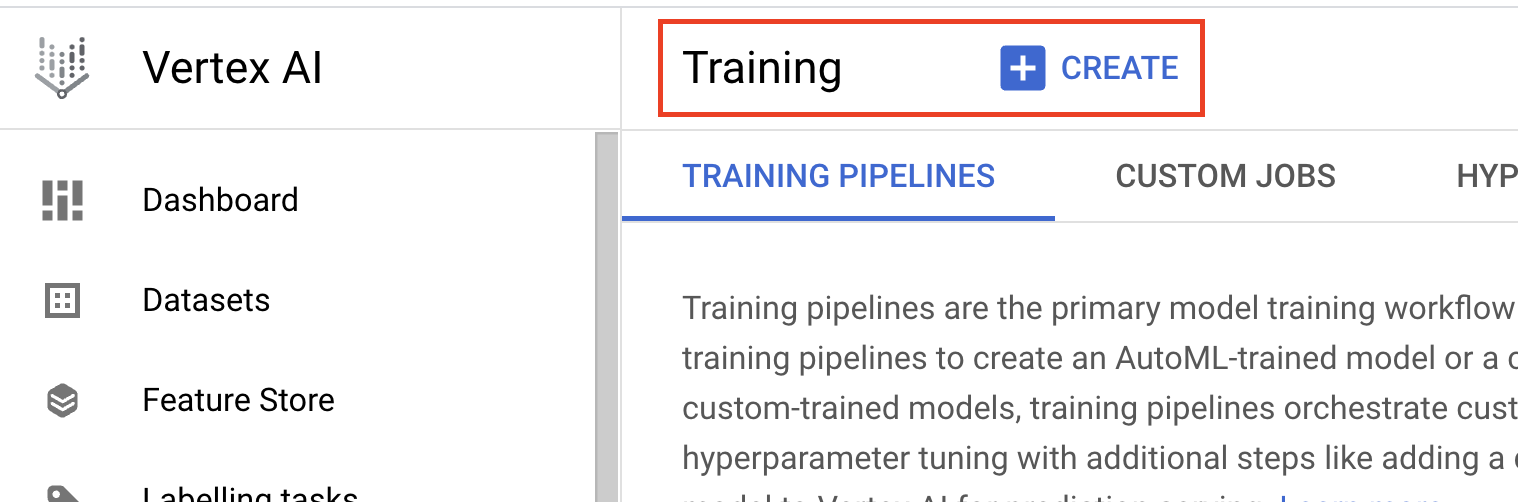
- En Método de entrenamiento de modelos, selecciona Entrenamiento personalizado (avanzado).
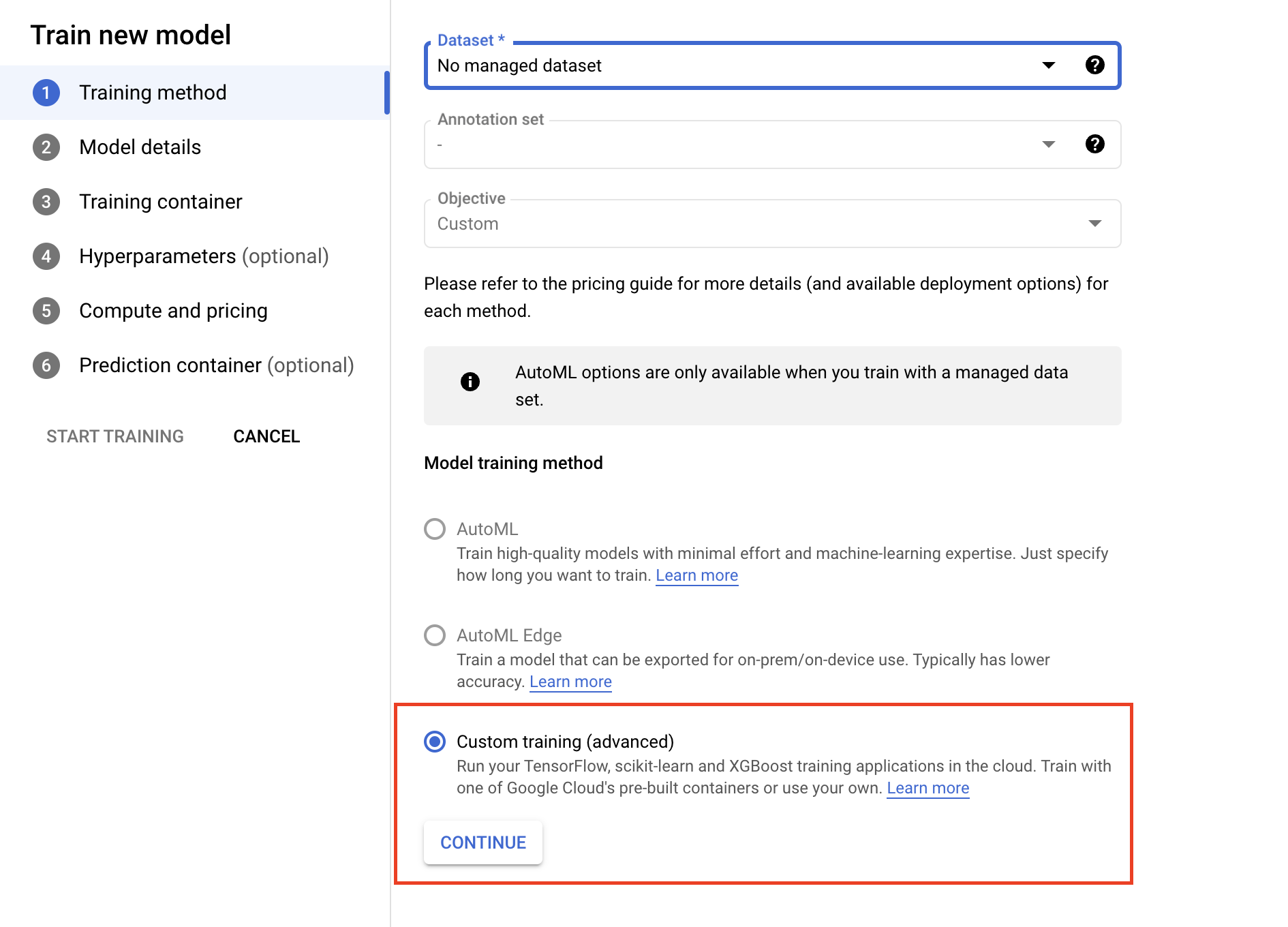
- En la sección Contenedor de entrenamiento, selecciona el contenedor compilado previamente o el personalizado, según cómo empaquetaste tu aplicación.
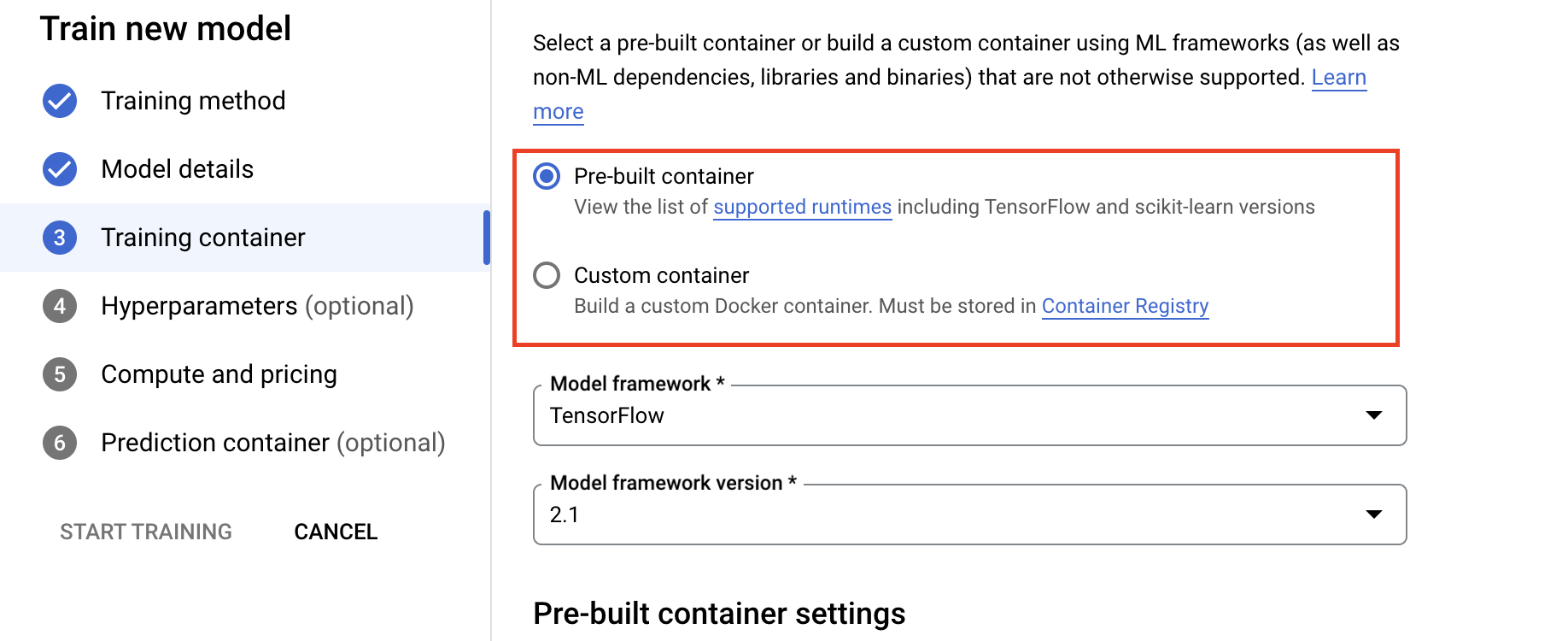
- En Procesamiento y precios, especifica el hardware para el trabajo de entrenamiento. Para el entrenamiento de nodo único, solo necesitas configurar el Grupo de trabajadores 0. Si te interesa ejecutar el entrenamiento distribuido, deberás comprender los otros grupos de trabajadores y puedes obtener más información en Entrenamiento distribuido.
