As informações neste artigo oferecem sugestões e informações detalhadas sobre a mistura de dados para ajudar a compreender como funciona a mistura e a resolver exemplos de utilização complexos. Para tirar o máximo partido deste artigo, já deve conhecer os princípios básicos da mistura de dados, que são abordados nos outros artigos deste tópico.
As misturas devem conter apenas um subconjunto dos dados disponíveis
Como prática recomendada, deve incluir apenas os campos específicos que quer visualizar em gráficos baseados numa combinação. Veja por que motivo isto é importante:
- A mistura pode criar conjuntos de dados muito grandes, o que pode levar a um desempenho lento e, possivelmente, a custos de consultas mais elevados para serviços pagos, como o BigQuery.
- Os gráficos baseados em misturas calculam todas as linhas na mistura, mesmo que não sejam usadas no gráfico.
- Por exemplo, suponhamos que cria uma mistura com 10 campos. Em seguida, define um gráfico que usa apenas 1 desses campos. O Looker Studio calcula a união de 10 campos e, em seguida, consulta esse campo no resultado da união para criar o gráfico.
- A nova agregação só ocorre se a combinação contiver um subconjunto dos dados subjacentes.
Use a mistura para voltar a agregar métricas
As métricas que inclui na origem de dados subjacente tornam-se números não agregados numa combinação. Quando a combinação inclui menos do que o conjunto completo de campos da origem de dados subjacente, estes números são novamente agregados com base nos novos dados. A mistura desta forma pode ser útil se precisar de aplicar uma agregação diferente a um campo já agregado, como calcular uma média de médias.
Consulte o artigo Use a combinação para voltar a agregar dados para mais informações.
Crie misturas a partir de uma única origem de dados
As misturas não têm de usar origens de dados diferentes. Também pode ser útil voltar a agregar dados misturando várias tabelas da mesma origem de dados.
Por exemplo, suponhamos que tem um conjunto de dados que contém dados da população dos três principais condados nos estados mais populosos dos EUA, conforme mostrado na tabela seguinte:
| Estado |
Condado |
População (estimativa de 2023) |
|---|---|---|
| Califórnia |
Condado de Los Angeles |
10,014,009 |
| Califórnia |
Condado de San Diego |
3 298 634 |
| Califórnia |
Condado de Orange |
3 186 989 |
| Texas |
Condado de Harris |
4 731 145 |
| Texas |
Condado de Dallas |
2 613 539 |
| Texas |
Condado de Tarrant |
2,110,640 |
| Nova Iorque |
Condado de Kings (Brooklyn) |
2 736 074 |
| Nova Iorque |
Condado de Queens |
2 405 464 |
| Nova Iorque |
Condado de Bronx |
1 418 890 |
Quer calcular a percentagem da população para cada concelho no estado, mas, para isso, precisa de ter a população total de cada estado como o seu próprio campo. No conjunto de dados, essa métrica não está disponível, mas pode obtê-la misturando a origem de dados da população consigo própria através dos seguintes passos:
- Crie uma origem de dados com o conjunto de dados base.
- Adicione um gráfico que use essa origem de dados a um relatório.
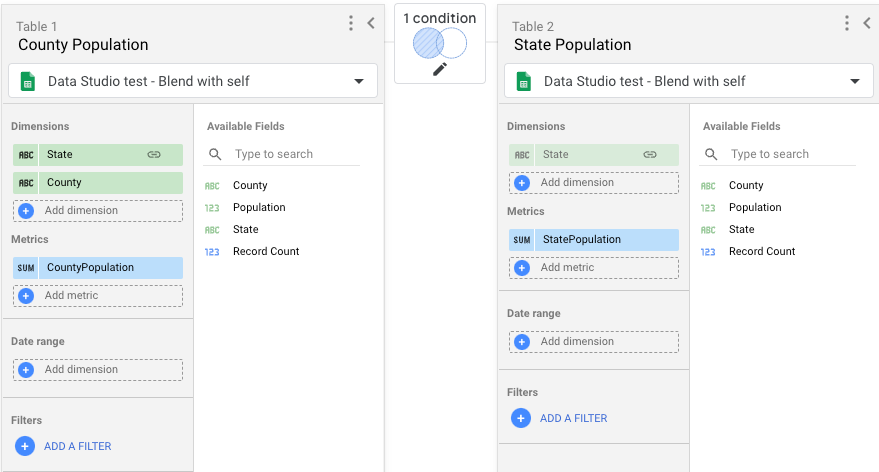
- Crie uma combinação com duas tabelas. Cada tabela vai usar a mesma origem de dados que criou no passo 1.
