La modélisation des données vous aide à structurer vos données dans Looker Studio pour créer des rapports pertinents et ciblés. Ce processus consiste à configurer les données et les métadonnées pour les aligner sur vos objectifs commerciaux. Pour ce faire, vous devez affiner la façon dont Looker Studio organise les données en dimensions, métriques et champs calculés. Vous pouvez appliquer ces techniques de modélisation à trois niveaux distincts : dans un rapport, dans la source de données ou directement dans l'ensemble de données sous-jacent.
Utilisez les fonctionnalités de modélisation des données pour ajuster les propriétés des champs, créer des champs calculés et appliquer des filtres. Ces fonctionnalités vous permettent de transformer des données brutes, d'obtenir de nouveaux insights et de contrôler l'accès aux données. Vous pouvez ainsi améliorer la pertinence et la clarté de vos rapports Looker Studio.
Avant de commencer
Pour tirer pleinement parti de cette page, vous devez maîtriser les thèmes suivants :
Comment Looker Studio organise vos données
Avant de vous pencher sur les spécificités de la modélisation des données, il est utile de comprendre comment Looker Studio organise vos données. Chaque graphique et tableau que vous créez dans Looker Studio est basé sur une structure de données tabulaires composée de colonnes et de lignes. Les colonnes, appelées champs, définissent les données contenues dans chaque ligne. Les informations qui définissent vos données sont appelées métadonnées.
Il existe deux types de champs dans Looker Studio :
- Les dimensions correspondent à vos catégories ou libellés. Les dimensions décrivent ce que vous mesurez. Exemple :
- Pays
- Nom du produit
- Date
- Les métriques sont vos mesures. Les métriques indiquent la quantité d'un élément. Par exemple :
- Ventes
- Pageviews
- Nombre de clics
Lorsque vous créez une source de données, vous voyez les dimensions et les métriques fournies par le connecteur que vous avez utilisé pour vous connecter à l'ensemble de données sous-jacent. En plus de ces champs par défaut, vous pouvez créer d'autres types de champs :
Les champs calculés utilisent des formules pour créer des métriques ou des dimensions à partir de vos données. Exemple :
Price * DiscountTODAY() - 7IF(FINAL GRADE > 35, "PASS", "FAIL")
Les paramètres et les variables vous permettent de personnaliser vos rapports en fonction des entrées utilisateur. En savoir plus sur les paramètres
Ensemble, ces champs (dimensions, métriques, champs calculés, paramètres et variables) constituent les blocs de base de vos rapports. La modélisation des données vous permet d'affiner ces blocs de construction pour vous aider à créer des rapports Looker Studio informatifs.
Où pouvez-vous modéliser vos données ?
Vous pouvez modéliser vos données à trois niveaux :
- Dans le rapport
- Dans la source de données
Dans l'ensemble de données sous-jacent
Vous pouvez considérer ces niveaux de modélisation comme une pyramide inversée. Vous pouvez combiner ces niveaux. L'endroit où vous modélisez vos données dépend de vos besoins.
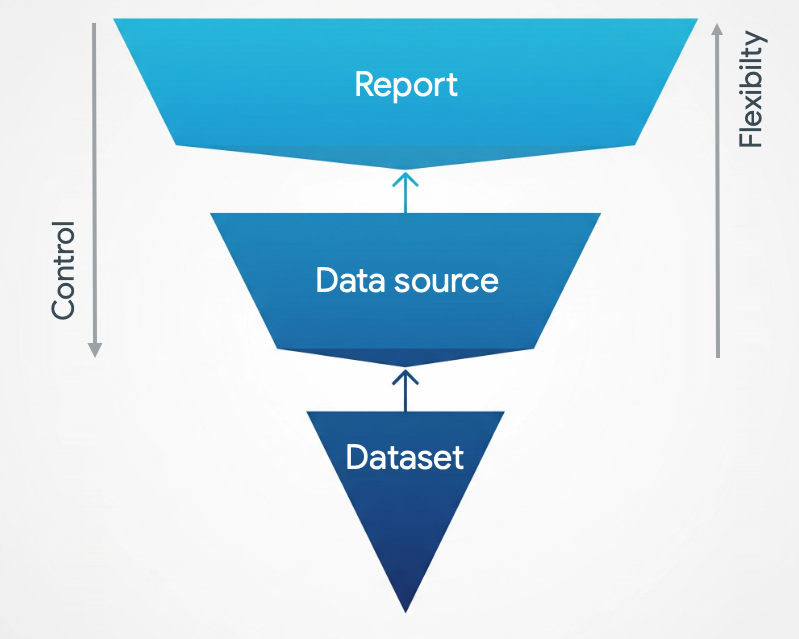
La modélisation des données au niveau de l'ensemble de données s'effectue en dehors de Looker Studio. Ici, l'accent n'est plus mis sur l'équilibre entre flexibilité et contrôle, mais sur la garantie que vos données et métadonnées sont exactement comme vous le souhaitez avant même d'atteindre Looker Studio.
