Puoi controllare lo stato di un volume Persistent Disk o Google Cloud Hyperdisk esaminando la metrica Stato delle prestazioni del disco. Questa metrica indica se le prestazioni del disco sono potenzialmente interessate da eventi avversi in Compute Engine.
Un problema che influisce sullo stato delle prestazioni del disco potrebbe essere visibile anche nella dashboard Personal Service Health (PSH) o Google Cloud Service Health del progetto.
Questo documento illustra lo stato delle prestazioni del disco e come utilizzarlo per risolvere i problemi di prestazioni.
Quando controllare l'integrità di un disco
Se noti un problema di prestazioni di un disco, controlla il suo stato esaminando la metrica relativa allo stato delle prestazioni del disco. La metrica dello stato delle prestazioni del disco viene aggiornata ogni minuto e rappresenta le prestazioni del disco nell'intero minuto precedente. Per la procedura per controllare l'integrità del disco, consulta Visualizza lo stato delle prestazioni del disco.
La tabella seguente riassume i possibili valori dello stato delle prestazioni del disco.
| Stato | Significato |
|---|---|
Healthy |
Le prestazioni del disco sono come previsto. |
Degraded |
Potresti notare temporaneamente una latenza I/O superiore al previsto. |
Severely degraded |
Si verificano latenze I/O elevate o altri errori. |
Se lo stato delle prestazioni del disco non è Healthy, consulta Informazioni su ogni stato
per conoscere i passaggi successivi.
Se lo stato delle prestazioni è Healthy, il disco funziona normalmente e devi
verificare altre cause del problema di prestazioni.
Devi verificare la presenza di errori dell'applicazione o del sistema operativo e assicurarti che il disco
sia ottimizzato correttamente. Per le linee guida sull'ottimizzazione,
consulta Ottimizza Hyperdisk
e Ottimizza Persistent Disk.
La relazione tra l'integrità del disco e le altre metriche sulle prestazioni del disco
Lo stato di integrità del disco, indicato dalla metrica dello stato delle prestazioni, mostra lo
stato interno del disco dal punto di vista di Google. Se lo stato di un disco è
Degraded o Severely Degraded, la causa principale si trova sempre all'interno
dell'infrastruttura Compute Engine.
In genere, non puoi modificare lo stato di un disco modificando il workload. Tuttavia, in rari casi, una modifica al workload potrebbe attivare un problema interno, pertanto potrebbe essere possibile attenuare un problema modificando il workload.
Per informazioni sulle altre metriche sulle prestazioni del disco disponibili, consulta Esamina le metriche sulle prestazioni del disco.
Scenari che non influiscono sullo stato delle prestazioni del disco
Lo stato delle prestazioni del disco non è correlato ai problemi causati dai seguenti fattori:
- Ottimizzazione del disco incompleta o insufficiente
- Limite di prestazioni associato al disco e al tipo di macchina (se il tipo di macchina scelto non è in grado di soddisfare i requisiti di prestazioni del workload)
- Aumento del carico sul disco a causa del traffico del workload
- Errore dell'utente, dell'applicazione o del sistema operativo
- Dischi pieni o danneggiati
- Per i volumi Hyperdisk ed Extreme Persistent Disk, IOPS o throughput sottoposti a provisioning insufficienti.
In queste situazioni, è tua responsabilità migliorare le prestazioni, ad esempio ottimizzando il disco, aumentando il workload, modificando il tipo di macchina ed eseguendo il provisioning di più capacità, IOPS o throughput.
Visualizza l'integrità del disco in Cloud Monitoring
Per visualizzare l'integrità di un disco, crea un grafico in Esplora metriche.
Ruoli e autorizzazioni richiesti
Per ottenere le autorizzazioni necessarie per controllare la metrica dello stato delle prestazioni del disco, chiedi all'amministratore di concederti i seguenti ruoli IAM nel progetto:
-
Monitoring Viewer (
roles/monitoring.viewer) -
Per salvare un grafico in una dashboard:
Monitoring Editor (
roles/monitoring.editor)
Per ulteriori informazioni sulla concessione dei ruoli, consulta Gestisci l'accesso a progetti, cartelle e organizzazioni.
