向量搜尋支援混合型搜尋,這是資訊檢索 (IR) 領域常用的架構模式,結合語意搜尋與關鍵字搜尋 (也稱為「詞元型搜尋」)。開發人員可以運用混合型搜尋,結合兩種做法的優勢,有效提高搜尋品質。
本頁面說明混合型搜尋、語意搜尋和詞元型搜尋的概念,並提供如何設定詞元型搜尋和混合型搜尋的範例:
混合型搜尋的重要性為何?
如「Vector Search 總覽」一文所述,Vector Search 的語意搜尋功能可使用查詢,找出語意相似的項目。
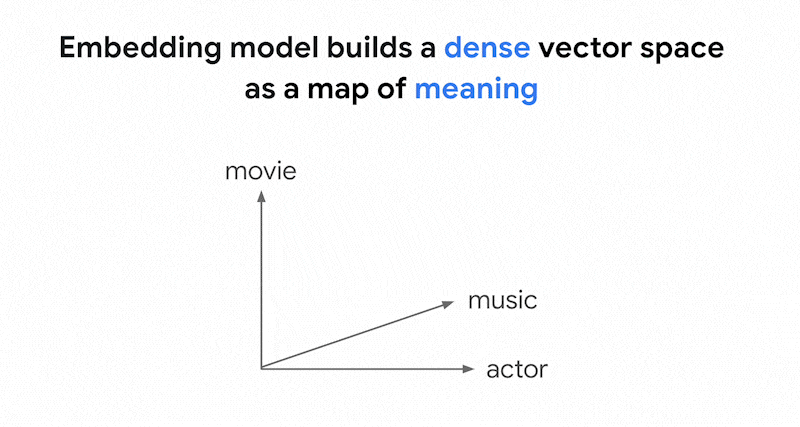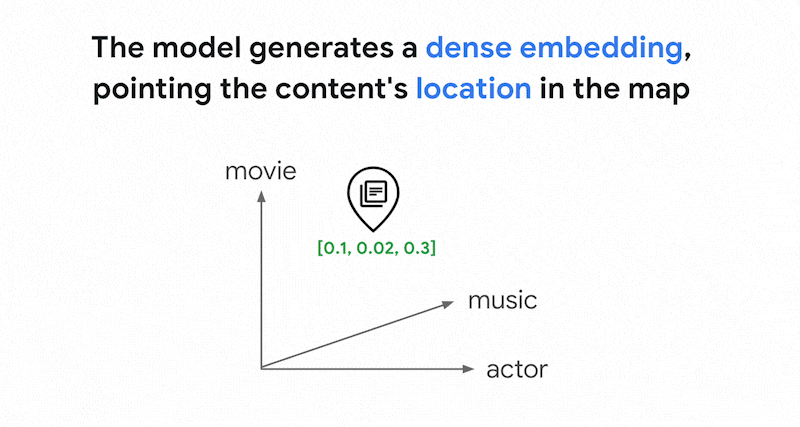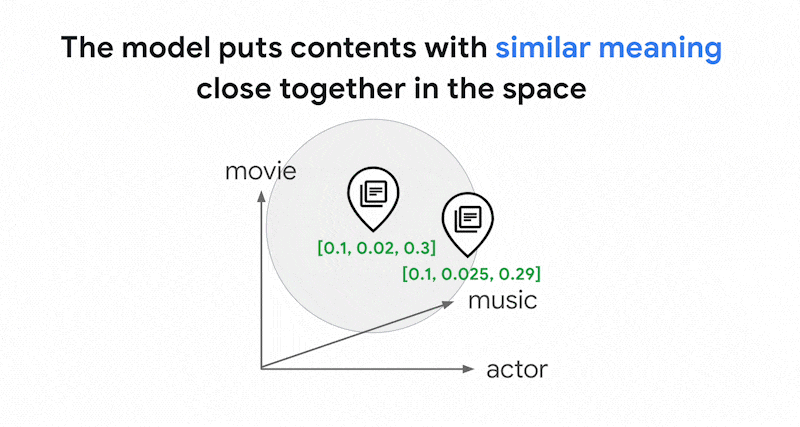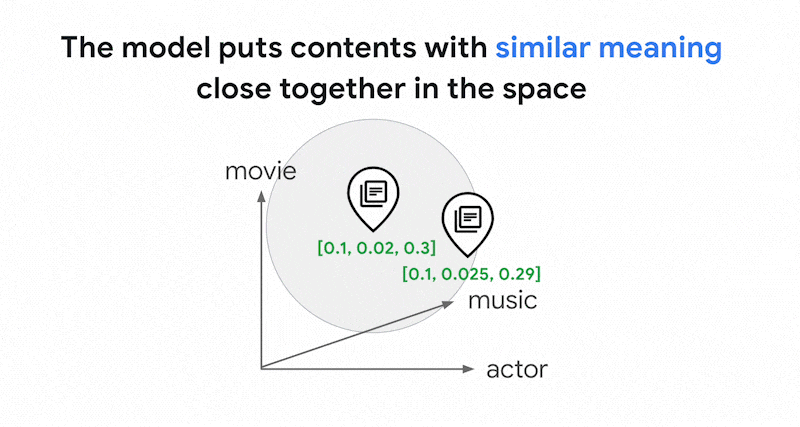
Vertex AI Embeddings 等嵌入模型會建構向量空間,做為內容意義的地圖。每個文字或多模態嵌入都是地圖中的位置,代表某項內容的含義。舉例來說,如果嵌入模型收到一段文字,其中 10% 的內容討論電影、2% 討論音樂,30% 討論演員,則模型可能會以嵌入 [0.1, 0.02,
0.3] 代表這段文字。使用 Vector Search,您可以快速找到附近的其他嵌入項目。這種依內容意義搜尋的方式稱為語意搜尋。
