Some Vertex AI service producers require you to connect to their services through Private Service Connect endpoints. These services are listed in the Vertex AI access methods table. They support unidirectional communication from a service consumer's on-premises, multicloud, and VPC workloads to Google-managed Vertex AI services. Clients connect to the endpoint by using internal IP addresses. Private Service Connect performs network address translation (NAT) to route requests to the service.
Service consumers can use their own internal IP addresses to access these Vertex AI services without leaving their VPC networks or using external IP addresses by creating a consumer endpoint. The endpoint connects to services in another VPC network using a Private Service Connect forwarding rule.
On the service producer's side of the private connection, there is a VPC network where your service resources are provisioned. This network is created exclusively for you and contains only your resources.
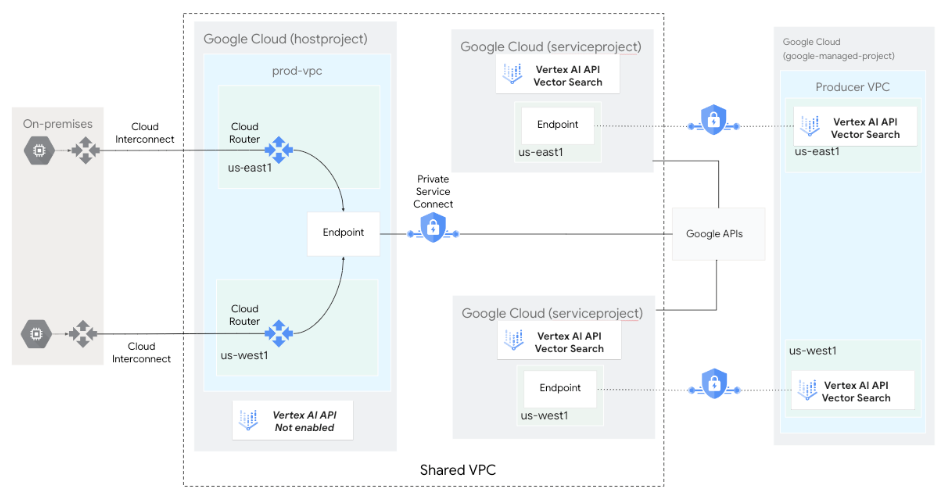
The following diagram shows a Vector Search architecture in which the
Vector Search API is enabled and managed in a service project
(serviceproject) as part of a Shared VPC
deployment. The Vector Search Compute Engine resources
are deployed as a Google-managed Infrastructure-as-a-Service (IaaS) in the
service producer's VPC network.
Private Service Connect endpoints are deployed in the service
consumer's VPC network (hostproject) for index query, in
addition to
Private Service Connect endpoints for Google APIs
for private index creation.
For more information, see Private Service Connect endpoints.
Before you configure Private Service Connect endpoints, learn about access considerations.
Private Service Connect endpoint deployment options
A Private Service Connect service attachment is generated from the producer service (such as Vertex AI). As a consumer, you can gain access to the service producer by deploying a consumer endpoint in one or more VPC networks.
Deployment considerations
The following sections discuss considerations for communication from your on-premises, multicloud, and VPC workloads to Google-managed Vertex AI services.
Private Service Connect backends
Google does not support using Private Service Connect backends with Vertex AI online prediction endpoints.
IP advertisement
When you use Private Service Connect to connect to services in another VPC network, you choose an IP address from a regular subnet in your VPC network.
By default, the Cloud Router will advertise regular VPC subnets unless custom advertisement mode is configured. For more information, see Custom advertisement mode.
The IP address for the consumer endpoint must be in the same region as the service producer's service attachment. For more information, see Service attachments and Access published services through endpoints.
Firewall rules
You must update the firewall rules for the VPC network that connects your on-premises and multicloud environments to Google Cloud to allow egress traffic to the Private Service Connect endpoint subnet. For more information, see Firewall rules.