As seções de objetivo a seguir incluem informações sobre requisitos de dados, o arquivo de esquema de entrada/saída e o formato dos arquivos de importação de dados (Linhas JSON e CSV) definidos pelo esquema.
Permissões
Para usar imagens de um bucket do Cloud Storage, conceda ao Agente de serviço da Vertex AI o papel Storage Object Viewer para o bucket. O agente de serviço é uma conta serviço gerenciado pelo Google que a Vertex AI usa para acessar seus dados em seu nome. Para uma explicação mais detalhada, consulte Agentes de serviço.
Detecção de objetos
Requisitos de dados
| Requisitos gerais de imagem | |
|---|---|
| Tipos de arquivos compatíveis |
|
| Tipos de imagens | Os modelos do AutoML são otimizados para fotografias de objetos reais. |
| Tamanho do arquivo de imagem de treinamento (MB) | Tamanho máximo de 30 MB. |
| Tamanho do arquivo de imagem de previsão* (MB) | Tamanho máximo de 1,5 MB. |
| Tamanho da imagem (pixels) | Máximo sugerido de 1024 x 1024 pixels. Para imagens muito maiores que 1.024 pixels por 1.024 pixels, a qualidade de algumas imagens talvez seja perdida durante o processo de normalização de imagens da Vertex AI. |
| Rótulos e requisitos da caixa delimitadora | |
|---|---|
| Os requisitos a seguir se aplicam aos conjuntos de dados usados para treinar modelos do AutoML. | |
| Rotular instâncias para treinamento | No mínimo 10 anotações (instâncias). |
| Requisitos de anotação | Para cada rótulo, é preciso ter pelo menos 10 imagens, cada uma com pelo menos uma anotação (caixa delimitadora e rótulo). No entanto, para fins de treinamento de modelo, o ideal é usar cerca de 1.000 anotações por rótulo. Em geral, quanto mais imagens por rótulo você tiver, melhor será o desempenho do seu modelo. |
| Proporção de rótulos (do rótulo mais comum para o menos comum): | O modelo funciona melhor quando há no máximo 100 vezes mais imagens para o rótulo mais comum do que para o menos comum. Para melhorar o desempenho do modelo, recomendamos a remoção de rótulos com frequência muito baixa. |
| Comprimento da borda da caixa delimitadora | Pelo menos 0,01 * comprimento de um lado de uma imagem. Por exemplo, uma imagem de 1.000 * 900 pixels exigiria caixas delimitadoras de pelo menos 10 * 9 pixels. Tamanho mínimo da caixa delimitadora: 8 pixels por 8 pixels. |
| Os requisitos a seguir se aplicam a conjuntos de dados usados para treinar o AutoML ou modelos personalizados treinados. | |
| Caixas delimitadoras por imagem distinta | No máximo 500. |
| Caixas delimitadoras retornadas de uma solicitação de previsão | 100 (padrão), no máximo 500. |
| Dados de treinamento e requisitos do conjunto de dados | |
|---|---|
| Os requisitos a seguir se aplicam aos conjuntos de dados usados para treinar modelos do AutoML. | |
| Características da imagem de treinamento | Os dados de treinamento precisam estar os mais próximos possíveis dos dados que serão usados nas previsões. Por exemplo, se o caso de uso envolver imagens borradas de baixa resolução, como de uma câmera de segurança, seus dados de treinamento precisarão ser compostos de imagens borradas de baixa resolução. Em geral, pense também em fornecer vários ângulos, resoluções e planos de fundo para suas imagens de treinamento. Os modelos da Vertex AI geralmente não preveem rótulos que pessoas não possam atribuir. Então, se um humano não puder ser treinado para atribuir rótulos olhando a imagem por um ou dois segundos, o modelo provavelmente não poderá ser treinado para fazer isso também. |