透過嵌入和向量搜尋進行語意搜尋,可讓 IT 系統像經驗豐富的圖書館員或店員一樣聰明。嵌入內容可用於將不同商家資料與其意義連結,例如查詢和搜尋結果、文字和圖片、使用者活動和建議產品、英文和日文文字,或是感應器資料和警示條件。這項功能可讓您將嵌入內容用於各種用途。
為什麼要結合語意搜尋和關鍵字搜尋?
語意搜尋無法涵蓋資訊檢索應用程式的所有可能需求,例如檢索增強生成 (RAG)。語意搜尋只能找出嵌入模型可解讀的資料。舉例來說,如果查詢或資料集含有任意產品編號或 SKU、最近新增的全新產品名稱,以及公司專屬代號,由於這些內容未納入嵌入模型訓練資料集,因此無法搭配語意搜尋使用。這類資料稱為「網域外」資料。
在這種情況下,您需要結合語意搜尋與關鍵字型 (也稱為「詞元型」) 搜尋,形成混合型搜尋。混合型搜尋結合語意和權杖型搜尋的優點,可提高搜尋品質。
Google 搜尋就是最受歡迎的混合型搜尋系統之一。這項服務除了採用以符記為基礎的關鍵字搜尋演算法,也在 2015 年整合了語意搜尋與 RankBrain 模型。Google 搜尋推出混合型搜尋後,可同時滿足「依據語意搜尋」和「依據關鍵字搜尋」這兩項需求,大幅提升搜尋品質。
以往要建立混合型搜尋引擎相當複雜,與 Google 搜尋一樣,您必須建構及運作兩種不同的搜尋引擎 (語意搜尋和以符記為基礎的搜尋),然後合併並排序兩者的結果。有了向量搜尋的混合搜尋支援功能,您可以使用單一向量搜尋索引,建構符合業務需求的自訂混合搜尋系統。
權杖型搜尋的運作方式