- Para a Tabela 1, inclua os seguintes campos:
- Estado, Condado, População.
- Mude o nome de Population para CountyPopulation.
- Para a tabela 2, inclua apenas o campo População e mude o nome desse campo para StatePopulation.
- Para a Tabela 1, inclua os seguintes campos:
- Para a condição de união, use uma união externa esquerda, associando Estado na tabela 1 a Estado na tabela 2.
- Clique em Guardar.
- Clique em X para voltar ao editor de relatórios.
Em seguida, adicione um novo gráfico (por exemplo, uma tabela) ao relatório e selecione a combinação como origem de dados do gráfico seguindo estes passos:
- Adicione os campos State, County, CountyPopulation e StatePopulation ao gráfico.
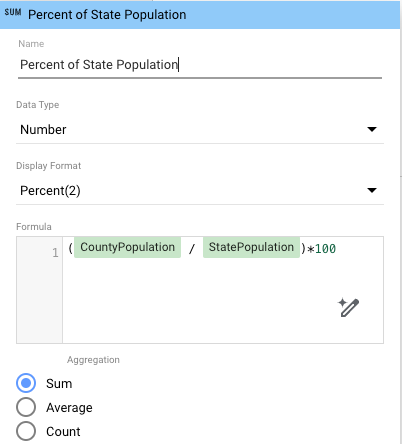
- Para calcular a percentagem da população do estado para cada concelho, adicione um campo calculado ao gráfico que use os novos dados reagregados:
- No painel de propriedades, clique em Adicionar métrica e, de seguida, em Adicionar campo.
- Atribua um nome ao campo, por exemplo, Percentagem da população do estado.
- Na caixa Fórmula, introduza
(CountyPopulation / StatePopulation)*100. - (Opcional) Defina o Formato de apresentação para mostrar os valores percentuais a um nível específico (por exemplo, Percentagem (2) para dois dígitos decimais).
Quando terminar, a tabela deve ter um aspeto semelhante ao seguinte:
| Estado |
Condado |
CountyPopulation |
StatePopulation |
Percentagem da população do estado |
|---|---|---|---|---|
| Califórnia |
Condado de Los Angeles |
10014009 |
16499632 |
60,69 |
| Texas |
Condado de Harris |
4731145 |
9455324 |
50,04 |
| Califórnia |
Condado de San Diego |
3298634 |
16499632 |
19,99 |
| Califórnia |
Condado de Orange |
3186989 |
16499632 |
19.32 |
| Nova Iorque |
Condado de Kings (Brooklyn) |
2736074 |
6560428 |
41,71 |
| Texas |
Condado de Dallas |
2613539 |
9455324 |
27,64 |
| Nova Iorque |
Condado de Queens |
2405464 |
6560428 |
36,67 |
| Texas |
Condado de Tarrant |
2110640 |
9455324 |
22.32 |
| Nova Iorque |
Condado de Bronx |
1418890 |
6560428 |
21,63 |
Ordem da tabela na mistura
O Looker Studio avalia as configurações de junção na mistura por ordem, começando pela configuração mais à esquerda. Os resultados de cada junção são, em seguida, aplicados à junção seguinte à direita. Por exemplo, numa união de três tabelas, a configuração de junção entre a tabela 1 (mais à esquerda) e a tabela 2 (do meio) é avaliada e, em seguida, esses resultados são usados pela configuração de junção entre a tabela 2 e a tabela 3 (mais à direita).
