如要使用範例式解釋,您必須在將 Model 資源匯入或上傳至 Model Registry 時,指定 explanationSpec 來設定解釋。
接著,當您要求線上說明時,可以指定要求中的 ExplanationSpecOverride,覆寫部分設定值。系統不支援批次說明,因此您無法要求這類說明。
本頁說明如何設定及更新這些選項。
匯入或上傳模型時設定說明
開始之前,請確認您具備以下項目:
內含模型構件的 Cloud Storage 位置。您的模型必須是深層類神經網路 (DNN) 模型,並提供層或簽章的名稱,其輸出內容可用做潛在空間,或者您可以提供直接輸出嵌入內容 (潛在空間表示法) 的模型。這個潛在空間會擷取用於生成說明的示例表示法。
Cloud Storage 位置,內含要建立索引的執行個體,以供近似最鄰近搜尋。詳情請參閱輸入資料規定。
主控台
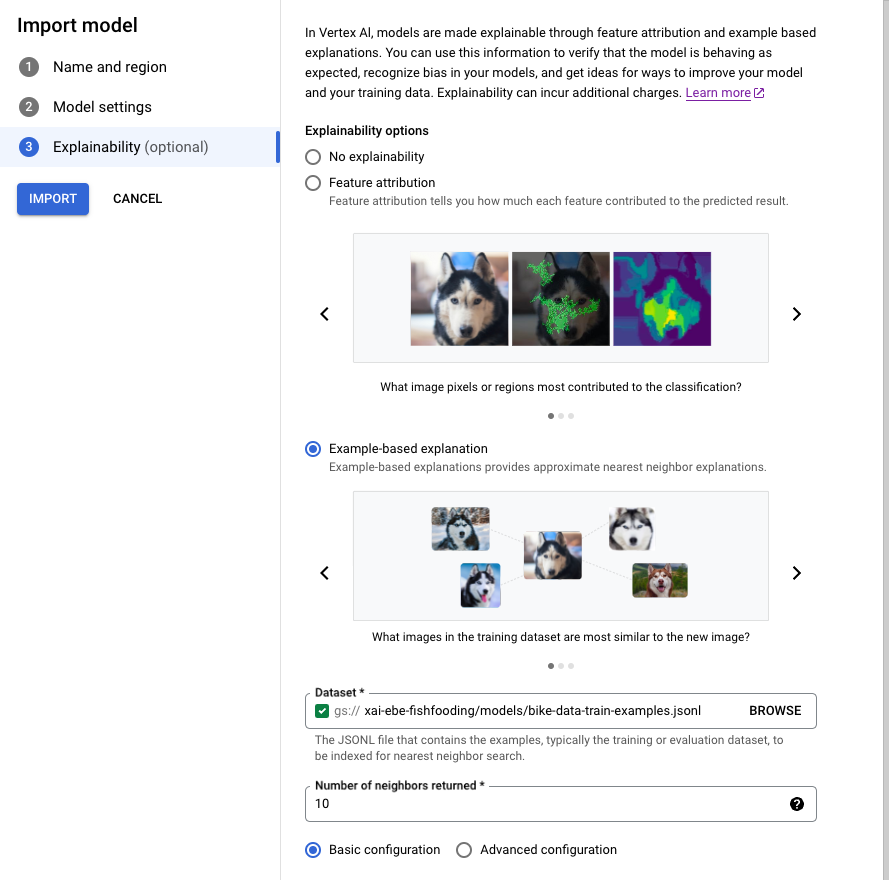
請按照指南,使用 Google Cloud 控制台匯入模型。
在「可解釋性」分頁中,選取「範例式解釋」並填寫欄位。
如要瞭解各個欄位,請參閱 Google Cloud 控制台中的提示 (如下所示),以及 Example 和 ExplanationMetadata 的參考說明文件。
gcloud CLI
- 在您的本機環境中,將下列
ExplanationMetadata寫入 JSON 檔案。檔案名稱不拘,但以本範例來說,請將檔案命名為explanation-metadata.json:
{
"inputs": {
"my_input": {
"inputTensorName": "INPUT_TENSOR_NAME",
"encoding": "IDENTITY",
},
"id": {
"inputTensorName": "id",
"encoding": "IDENTITY"
}
},
"outputs": {
"embedding": {
"outputTensorName": "OUTPUT_TENSOR_NAME"
}
}
}
- (選用) 如果您要指定完整
NearestNeighborSearchConfig,請在本地環境中將下列內容寫入 JSON 檔案。檔案名稱不拘,但以本範例來說,請將檔案命名為search_config.json:
{
"contentsDeltaUri": "",
"config": {
"dimensions": 50,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
- 執行下列指令來上傳
Model。
如果您使用 Preset 搜尋設定,請移除 --explanation-nearest-neighbor-search-config-file 標記。如果您指定 NearestNeighborSearchConfig,請移除 --explanation-modality 和 --explanation-query 標記。
與範例式解釋最相關的標記會以粗體顯示。
gcloud ai models upload \
--region=LOCATION \
--display-name=MODEL_NAME \
--container-image-uri=IMAGE_URI \
--artifact-uri=MODEL_ARTIFACT_URI \
--explanation-method=examples \
--uris=[URI, ...] \
--explanation-neighbor-count=NEIGHBOR_COUNT \
--explanation-metadata-file=explanation-metadata.json \
--explanation-modality=IMAGE|TEXT|TABULAR \
--explanation-query=PRECISE|FAST \
--explanation-nearest-neighbor-search-config-file=search_config.json
詳情請參閱 gcloud ai models upload。
-
上傳動作會傳回
OPERATION_ID,可用於檢查作業何時完成。您可以輪詢作業狀態,直到回應包含"done": true為止。使用 gcloud ai operations describe 指令輪詢狀態,例如:gcloud ai operations describe <operation-id>作業完成後才能要求說明。 視資料集大小和模型架構而定,這個步驟可能需要數小時才能建構用於查詢範例的索引。
