這份新手指南將介紹如何在 Vertex AI 上進行自訂訓練。自訂訓練是指使用 TensorFlow、PyTorch 或 XGBoost 等機器學習架構訓練模型。
學習目標
Vertex AI 經驗程度:初學者
預計閱讀時間:15 分鐘
課程內容:
- 使用代管服務進行自訂訓練的優點。
- 封裝訓練程式碼的最佳做法。
- 如何提交及監控訓練工作。
為什麼要使用代管訓練服務?
假設您正在處理新的機器學習問題。開啟筆記本、匯入資料,然後執行實驗。在本情境中,您將使用所選的 ML 架構建立模型,並執行筆記本儲存格來執行訓練迴圈。訓練完成後,您可以評估模型結果、進行變更,然後重新執行訓練。這個工作流程適合用於實驗,但開始考慮使用 ML 建構正式版應用程式時,您可能會發現手動執行筆記本的儲存格並非最方便的選項。
舉例來說,如果資料集和模型很大,您可能會想試試分散式訓練。此外,在正式環境中,您不太可能只需要訓練模型一次。隨著時間推移,您將重新訓練模型,確保模型能持續提供最新資訊和有價值的結果。如要大規模自動進行實驗,或為生產應用程式重新訓練模型,使用代管式機器學習訓練服務可簡化工作流程。
本指南將簡介如何在 Vertex AI 上訓練自訂模型。由於訓練服務是全代管服務,Vertex AI 會自動佈建運算資源、執行訓練工作,並在訓練工作完成後確保刪除運算資源。請注意,還有其他自訂項目、功能和服務介面,本文未一一列出。本指南旨在提供概略說明。詳情請參閱 Vertex AI Training 說明文件。
