机器学习模型通常被称为“黑盒”,即使其设计者也无法解释模型生成特定推理的方式或原因。Vertex Explainable AI 提供基于特征和基于样本的说明,以更好地了解模型决策。
知道模型的行为方式以及训练数据集对模型的影响,构建或使用机器学习功能的任何人员就能够改进模型、建立对推理的信心,以及了解问题发生的时间和原因。
基于样本的解释
通过基于样本的说明,Vertex AI 使用最邻近对象搜索来返回与输入最相似的样本列表(通常来自训练集)。由于通常我们希望类似的输入产生类似的推理,因此我们可以使用这些样本来探索和解释模型的行为。
基于样本的说明在很多情况下都非常有用:
改进数据或模型:基于样本的说明的核心用例之一是帮助您了解模型在推理中做出某些错误的原因,并利用这些分析结果改进模型您的数据或模型。 为此,请先选择您感兴趣的测试数据。这可能是由业务需求或启发法(例如模型出现最严重的错误)驱动的。
例如,假设我们有一个模型,将图片归类为鸟类或飞机,并且以高置信度错误地将以下鸟类归类为飞机。您可以使用基于样本的说明从训练集中检索类似图片,从而找出具体问题。

由于其所有的说明都是来自飞机类别的深色轮廓,因此就表明要获取更多鸟形。
但是,如果说明主要来自鸟类,这表明我们的模型即使在数据丰富时也无法学习关系,我们应考虑增加模型复杂性(例如,添加更多层)。
解读新数据:假设您的模型经过训练,可以对鸟类和飞机进行分类,但在现实世界中,该模型还会遇到风筝、无人机和直升机的图像。如果您的最邻近数据集包含一些风筝、无人机和直升机的带标签图片,您可以使用基于样本的说明,通过应用其最邻近数据集中最常出现的标签来对新图片进行分类。之所以有这种可能性,是因为我们希望风筝的潜在表示与鸟类或飞机的表示不同,并且更像是最邻近数据集内带标签的风筝。
检测异常值:直观地说,如果某个实例与训练集中的所有数据相离很远,则可能属于离群值。已知神经网络会对其错误过于自信,从而掩盖其错误。使用基于样本的说明监控模型有助于识别最严重的离群值。
主动学习:基于样本的说明可帮助您识别可能受益于人工加标签的实例。如果标签添加速度缓慢或费用高昂,这尤为有用,可确保从有限的标签资源中获取最丰富的数据集。
例如,假设我们有一个将医疗患者归类为感冒或流感的模型。如果一名患者被归类为患有流感,并且她基于样本的所有说明都来自流感类别,那么医生可以对模型的推理更有信心,而无需更仔细地观察。但是,如果某些说明来自流感类别,而有些说明来自感冒类别,则需要获得医生的意见。这将形成这样一个数据集,其中困难的实例具有更多标签,从而使下游模型更容易学习复杂的关系。
如需创建支持基于样本的说明的模型,请参阅配置基于样本的说明。
支持的模型类型
任何可以为输入提供嵌入(潜在表示法)的 TensorFlow 模型都受支持。不支持基于树的模型(例如决策树)。尚不支持其他框架中的模型,例如 PyTorch 或 XGBoost。
对于深度神经网络,我们通常假定较高层(更接近输出层)学到了“有意义”的东西,因此通常会选择倒数第二层进行嵌入。您可以试验几个不同的层,调查获得的示例,并根据一些定量(类别匹配)或定性(看起来合理)度量选择层。
有关如何从 TensorFlow 模型中提取嵌入和执行最邻近对象搜索的演示说明,请参阅基于样本的解释笔记本。
基于功能的解释
Vertex Explainable AI 将特征归因集成到 Vertex AI 中。本部分提供 Vertex AI 提供的特征归因方法的简要概念概览。