Potresti anche riuscire a ottenere le autorizzazioni richieste tramite i ruoli personalizzati o altri ruoli predefiniti.
Crea un grafico in Esplora metriche
Per creare un grafico, crea una query con l'interfaccia basata su menu o PromQL.
Interfaccia basata su menu
Per visualizzare lo stato di uno o più dischi in un grafico, segui queste istruzioni.
-
Nella console Google Cloud , vai alla pagina leaderboard Esplora metriche:
Se utilizzi la barra di ricerca per trovare questa pagina, seleziona il risultato con il sottotitolo Monitoring.
- Nella barra degli strumenti della console Google Cloud , seleziona il tuo progetto Google Cloud . Per le configurazioni di App Hub, seleziona il progetto host di App Hub o il progetto di gestione della cartella app.
- Nell'elemento Metrica, espandi il menu Seleziona una metrica,
digita
VM Instancenella barra dei filtri e poi utilizza i sottomenu per selezionare un tipo di risorsa e una metrica specifici:- Nel menu Risorse attive, seleziona Istanza VM.
- Nel menu Categorie di metriche attive, seleziona Istanza.
- Nel menu Metriche attive, seleziona Stato delle prestazioni del disco.
- Fai clic su Applica.
compute.googleapis.com/instance/disk/performance_status. Per aggiungere filtri, che rimuovono le serie temporali dai risultati della query, utilizza l'elemento Filtro.
- Configura la modalità di visualizzazione dei dati.
Disattiva l'aggregazione. Assicurati che nell'elemento Aggregazione, il primo menu sia impostato su Nessuna aggregazione e il secondo su Nessuna.
Per visualizzare lo stato di un disco specifico, filtra in base adevice_name.
Per ulteriori informazioni sulla configurazione di un grafico, consulta Seleziona le metriche durante l'utilizzo di Esplora metriche.
PromQL
Apri l'editor di query: segui i passaggi descritti in Scrivi query PromQL.
Inserisci la query nell'editor di query. Ad esempio, per visualizzare lo stato delle prestazioni di un disco specifico, inserisci la seguente query:
last_over_time
(compute_googleapis_com:instance_disk_performance_status
{monitored_resource="gce_instance",
project_id ="PROJECT_ID",
device_name="DISK_NAME"}[${__interval}])
Sostituisci DISK_NAME con il nome del disco, ad esempio
disk-1.
Se visualizzi i risultati in un grafico, sono presenti 3 righe per ogni disco, una per ogni possibile stato. Analogamente, se visualizzi il risultato della query in una tabella, la tabella contiene 3 righe per ogni disco.
Se hai creato la query con PromQL, ogni riga avrà
un valore 1 o 0. Per le query create con i menu, i valori saranno
100% o 0.
Lo stato corrente del disco è rappresentato dalla riga il cui valore è 100%
o 1.
Ad esempio, lo screenshot seguente mostra il grafico di un disco denominato a-test-VM,