| Pré-processamento interno de imagem | Depois que as imagens são importadas, a Vertex AI executa um pré-processamento nos dados. As imagens pré-processadas são os dados reais usados para treinar o modelo. O pré-processamento de imagens (redimensionamento) ocorre quando a menor borda da imagem é maior do que 1.024 pixels. No caso em que o lado menor da imagem é maior que 1.024 pixels, esse lado menor é redimensionado para 1.024 pixels. O lado maior e os caixas delimitadoras são reduzidos pela mesma quantidade do lado menor. Consequentemente, todas as anotações reduzidas (caixas delimitadoras e rótulos) serão removidas se tiverem menos de 8 pixels por 8 pixels. Imagens com um lado menor que ou menor que 1.024 pixels não estão sujeitas ao redimensionamento de pré-processamento. |
| Os requisitos a seguir se aplicam a conjuntos de dados usados para treinar o AutoML ou modelos personalizados treinados. | |
| Imagens em cada conjunto de dados | No máximo 150.000 |
| Caixas delimitadoras totais anotadas em cada conjunto de dados | No máximo 1.000.000 |
| Número de rótulos em cada conjunto de dados | No mínimo 1, no máximo 1.000 |
Arquivo de esquema YAML
Use o seguinte arquivo de esquema de acesso público para importar anotações de detecção de objetos de imagem (caixas delimitadoras e rótulos). Esse arquivo de esquema determina o formato dos arquivos de entrada de dados. A estrutura desse arquivo segue o esquema OpenAPI.
gs://google-cloud-aiplatform/schema/dataset/ioformat/image_bounding_box_io_format_1.0.0.yaml
Arquivo de esquema completo
title: ImageBoundingBox description: > Import and export format for importing/exporting images together with bounding box annotations. Can be used in Dataset.import_schema_uri field. type: object required: - imageGcsUri properties: imageGcsUri: type: string description: > A Cloud Storage URI pointing to an image. Up to 30MB in size. Supported file mime types: `image/jpeg`, `image/gif`, `image/png`, `image/webp`, `image/bmp`, `image/tiff`, `image/vnd.microsoft.icon`. boundingBoxAnnotations: type: array description: Multiple bounding box Annotations on the image. items: type: object description: > Bounding box anntoation. `xMin`, `xMax`, `yMin`, and `yMax` are relative to the image size, and the point 0,0 is in the top left of the image. properties: displayName: type: string description: > It will be imported as/exported from AnnotationSpec's display name, i.e. the name of the label/class. xMin: description: The leftmost coordinate of the bounding box. type: number format: double xMax: description: The rightmost coordinate of the bounding box. type: number format: double yMin: description: The topmost coordinate of the bounding box. type: number format: double yMax: description: The bottommost coordinate of the bounding box. type: number format: double annotationResourceLabels: description: Resource labels on the Annotation. type: object additionalProperties: type: string dataItemResourceLabels: description: Resource labels on the DataItem. type: object additionalProperties: type: string
Arquivos de entrada
Linhas JSON
JSON em cada linha:
{
"imageGcsUri": "gs://bucket/filename.ext",
"boundingBoxAnnotations": [
{
"displayName": "OBJECT1_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX",
"annotationResourceLabels": {
"aiplatform.googleapis.com/annotation_set_name": "displayName",
"env": "prod"
}
},
{
"displayName": "OBJECT2_LABEL",
"xMin": "X_MIN",
"yMin": "Y_MIN",
"xMax": "X_MAX",
"yMax": "Y_MAX"
}
],
"dataItemResourceLabels": {
"aiplatform.googleapis.com/ml_use": "test/train/validation"
}
}Observações sobre o campo:
imageGcsUri: o único campo obrigatório.annotationResourceLabels: pode conter qualquer número de pares de strings de chave-valor. O único par de chave-valor reservado pelo sistema é o seguinte:- "aiplatform.googleapis.com/annotation_set_name" : "value"
Em que value é um dos nomes de exibição dos conjuntos de anotações existentes no conjunto de dados.
