Un modelo de Vertex AI se despliega en su propia instancia de máquina virtual (VM) de forma predeterminada. Vertex AI ofrece la posibilidad de alojar modelos en la misma máquina virtual, lo que proporciona las siguientes ventajas:
- Compartir recursos entre varias implementaciones.
- Aplicación de modelos rentable.
- Se ha mejorado el uso de la memoria y los recursos computacionales.
En esta guía se describe cómo compartir recursos entre varias implementaciones en Vertex AI.
Información general
La compatibilidad con el coanfitrión de modelos introduce el concepto de DeploymentResourcePool, que agrupa las implementaciones de modelos que comparten recursos en una sola máquina virtual. Se pueden implementar varios endpoints en la misma VM dentro de un DeploymentResourcePool. Cada endpoint tiene uno o varios modelos implementados. Los modelos desplegados de un endpoint determinado se pueden agrupar en el mismo DeploymentResourcePool o en otro.
En el siguiente ejemplo, tienes cuatro modelos y dos endpoints:
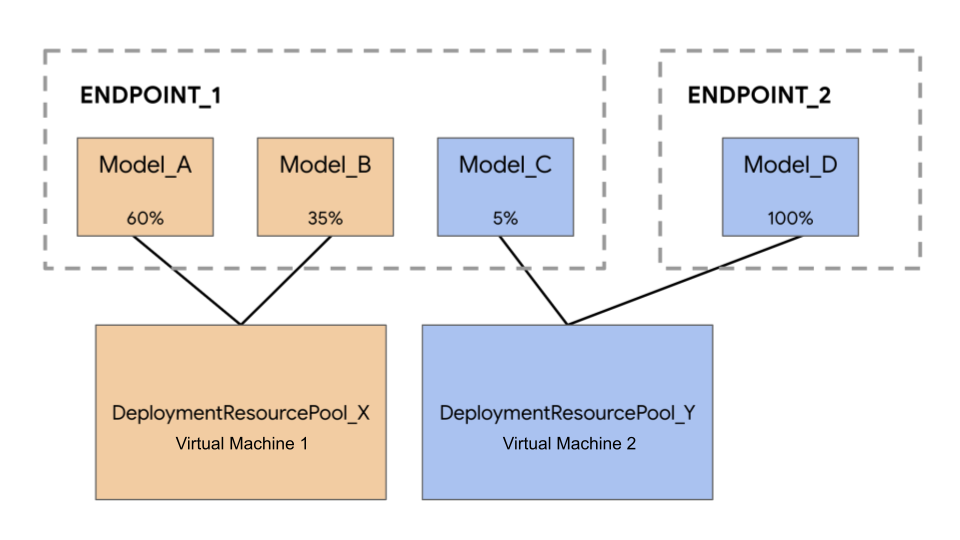
Model_A, Model_B y Model_C se implementan en Endpoint_1 y el tráfico se dirige a todos ellos. Model_D se implementa en Endpoint_2, que recibe el 100% del tráfico de ese endpoint.
En lugar de asignar cada modelo a una VM independiente, puede agrupar los modelos de una de las siguientes formas:
- Agrupa
Model_AyModel_Bpara compartir una VM, lo que los convierte en parte deDeploymentResourcePool_X. - Agrupa
Model_CyModel_D(que actualmente no están en el mismo endpoint) para compartir una VM, lo que los convierte en parte deDeploymentResourcePool_Y.
Los diferentes grupos de recursos de implementación no pueden compartir una máquina virtual.
Cuestiones importantes
No hay límite máximo en el número de modelos que se pueden implementar en un único grupo de recursos de implementación. Depende del perfil de VM elegido, del tamaño de los modelos y de los patrones de tráfico. El alojamiento conjunto funciona bien cuando tienes muchos modelos desplegados con tráfico disperso, de forma que asignar una máquina dedicada a cada modelo desplegado no utiliza los recursos de forma eficaz.
Puedes desplegar modelos en el mismo grupo de recursos de implementación simultáneamente. Sin embargo, hay un límite de 20 solicitudes de despliegue simultáneas en cualquier momento.
Un pool de recursos de implementación vacío no consume tu cuota de recursos. Los recursos se aprovisionan en un grupo de recursos de implementación cuando se implementa el primer modelo y se liberan cuando se desimplementa el último modelo.
Los modelos de un mismo grupo de recursos de implementación no están aislados entre sí y pueden competir por la CPU y la memoria. El rendimiento de un modelo puede ser peor si otro modelo está procesando una solicitud de inferencia al mismo tiempo.