REST
使用任何要求資料之前,請先替換以下項目:
- PROJECT
- LOCATION
如要瞭解其他預留位置,請參閱 Model、explanationSpec 和 Examples。
如要進一步瞭解如何上傳模型,請參閱 upload 方法和「匯入模型」一文。
下方的 JSON 要求主體指定 Preset 搜尋設定。或者,您也可以指定完整NearestNeighborSearchConfig。
HTTP 方法和網址:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/models:upload
JSON 要求主體:
{
"model": {
"displayName": "my-model",
"artifactUri": "gs://your-model-artifact-folder",
"containerSpec": {
"imageUri": "us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-11:latest",
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": ["gs://your-examples-folder"]
},
"neighborCount": 10,
"presets": {
"modality": "image"
}
}
},
"metadata": {
"outputs": {
"embedding": {
"output_tensor_name": "embedding"
}
},
"inputs": {
"my_fancy_input": {
"input_tensor_name": "input_tensor_name",
"encoding": "identity",
"modality": "image"
},
"id": {
"input_tensor_name": "id",
"encoding": "identity"
}
}
}
}
}
}
如要傳送要求,請展開以下其中一個選項:
您應該會收到如下的 JSON 回應:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/models/MODEL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.UploadModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-01-08T01:21:10.147035Z",
"updateTime": "2022-01-08T01:21:10.147035Z"
}
}
}
上傳動作會傳回 OPERATION_ID,可用於檢查作業何時完成。您可以輪詢作業狀態,直到回應包含 "done": true 為止。使用 gcloud ai operations describe 指令輪詢狀態,例如:
gcloud ai operations describe <operation-id>
作業完成後才能要求說明。 視資料集大小和模型架構而定,這個步驟可能需要數小時才能建構用於查詢範例的索引。
Python
請參閱圖片分類範例說明筆記本中的「上傳模型」一節。
NearestNeighborSearchConfig
下列 JSON 要求主體示範如何在 upload 要求中指定完整的 NearestNeighborSearchConfig (而非預設值)。
{
"model": {
"displayName": displayname,
"artifactUri": model_path_to_deploy,
"containerSpec": {
"imageUri": DEPLOY_IMAGE,
},
"explanationSpec": {
"parameters": {
"examples": {
"gcsSource": {
"uris": [DATASET_PATH]
},
"neighborCount": 5,
"nearest_neighbor_search_config": {
"contentsDeltaUri": "",
"config": {
"dimensions": dimensions,
"approximateNeighborsCount": 10,