il cui stato è Healthy:
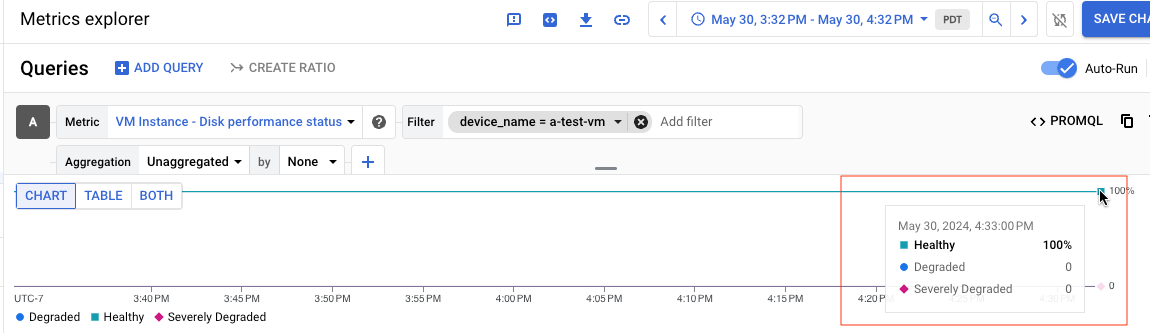
Se visualizzi i risultati della query come tabella, la tabella seguente è un esempio di
risultati per un disco Healthy:
| performance_status | value |
|---|---|
Healthy |
1 |
Degraded |
0 |
Severely Degraded |
0 |
Lo screenshot seguente mostra il grafico di un disco denominato replica-23509 il cui stato è Prestazioni ridotte:
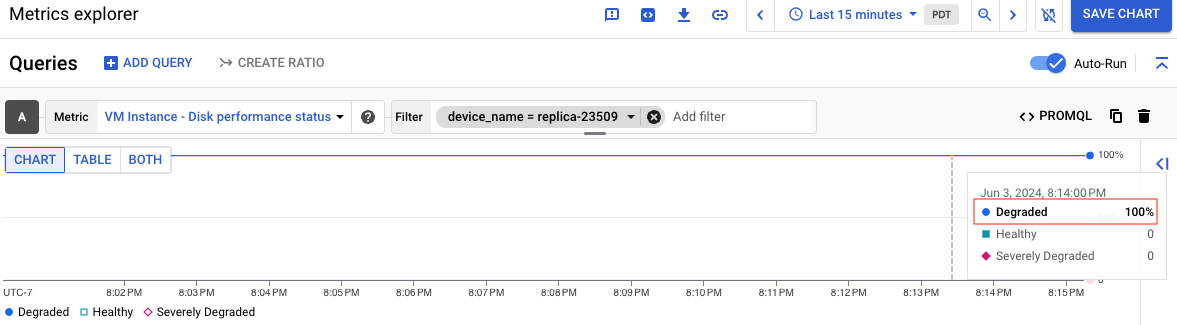
Per informazioni sul significato di ogni stato delle prestazioni del disco, consulta Informazioni su ogni stato. Dopo aver creato il grafico, puoi salvarlo in una dashboard per utilizzarlo in futuro.
Risultati frazionari
Se la query include risultati frazionati come nella tabella seguente,
solitamente è perché il periodo di visualizzazione
selezionato era lungo. Di conseguenza, Cloud Monitoring ha aggregato i dati nel tempo.
Un valore 77% per lo stato Healthy indica che lo stato del disco era Healthy
nel 77% del periodo di visualizzazione selezionato.
| performance_status | value |
|---|---|
Healthy |
77% |
Degraded |
23% |
Severely Degraded |
0 |
Per una visione più granulare dell'integrità di un disco, utilizza un periodo di visualizzazione di alcune ore o di alcuni minuti.
Informazioni su ogni stato
Questa sezione illustra il significato di ogni stato e quando potresti dover intraprendere un'azione aggiuntiva.
Healthy
Lo stato Healthy indica che, dal punto di vista di Google, il disco
funziona normalmente.
Se un disco Healthy presenta problemi di prestazioni, non contattare l'assistenza. Invece
risolvi i problemi del disco utilizzando alcuni dei seguenti suggerimenti:
- Esamina le metriche sulle prestazioni del disco, ad esempio la latenza e la profondità della coda.
- Controlla i log e le metriche del workload per rilevare anomalie e colli di bottiglia.
- Se utilizzi un Persistent Disk, assicurati che la capacità di cui è stato eseguito il provisioning possa soddisfare le esigenze di prestazioni del disco. Se utilizzi volumi Hyperdisk o Extreme Persistent Disk, verifica di aver eseguito il provisioning di IOPS e throughput in maniera sufficiente.
- Assicurati di aver seguito le linee guida per ottimizzare il disco. Per ulteriori informazioni, consulta Ottimizza Hyperdisk e Ottimizza Persistent Disk.
Degraded
In genere non è necessario contattare l'assistenza se lo stato del disco
è Degraded. Un Degraded status è generalmente causato dalla normale manutenzione interna
dell'infrastruttura Compute Engine.
Potresti non notare alcun impatto sulle prestazioni del disco mentre lo stato è
Degraded. Se il problema di prestazioni e lo stato Degraded
sono correlati nel tempo, il problema di prestazioni potrebbe non essere correlato allo stato
Degraded.
