データ モデリングは、Looker Studio でデータを成形して、分析情報に富んだ的を絞ったレポートを作成するのに役立ちます。このプロセスでは、Looker Studio でデータをディメンション、指標、計算フィールドに整理する方法を調整して、ビジネス目標に合わせてデータとメタデータを構成します。これらのモデリング手法は、レポート内、データソース内、基盤となるデータセット内の 3 つの異なるレベルで適用できます。
データ モデリング機能を使用して、フィールドのプロパティを調整したり、計算フィールドを作成したり、フィルタを適用したりします。これらの機能により、生データを変換し、新しい分析情報を導き出し、データアクセスを制御して、最終的に Looker Studio レポートの関連性と明瞭性を高めることができます。
始める前に
このページを最大限に活用するには、次のトピックについて理解しておく必要があります。
Looker Studio でデータを整理する方法
データ モデリングの詳細に入る前に、Looker Studio でデータがどのように整理されるかを理解しておくと便利です。Looker Studio で作成するすべてのグラフとテーブルは、列と行で構成される表形式のデータ構造に基づいて作成されます。列(フィールド)は、各行に含まれるデータを定義します。データを定義する情報は、メタデータと呼ばれます。
Looker Studio には次の 2 種類のフィールドがあります。
- ディメンションはカテゴリまたはラベルです。ディメンションは、測定対象を記述します。次に例を示します。
- 国
- プロダクト名
- 日付
- 指標は測定値です。指標は、何かの量を示します。例:
- セールス
- ページビュー数
- クリック数
データソースを作成すると、基盤となるデータセットへの接続に使用したコネクタによって提供されるディメンションと指標が表示されます。これらのデフォルト フィールドに加えて、次のタイプのフィールドを作成できます。
計算フィールドでは、数式を使用して、データから派生した新しい指標やディメンションを作成します。次に例を示します。
Price * DiscountTODAY() - 7IF(FINAL GRADE > 35, "PASS", "FAIL")
パラメータと変数を使用すると、ユーザー入力に基づいてレポートをパーソナライズできます。パラメータの詳細
これらのフィールド(ディメンション、指標、計算フィールド、パラメータ、変数)は、レポートの構成要素です。データ モデリングを使用すると、これらのビルディング ブロックを微調整して、分析情報に富んだ Looker Studio レポートを作成できます。
データをモデル化できる場所
データをモデリングできるレベルは 3 つあります。
- レポート
- データソース内
基盤となるデータセット
これらのモデリング レベルは、逆ピラミッドのように考えることができます。これらのレベルを組み合わせて使用できます。データのモデリング場所は、必要なものによって異なります。
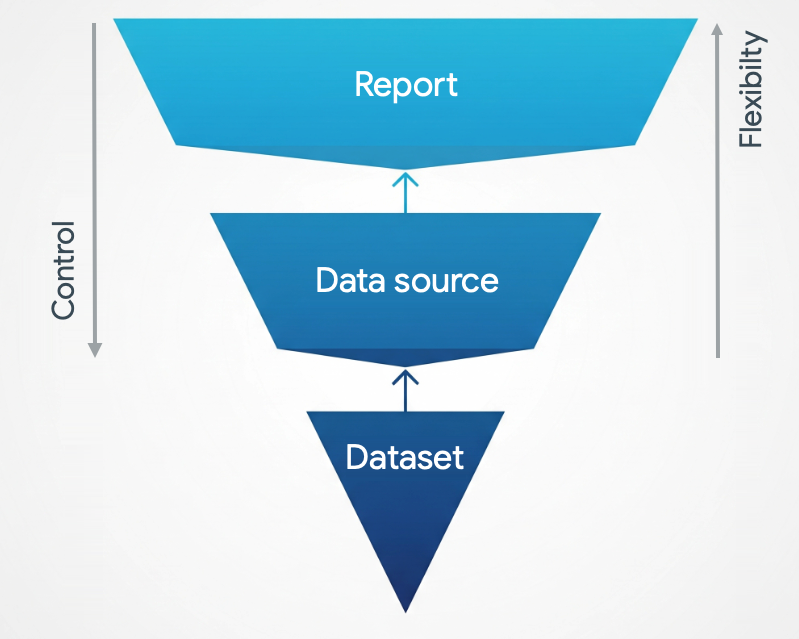
データセット レベルでのデータ モデリングは、Looker Studio の外部で行われます。ここでは、柔軟性と制御のバランスを取ることから、データとメタデータが Looker Studio に到達する前に、意図したとおりに正確であることを確認することに重点が置かれています。
以降のセクションでは、これらのモデリング レベルについて詳しく説明します。
レポートレベルのモデリング
レポートレベルでデータをモデリングすると、レポート編集者は、まるで積み木を自由に組み立てるように、データを自由に修正したり、探索したりできます。
レポートレベルでデータをモデリングする際は、次の点に留意してください。