Vector Search 中的權杖搜尋如何運作?將文字分割成權杖 (例如字詞或子字詞) 後,您可以使用熱門的稀疏嵌入演算法 (例如 TF-IDF、BM25 或 SPLADE),為文字產生稀疏嵌入。
稀疏嵌入的簡化說明:稀疏嵌入是向量,代表每個字詞或子字詞在文字中出現的次數。一般稀疏嵌入不會考量文字的語意。

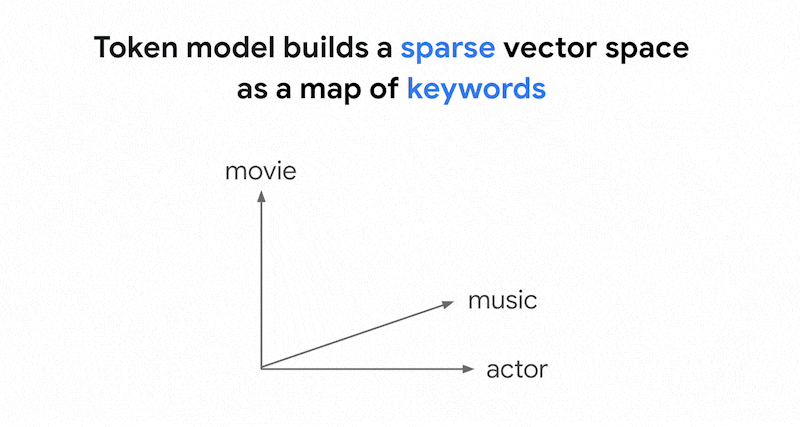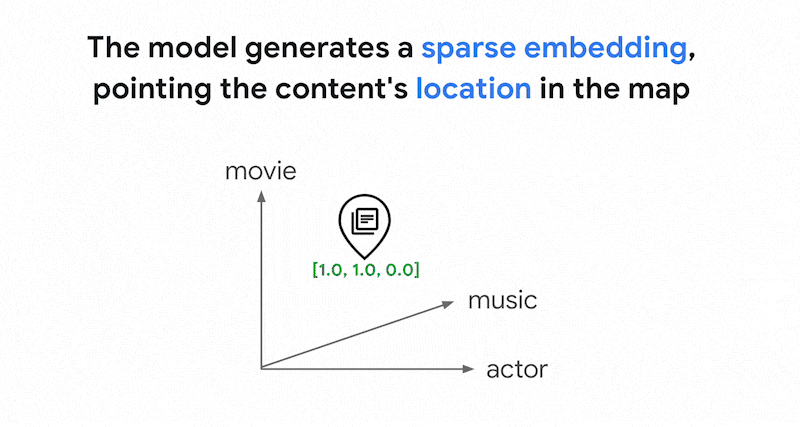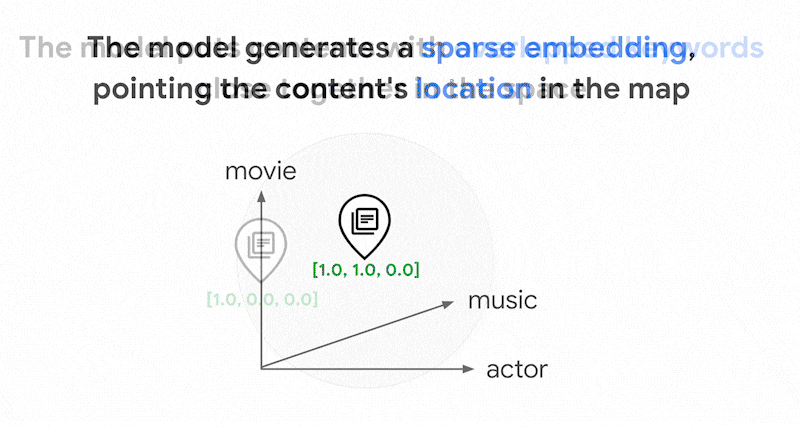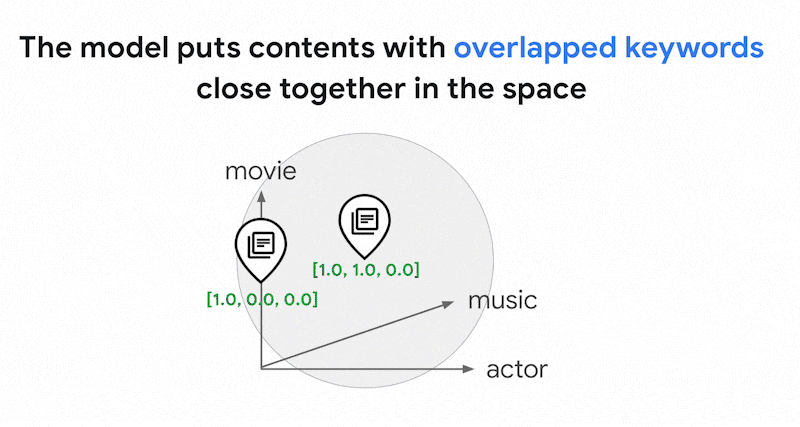
文字中可能使用數千個不同的字詞。因此,這個嵌入通常有數萬個維度,但只有少數維度具有非零值。因此稱為「稀疏」嵌入。大部分值都是零。這個稀疏嵌入空間就像關鍵字地圖,類似於書籍索引。
在這個稀疏嵌入空間中,您可以查看查詢嵌入的鄰近項目,找出類似的嵌入。這些嵌入在文字中使用的關鍵字分布方面相似。
這是以符記為基礎的搜尋基本機制,採用稀疏嵌入。 透過 Vector Search 的混合型搜尋功能,您可以將稠密和稀疏嵌入項目混合到單一向量索引中,並使用稠密嵌入項目、稀疏嵌入項目或兩者執行查詢。結果是語意搜尋和詞元型搜尋結果的組合。
與採用反向索引設計的權杖型搜尋引擎相比,混合型搜尋的查詢延遲時間也較短。與語意搜尋的向量搜尋一樣,即使有數百萬或數十億個項目,每個查詢 (含密集或稀疏嵌入) 也能在幾毫秒內完成。
範例:如何使用以符記為準的搜尋功能
