Como cientista de dados, este é um fluxo de trabalho comum: treinar um modelo localmente (no meu notebook), registrar os parâmetros, registrar as métricas de série temporal de treinamento no Vertex AI TensorBoard e registrar as métricas de avaliação.
Como cientista de dados, quero reutilizar o código de pré-processamento de dados que outras pessoas da minha empresa escreveram para simplificar e padronizar toda a complexa preparação de dados que fazemos. Quero conseguir:
- Usar uma biblioteca de pré-processamento de dados Python para limpar um conjunto de dados na memória (um Dataframe do Pandas) em um notebook.
- Treine um modelo usando o Keras (novamente em um notebook).
Notebook: experimentação de modelo com dados pré-processados
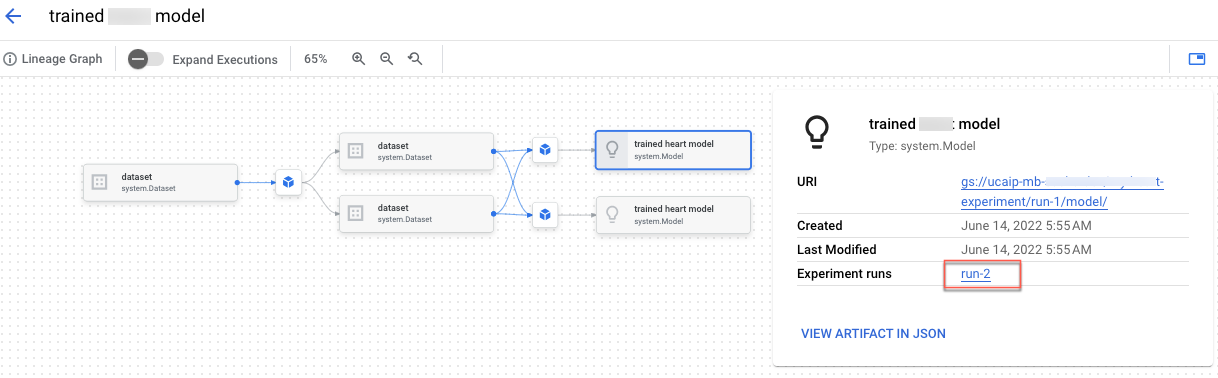
No notebook "Criar uma linhagem do Vertex AI Experiments para treinamento personalizado", você vai aprender a integrar o código de pré-processamento nos experimentos da Vertex AI. Além disso, você criará a linhagem do experimento que permite registrar, analisar, depurar, auditar metadados e artefatos produzidos durante a jornada de ML.
É possível conferir a linhagem do artefato no console do Google Cloud .