フィードバックを送信
事前構築されたデータの前処理コードを使用したモデルのトレーニング: ノートブック
ノートブックを使用してモデルをローカルでトレーニングする、パラメータをログに記録する、トレーニング時系列の指標を Vertex AI TensorBoard に記録する、評価指標を記録する、という流れは、データ サイエンティストにとって一般的なワークフローです。
しかし、社内の他の人が作成したデータ前処理コードを再利用できれば、煩雑なデータ ラングリングを省力化し、標準化できます。そのために、次のことを可能にする必要があります。
Python データ前処理ライブラリを使用して、ノートブックのメモリ内データセット(Pandas Dataframe)をクリーンアップする。
Keras を使用してモデルをトレーニングする(ノートブックで再度トレーニングする)。
ノートブック: 前処理済みデータを使用したモデルのテスト
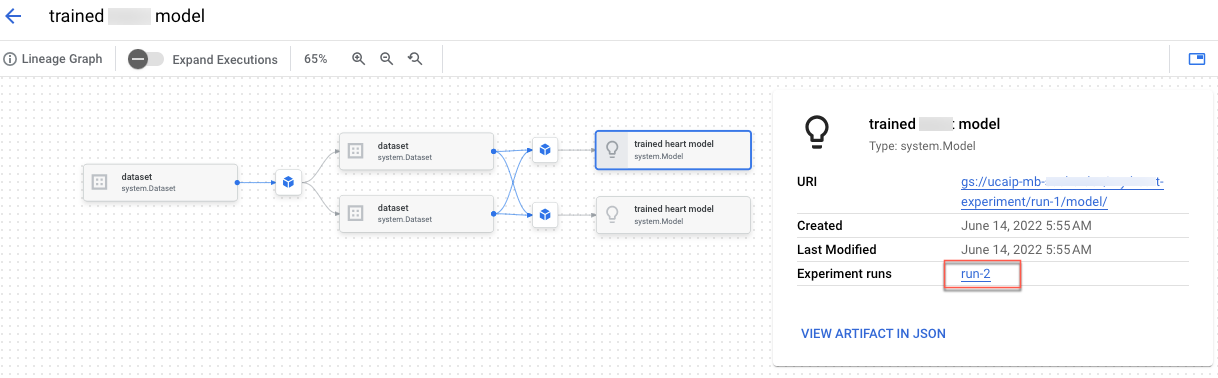
「カスタム トレーニング用の Vertex AI Experiments リネージを作成する」ノートブックでは、Vertex AI Experiments に前処理コードを統合する方法を学習します。また、ML の過程で生成されたメタデータとアーティファクトの記録、分析、デバッグ、監査を行えるテストリネージを構築します。
アーティファクト リネージは、 Google Cloud コンソールで確認できます。
関連性の高いコンテンツ
フィードバックを送信
特に記載のない限り、このページのコンテンツはクリエイティブ・コモンズの表示 4.0 ライセンス により使用許諾されます。コードサンプルは Apache 2.0 ライセンス により使用許諾されます。詳しくは、Google Developers サイトのポリシー をご覧ください。Java は Oracle および関連会社の登録商標です。
最終更新日 2025-10-19 UTC。
ご意見をお聞かせください
[[["わかりやすい","easyToUnderstand","thumb-up"],["問題の解決に役立った","solvedMyProblem","thumb-up"],["その他","otherUp","thumb-up"]],[["わかりにくい","hardToUnderstand","thumb-down"],["情報またはサンプルコードが不正確","incorrectInformationOrSampleCode","thumb-down"],["必要な情報 / サンプルがない","missingTheInformationSamplesINeed","thumb-down"],["翻訳に関する問題","translationIssue","thumb-down"],["その他","otherDown","thumb-down"]],["最終更新日 2025-10-19 UTC。"],[],[]]