Limitaciones
Se aplican las siguientes limitaciones al implementar modelos con la función de compartir recursos habilitada:
- Esta función solo se admite en las siguientes configuraciones:
- Despliegues de modelos de TensorFlow que usan contenedores precompilados para TensorFlow
- Implementaciones de modelos de PyTorch que usan contenedores precompilados para PyTorch
- No se admiten contenedores prediseñados configurados para otros frameworks.
- No se admiten contenedores personalizados.
- Solo se admiten modelos entrenados de forma personalizada y modelos importados. No se admiten los modelos de AutoML.
- Solo se pueden desplegar en el mismo grupo de recursos de despliegue los modelos que tengan la misma imagen de contenedor (incluida la versión del framework) de los contenedores precompilados de Vertex AI para la inferencia de TensorFlow o PyTorch.
- Vertex Explainable AI no se admite.
Desplegar un modelo
Para implementar un modelo en un DeploymentResourcePool, sigue estos pasos:
- Crea un pool de recursos de implementación si es necesario.
- Crea un endpoint si es necesario.
- Obtén el ID del endpoint.
- Despliega el modelo en el endpoint del pool de recursos de despliegue.
Crear un grupo de recursos de implementación
Si vas a implementar un modelo en un DeploymentResourcePool, omite este paso:
Usa CreateDeploymentResourcePool para crear un pool de recursos.
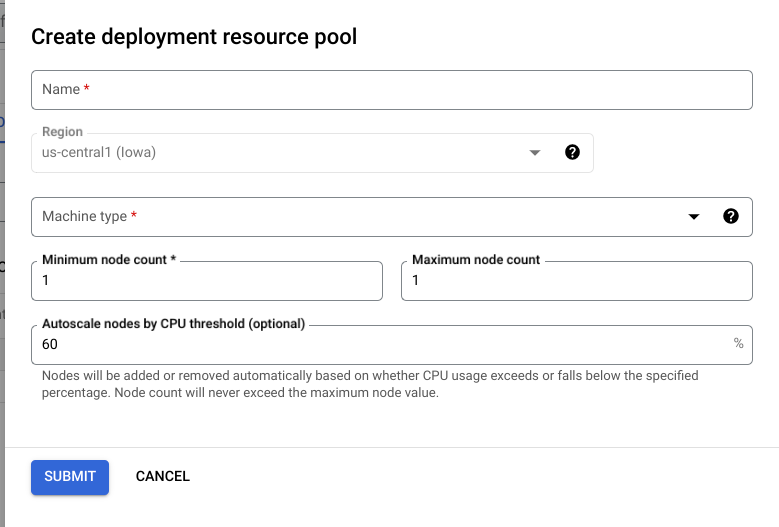
Consola de Cloud
En la Google Cloud consola, ve a la página Grupos de recursos de implementación de Vertex AI.
Haz clic en Crear y rellena el formulario (que se muestra a continuación).
REST
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- LOCATION_ID: la región en la que usas Vertex AI.
- PROJECT_ID: tu ID de proyecto.
-
MACHINE_TYPE: opcional. Los recursos de la máquina que se usan en cada nodo de esta implementación. Su ajuste predeterminado es
n1-standard-2. Más información sobre los tipos de máquinas - ACCELERATOR_TYPE: tipo de acelerador que se va a asociar a la máquina. Opcional si ACCELERATOR_COUNT no se especifica o es cero. No se recomienda para modelos de AutoML ni modelos entrenados personalizados que usen imágenes que no sean de GPU. Más información
- ACCELERATOR_COUNT: número de aceleradores que debe usar cada réplica. Opcional. Debe ser cero o no especificarse en los modelos de AutoML o en los modelos entrenados personalizados que usen imágenes que no sean de GPU.
- MIN_REPLICA_COUNT: número mínimo de nodos de esta implementación. El número de nodos se puede aumentar o reducir según lo requiera la carga de inferencia, hasta el número máximo de nodos y nunca por debajo de este número. Este valor debe ser superior o igual a 1.
- MAX_REPLICA_COUNT: número máximo de nodos de este despliegue. El número de nodos se puede aumentar o reducir según lo requiera la carga de inferencia, hasta este número de nodos y nunca por debajo del número mínimo de nodos.