為說明如何使用詞元型搜尋,以下章節提供程式碼範例,這些範例會生成稀疏嵌入,並在 Vector Search 上使用這些嵌入建立索引。
如要試用這個程式碼範例,請使用筆記本:結合語意和關鍵字搜尋: 透過 Vertex AI Vector Search 進行混合搜尋的教學課程。
第一步是準備資料檔案,根據「輸入資料格式和結構」一文所述的資料格式,為稀疏嵌入建立索引。
在 JSON 中,資料檔案如下所示:
{"id": "3", "sparse_embedding": {"values": [0.1, 0.2], "dimensions": [1, 4]}}
{"id": "4", "sparse_embedding": {"values": [-0.4, 0.2, -1.3], "dimensions": [10, 20, 30]}}
每個項目都應具備 sparse_embedding 屬性,其中包含 values 和 dimensions 屬性。稀疏嵌入有數千個維度,但只有少數非零值。這種資料格式只包含空間中的非零值及其位置,因此效率很高。
準備範例資料集
我們將使用 Google 商品網路商店資料集做為範例資料集,其中包含約 200 列的 Google 品牌商品。
0 Google Sticker
1 Google Cloud Sticker
2 Android Black Pen
3 Google Ombre Lime Pen
4 For Everyone Eco Pen
...