Les sections suivantes décrivent ces niveaux de modélisation plus en détail.
Modélisation au niveau du rapport
La modélisation des données au niveau du rapport offre aux éditeurs de rapports la plus grande flexibilité pour modifier et explorer les données comme ils le souhaitent, un peu comme s'ils jouaient librement avec des blocs de construction.
Lorsque vous modélisez des données au niveau du rapport, tenez compte des points suivants :
- Les fonctionnalités de modélisation appliquées lors de la modification d'un rapport résident exclusivement dans ce rapport. Par conséquent, différents rapports peuvent afficher des insights différents, même s'ils utilisent la même source de données.
- La modélisation au niveau du rapport offre le moins de contrôle sur vos données. Les éditeurs de rapports peuvent consulter et modifier les champs des sources de données intégrées.
- Les lecteurs de rapports peuvent consulter certaines configurations de modélisation. Pour en savoir plus, consultez la section sur la modélisation et l'accès aux données.
Modélisation au niveau de la source de données
La modélisation des données au niveau de la source de données vous permet de mieux contrôler les données. Vous pouvez limiter les personnes autorisées à modifier la source de données et empêcher la modification des champs dans le rapport. La modélisation au niveau de la source de données permet de s'assurer que tous vos rapports sont basés sur une source unique de vérité.
Lorsque vous modélisez des données au niveau de la source de données, tenez compte des points suivants :
- Les fonctionnalités de modélisation appliquées lors de la modification d'une source de données résident dans cette source de données.
- La modélisation au niveau de la source de données rend le modèle disponible pour chaque graphique et rapport qui l'utilise.
- Certaines fonctionnalités de modélisation des données ne sont disponibles qu'au niveau de la source de données. Par exemple, vous ne pouvez ajouter des descriptions de champs que dans la source de données. À l'inverse, à l'exception des rapports qui utilisent le connecteur Looker, vous ne pouvez appliquer des filtres qu'au niveau du rapport.
- Les lecteurs de rapports peuvent consulter certaines configurations de modélisation au niveau de la source de données. Pour en savoir plus, consultez Modélisation et accès aux données.
Modéliser les données dans l'ensemble de données sous-jacent
La modélisation des données dans l'ensemble de données sous-jacent garantit que chaque source de données connectée reçoit les données précises dont elle a besoin. Cette approche est souvent préférable lorsque vous préparez des données avant qu'elles n'atteignent Looker Studio.
Par exemple, écrire une requête SQL directement dans le connecteur BigQuery peut être plus efficace que d'utiliser des fonctions ou des filtres Looker Studio pour des transformations de données complexes.
La modélisation au niveau du dataset offre le plus haut degré de sécurité pour vos données. Les éditeurs de sources de données ne peuvent pas accéder à l'ensemble de données sous-jacent, sauf s'ils ont reçu explicitement des autorisations directes.
Modéliser vos données
Vous pouvez modéliser vos données à l'aide des fonctionnalités suivantes :
- Ajuster les propriétés des champs, comme le nom, le type de données ou l'agrégation
- Créer des champs calculés qui étendent ou transforment les données de base
- Appliquer des filtres aux données pour inclure ou exclure certaines valeurs
Ajuster les propriétés des champs
Les champs de votre source de données sont associés à un ensemble de propriétés par défaut fournies par le connecteur utilisé pour créer cette source de données, comme indiqué dans le tableau ci-dessous.
Afficher les propriétés de champ que vous pouvez modifier
| Propriété | Description |
| Nom du champ | Le nom du champ apparaît dans la colonne Champ de la source de données et dans le Nom à afficher du chip de champ dans le panneau des propriétés du rapport. |
| Type de données | Le type de données apparaît dans la colonne Type de la source de données et dans le chip de champ Type de données du panneau des propriétés du rapport.