- レポートの編集時に適用されたモデリング機能は、そのレポート内にのみ存在します。そのため、同じデータソースを使用している場合でも、レポートごとに異なる分析情報が表示されることがあります。
- レポートレベルのモデリングでは、データを最も細かく制御できます。レポートの編集者は、埋め込みデータソースのフィールドを表示および編集できます。
- レポート閲覧者は、特定のモデリング構成を表示できます。詳細については、データ モデリングとデータアクセスをご覧ください。
データソース レベルのモデリング
データソース レベルでデータをモデリングすると、データをより詳細に制御できます。データソースを編集できるユーザーを制限し、レポート内のフィールドの変更を防ぐことができます。データソース レベルのモデリングは、すべてのレポートが信頼できる単一の情報源に基づいていることを確認するのに役立ちます。
データソース レベルでデータをモデリングする際は、次の点に留意してください。
- データソースの編集時に適用されるモデリング機能は、そのデータソース内に存在します。
- データソース レベルのモデリングでは、モデルを使用するすべてのグラフとレポートでモデルを使用できます。
- 一部のデータ モデリング機能は、データソース レベルでのみ使用できます。たとえば、フィールドの説明はデータソースでのみ追加できます。逆に、Looker コネクタを使用するレポートを除き、フィルタはレポート単位でのみ適用できます。
- レポートの閲覧者は、特定のデータソース レベルのモデリング構成を表示できます。詳細については、データ モデリングとデータアクセスをご覧ください。
基盤となるデータセットのデータをモデル化する
基盤となるデータセットでデータをモデリングすると、接続されたすべてのデータソースが、必要な正確なデータを受け取ることができます。このアプローチは、Looker Studio に到達する前にデータを準備する場合によく使用されます。
たとえば、複雑なデータ変換に Looker Studio の関数やフィルタを使用するよりも、BigQuery コネクタで SQL クエリを直接記述する方が効率的で効果的な場合があります。
データセット レベルのモデリングは、データに最高レベルのセキュリティを提供します。データソースの編集者は、直接権限が明示的に付与されていない限り、基になるデータセットにアクセスできません。
データをモデル化する方法
次の機能を使用してデータをモデル化できます。
- 名前、データ型、集計などのフィールド プロパティの調整
- ベースデータを拡張または変換する計算フィールドを作成する
- 特定の値を含めるまたは除外するためにデータにフィルタを適用する
フィールドのプロパティを調整する
データソースのフィールドには、次の表に示すように、そのデータソースの作成に使用されるコネクタによって提供されるデフォルトのプロパティ セットがあります。
編集可能なフィールドのプロパティを確認する
| プロパティ | 説明 |
| フィールド名 | フィールド名は、データソースの [フィールド] 列と、レポートのプロパティ パネルのフィールド チップの [表示名] に表示されます。 |
| データ型 | データ型は、データソースの [種類] 列と、レポートのプロパティ パネルのフィールド チップの [データ型] に表示されます。 データ型のプロパティは、そのフィールドの処理時に想定されるデータの種類を Looker Studio に示します。データ型によって、データがレポートにどのように表示されるか、データに対して許可されるオペレーションと許可されないオペレーションが決まります。たとえば、算術関数を [テキスト] フィールドに適用したり、[数値] フィールドをレポートの期間として使用したりすることはできません。 |
| 集計 | 集計は、データソースでは [デフォルトの集計] 列として、レポートのプロパティ パネルのフィールド チップでは [集計] 列として表示されます。 集計では、フィールドのデータが要約されます。データの取得元と、データセットでの定義方法に応じて、次の 3 つのデフォルトの方法を使用できます。