197 Google Recycled Black Backpack
198 Google Cascades Unisex Zip Sweater
199 Google Cascades Womens Zip Sweater
200 Google Cloud Skyline Backpack
201 Google City Black Tote Backpack
準備 TF-IDF 向量化工具
我們會使用這個資料集訓練向量化工具,該模型會從文字生成稀疏嵌入。本範例使用 scikit-learn 中的 TfidfVectorizer,這是使用 TF-IDF 演算法的基本向量化工具。
from sklearn.feature_extraction.text import TfidfVectorizer
# Make a list of the item titles
corpus = df.title.tolist()
# Initialize TfidfVectorizer
vectorizer = TfidfVectorizer()
# Fit and Transform
vectorizer.fit_transform(corpus)
變數 corpus 會保留 200 個項目名稱的清單,例如「Google 貼紙」或「Chrome 恐龍別針」。接著,程式碼會呼叫 fit_transform() 函式,將這些資料傳遞至向量化工具。這樣一來,向量化工具就能準備好生成稀疏嵌入。
TF-IDF 向量化工具會嘗試為資料集中的特徵字詞 (例如「襯衫」或「恐龍」) 賦予較高權重,相較之下,微不足道的字詞 (例如「The」、「a」或「of」) 權重較低,並計算這些特徵字詞在指定文件中使用的次數。稀疏嵌入的每個值都代表每個字詞的頻率 (以計數為準)。如要進一步瞭解 TF-IDF,請參閱「TF-IDF 和 TfidfVectorizer 的運作方式」。
在這個範例中,為求簡單,我們使用基本字詞層級的權杖化和 TF-IDF 向量化。在正式版開發中,您可以根據需求,選擇任何其他權杖化和向量化選項,產生稀疏嵌入。就權杖化工具而言,在許多情況下,子字權杖化工具的效能優於字詞層級的權杖化工具,因此是熱門選擇。就向量化工具而言,BM25 是 TF-IDF 的改良版,因此相當熱門。SPLADE 是另一種熱門的向量化演算法,會擷取稀疏嵌入的一些語意。
取得稀疏嵌入
為了方便搭配 Vector Search 使用向量化工具,我們將定義包裝函式 get_sparse_embedding():
def get_sparse_embedding(text):
# Transform Text into TF-IDF Sparse Vector
tfidf_vector = vectorizer.transform([text])
# Create Sparse Embedding for the New Text
values = []
dims = []
for i, tfidf_value in enumerate(tfidf_vector.data):
values.append(float(tfidf_value))
dims.append(int(tfidf_vector.indices[i]))
return {"values": values, "dimensions": dims}
這個函式會將「text」參數傳遞至向量化工具,以產生稀疏嵌入。然後轉換為先前所述的 {"values": ...., "dimensions": ...} 格式,以建立 Vector Search 稀疏索引。
您可以測試這項功能:
text_text = "Chrome Dino Pin"
get_sparse_embedding(text_text)
這應該會輸出下列稀疏嵌入:
{'values': [0.6756557405747007, 0.5212913389979028, 0.5212913389979028],
'dimensions': [157, 48, 33]}
建立輸入資料檔案
在本範例中,我們會為所有 200 個項目生成稀疏嵌入。
items = []
for i in range(len(df)):
id = i
title = df.title[i]
sparse_embedding = get_sparse_embedding(title)
items.append({"id": id, "title": title, "sparse_embedding": sparse_embedding})
這段程式碼會為每個項目產生下列行:
{
'id': 0,
'title': 'Google Sticker',
'sparse_embedding': {
'values': [0.933008728540452, 0.359853737603667],
'dimensions': [191, 78]
}
}
然後將這些資料儲存為 JSONL 檔案「items.json」,並上傳至 Cloud Storage bucket。