- REQUIRED_REPLICA_COUNT: opcional. Número de nodos necesarios para que esta implementación se marque como correcta. Debe ser igual o superior a 1 e igual o inferior al número mínimo de nodos. Si no se especifica, el valor predeterminado es el número mínimo de nodos.
-
DEPLOYMENT_RESOURCE_POOL_ID: un nombre para tu
DeploymentResourcePool. La longitud máxima es de 63 caracteres y los caracteres válidos son /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/.
Método HTTP y URL:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/deploymentResourcePools
Cuerpo JSON de la solicitud:
{
"deploymentResourcePool":{
"dedicatedResources":{
"machineSpec":{
"machineType":"MACHINE_TYPE",
"acceleratorType":"ACCELERATOR_TYPE",
"acceleratorCount":"ACCELERATOR_COUNT"
},
"minReplicaCount":MIN_REPLICA_COUNT,
"maxReplicaCount":MAX_REPLICA_COUNT,
"requiredReplicaCount":REQUIRED_REPLICA_COUNT
}
},
"deploymentResourcePoolId":"DEPLOYMENT_RESOURCE_POOL_ID"
}
Para enviar tu solicitud, despliega una de estas opciones:
Deberías recibir una respuesta JSON similar a la siguiente:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION_ID/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.CreateDeploymentResourcePoolOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-15T05:48:06.383592Z",
"updateTime": "2022-06-15T05:48:06.383592Z"
}
}
}
Puedes sondear el estado de la operación hasta que la respuesta incluya "done": true.
Python
# Create a deployment resource pool.
deployment_resource_pool = aiplatform.DeploymentResourcePool.create(
deployment_resource_pool_id="DEPLOYMENT_RESOURCE_POOL_ID", # User-specified ID
machine_type="MACHINE_TYPE", # Machine type
min_replica_count=MIN_REPLICA_COUNT, # Minimum number of replicas
max_replica_count=MAX_REPLICA_COUNT, # Maximum number of replicas
)
Haz los cambios siguientes:
DEPLOYMENT_RESOURCE_POOL_ID: un nombre para tuDeploymentResourcePool. La longitud máxima es de 63 caracteres y los caracteres válidos son /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/.MACHINE_TYPE: opcional. Los recursos de la máquina que se usan en cada nodo de este despliegue. El valor predeterminado esn1-standard-2. Más información sobre los tipos de máquinasMIN_REPLICA_COUNT: número mínimo de nodos de esta implementación. El número de nodos se puede aumentar o reducir según lo requiera la carga de inferencia, hasta el número máximo de nodos y nunca por debajo de este número. Este valor debe ser superior o igual a 1.MAX_REPLICA_COUNT: número máximo de nodos de esta implementación. El recuento de nodos se puede aumentar o reducir según lo requiera la carga de inferencia, hasta este número de nodos y nunca por debajo del número mínimo de nodos.
Crear un punto final
Para crear un endpoint, consulta Crear un endpoint público con la CLI de gcloud o la API de Vertex AI. Este paso es el mismo que para una implementación de un solo modelo.
Recuperar el ID del endpoint
Para obtener el ID del endpoint, consulta Desplegar un modelo con la CLI de gcloud o la API de Vertex AI. Este paso es el mismo que para una implementación de un solo modelo.
Desplegar el modelo en un pool de recursos de despliegue
Una vez que hayas creado un DeploymentResourcePool y un endpoint, podrás desplegarlo con el método de la API DeployModel. Este proceso es similar a una implementación de un solo modelo. Si hay un DeploymentResourcePool, especifica shared_resources de DeployModel con el nombre de recurso del DeploymentResourcePool que estés implementando.
