如果是圖片資料,您可以匯入已加上標籤或未加上標籤的資料,並使用 Google Cloud 控制台新增標籤。您也可以刪除或新增現有標記資料集的標籤。
如要瞭解如何匯入資料,請參閱「訓練總覽」頁面中,您使用的資料類型和目標的「準備資料」頁面。繼續前往資料類型和目標適用的「建立資料集」頁面。
建立資料集並匯入未標記的資料後,系統會進入「瀏覽」模式。

如何新增標籤
如需目標標記操作說明,請參閱這篇文章。
您剛匯入資料集的圖片未加上標籤,這是預期行為。
分類
在「瀏覽」模式中,選取含有未加標籤圖片的資料集後,即可查看上傳的圖片。
- 按一下「新增標籤」,然後輸入新標籤。
- 按一下「完成」。
針對要新增的每個標籤重複上述步驟。 - 選取要加上標籤的圖片。
系統會顯示標籤清單。 - 選取要與圖片建立關聯的標籤。
- 按一下 [儲存]。
分類
在「瀏覽」模式下,選取含有未標記圖片的資料集,即可查看上傳的圖片。
- 按一下「新增標籤」,然後輸入新標籤。
- 按一下「完成」。
針對要新增的每個標籤重複上述步驟。 - 選取要加上標籤的圖片。
系統會顯示標籤清單。 - 選取要與圖片建立關聯的標籤。
- 按一下 [儲存]。
- 您可以在「瀏覽」分頁中查看套用至每張圖片的標籤。

物件偵測
在「瀏覽」模式下,選取含有未標記圖片的資料集,即可查看上傳的圖片。
- 按一下「新增標籤」,然後輸入新標籤。
- 按一下「完成」。
針對要新增的每個標籤重複上述步驟。 - 選取要加上標籤的圖片。
- 如果有的話,畫面會顯示標籤物件清單。
- 在新增註解視窗中,選取「新增邊界方塊」按鈕,將物件邊界方塊新增至圖片。
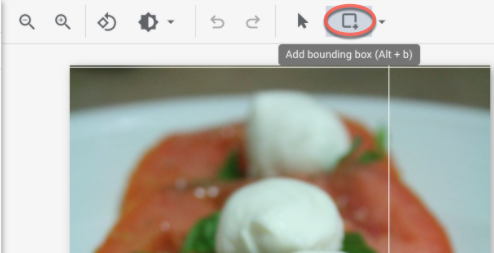
- 繪製定界框後,系統會顯示可套用至物件的標籤清單。
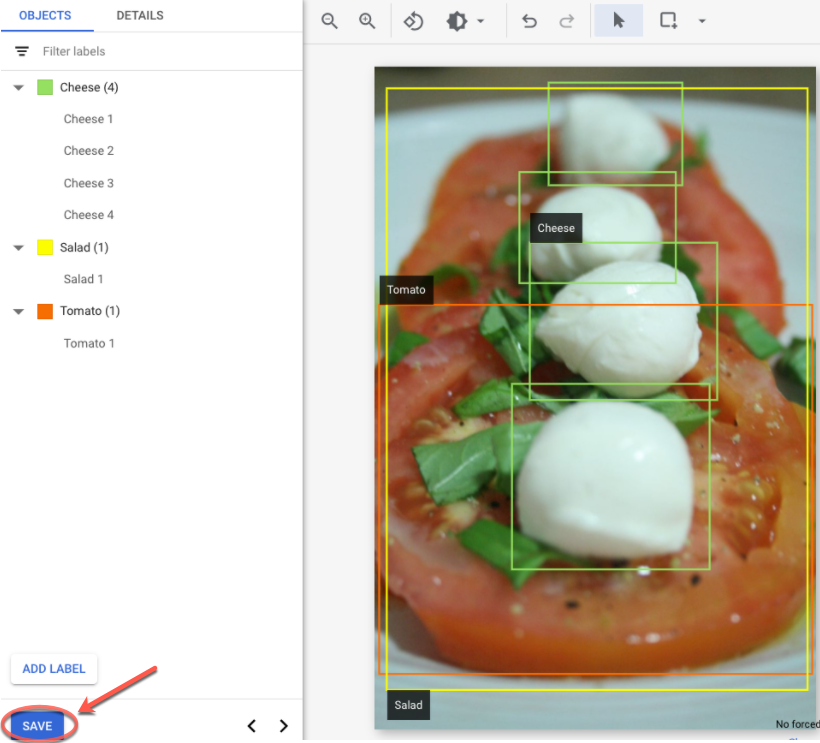
選擇適當的標籤。

- 新增所有標籤和邊界方塊後,按一下「儲存」,即可更新圖片的註解。
後續步驟
- 使用 Google Cloud 控制台訓練 AutoML 模型。
使用 Google Cloud 控制台訓練 AutoML Edge 模型。 (僅限圖片)