# output as a JSONL file and save to bucket
with open("items.json", "w") as f:
for item in items:
f.write(f"{item}\n")
! gcloud storage cp items.json $BUCKET_URI
在 Vector Search 中建立稀疏嵌入索引
接著,我們將在向量搜尋中建構及部署稀疏嵌入索引。 這與向量搜尋快速入門中記錄的程序相同。
# create Index
my_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name = f"vs-hybridsearch-index-{UID}",
contents_delta_uri = BUCKET_URI,
dimensions = 768,
approximate_neighbors_count = 10,
)
如要使用索引,請建立索引端點。這個執行個體會做為伺服器,接受索引的查詢要求。
# create IndexEndpoint
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name = f"vs-quickstart-index-endpoint-{UID}",
public_endpoint_enabled = True
)
使用索引端點部署索引,並指定專屬的已部署索引 ID。
DEPLOYED_INDEX_ID = f"vs_quickstart_deployed_{UID}"
# deploy the Index to the Index Endpoint
my_index_endpoint.deploy_index(
index = my_index, deployed_index_id = DEPLOYED_INDEX_ID
)
等待部署完成後,我們就可以執行測試查詢。
使用稀疏嵌入索引執行查詢
如要使用稀疏嵌入索引執行查詢,您需要建立 HybridQuery 物件,封裝查詢文字的稀疏嵌入,如下列範例所示:
from google.cloud.aiplatform.matching_engine.matching_engine_index_endpoint import HybridQuery
# create HybridQuery
query_text = "Kids"
query_emb = get_sparse_embedding(query_text)
query = HybridQuery(
sparse_embedding_dimensions=query_emb['dimensions'],
sparse_embedding_values=query_emb['values'],
)
這個範例程式碼會使用「Kids」文字進行查詢。現在,請使用 HybridQuery 物件執行查詢。
# build a query request
response = my_index_endpoint.find_neighbors(
deployed_index_id=DEPLOYED_INDEX_ID,
queries=[query],
num_neighbors=5,
)
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
print(f"{title:<40}")
這應該會提供類似以下的輸出內容:
Google Blue Kids Sunglasses
Google Red Kids Sunglasses
YouTube Kids Coloring Pencils
YouTube Kids Character Sticker Sheet
在 200 個項目中,結果會包含含有「兒童」關鍵字的項目名稱。
範例:如何使用混合搜尋
這個範例會結合以符記為準的搜尋和語意搜尋,在 Vector Search 中建立混合搜尋。
如何建立混合索引
如要建立混合索引,每個項目都應包含「embedding」(適用於稠密嵌入) 和「sparse_embedding」:
items = []
for i in range(len(df)):
id = i
title = df.title[i]
dense_embedding = get_dense_embedding(title)
sparse_embedding = get_sparse_embedding(title)
items.append(
{"id": id, "title": title,
"embedding": dense_embedding,
"sparse_embedding": sparse_embedding,}
)
items[0]
get_dense_embedding() 函式會使用 Vertex AI Embedding API 生成最多 768 個維度的文字嵌入。現在,稠密和稀疏嵌入都會合併為下列格式:
{
"id": 0,
"title": "Google Sticker",
"embedding":
[0.022880317643284798,
-0.03315234184265137,
...