La propriété de type de données indique à Looker Studio à quel genre de données il doit s'attendre au moment de traiter le champ. Le type de données détermine la façon dont les données apparaissent dans vos rapports, et les opérations qui sont autorisées ou non. Par exemple, vous ne pouvez pas appliquer de fonction arithmétique à un champ de type Texte, ni utiliser un champ de type Nombre comme dimension d'une période dans un rapport. |
| Agrégation | L'agrégation s'affiche dans la colonne Agrégation par défaut de la source de données et dans la colonne Agrégation du chip de champ dans le panneau des propriétés du rapport.
L'agrégation résume les données d'un champ. Trois méthodes par défaut sont disponibles, en fonction de la source des données et de leur définition dans l'ensemble de données :
|
| Description | La colonne Description de la source de données vous permet d'ajouter des annotations à des champs individuels. Vous ne pouvez pas modifier la description d'un champ au niveau du rapport.
Certains connecteurs, comme Looker et Search Ads 360, fournissent automatiquement des descriptions de champs. Pour afficher les descriptions des champs dans les tableaux, activez l'option de style Afficher les descriptions des champs dans les propriétés du tableau. L'option Afficher les descriptions des champs est automatiquement activée pour les graphiques connectés à une source de données Looker ou Search Ads 360. |
| Format d'affichage | La propriété Format d'affichage vous permet de modifier la façon dont un champ numérique ou de date s'affiche dans un graphique. L'option Format d'affichage n'apparaît que dans le chip de champ du panneau des propriétés du rapport. |
| Calcul de comparaison | La propriété Calcul de comparaison vous permet de comparer chaque ligne de données au total global de ce champ. Le calcul de comparaison n'apparaît que dans le chip de champ du panneau des propriétés du rapport. |
| Calculs cumulés | La propriété Calcul cumulé vous permet de calculer les résultats cumulés de vos données. L'option Calcul cumulé n'apparaît que dans le chip du champ, dans le panneau des propriétés du rapport. |
Pour modifier les propriétés des champs au niveau de la source de données, modifiez la source de données.
Pour modifier les propriétés d'un champ au niveau du rapport :
- Modifiez le rapport, puis sélectionnez un graphique.
- Dans le panneau des propriétés du graphique, pointez sur l'icône de type de données du champ. L'icône du type de données est remplacée par l'icône en forme de crayon.
- Cliquez sur l'icône crayon .
- Dans la boîte de dialogue qui s'affiche, modifiez les propriétés du champ.
Pour empêcher les éditeurs de rapports de modifier les propriétés des champs, désactivez l'option Modification des champs dans les rapports de la source de données. En savoir plus sur la modification des champs
Modéliser des données avec des champs calculés
Les champs calculés vous permettent de créer des champs à partir de vos données. Ils sont représentés par le symbole fx dans la liste des champs.
Les champs calculés que vous créez dans la source de données sont disponibles dans tous les rapports qui utilisent cette source de données. Les champs calculés que vous créez dans un graphique du rapport ne sont disponibles que dans ce graphique.
En savoir plus sur les champs calculés
Appliquer les filtres
Vous pouvez limiter les données d'un rapport en appliquant un filtre pour affiner les informations qui sont présentées aux lecteurs. Les filtres vous aident à vous concentrer sur les données les plus importantes, ce qui rend vos rapports plus pertinents pour votre audience.
Vous pouvez appliquer des filtres à un seul composant, à un groupe de composants, à une page entière ou à l'ensemble du rapport.
En savoir plus sur les propriétés de filtrage
Modélisation et accès aux données
Les métadonnées d'un rapport incluent les paramètres d'affichage des fonctionnalités de modélisation au niveau du rapport, comme la configuration des filtres ou les noms des champs calculés créés à partir du panneau des propriétés. Les métadonnées des rapports sont visibles par toute personne ayant accès en lecture au rapport qui examine les requêtes réseau du rapport ou en crée une copie.
Seuls les éditeurs de sources de données peuvent voir les paramètres d'affichage des fonctionnalités de modélisation au niveau de la source de données, comme les descriptions de champs ou les noms des champs calculés créés dans la source de données. Toutefois, certains aspects du modèle de source de données, comme le type de connecteur et les noms de colonnes du schéma de source de données, sont toujours accessibles aux utilisateurs.