自訂訓練總覽
在 Vertex AI 中訓練自訂模型時,請按照下列標準工作流程操作:
封裝訓練應用程式程式碼。
設定及提交自訂訓練工作。
監控自訂訓練工作。
封裝訓練應用程式程式碼
在 Vertex AI 上執行自訂訓練工作時,需要使用容器。容器是應用程式程式碼的套件 (在本例中為訓練程式碼),以及執行程式碼所需的程式庫特定版本等依附元件。除了協助管理依附元件,容器幾乎可以在任何地方執行,因此可提高可攜性。將訓練程式碼連同參數和依附元件封裝到容器中,建立可攜式元件,是將機器學習應用程式從原型移至正式環境的重要步驟。
您必須先封裝訓練應用程式,才能啟動自訂訓練工作。在本例中,訓練應用程式是指執行載入資料、預先處理資料、定義模型和執行訓練迴圈等工作的檔案 (或多個檔案)。Vertex AI 訓練服務會執行您提供的任何程式碼,因此訓練應用程式中包含哪些步驟完全由您決定。
Vertex AI 提供 TensorFlow、PyTorch、XGBoost 和 Scikit-learn 的預建容器。這些容器會定期更新,並包含訓練程式碼中可能需要的常見程式庫。您可以選擇使用其中一個容器執行訓練程式碼,也可以建立自訂容器,預先安裝訓練程式碼和依附元件。