-0.03309667482972145,
0.04621824622154236],
"sparse_embedding": {
"values": [0.933008728540452, 0.359853737603667],
"dimensions": [191, 78]
}
}
其餘程序與「範例:如何使用以權杖為基礎的搜尋功能」一文所述相同:將 JSONL 檔案上傳至 Cloud Storage 值區、使用該檔案建立向量搜尋索引,然後將索引部署至索引端點。
執行混合型查詢
部署混合型索引後,即可執行混合型查詢:
# create HybridQuery
query_text = "Kids"
query_dense_emb = get_dense_embedding(query_text)
query_sparse_emb = get_sparse_embedding(query_text)
query = HybridQuery(
dense_embedding=query_dense_emb,
sparse_embedding_dimensions=query_sparse_emb['dimensions'],
sparse_embedding_values=query_sparse_emb['values'],
rrf_ranking_alpha=0.5,
)
針對查詢文字「Kids」,為該字詞產生稠密和稀疏嵌入,並封裝至 HybridQuery 物件。與先前的 HybridQuery 不同之處在於,這兩個函式多了 dense_embedding 和 rrf_ranking_alpha 兩個參數。
這次,我們要列印每個項目的距離:
# print results
for idx, neighbor in enumerate(response[0]):
title = df.title[int(neighbor.id)]
dense_dist = neighbor.distance if neighbor.distance else 0.0
sparse_dist = neighbor.sparse_distance if neighbor.sparse_distance else 0.0
print(f"{title:<40}: dense_dist: {dense_dist:.3f}, sparse_dist: {sparse_dist:.3f}")
在每個 neighbor 物件中,都有一個 distance 屬性,其中包含查詢與具有密集嵌入的項目之間的距離,以及一個 sparse_distance 屬性,其中包含與稀疏嵌入的距離。這些值是反向距離,因此值越高代表距離越短。
使用 HybridQuery 執行查詢後,會得到以下結果:
Google Blue Kids Sunglasses : dense_dist: 0.677, sparse_dist: 0.606
Google Red Kids Sunglasses : dense_dist: 0.665, sparse_dist: 0.572
YouTube Kids Coloring Pencils : dense_dist: 0.655, sparse_dist: 0.478
YouTube Kids Character Sticker Sheet : dense_dist: 0.644, sparse_dist: 0.468
Google White Classic Youth Tee : dense_dist: 0.645, sparse_dist: 0.000
Google Doogler Youth Tee : dense_dist: 0.639, sparse_dist: 0.000
Google Indigo Youth Tee : dense_dist: 0.637, sparse_dist: 0.000
Google Black Classic Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Chrome Dino Glow-in-the-Dark Youth Tee : dense_dist: 0.632, sparse_dist: 0.000
Google Bike Youth Tee : dense_dist: 0.629, sparse_dist: 0.000
除了含有「兒童」關鍵字的權杖型搜尋結果外,系統也會納入語意搜尋結果。舉例來說,由於嵌入模型知道「Youth」和「Kids」在語意上相似,因此「Google White Classic Youth Tee」會納入其中。
如要合併詞元型和語意搜尋結果,混合型搜尋會使用倒數排名融合 (RRF)。如要進一步瞭解 RRF 和如何指定 rrf_ranking_alpha 參數,請參閱「什麼是互惠排序融合?」一文。
重新排序
RRF 可合併語意和權杖式搜尋結果的排名。在許多生產資訊檢索或推薦系統中,結果會經過進一步的精確度排名演算法,也就是所謂的重新排名。結合毫秒級的快速檢索功能和向量搜尋,以及結果的精確重新排序,您可以建構多階段系統,提供更高品質的搜尋結果或推薦內容。
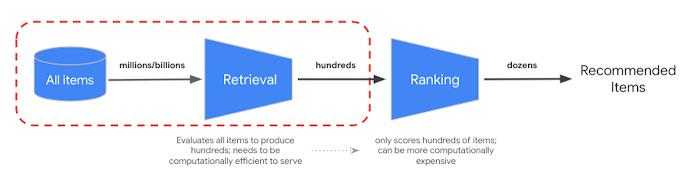
Vertex AI Ranking API 提供一種方法,可根據查詢文字與搜尋結果文字之間的通用關聯性,使用預先訓練模型實作排名。TensorFlow Ranking 也會介紹如何設計及訓練機器學習演算排序 (LTR) 模型,以進行進階重新排序,並根據各種業務需求自訂模型。
開始使用混合搜尋
如要開始在 Vector Search 中使用混合型搜尋,請參閱下列資源。
混合型搜尋資源
- 結合語意和關鍵字搜尋:使用 Vertex AI Vector Search 進行混合型搜尋的教學課程:混合型搜尋入門範例筆記本
- 輸入資料格式和結構:用於建構稀疏嵌入索引的輸入資料格式
- 查詢公開索引以取得最接近的鄰近項目:如何使用混合型搜尋執行查詢
- 倒數排名融合演算法優於 Condorcet 和個別排名學習方法:討論 RRF 演算法
向量搜尋資源
- Overview of Vertex AI Vector Search (Vertex AI Vector Search 總覽)
- Vector Search 快速入門導覽課程
其他概念
以下各節將進一步說明 TF-IDF 和 TfidVectorizer、互惠排序融合,以及 alpha 參數。
TF-IDF 和 TfidfVectorizer 如何運作?
