Como científico de datos, este es un flujo de trabajo habitual: entrenar un modelo localmente (en mi cuaderno), registrar los parámetros, registrar las métricas de series temporales de entrenamiento en Vertex AI TensorBoard y registrar las métricas de evaluación.
Como científico de datos, quiero poder reutilizar el código de preprocesamiento de datos que han escrito otros miembros de mi empresa para simplificar y estandarizar todas las complejas tareas de gestión de datos que realizamos. Quiero poder hacer lo siguiente:
- Usa una biblioteca de preprocesamiento de datos de Python para limpiar un conjunto de datos en memoria (un DataFrame de Pandas) en un cuaderno.
- Entrena un modelo con Keras (de nuevo en un cuaderno).
Cuaderno: experimentación de modelos con datos preprocesados
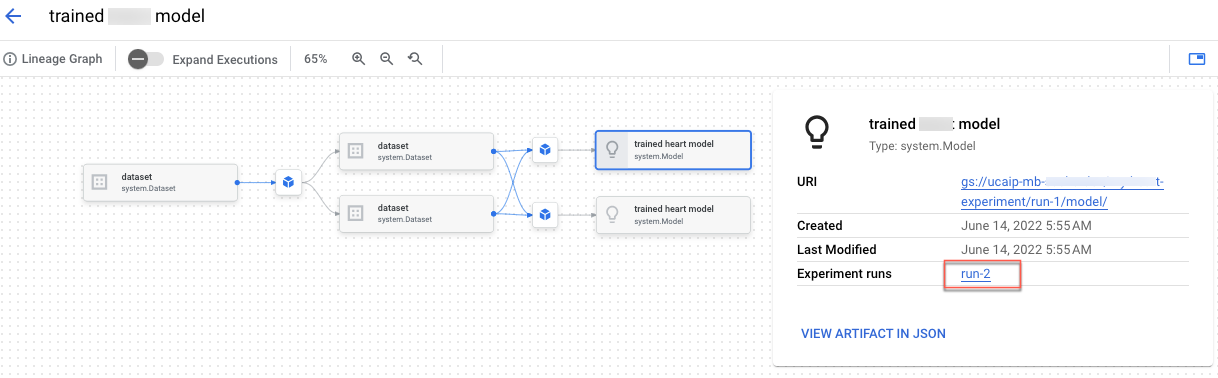
En el cuaderno "Build Vertex AI Experiments lineage for custom training" (Crear un linaje de experimentos de Vertex AI para el entrenamiento personalizado), aprenderás a integrar código de preprocesamiento en Vertex AI Experiments. También crearás el linaje de experimentos, que te permite registrar, analizar, depurar y auditar los metadatos y los artefactos que se producen a lo largo de tu proceso de aprendizaje automático.
Puedes ver el linaje de los artefactos en la Google Cloud consola.