For image data, you can import labeled or unlabeled data and add labels using the Google Cloud console. You can also delete or add new labels to existing labeled datasets.
To learn how to import your data, see the Prepare data page of the data type and objective that you're working with on the Training overview page. Continue with the respective Create dataset page for your data type and objective.
After creating the dataset and importing the unlabeled data, you will be in
Browse mode.

How to add labels
Instructions for labeling objectives are provided here.
The images you have just imported in the dataset are unlabeled, as expected.
Classification
When in Browse mode, and the dataset with the unlabeled images is selected, you can see your uploaded images.
- Click Add new label and enter your new label.
- Click Done.
Repeat for each label you want to add. - Select the image you want to label.
The list of labels appears. - Select the label you want to associate with the image.
- Click Save.
Classification
When in Browse mode, and the dataset with the unlabeled images is selected, you can see your uploaded images.
- Click Add new label and enter your new label.
- Click Done.
Repeat for each label you want to add. - Select the image you want to label.
The list of labels appears. - Select the label you want to associate with the image.
- Click Save.
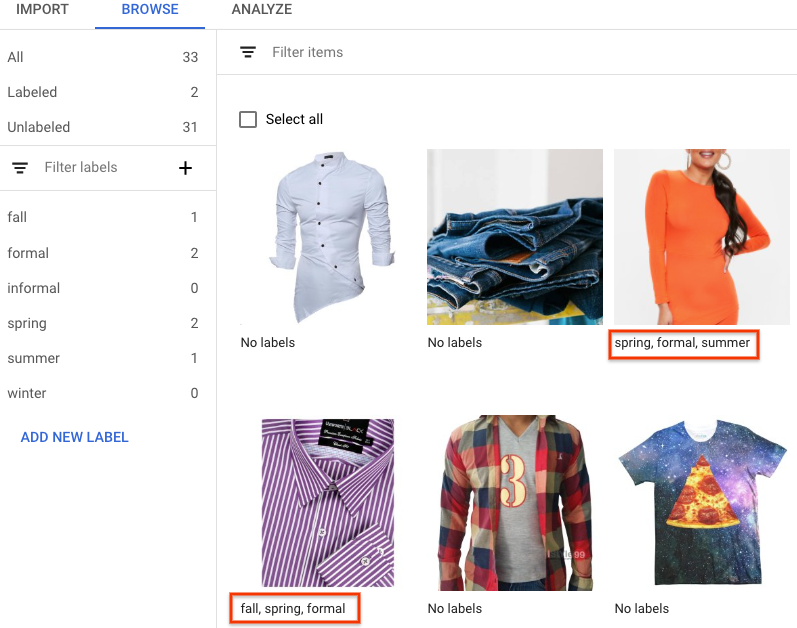
- You can view the labels applied to each image in the Browse tab.
Object detection
When in Browse mode, and the dataset with the unlabeled images is selected, you can see your uploaded images.
- Click Add new label and enter your new label.
- Click Done.
Repeat for each label you want to add. - Select the image you want to label.
- The list of labels objects appears, if there are any.
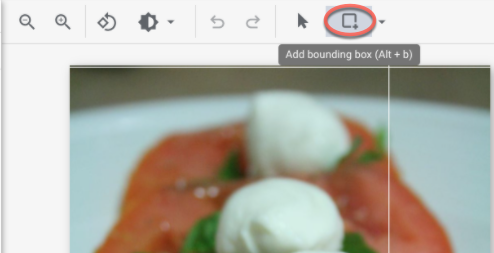
- In the add annotation window, select the Add bounding box button to add an object
bounding box to the image.
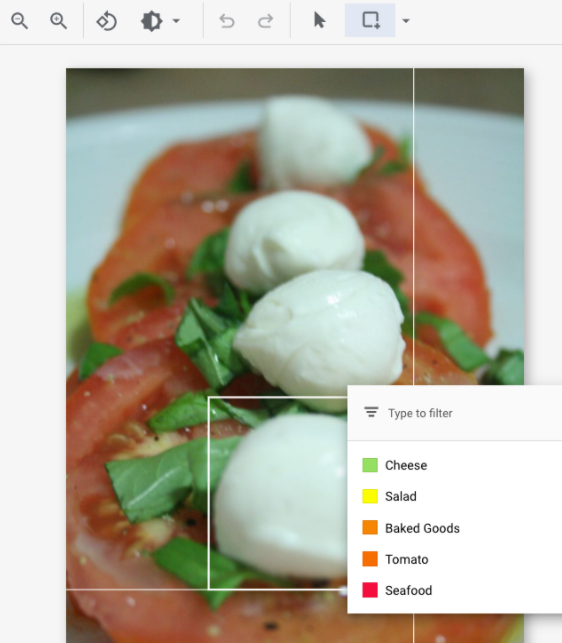
- After drawing a bounding box, a list of labels to apply to the object will appear.
Choose the appropriate label.
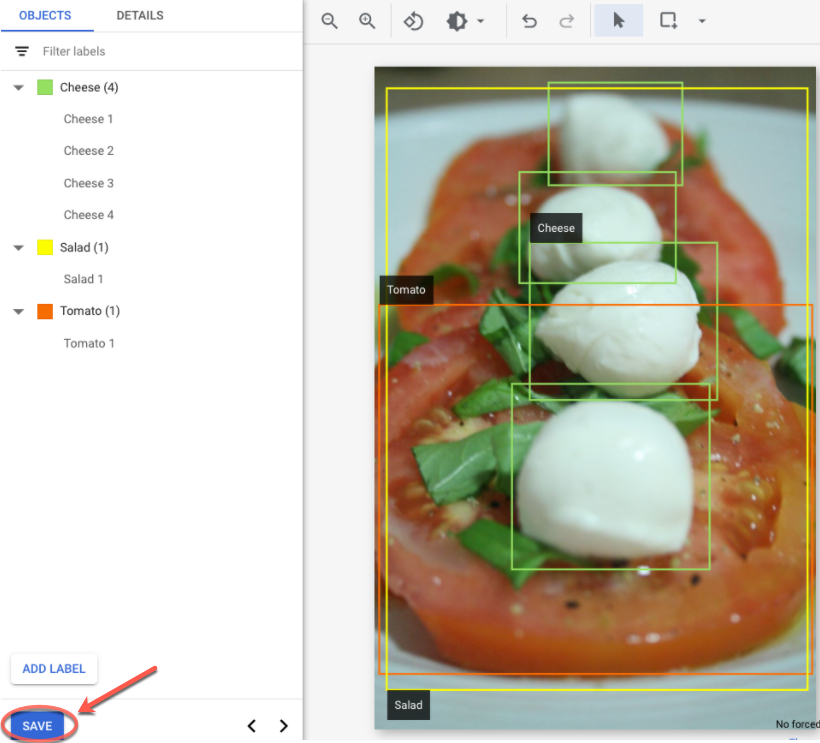
- After you have added all labels and bounding boxes, click Save to update the
image's annotations.
What's next
- Train your AutoML model using the Google Cloud console.
Train your AutoML Edge model using the Google Cloud console. (image only)
Train your AutoML Edge model using the Vertex AI API. (image only)