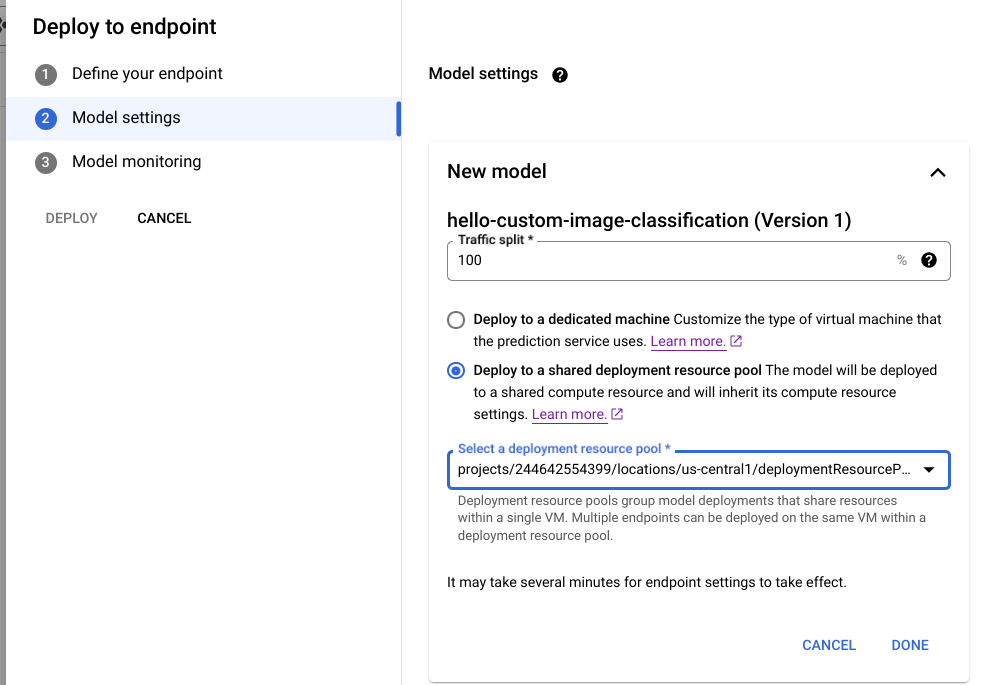
Consola de Cloud
En la Google Cloud consola, ve a la página Registro de modelos de Vertex AI.
Busca tu modelo y haz clic en Implementar en endpoint.
En Configuración del modelo (que se muestra más abajo), selecciona Implementar en un grupo de recursos de implementación compartidos.
REST
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
- LOCATION_ID: la región en la que usas Vertex AI.
- PROJECT: tu ID de proyecto.
- ENDPOINT_ID: ID del endpoint.
- MODEL_ID: ID del modelo que se va a implementar.
-
DEPLOYED_MODEL_NAME: nombre del
DeployedModel. También puedes usar el nombre visible de laModelpara laDeployedModel. -
DEPLOYMENT_RESOURCE_POOL_ID: un nombre para tu
DeploymentResourcePool. La longitud máxima es de 63 caracteres y los caracteres válidos son /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/. - TRAFFIC_SPLIT_THIS_MODEL: porcentaje del tráfico de predicción de este punto final que se va a dirigir al modelo que se está desplegando con esta operación. El valor predeterminado es 100. Todos los porcentajes de tráfico deben sumar 100. Más información sobre las divisiones de tráfico
- DEPLOYED_MODEL_ID_N: opcional. Si se implementan otros modelos en este endpoint, debes actualizar los porcentajes de división del tráfico para que todos los porcentajes sumen 100.
- TRAFFIC_SPLIT_MODEL_N: valor del porcentaje de división del tráfico de la clave del ID del modelo implementado.
- PROJECT_NUMBER: el número de proyecto generado automáticamente de tu proyecto
Método HTTP y URL:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/endpoints/ENDPOINT_ID:deployModel
Cuerpo JSON de la solicitud:
{
"deployedModel": {
"model": "projects/PROJECT/locations/us-central1/models/MODEL_ID",
"displayName": "DEPLOYED_MODEL_NAME",
"sharedResources":"projects/PROJECT/locations/us-central1/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID"
},
"trafficSplit": {
"0": TRAFFIC_SPLIT_THIS_MODEL,
"DEPLOYED_MODEL_ID_1": TRAFFIC_SPLIT_MODEL_1,
"DEPLOYED_MODEL_ID_2": TRAFFIC_SPLIT_MODEL_2
},
}
Para enviar tu solicitud, despliega una de estas opciones:
Deberías recibir una respuesta JSON similar a la siguiente:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.DeployModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-19T17:53:16.502088Z",
"updateTime": "2022-06-19T17:53:16.502088Z"
}
}
}
Python
# Deploy model in a deployment resource pool.
model = aiplatform.Model("MODEL_ID")
model.deploy(deployment_resource_pool=deployment_resource_pool)
Sustituye MODEL_ID por el ID del modelo que se va a implementar.
Repite la solicitud anterior con diferentes modelos que tengan los mismos recursos compartidos para desplegar varios modelos en el mismo grupo de recursos de implementación.
Obtener inferencias
Puedes enviar solicitudes de inferencia a un modelo de un DeploymentResourcePool como lo harías con cualquier otro modelo desplegado en Vertex AI.