特征归因指出了模型中每个特征对每个给定实例的推理结果的影响程度。请求推理时,您会获得适合您模型的值。请求说明时,您会获得推理结果以及特征归因信息。
特征归因可处理表格数据,并内置可视化功能以用于处理图片数据。请参考以下示例:
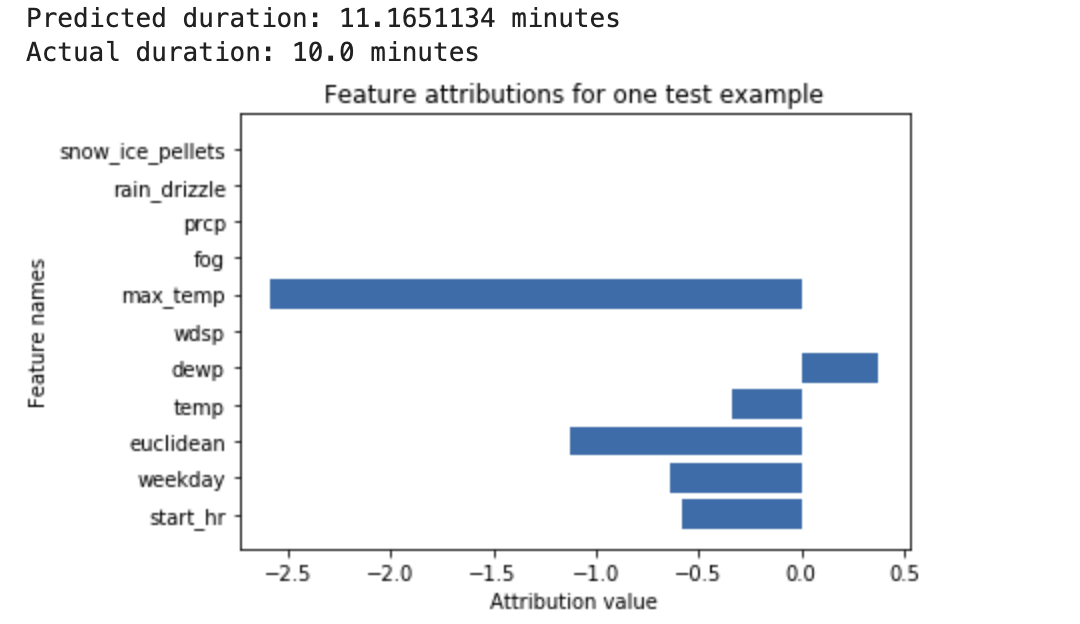
深度神经网络经训练后可根据天气数据和之前的骑行共享数据来预测骑行时长。如果您仅使用此模型请求推理结果,则可以在几分钟后获得预计的骑行时长。如果您请求说明,则会获得预计的骑行时长,以及说明请求中每个特征的归因分数。归因分数显示特征对推理值相对于指定基准值的变化的影响程度。选择对模型有意义的基准,在本例中,基准为骑行时长的中间值。您可以绘制特征归因分数,查看哪些特征对生成的推理结果影响最大:
图片分类模型经训练后可预测给定图片是否包含狗或猫。如果您请求使用此模型对一组新图片进行推理,则会收到每张图片的推理结果(“猫”或“狗”)。如果您请求说明,则会获得预测的类,并且图片上还会附加一个叠加图层,显示图片中哪些像素对生成的推理结果影响最大:

包含特征归因叠加图层的猫的照片 
包含特征归因叠加图层的狗的照片 训练图片分类模型以预测图片中花的种类。如果您请求使用此模型对一组新图片进行推理,则会收到每张图片的推理结果(“雏菊”或“蒲公英”)。如果您请求说明,则会获得预测的类,并且图片上还会附加一个叠加图层,显示图片中哪些区域对生成的推理结果影响最大:

包含特征归因叠加图层的雏菊的照片
支持的模型类型
所有类型的模型(包括 AutoML 和自定义训练模型)、框架(TensorFlow、scikit、XGBoost)、BigQuery 机器学习模型和模态(图片、文本、表格、视频)都支持特征归因。
如需使用特征归因,请在将模型上传或注册到 Vertex AI Model Registry 时配置模型以使用特征归因。
此外,对于以下类型的 AutoML 模型,特征归因已集成到 Google Cloud 控制台中:
- AutoML 图片模型(仅限分类模型)
- AutoML 表格模型(仅限分类和回归模型)
对于集成的 AutoML 模型类型,您可以在训练期间在 Google Cloud 控制台中启用特征归因,并查看模型特征重要性从总体了解模型,以及查看局部特征重要性了解在线和批量推理。
对于未集成的 AutoML 模型类型,您仍然可以在将模型工件上传到 Vertex AI 模型注册表时导出模型工件并配置特征归因,以启用特征归因。
优点
如果您在训练数据集中检查特定实例并汇总特征归因,就可以更深入地了解模型的工作原理。请考虑以下优点:
调试模型:特征归因有助于检测出数据中通常被标准模型评估技术忽略的问题。
例如,某个图片病理学模型在一个胸部 X 光片测试数据集中获得了好得令人生疑的结果。特征归因表明,模型的高准确度依赖于图片中放射科专家所做的记号。如需详细了解此示例,请参阅 AI Explanations 白皮书。
优化模型:您可以识别和移除不太重要的特征,从而生成更有效率的模型。
特征归因方法
每种特征归因方法都基于 Shapley 值,这是一种根据特定结果为游戏中的每位玩家分配积分的合作博弈论算法。应用到机器学习模型中,就意味着每个模型特征都被视作游戏中的一个“玩家”Vertex Explainable AI 会根据特定推理结果按比例为每个特征分配积分。