fit_transform() 函式會執行 TF-IDF 演算法的兩項重要程序:
Fit:向量化工具會計算詞彙中每個字詞的轉換文件頻率 (IDF)。IDF 反映了某個詞彙在整個語料庫中的重要性。罕見字詞的 IDF 分數較高:
IDF(t) = log_e(Total number of documents / Number of documents containing term t)轉換:
- 斷詞:將文件拆解為個別字詞或詞組
字詞頻率 (TF) 計算:計算每個字詞在每份文件中出現的頻率,計算方式如下:
TF(t, d) = (Number of times term t appears in document d) / (Total number of terms in document d)TF-IDF 計算:將每個字詞的 TF 與預先計算的 IDF 結合,建立 TF-IDF 分數。這個分數代表特定文件中的字詞在整個語料庫中的重要性。
TF-IDF(t, d) = TF(t, d) * IDF(t)TF-IDF 向量化工具會嘗試為資料集中的特徵字詞 (例如「襯衫」或「恐龍」) 加上較高的權重,相較之下,微不足道的字詞 (例如「的」、「一」或「之」) 權重較低,並計算這些特徵字詞在指定文件中出現的次數。稀疏嵌入的每個值都代表各個單字的頻率 (以計數為準)。
什麼是倒數排名融合?
混合型搜尋會使用倒數排名融合 (RRF) 技術合併詞元型和語意搜尋結果。RRF 演算法會將多個項目排序清單合併為單一統一排序。這項技術可合併來自不同來源或檢索方法的搜尋結果,因此廣受歡迎,尤其是在混合型搜尋系統和大型語言模型中。
如果是向量搜尋的混合搜尋,密集距離和稀疏距離是在不同空間中測量,因此無法直接比較。因此,RRF 可有效合併及排序這兩個不同空間的結果。
RRF 的運作方式如下:
- 倒數排序:針對排序清單中的每個項目,計算其倒數排序。也就是說,要取得清單中項目位置 (排名) 的反向值。舉例來說,排名第一的項目會得到 1/1 = 1 的倒數排名,排名第二的項目則會得到 1/2 = 0.5。
- 互惠排序總和:將所有排序清單中每個項目的互惠排序加總。系統會為每項商品提供最終分數。
- 依最終分數排序:依最終分數降序排序項目。得分最高的項目會被視為最相關或最重要的項目。
簡而言之,稠密和稀疏結果中排名較高的項目會顯示在清單頂端。因此,「Google Blue Kids Sunglasses」項目會顯示在頂端,因為在密集和稀疏搜尋結果中,該項目的排名都較高。「Google White Classic Youth Tee」等項目排名較低,因為在密集的搜尋結果中,這些項目只佔據排名。
Alpha 參數的行為
混合搜尋的使用範例會在建立 HybridQuery 物件時,將 rrf_ranking_alpha 參數設為 0.5。您可以為密集和稀疏搜尋結果的排名指定權重,方法是為 rrf_ranking_alpha 使用下列值:
1,或未指定:混合式搜尋只會使用密集搜尋結果,並忽略稀疏搜尋結果。0:混合型搜尋只會使用稀疏搜尋結果,並忽略密集搜尋結果。0至1:混合搜尋會合併密集和稀疏的結果,並根據值指定的權重進行。0.5 表示會以相同權重合併。