"distanceMeasureType": "SQUARED_L2_DISTANCE",
"featureNormType": "NONE",
"algorithmConfig": {
"treeAhConfig": {
"leafNodeEmbeddingCount": 1000,
"fractionLeafNodesToSearch": 1.0
}
}
}
}
}
},
"metadata": { ... }
}
}
}
這些表格列出 NearestNeighborSearchConfig 的欄位。
| 欄位 | |
|---|---|
dimensions |
這是必要旗標,輸入向量的維度數量。僅適用於密集嵌入。 |
approximateNeighborsCount |
如果使用 tree-AH 演算法,則為必要項目。 執行確切重新排序之前,要透過近似搜尋尋找的預設鄰點數量。確切重新排序程序會使用成本較高的距離計算,重新排序近似搜尋演算法傳回的結果。 |
ShardSize |
ShardSize
每個分片的容量。如果索引很大,系統會根據指定的資料分割大小進行分割。在服務期間,每個分片都會在個別節點上提供服務,並可獨立擴充。 |
distanceMeasureType |
最鄰近搜尋所使用的距離度量。 |
featureNormType |
要針對各個向量執行的正規化類型。 |
algorithmConfig |
oneOf:
Vector Search 用於高效率搜尋的演算法設定。僅適用於密集嵌入。
|
DistanceMeasureType
| 列舉 | |
|---|---|
SQUARED_L2_DISTANCE |
歐幾里得 (L2) 距離 |
L1_DISTANCE |
曼哈頓 (L1) 距離 |
DOT_PRODUCT_DISTANCE |
預設值。定義為點積的負數。 |
COSINE_DISTANCE |
餘弦距離。強烈建議您將 DOT_PRODUCT_DISTANCE 與 UNIT_L2_NORM 搭配使用,而不要使用 COSINE 距離。我們的演算法已針對 DOT_PRODUCT 距離進行最佳化,如將 DOT_PRODUCT 距離與 UNIT_L2_NORM 搭配使用,在數學上就等同於 COSINE 距離,並能產生相同排名。 |
FeatureNormType
| 列舉 | |
|---|---|
UNIT_L2_NORM |
單位 L2 正規化類型。 |
NONE |
預設值。未指定任何正規化類型。 |
TreeAhConfig
這些是 tree-AH 演算法 (淺層樹狀結構 + 不對稱雜湊) 的選取欄位。
| 欄位 | |
|---|---|
fractionLeafNodesToSearch |
double |
| 分葉節點的預設比率,任何查詢都有可能因此而經搜尋。 必須介於 0.0 到 1.0 之間 (不含 0.0 與 1.0)。如未設定,則預設值為 0.05。 | |
leafNodeEmbeddingCount |
int32 |
| 每個分葉節點的嵌入項目數量。如未設定,則預設值為 1000。 | |
leafNodesToSearchPercent |
int32 |
已淘汰,請改用 fractionLeafNodesToSearch。任何查詢可能獲得搜尋的預設分葉節點百分比。 必須介於 1 到 100 之間 (含 1 和 100)。如未設定,預設值為 10 (即 10%)。 |
|
BruteForceConfig
這個選項會針對每個查詢,在資料庫中實作標準線性搜尋。沒有可供暴力搜尋設定的欄位。如要選取這個演算法,請將 BruteForceConfig 的空物件傳遞至 algorithmConfig。
輸入資料規定
將資料集上傳至 Cloud Storage 位置。確認檔案為 JSON Lines 格式。
檔案必須採用 JSON Lines 格式。以下範例來自圖片分類示例式說明筆記本:
{"id": "0", "bytes_inputs": {"b64": "..."}}
{"id": "1", "bytes_inputs": {"b64": "..."}}
{"id": "2", "bytes_inputs": {"b64": "..."}}
更新索引或設定
您可以使用 Vertex AI 更新模型的最近鄰索引或Example設定。如果您想更新模型,但不想重新為資料集建立索引,這項功能就非常實用。舉例來說,如果模型的索引包含 1,000 個執行個體,且您想再新增 500 個執行個體,可以呼叫 UpdateExplanationDataset 將執行個體新增至索引,不必重新處理原始的 1,000 個執行個體。