在 Vertex AI 上封裝程式碼有三種方式:
- 提交單一 Python 檔案。
- 建立 Python 來源發行套件。
- 使用自訂容器。
Python 檔案
這個選項適合用於快速實驗。如果執行訓練應用程式所需的所有程式碼都在一個 Python 檔案中,且其中一個預建的 Vertex AI 訓練容器具有執行應用程式所需的所有程式庫,您就可以使用這個選項。如要瞭解如何將訓練應用程式封裝為單一 Python 檔案,請參閱筆記本教學課程「自訂訓練和批次推論」。
Python 來源發布
您可以建立包含訓練應用程式的 Python 來源發行套件。您會將來源發布內容連同訓練程式碼和依附元件,儲存在 Cloud Storage bucket 中。如要瞭解如何將訓練應用程式封裝為 Python 來源發行版本,請參閱筆記本教學課程「訓練、調整及部署 PyTorch 分類模型」。
自訂容器
如果您想進一步掌控應用程式,或是想執行非以 Python 編寫的程式碼,這個選項就非常實用。在這種情況下,您需要編寫 Dockerfile、建構自訂映像檔,並將其推送至 Artifact Registry。如需訓練應用程式的容器化範例,請參閱筆記本教學課程「使用 Profiler 分析模型訓練成效」。
建議的訓練應用程式結構