采样 Shapley 方法
采样 Shapley 可以提供精确 Shapley 值的近似采样值。 AutoML Tables 模型使用采样 Shapley 方法获得特征重要性。采用 Shapley 非常适合这些模型,模型是树和神经网络的元集成。
如需深入了解采样的 Shapley 方法的工作原理,请参阅论文限定采样 Shapley 值逼近法的估计误差。
积分梯度方法
在积分梯度方法中,推理结果输出的梯度根据输入的特征沿积分路径进行计算。
- 梯度按调节参数的不同间隔值进行计算。 高斯求积规则可确定每个间隔的大小。(对于图片数据,可将此调节参数想象成一个“滑块”,它能够将图片的所有像素调节为黑色。)
- 梯度集成如下:
- 积分是使用加权平均值进行近似计算的。
- 计算平均梯度和原始输入的元素积。
如需了解此流程应用到相应图片的直观说明,请参阅将深度网络的推理结果归因于输入特征这篇博文。积分梯度原文(深度网络的公理化归因)作者在前面的博文中展示了相应图片在流程的每个步骤中的效果。
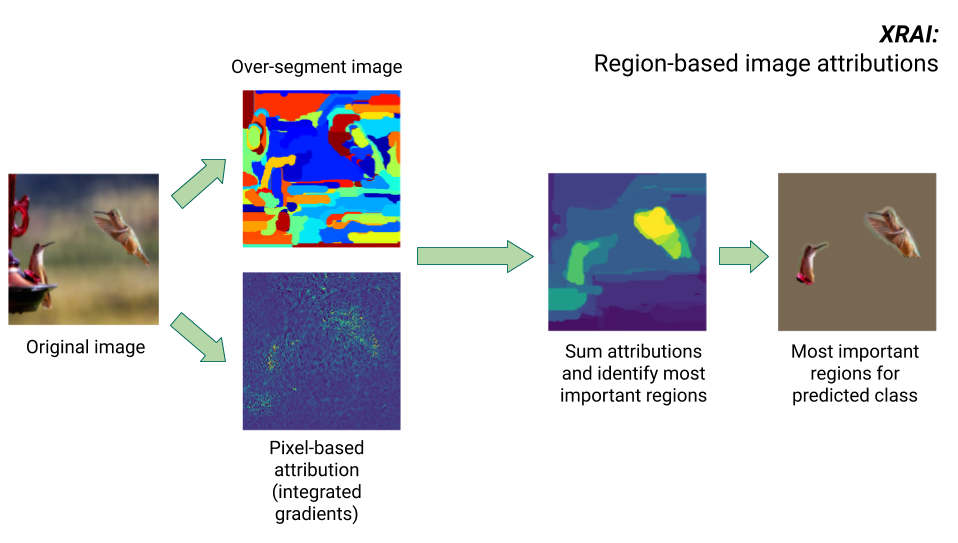
XRAI 方法
XRAI 方法结合了积分梯度方法和其他步骤,以确定图片的哪些区域对给定类别推理结果的贡献最大。
- 像素级别归因:XRAI 为输入图片执行像素级别归因。在此步骤中,XRAI 使用带有黑色基准和白色基准的积分梯度方法。
- 过度分割:XRAI 不受像素级别归因的影响,会对图片进行过度分割,创建一个由小区域拼凑而成的对象。XRAI 使用 Felzenswalb 的基于图表的方法创建图片细分。
- 区域选择:XRAI 会汇总每个细分内的像素级归因,以确定其归因密度。XRAI 使用这些值对每个细分进行排名,然后按照从正到负的顺序对细分进行排序。这决定了图片的哪个区域最显着,或对给定的类别推理结果贡献最大。
比较特征归因方法
Vertex Explainable AI 提供了三种用于特征归因的方法:采样 Shapley、积分梯度和 XRAI。
| 方法 | 基本说明 | 推荐的模型类型 | 实际使用示例 | 兼容的 Vertex AI Model 资源 |
|---|---|---|---|---|
| 采样 Shapley | 为每个特征的结果分配积分,并考虑特征的不同排列。此方法可以提供精确 Shapley 值的近似采样值。 | 不可微分的模型,例如树和神经网络的集成学习 |
|
|
| 积分梯度 | 梯度方法可以高效计算与 Shapley 值具有相同公理属性的特征归因。 | 可微分模型,例如神经网络。特别推荐用于具有大型特征空间的模型。 建议用于低对比度图片,例如 X 光。 |
|
|
| XRAI(带排名区域积分的说明) | 根据积分梯度方法,XRAI 会评估图片的重叠区域,以创建显著图来突出显示相关图片区域(而非像素)。 | 接受图片输入的模型。特别推荐用于自然图片,即任何包含多个对象的现实场景。 |
|
|
如需查看归因方法的更全面的比较,请参阅 AI Explanations 白皮书。
可微分和不可微分的模型
在可微分的模型中,您可以计算 TensorFlow 图中所有运算的导数。该属性有助于在此类模型中使用反向传播算法。例如,神经网络可微分。如需获取可微分模型的特征归因,请使用积分梯度方法。