如要更新說明資料集:
Python
def update_explanation_dataset(model_id, new_examples):
response = clients["model"].update_explanation_dataset(model=model_id, examples=new_examples)
update_dataset_response = response.result()
return update_dataset_response
PRESET_CONFIG = {
"modality": "TEXT",
"query": "FAST"
}
NEW_DATASET_FILE_PATH = "new_dataset_path"
NUM_NEIGHBORS_TO_RETURN = 10
EXAMPLES = aiplatform.Examples(presets=PRESET_CONFIG,
gcs_source=aiplatform.types.io.GcsSource(uris=[NEW_DATASET_FILE_PATH]),
neighbor_count=NUM_NEIGHBORS_TO_RETURN)
MODEL_ID = 'model_id'
update_dataset_response = update_explanation_dataset(MODEL_ID, EXAMPLES)
使用須知:
UpdateExplanationDataset作業完成後,model_id仍維持不變。UpdateExplanationDataset作業只會影響Model資源,不會更新任何相關聯的DeployedModel。也就是說,deployedModel的索引包含部署時的資料集。如要更新deployedModel的索引,必須將更新後的模型重新部署至端點。
在取得線上說明時覆寫設定
要求說明時,您可以指定 ExplanationSpecOverride 欄位,即時覆寫部分參數。
視應用程式而定,您可能希望對傳回的說明類型設下某些限制。舉例來說,為確保解釋內容的多樣性,使用者可以指定擁擠程度參數,規定解釋內容中不得過度呈現單一類型的範例。具體來說,如果使用者想瞭解模型為何將鳥類標示為飛機,他們可能不希望看到太多鳥類範例,因為這無助於調查根本原因。
下表列出可為範例說明要求覆寫的參數:
| 屬性名稱 | 屬性值 | 說明 |
|---|---|---|
| neighborCount | int32 |
要傳回做為說明的範例數量 |
| crowdingCount | int32 |
傳回相同擁擠標記的樣本數量上限 |
| allow | String Array |
說明面板可顯示的標記 |
| deny | String Array |
不允許說明面板顯示的代碼 |
如要進一步瞭解這些參數,請參閱「向量搜尋篩選」。
以下是包含覆寫內容的 JSON 要求主體範例:
{
"instances":[
{
"id": data[0]["id"],
"bytes_inputs": {"b64": bytes},
"restricts": "",
"crowding_tag": ""
}
],
"explanation_spec_override": {
"examples_override": {
"neighbor_count": 5,
"crowding_count": 2,
"restrictions": [
{
"namespace_name": "label",
"allow": ["Papilloma", "Rift_Valley", "TBE", "Influenza", "Ebol"]
}
]
}
}
}
後續步驟
以下是根據範例的 explain 要求所傳回的回應範例:
[
{
"neighbors":[
{
"neighborId":"311",
"neighborDistance":383.8
},
{
"neighborId":"286",
"neighborDistance":431.4
}
],
"input":"0"
},
{
"neighbors":[
{
"neighborId":"223",
"neighborDistance":471.6
},
{
"neighborId":"55",
"neighborDistance":392.7
}
],
"input":"1"
}
]
定價
請參閱定價頁面中以範例為基礎的說明。