如果您選擇將程式碼封裝為 Python 來源發行版本或自訂容器,建議您將應用程式架構設為如下:
training-application-dir/
....setup.py
....Dockerfile
trainer/
....task.py
....model.py
....utils.py
建立目錄來儲存所有訓練應用程式程式碼,在本例中為 training-application-dir。如果您使用 Python 來源發行版本,這個目錄會包含 setup.py 檔案;如果您使用自訂容器,則會包含 Dockerfile。
在這兩種情況下,這個高階目錄也會包含子目錄 trainer,其中包含執行訓練的所有程式碼。在 trainer 中,task.py 是應用程式的主要進入點。這個檔案會執行模型訓練。您可以選擇將所有程式碼放在這個檔案中,但對於正式版應用程式,您可能會有其他檔案,例如 model.py、data.py、utils.py 等。
執行自訂訓練
Vertex AI 中的訓練工作會自動佈建運算資源、執行訓練應用程式程式碼,並在訓練工作完成後刪除運算資源。
隨著您建構更複雜的工作流程,您可能會使用 Python 適用的 Vertex AI SDK 來設定、提交及監控訓練工作。不過,首次執行自訂訓練工作時,使用 Google Cloud 控制台會比較簡單。
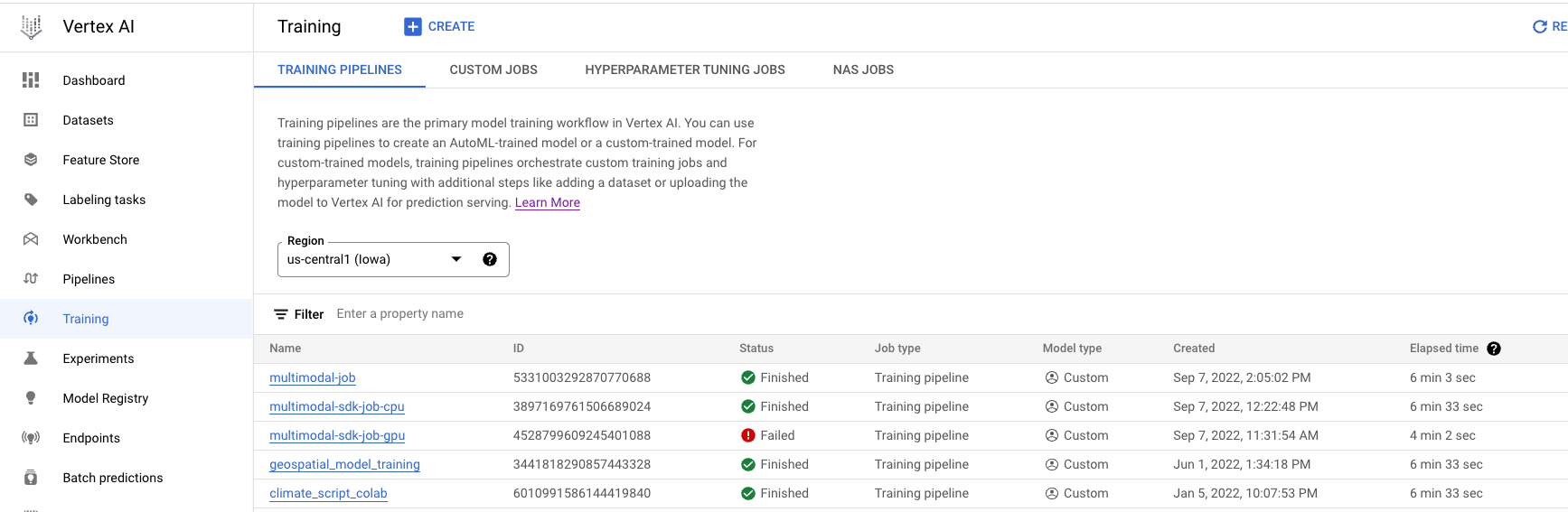
- 前往 Cloud 控制台的 Vertex AI 專區,然後點選「訓練」。按一下「建立」按鈕,即可建立新的訓練工作。
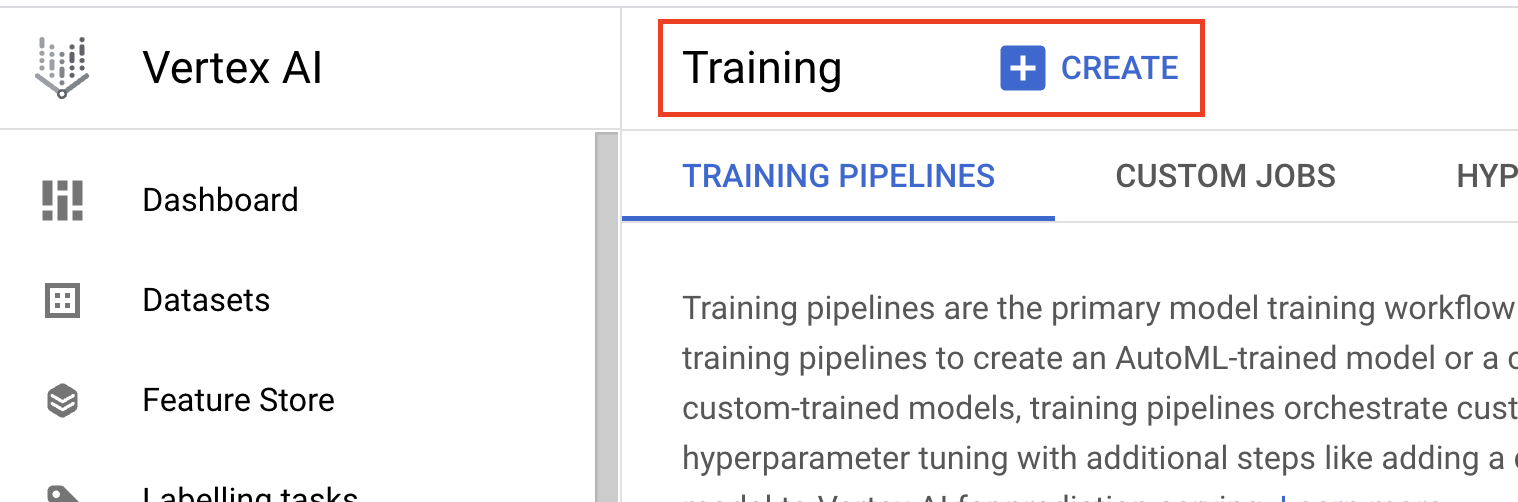
- 在模型「訓練方法」下方,選取「自訂訓練 (進階)」。
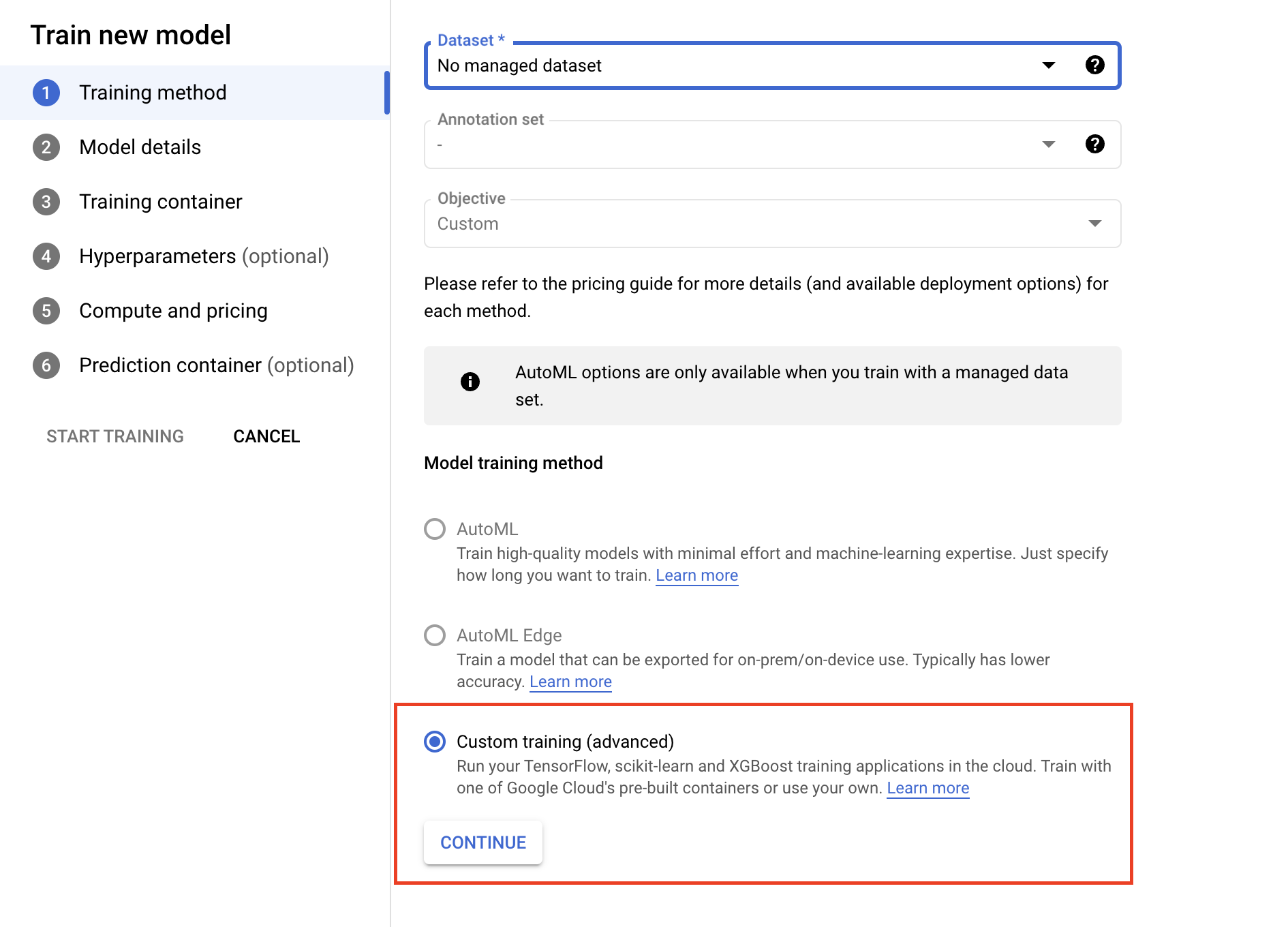
- 在「訓練容器」部分下方,視應用程式的封裝方式,選取預先建構或自訂容器。

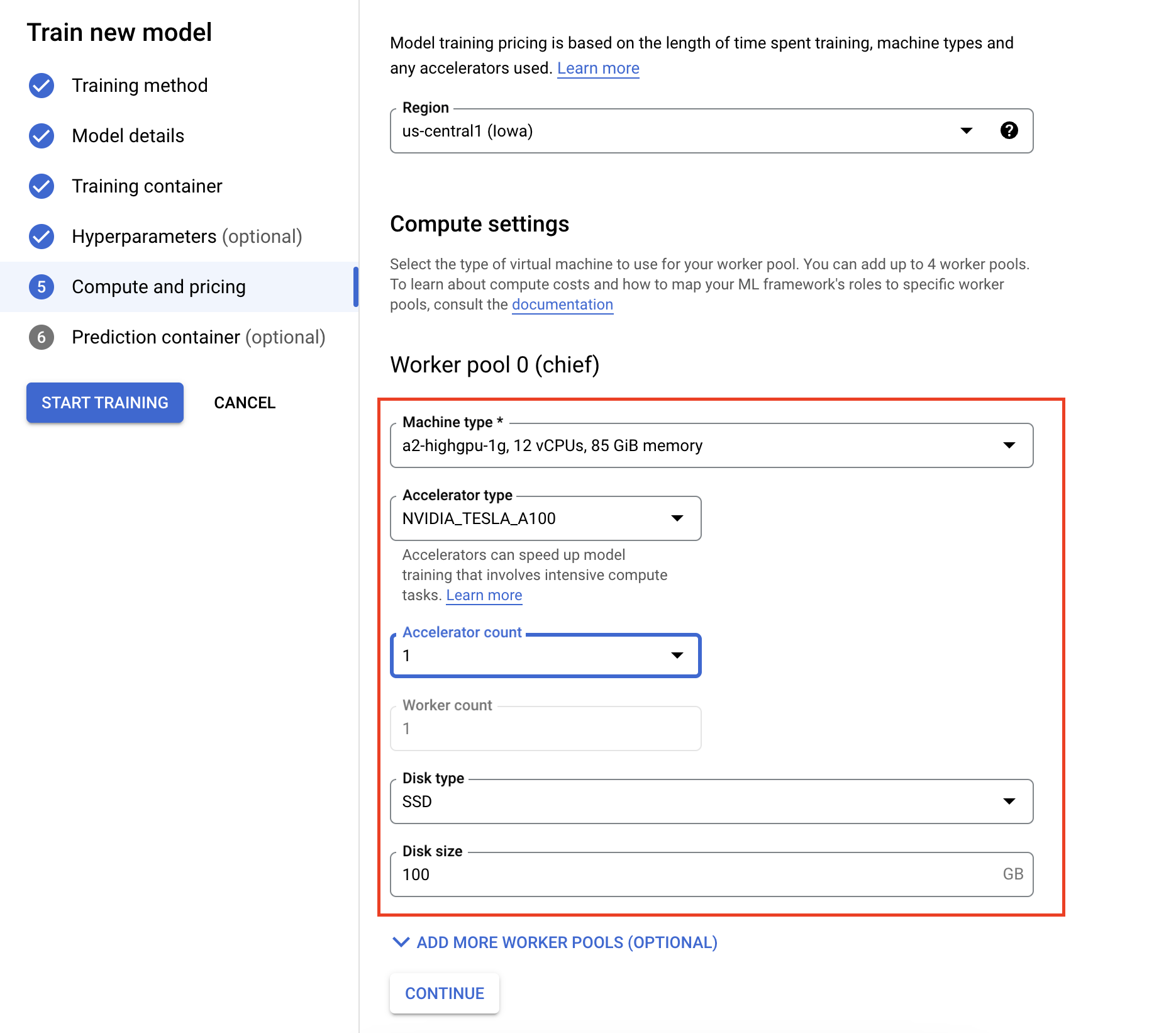
- 在「運算和定價」下方,指定訓練工作的硬體。如果是單一節點訓練,您只需要設定工作站集區 0。如有意執行分散式訓練,您需要瞭解其他工作站集區,詳情請參閱「分散式訓練」。
您可以選擇是否設定推論容器。如果您只想在 Vertex AI 上訓練模型,並存取產生的已儲存模型構件,可以略過這個步驟。如要在 Vertex AI 代管的推論服務上代管及部署產生的模型,您需要設定推論容器。詳情請參閱「從自訂訓練模型取得推論結果」。
監控訓練工作
您可以在 Google Cloud 控制台中監控訓練工作,畫面上會列出所有已執行的工作。如果發生錯誤,您可以點選特定工作並檢查記錄。