|
| 説明 | データソースの [説明] 列を使用すると、個々のフィールドにアノテーションを追加できます。レポート単位でフィールドの説明を変更することはできません。 Looker や 検索広告 360 などの一部のコネクタでは、フィールドの説明が自動的に提供されます。 表グラフにフィールドの説明を表示するには、表のプロパティで [フィールドの説明を表示する] スタイル オプションを有効にします。Looker または検索広告 360 のデータソースに接続されているグラフでは、[フィールドの説明を表示する] が自動的に有効になります。 |
| 表示形式 | [表示形式] プロパティを使用すると、グラフでの数値フィールドや日付フィールドの表示方法を変更できます。[表示形式] は、レポートのプロパティ パネルのフィールド チップにのみ表示されます。 |
| 比較計算 | [比較計算] プロパティを使用すると、各行のデータをフィールドの合計値と比較できます。比較計算は、レポートのプロパティ パネルのフィールド チップにのみ表示されます。 詳しくは、比較計算の詳細をご覧ください。 |
| 関数 | 関数プロパティを使用すると、データの累積結果を計算できます。[累計] は、レポートのプロパティ パネルのフィールド チップにのみ表示されます。 詳しくは、関数についての記事をご覧ください。 |
データソース レベルでフィールドのプロパティを変更するには、データソースを編集します。
レポートレベルでフィールドのプロパティを変更する手順は次のとおりです。
- レポートを編集して、グラフを選択します。
- グラフのプロパティ パネルで、フィールドのデータ型アイコンにカーソルを合わせます。データ型のアイコンが編集用の鉛筆アイコンに変わります。
- 編集アイコン(鉛筆アイコン) をクリックします。
- 表示されたダイアログで、フィールドのプロパティを編集します。
レポートの編集者がフィールドのプロパティを変更できないようにするには、データソースを編集して [レポートのフィールド編集] をオフにします。詳しくは、フィールドを編集するをご覧ください。
計算フィールドを使用してデータをモデル化する
計算フィールドを使用すると、データを基に新しいフィールドを作成できます。計算フィールドは、フィールド リストに fx という記号付きで表示されます。
データソースで作成した計算フィールドは、そのデータソースを使用するすべてのレポートで使用できます。レポートのグラフで作成した計算フィールドは、そのグラフでのみ使用できます。
詳しくは、計算フィールドについてをご覧ください。
フィルタを適用
レポートにフィルタを適用して、閲覧者に表示される情報を絞り込むことで、レポート内のデータを制限できます。フィルタを使用すると、最も重要なデータに焦点を当て、レポートの内容を閲覧者にとってより有益なものに整えることができます。
フィルタは、1 つのコンポーネント、コンポーネントのグループ、1 つのページ、またはレポート全体に適用できます。
詳しくは、フィルタ プロパティをご覧ください。
データ モデリングとデータアクセス
レポートのメタデータには、フィルタ構成などのレポートレベルのモデリング機能の表示設定や、プロパティ パネルから作成された計算フィールドの名前が含まれます。レポートのメタデータは、レポートの閲覧権限を持つユーザーがレポートのネットワーク リクエストを調べたり、レポートのコピーを作成したりすると表示されます。
データソースの編集者のみが、フィールドの説明やデータソース内で作成された計算フィールドの名前など、データソース レベルのモデリング機能の表示設定を確認できます。ただし、データソース モデルのコネクタタイプやデータソース スキーマの列名など、一部の側面は常にユーザーがアクセスできます。