Ordem das tabelas em misturas criadas automaticamente
Quando mistura uma seleção de gráficos, o Looker Studio cria uma tabela para cada gráfico e, em seguida, adiciona os campos no gráfico à tabela correspondente. A ordem das tabelas na combinação corresponde à ordem em que seleciona os gráficos: o primeiro gráfico selecionado torna-se a primeira tabela (mais à esquerda), o segundo gráfico selecionado torna-se a segunda tabela, etc.
O Looker Studio também cria automaticamente uma configuração de união para cada tabela e usa o tipo de união externa esquerda.
Se a configuração predefinida não for a pretendida ou se não existirem associações claras entre as tabelas, pode editar a combinação de acordo com os seus objetivos.
As tabelas são criadas antes da mistura
Os dados de cada tabela numa combinação são consultados antes de serem unidos na combinação final. Os intervalos de datas, os filtros e os campos calculados numa tabela são aplicados à consulta que gera a tabela antes de serem feitas quaisquer junções. Estes fatores podem afetar os dados incluídos nas tabelas de combinação e alterar o resultado da combinação.
As misturas podem conter mais linhas do que os dados originais
Pode ver mais dados num gráfico combinado do que nos gráficos baseados nas origens de dados individuais que compõem a combinação. O resultado pode depender dos seus dados e da configuração de junção escolhida para a combinação. Por exemplo, uma junção externa esquerda inclui todos os registos da tabela à esquerda, bem como todos os registos das tabelas à direita que partilham os mesmos valores na condição de junção. Várias correspondências para a condição de junção podem resultar na apresentação de mais linhas nos dados misturados do que existem na origem de dados mais à esquerda.
Misturas e intervalos de datas e filtros explícitos
Existem duas formas de limitar o número de linhas nas suas misturas: usar um intervalo de datas ou aplicar um filtro. Pode limitar as linhas em gráficos baseados numa união ou nas tabelas que compõem a união. É útil pensar no processo como "pré-mistura" ou "pós-mistura".
Quando aplica um intervalo de datas ou um filtro a uma tabela na união, este entra em vigor antes de os dados serem unidos com as outras tabelas na união. As linhas que estão fora do intervalo de datas ou que são excluídas pelo filtro não estão disponíveis para a consulta de junção funcionar.
Quando aplica um intervalo de datas ou um filtro a um gráfico baseado numa combinação, está a aplicá-lo aos dados depois de a combinação ter sido criada ("pós-combinação").
Esta diferença pode ter um grande impacto nos resultados que vê nos gráficos, consoante os seus dados e a forma como configurou a combinação.
Misturas e filtros herdados
As combinações herdam filtros ao nível do relatório, da página ou do grupo, desde que o filtro seja compatível com os dados pré-combinação ou pós-combinação. Se o filtro for compatível com as origens de dados subjacentes usadas na combinação, o filtro atua nos dados pré-combinados. Caso contrário, o filtro atua sobre os dados após a mistura. Se o filtro não for compatível com os dados pré-misturados ou pós-misturados, é ignorado.
Saiba mais acerca da herança de filtros.
Quando um gráfico baseado numa união está sujeito a um filtro herdado, o Looker Studio processa os dados em cinco passos:
(Pré-mistura):
- Passo 1: os dados são agrupados e agregados com base nas dimensões especificadas no painel Misturar dados.
- Passo 2: os filtros de dimensões herdados e os filtros de métricas compatíveis são aplicados às origens de dados incluídas no painel Misturar dados.
(Mistura):
- Passo 3: os dados são misturados através da configuração de junção especificada.
(Após a combinação):
- Passo 4: os dados são agrupados e agregados com base nas dimensões no gráfico.
- Passo 5: os filtros de métricas, se forem compatíveis com dados misturados, são aplicados ao gráfico.