Nell'improbabile caso in cui un problema di prestazioni sia dovuto allo stato Degraded,
l'impatto è in genere temporaneo. Lo stato del disco dovrebbe tornare a Healthy entro
alcuni minuti.
Puoi ignorare lo stato Degraded se non ci sono problemi di prestazioni
con il disco.
Che cosa fare in caso di problemi di prestazioni
Se lo stato delle prestazioni del disco è Degraded e riscontri un problema di prestazioni,
segui questi passaggi:
- Controlla la dashboard PSH per verificare se si è verificato un incidente che interessa il disco. In caso di incidente, non contattare l'assistenza perché Google è a conoscenza del problema e sta lavorando per risolverlo.
- Se non sono presenti problemi noti, attendi almeno 5 minuti affinché il problema di prestazioni si risolva autonomamente.
Se dopo 5 minuti il problema di prestazioni non è stato risolto e lo stato è ancora
Degraded, assicurati che il problema non sia dovuto a un'ottimizzazione insufficiente del disco. Ad esempio, controlla la latenza e la profondità della coda del disco. È possibile che il problema di prestazioni e lo statoDegradednon siano correlati e siano solo una coincidenza. A questo scopo, esamina le metriche del disco e le linee guida per l'ottimizzazione delle prestazioni.Se i problemi di prestazioni persistono e tutte le seguenti condizioni sono soddisfatte, puoi contattare l'assistenza per ricevere aiuto:
- Lo stato del disco è
Degradedda più di 5 minuti - Hai ragionevoli garanzie che non si tratta di un problema di workload perché hai ottimizzato il disco e verificato che non ci siano altri problemi come un collo di bottiglia o un'applicazione sovraccaricata
- Non sono presenti avvisi nella dashboard PSH
- Lo stato del disco è
Google sconsiglia di creare un avviso direttamente per lo stato
Degraded, ma consiglia di creare un avviso per lo stato dell'applicazione di livello superiore e di utilizzare
questa metrica per eseguire il debug dei problemi.
Severely Degraded
Un disco con stato di prestazioni Severely Degraded presenta un
problema di prestazioni. Questo problema può essere dovuto a un incidente o a un errore e potrebbe
essere già visibile nella dashboard PSH
o nella dashboard Google Cloud Service Health.
Cosa fare
Se lo stato delle prestazioni del disco è Severely Degraded, segui questi passaggi:
- Controlla la dashboard PSH e la dashboard Google Cloud di integrità generale per verificare la presenza di un incidente che interessa il disco. In caso di incidente, non contattare l'assistenza, poiché Google è a conoscenza del problema e sta lavorando per risolverlo.
- Se non sono presenti problemi noti in entrambe le dashboard, contatta l'assistenza per ricevere aiuto.
Albero decisionale
Il seguente diagramma illustra la procedura da seguire in caso di problemi di prestazioni di un disco e riassume le informazioni riportate nelle sezioni precedenti.

Come mostrato nel diagramma di flusso, devi contattare l'assistenza solo se non sono presenti avvisi noti
nelle dashboard di PSH e del servizio cloud e lo stato del disco è
Severely Degraded. Se il disco è Degraded, contatta l'assistenza solo se sono soddisfatte tutte
le seguenti condizioni:
- Il disco è
Degradedda più di 5 minuti - Hai escluso un errore o una configurazione errata del workload (ad esempio problemi di rete)
- Non è possibile eseguire ottimizzazioni aggiuntive a livello di applicazione, workload o disco
- Hai esaminato tutte le metriche del disco
- Hai esaminato i log del workload e della macchina virtuale (VM)
Passaggi successivi
- Scopri di più sulla creazione di grafici con Esplora metriche e su come perfezionare i risultati delle query aggiungendo filtri a un grafico.
- Controlla la presenza di eventi Service Health attivi e passati nella dashboard di Personalized Service Health e in Google Service Health
- Per le linee guida sull'ottimizzazione delle prestazioni, consulta Ottimizza Hyperdisk e Ottimizza Persistent Disk.