dataItemResourceLabels: pode conter qualquer número de pares de strings de chave-valor. O único par de chave-valor reservado pelo sistema é o seguinte que especifica o conjunto de uso de machine learning do item de dados:- "aiplatform.googleapis.com/ml_use" : "training/test/validation"
Exemplo de linhas JSON: object_detection.jsonl:
{"imageGcsUri": "gs://bucket/filename1.jpeg", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.3", "yMin": "0.3", "xMax": "0.7", "yMax": "0.6"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "test"}}
{"imageGcsUri": "gs://bucket/filename2.gif", "boundingBoxAnnotations": [{"displayName": "Tomato", "xMin": "0.8", "yMin": "0.2", "xMax": "1.0", "yMax": "0.4"},{"displayName": "Salad", "xMin": "0.0", "yMin": "0.0", "xMax": "1.0", "yMax": "1.0"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename3.png", "boundingBoxAnnotations": [{"displayName": "Baked goods", "xMin": "0.5", "yMin": "0.7", "xMax": "0.8", "yMax": "0.8"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "training"}}
{"imageGcsUri": "gs://bucket/filename4.tiff", "boundingBoxAnnotations": [{"displayName": "Salad", "xMin": "0.1", "yMin": "0.2", "xMax": "0.8", "yMax": "0.9"}], "dataItemResourceLabels": {"aiplatform.googleapis.com/ml_use": "validation"}}
...CSV
Formato CSV:
[ML_USE],GCS_FILE_PATH,[LABEL],[BOUNDING_BOX]*
ML_USE(Opcional). Para fins de divisão de dados ao treinar um modelo. Use TRAINING, TEST, ou VALIDATION. Para mais informações sobre a divisão de dados manual, consulte Sobre a divisão de dados para modelos do AutoML.GCS_FILE_PATHEsse campo contém o URI do Cloud Storage para a imagem. Esses URIs diferenciam maiúsculas de minúsculas.LABELOs rótulos precisam começar com uma letra e conter apenas letras, números e sublinhado (opcional).BOUNDING_BOXUma caixa delimitadora para um objeto na imagem. Especificar uma caixa delimitadora envolve mais de uma coluna.
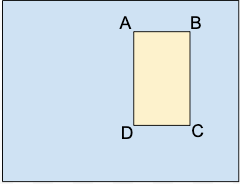
A.X_MIN,Y_MIN
B.X_MAX,Y_MIN
C.X_MAX,Y_MAX
D.X_MIN,Y_MAX
Cada vertex é especificado por valores de coordenadas x, y. As coordenadas são valores flutuantes normalizados [0,1]; 0.0 é X_MIN ou Y_MIN, 1.0 é X_MAX ou Y_MAX.
Por exemplo, uma caixa delimitadora para toda a imagem é expressa como (0.0,0.0,,,1.0,1.0,,) ou (0.0,0.0,1.0,0.0,1.0,1.0,0.0,1.0).
A caixa delimitadora de um objeto pode ser especificada de duas maneiras:
- Dois vértices (dois conjuntos de coordenadas x,y) que são pontos diagonalmente opostos do retângulo:
A.X_MIN,Y_MIN
C.X_MAX,Y_MAX
como mostrado neste exemplo:
A,,C,
X_MIN,Y_MIN,,,X_MAX,Y_MAX,,. - Todos os quatro vértices especificados conforme mostrado em:
X_MIN,Y_MIN,X_MAX,Y_MIN, X_MAX,Y_MAX,X_MIN,Y_MAX,
Se os quatro vértices especificados não formarem um retângulo paralelo às bordas da imagem, a Vertex AIespecifica os vértices que formem um retângulo.
- Dois vértices (dois conjuntos de coordenadas x,y) que são pontos diagonalmente opostos do retângulo:
Exemplo de CSV - object_detection.csv:
test,gs://bucket/filename1.jpeg,Tomato,0.3,0.3,,,0.7,0.6,,
training,gs://bucket/filename2.gif,Tomato,0.8,0.2,,,1.0,0.4,,
gs://bucket/filename2.gif
gs://bucket/filename3.png,Baked goods,0.5,0.7,0.8,0.7,0.8,0.8,0.5,0.8
validation,gs://bucket/filename4.tiff,Salad,0.1,0.2,,,0.8,0.9,,
...