根據預設,Vertex AI 模型會部署至專屬的虛擬機器 (VM) 執行個體。Vertex AI 支援在同一部 VM 上共用模型,可帶來下列優點:
- 跨多個部署作業共用資源。
- 以符合成本效益的方式提供模型。
- 提升記憶體和運算資源的使用率。
本指南說明如何在 Vertex AI 的多個部署作業中共用資源。
總覽
模型共同託管支援功能導入了DeploymentResourcePool的概念,可將單一 VM 內共用資源的模型部署項目歸類在一起。在同一個 DeploymentResourcePool 中,您可以將多個端點部署至相同的 VM。每個端點都有一或多個已部署的模型。您可以視需要將特定端點的已部署模型編入相同或不同的 DeploymentResourcePool。
在下列範例中,您有四個模型和兩個端點:
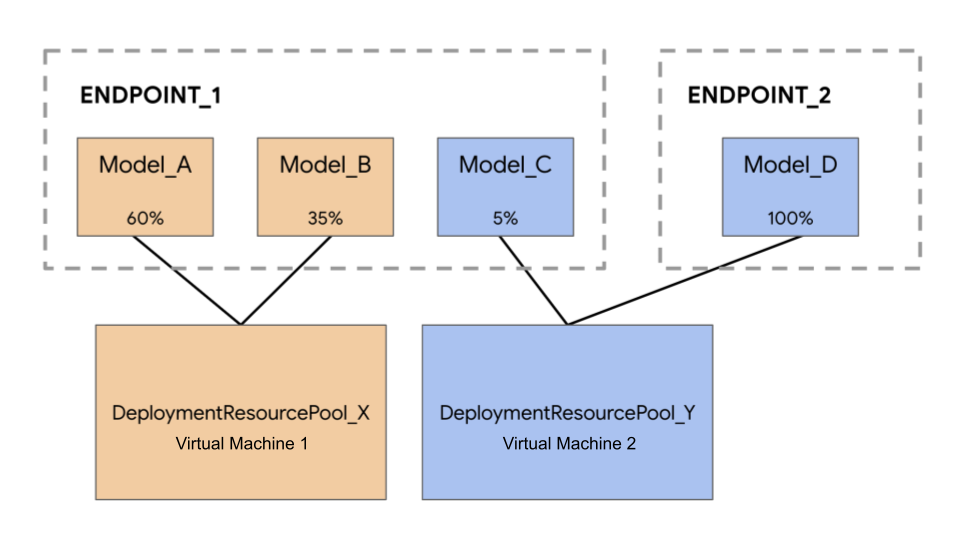
Model_A、Model_B 和 Model_C 會部署至 Endpoint_1,且流量會同時導向所有版本。Model_D,並部署到 Endpoint_2,該端點會接收 100% 的流量。
您可以將模型分組,不必為每個模型指派個別的 VM,分組方式如下:
- 將
Model_A和Model_B分組為DeploymentResourcePool_X,即可共用 VM。 - 群組
Model_C和Model_D(目前不在同一個端點) 共用 VM,因此成為DeploymentResourcePool_Y的一部分。
不同的部署資源集區無法共用 VM。
注意事項
部署至單一部署資源集區的模型數量沒有上限。這取決於所選的 VM 形狀、模型大小和流量模式。當您部署許多模型,但流量稀疏時,共用主機就很實用,因為為每個已部署的模型指派專屬機器,無法有效運用資源。
您可以同時將模型部署至同一個部署資源集區。但任何時間點的並行部署要求上限為 20 個。
空的部署資源集區不會耗用資源配額。部署第一個模型時,系統會將資源佈建至部署資源集區,並在解除部署最後一個模型時釋出資源。
單一部署資源集區中的模型不會彼此隔離,可能會爭用 CPU 和記憶體。如果另一個模型同時處理推論要求,某個模型的效能可能會降低。
限制
啟用資源共用功能後,部署模型時會受到下列限制:
- 這項功能僅支援下列設定:
- 使用 TensorFlow 預先建構容器部署 TensorFlow 模型
- 使用 PyTorch 預先建構容器的 PyTorch 模型部署作業
- 系統不支援為其他架構設定的預先建構容器。
- 不支援自訂容器。
- 僅支援自訂訓練模型和匯入模型。系統不支援 AutoML 模型。
- 只有使用相同容器映像檔 (包括架構版本) 的模型,才能部署在相同的部署資源集區。這些模型必須使用 Vertex AI 預建容器,以進行 TensorFlow 或 PyTorch 推論。
- 不支援 Vertex Explainable AI。
部署模型
如要將模型部署至 DeploymentResourcePool,請完成下列步驟:
- 視需要建立部署項目資源集區。
- 視需要建立端點。
- 擷取端點 ID。
- 將模型部署至部署項目資源集區中的端點。
建立部署項目資源集區
如果將模型部署至現有 DeploymentResourcePool,請略過這個步驟:
使用 CreateDeploymentResourcePool 建立資源集區。
Cloud Console
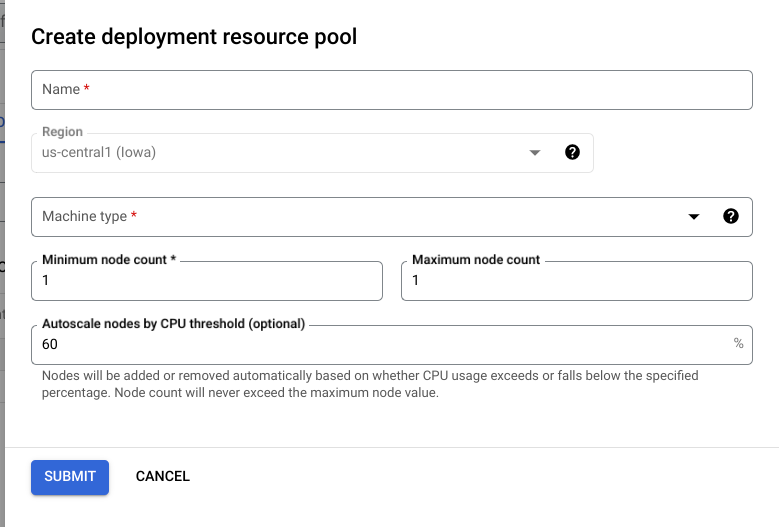
前往 Google Cloud 控制台的 Vertex AI「Deployment Resource Pools」(部署項目資源集區) 頁面。
按一下「建立」並填寫表單 (如下所示)。
REST
使用任何要求資料之前,請先替換以下項目:
- LOCATION_ID:您使用 Vertex AI 的區域。
- PROJECT_ID:您的專案 ID。
-
MACHINE_TYPE:選用。這個部署作業中每個節點使用的機器資源。預設設定為
n1-standard-2。 進一步瞭解機器類型。 - ACCELERATOR_TYPE:要附加至機器的加速器類型。如果未指定 ACCELERATOR_COUNT 或指定為零,則為選用。不建議用於使用非 GPU 圖片的 AutoML 模型或自訂訓練模型。瞭解詳情。
- ACCELERATOR_COUNT:每個副本要使用的加速器數量。 (選用步驟) 如果是使用非 GPU 圖片的 AutoML 模型或自訂訓練模型,則應為零或未指定。
- MIN_REPLICA_COUNT:此部署作業的節點數量下限。節點數量可視推論負載增加或減少,最多可達節點數量上限,最少則不得低於這個數量。這個值必須大於或等於 1。
- MAX_REPLICA_COUNT:此部署作業的節點數量上限。 節點數量可視推論負載需求增減,最多可達這個節點數量,且絕不會少於節點數量下限。
- REQUIRED_REPLICA_COUNT:選用。這項部署作業要標示為成功,所需的節點數量。必須大於或等於 1,且小於或等於節點數下限。如未指定,預設值為節點數量下限。
-
DEPLOYMENT_RESOURCE_POOL_ID:
DeploymentResourcePool的名稱。 長度上限為 63 個字元,有效字元為 /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/。
HTTP 方法和網址:
POST https://LOCATION_ID-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION_ID/deploymentResourcePools
JSON 要求主體:
{
"deploymentResourcePool":{
"dedicatedResources":{
"machineSpec":{
"machineType":"MACHINE_TYPE",
"acceleratorType":"ACCELERATOR_TYPE",
"acceleratorCount":"ACCELERATOR_COUNT"
},
"minReplicaCount":MIN_REPLICA_COUNT,
"maxReplicaCount":MAX_REPLICA_COUNT,
"requiredReplicaCount":REQUIRED_REPLICA_COUNT
}
},
"deploymentResourcePoolId":"DEPLOYMENT_RESOURCE_POOL_ID"
}
如要傳送要求,請展開以下其中一個選項:
您應該會收到如下的 JSON 回應:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION_ID/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.CreateDeploymentResourcePoolOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-15T05:48:06.383592Z",
"updateTime": "2022-06-15T05:48:06.383592Z"
}
}
}
您可以輪詢作業狀態,直到回應包含 "done": true 為止。
Python
# Create a deployment resource pool.
deployment_resource_pool = aiplatform.DeploymentResourcePool.create(
deployment_resource_pool_id="DEPLOYMENT_RESOURCE_POOL_ID", # User-specified ID
machine_type="MACHINE_TYPE", # Machine type
min_replica_count=MIN_REPLICA_COUNT, # Minimum number of replicas
max_replica_count=MAX_REPLICA_COUNT, # Maximum number of replicas
)
更改下列內容:
DEPLOYMENT_RESOURCE_POOL_ID:DeploymentResourcePool的名稱。長度上限為 63 個字元,有效字元為 /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/.MACHINE_TYPE:選用。這個部署項目中每個節點使用的機器資源。預設值為n1-standard-2。進一步瞭解機器類型。MIN_REPLICA_COUNT:此部署作業的節點數量下限。節點數量可視推論負載需求增減,最多可達節點數上限,最少則不得低於這個節點數。這個值必須大於或等於 1。MAX_REPLICA_COUNT:這個部署作業的節點數量上限。節點數量可根據推論負載增加或減少,最多可達這個節點數量,且不得少於節點數量下限。
建立端點
如要建立端點,請參閱「使用 gcloud CLI 或 Vertex AI API 建立公開端點」。這個步驟與單一模型部署相同。
擷取端點 ID
如要擷取端點 ID,請參閱「使用 gcloud CLI 或 Vertex AI API 部署模型」。這個步驟與單一模型部署相同。
在部署資源集區中部署模型
建立 DeploymentResourcePool 和端點後,即可使用 DeployModel API 方法進行部署。這個程序與單一模型部署類似。如果存在 DeploymentResourcePool,請指定要部署的 DeploymentResourcePool 資源名稱的 DeployModel shared_resources。
Cloud Console
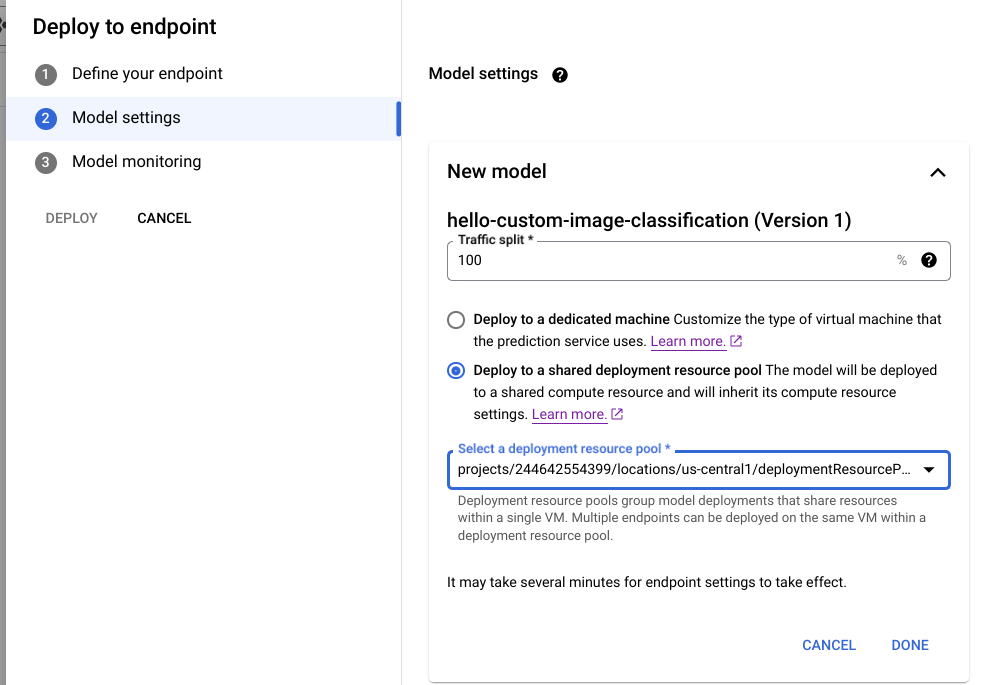
前往 Google Cloud 控制台的 Vertex AI「Model Registry」頁面。
找到模型,然後按一下「Deploy to endpoint」(部署至端點)。
在「模型設定」下方 (如下所示),選取「部署至共用部署項目資源集區」。
REST
使用任何要求資料之前,請先替換以下項目:
- LOCATION_ID:您使用 Vertex AI 的區域。
- PROJECT:您的專案 ID。
- ENDPOINT_ID:端點的 ID。
- MODEL_ID:要部署的模型 ID。
-
DEPLOYED_MODEL_NAME:
DeployedModel的名稱。您也可以使用Model的顯示名稱做為DeployedModel。 -
DEPLOYMENT_RESOURCE_POOL_ID:
DeploymentResourcePool的名稱。 長度上限為 63 個字元,有效字元為 /^[a-z]([a-z0-9-]{0,61}[a-z0-9])?$/。 - TRAFFIC_SPLIT_THIS_MODEL:要將多少預測流量從這個端點導向透過這項作業部署的模型。預設值為 100。所有流量百分比加總必須為 100%。進一步瞭解流量分配。
- DEPLOYED_MODEL_ID_N:選用。如果其他模型部署至這個端點,您必須更新流量分配百分比,讓所有百分比加總為 100%。
- TRAFFIC_SPLIT_MODEL_N:已部署模型 ID 鍵的流量分配百分比值。
- PROJECT_NUMBER:系統自動為專案產生的專案編號
HTTP 方法和網址:
POST https://LOCATION-aiplatform.googleapis.com/v1/projects/PROJECT/locations/LOCATION/endpoints/ENDPOINT_ID:deployModel
JSON 要求主體:
{
"deployedModel": {
"model": "projects/PROJECT/locations/us-central1/models/MODEL_ID",
"displayName": "DEPLOYED_MODEL_NAME",
"sharedResources":"projects/PROJECT/locations/us-central1/deploymentResourcePools/DEPLOYMENT_RESOURCE_POOL_ID"
},
"trafficSplit": {
"0": TRAFFIC_SPLIT_THIS_MODEL,
"DEPLOYED_MODEL_ID_1": TRAFFIC_SPLIT_MODEL_1,
"DEPLOYED_MODEL_ID_2": TRAFFIC_SPLIT_MODEL_2
},
}
如要傳送要求,請展開以下其中一個選項:
您應該會收到如下的 JSON 回應:
{
"name": "projects/PROJECT_NUMBER/locations/LOCATION/endpoints/ENDPOINT_ID/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.aiplatform.v1.DeployModelOperationMetadata",
"genericMetadata": {
"createTime": "2022-06-19T17:53:16.502088Z",
"updateTime": "2022-06-19T17:53:16.502088Z"
}
}
}
Python
# Deploy model in a deployment resource pool.
model = aiplatform.Model("MODEL_ID")
model.deploy(deployment_resource_pool=deployment_resource_pool)
將 MODEL_ID 替換為要部署的模型的 ID。
使用具有相同共用資源的不同模型重複上述要求,將多個模型部署至相同部署項目資源集區。
取得推論結果
您可以像對部署在 Vertex AI 上的任何其他模型一樣,對 DeploymentResourcePool 中的模型傳送推論要求。