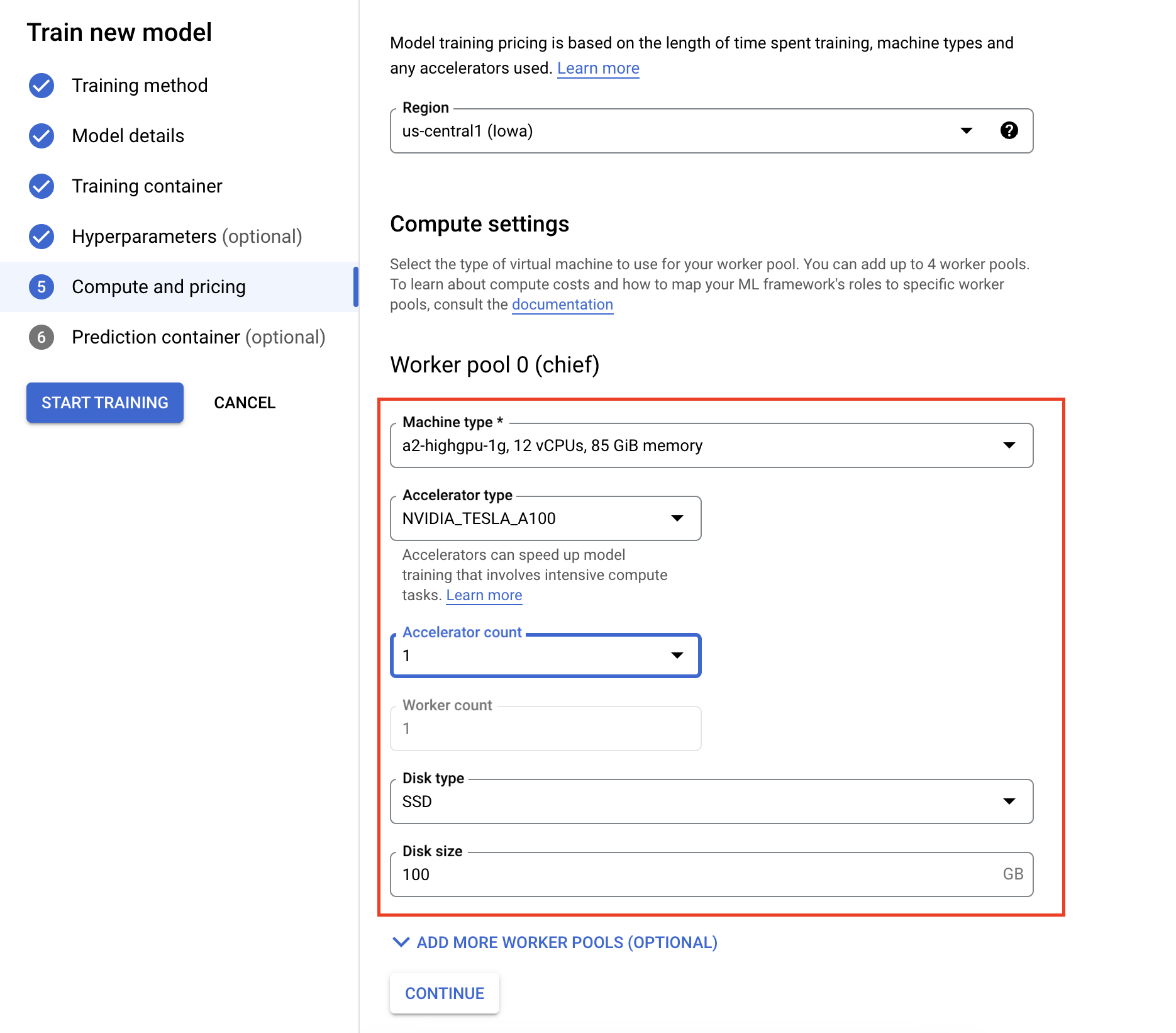
Configurar el contenedor de inferencia es opcional. Si solo deseas entrenar un modelo en Vertex AI y acceder a los artefactos resultantes del modelo guardado, puedes omitir este paso. Si deseas alojar y, luego, implementar el modelo resultante en el servicio de inferencia administrado de Vertex AI, deberás configurar un contenedor de inferencia. Para obtener más información, consulta Cómo obtener inferencias a partir de un modelo entrenado personalizado.
Supervisa trabajos de entrenamiento
Puedes supervisar el trabajo de entrenamiento en la consola de Google Cloud . Verás una lista de todos los trabajos que se ejecutaron. Puedes hacer clic en un trabajo en particular y examinar los registros si algo sale mal.