积分梯度方法不适用于不可微分的模型。详细了解如何对不可微分的输入进行编码,以使用积分梯度方法。
不可微分的模型在 TensorFlow 图中包含不可微分的运算,例如执行解码和舍入任务的运算。例如,作为树和神经网络的集成学习构建的模型是不可微分的。若要获取不可微分的模型的特征归因,请使用采样 Shapley 方法。采样 Shapley 还适用于可微分的模型,但在这种情况下,会耗费更多不必要的计算资源。
概念限制
请考虑特征归因的以下限制:
特征归因(例如 AutoML 提供的局部特征重要性)是针对每一次具体的推理进行的解释。 分析某次推理的特征归因或许能提供有用的分析洞见,但该分析洞见未必能普适于该实例所属的整个类,或整个模型。
如需获得更通用的 AutoML 模型数据分析,请参阅模型特征重要性。如需获得针对其他模型的更多数据洞见,请通过数据集内的子集或整个数据集聚合归因。
尽管特征归因有助于模型调试,但它们并不总能清晰地指明一个问题是源于模型本身,还是源于训练模型所用的数据。您必须尽量正确地做出判断,并诊断常见的数据问题,以筛查出可能的原因。
特征归因与复杂模型中的推理一样,也会受到类似的反对性攻击。
如需详细了解限制,请参阅高层级限制列表和 AI Explanations 白皮书。
引用
对于特征归因,采样 Shapley、积分梯度和 XRAI 的实现分别基于下列参考文档:
如需详细了解 Vertex Explainable AI 的实现,请阅读 AI Explanations 白皮书。
笔记本
如需开始使用 Vertex Explainable AI,请使用以下笔记本:
| 笔记本 | 可解释性方法 | 机器学习框架 | 模态 | 任务 |
|---|---|---|---|---|
| GitHub 链接 | 基于示例的解释 | TensorFlow | 图片 | 训练一个预测所提供的输入图片的类别的分类模型并获取在线说明 |
| GitHub 链接 | 基于特征 | AutoML | 表格 | 训练一个预测银行自定义是否购买了定期存款的二元分类模型并获取批量说明 |
| GitHub 链接 | 基于特征 | AutoML | 表格 | 训练一个预测鸢尾花种类的分类模型并获取在线说明 |
| GitHub 链接 | 基于特征(采样的 Shapley) | scikit-learn | 表格 | 训练一个预测出租车费用的线性回归模型并获取在线说明 |
| GitHub 链接 | 基于特征(积分梯度) | TensorFlow | 图片 | 训练一个预测所提供的输入图片的类别的分类模型并获取批量说明 |
| GitHub 链接 | 基于特征(积分梯度) | TensorFlow | 图片 | 训练一个预测所提供的输入图片的类别的分类模型并获取在线说明 |
| GitHub 链接 | 基于特征(积分梯度) | TensorFlow | 表格 | 训练一个预测房屋的中位价的回归模型并获取批量说明 |
| GitHub 链接 | 基于特征(积分梯度) | TensorFlow | 表格 | 训练一个预测房屋的中位价的回归模型并获取在线说明 |
| GitHub 链接 | 基于特征(采样的 Shapley) | TensorFlow | text | 训练一个使用评价文本将电影评论分类为正面或负面的 LSTM 模型并获取在线说明 |
教育资源
以下资源提供了更多有用的教育材料: