Vertex 機器學習中繼資料會以階層方式整理資源,每個資源都屬於 MetadataStore。您必須先擁有 MetadataStore,才能建立中繼資料資源。
Vertex 機器學習中繼資料術語
下文將介紹用於描述 Vertex 機器學習中繼資料資源和元件的資料模型和術語。
MetadataStore
- MetadataStore 是中繼資料資源的頂層容器。MetadataStore 具有區域性,且與特定 Google Cloud 專案相關聯。一般來說,機構會在每個專案中使用一個共用的 MetadataStore,存放中繼資料資源。
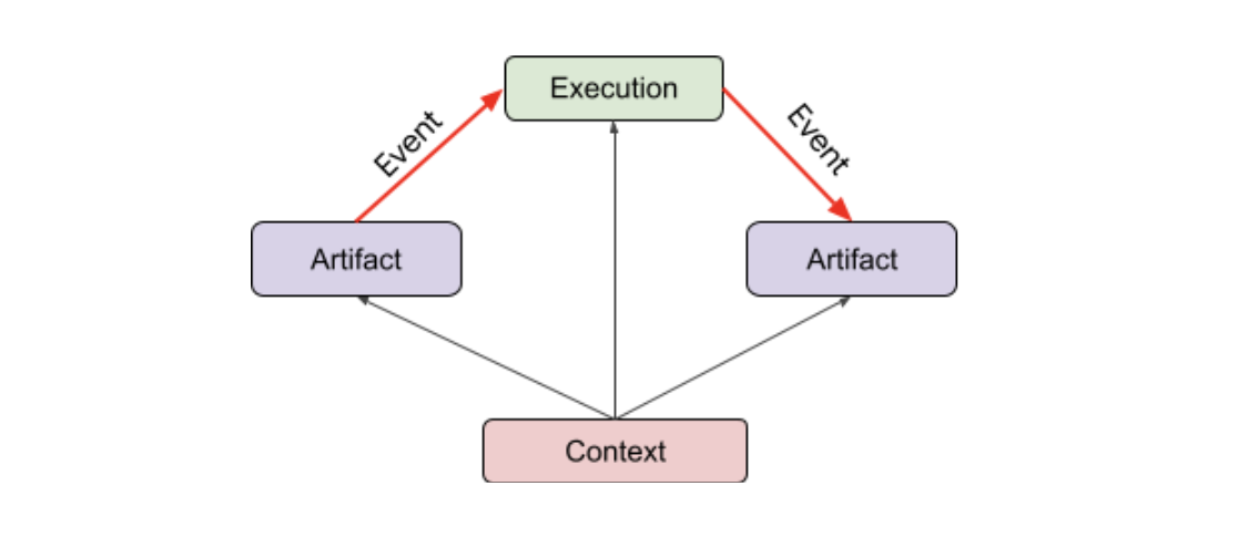
構件
- 構件是機器學習工作流程產生及使用的離散實體或資料。構件範例包括資料集、模型、輸入檔案和訓練記錄。
context
- 脈絡用於將構件和執行作業歸類為單一可查詢的型別類別。背景資訊可用來表示一組中繼資料。舉例來說,Context 可以是機器學習管道的執行作業。
Vertex AI Pipelines 管道執行作業。在本例中,脈絡代表一次執行作業,而每次執行作業則代表機器學習管道中的一個步驟。
從筆記本執行的實驗。在此情況下,內容可能代表筆記本,而每次執行作業可能代表筆記本中的儲存格。
活動
- 事件說明構件和執行作業之間的關係。每個構件都可以由執行作業產生,並由其他執行作業使用。您可以將構件和執行作業串連在一起,透過事件判斷機器學習工作流程中構件的出處。
執行
- 執行作業是個別機器學習工作流程步驟的記錄,通常會附上執行階段參數的註解。執行作業的範例包括資料擷取、資料驗證、模型訓練、模型評估和模型部署。
MetadataSchema
- MetadataSchema 會說明特定類型的構件、執行作業或環境的結構定義。建立相應的 Metadata 資源時,系統會使用 MetadataSchema 驗證鍵/值組合。系統只會對資源和 MetadataSchema 之間相符的欄位執行結構定義驗證。型別結構定義會以 OpenAPI 結構定義物件表示,並應使用 YAML 說明。
MetadataSchema 範例
類型結構定義會以 OpenAPI 結構定義物件表示,並以 YAML 說明。
以下範例說明如何以 YAML 格式指定預先定義的 Model 系統類型。
title: system.Model
type: object
properties:
framework:
type: string
description: "The framework type, for example 'TensorFlow' or 'Scikit-Learn'."
framework_version:
type: string
description: "The framework version, for example '1.15' or '2.1'"
payload_format:
type: string
description: "The format of the Model payload, for example 'SavedModel' or 'TFLite'"
結構定義的標題必須使用 <namespace>.<type name> 格式。
Vertex 機器學習中繼資料會發布及維護系統定義的結構定義,用於表示機器學習工作流程中廣泛使用的常見類型。這些結構定義位於 system 命名空間下,可在 API 中以 MetadataSchema 資源的形式存取。結構定義一律會加上版本。
如要進一步瞭解結構定義,請參閱「系統結構定義」。 此外,您還可以使用 Vertex 機器學習中繼資料建立使用者定義的自訂結構定義。如要進一步瞭解系統結構定義,請參閱「如何註冊自訂結構定義」。
公開的中繼資料資源與 ML Metadata (MLMD) 的開放原始碼實作項目密切相關。